







 本文是一系列教程的第一章,介绍了大模型的基础概念,随后深入讲解了如何使用LangChain技术来调用智谱的GLM模型进行知识库构建和RAG应用开发。
本文是一系列教程的第一章,介绍了大模型的基础概念,随后深入讲解了如何使用LangChain技术来调用智谱的GLM模型进行知识库构建和RAG应用开发。
系列文章目录
动手学大模型应用开发第一章:大模型简介
动手学大模型应用开发第二章:使用 LLM API 开发应用
动手学大模型应用开发第三章:搭建知识库
动手学大模型应用开发第四章:构建 RAG 应用
动手学大模型应用开发第五章:系统评估与优化
文章目录
前言
本文内容来自 https://datawhalechina.github.io/llm-universe
1 LLM 接入 LangChain
1.1 使用 LangChain 调用智谱 GLM
- 同样可以通过 LangChain 框架来调用智谱 AI 大模型,以将其接入到我们的应用框架中。由于 langchain 中提供的ChatGLM已不可用,因此我们需要自定义一个 LLM。
自定义 LLM
- 这里采用 llm-universe 提供的源码 https://datawhalechina.github.io/llm-universe/#/./zhipuai_llm.py
# -*- encoding: utf-8 -*-
"""
封装的使用langchain调用智谱LLM方法
因为langchain已经不在支持chatglm
"""
from typing import Any, List, Mapping, Optional, Dict
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from zhipuai import ZhipuAI
import os
# 继承自 langchain.llms.base.LLM
class ZhipuAILLM(LLM):
# 默认选用 glm-4
model: str = "glm-4"
# 温度系数
temperature: float = 0.1
# API_Key
api_key: str = None
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
client = ZhipuAI(
api_key = self.api_key
)
def gen_glm_params(prompt):
'''
构造 GLM 模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
messages = gen_glm_params(prompt)
response = client.chat.completions.create(
model = self.model,
messages = messages,
temperature = self.temperature
)
if len(response.choices) > 0:
return response.choices[0].message.content
return "generate answer error"
# 首先定义一个返回默认参数的方法
@property
def _default_params(self) -> Dict[str, Any]:
"""获取调用API的默认参数。"""
normal_params = {
"temperature": self.temperature,
}
# print(type(self.model_kwargs))
return {**normal_params}
@property
def _llm_type(self) -> str:
return "Zhipu"
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model": self.model}, **self._default_params}
使用自定义 LLM 接入 langchain
- 这里没什么新意,只是调用而已,模型采用了glm最新模型。
import sys
sys.path.append("./utils")
import os
from dotenv import load_dotenv, find_dotenv
from zhipuai_llm import ZhipuAILLM
_ = load_dotenv(find_dotenv())
API_KEY=os.environ["ZHIPUAI_API_KEY"]
# 调用智谱ai
zp = ZhipuAILLM(model = "GLM-4-0520", temperature = 0.1, api_key = API_KEY) #model="glm-4",
print(zp("你好,请你介绍一下你的模型代码!"))

2 构建检索问答链
- 在这里,我们将使用搭建好的向量数据库,对 query 查询问题进行召回,并将召回结果和 query 结合起来构建 prompt,输入到大模型中进行问答。
2.1 加载向量数据库
- 在这里,借用上一节的代码加载向量数据库
# 定义embeddings
embedding = ZhipuAIEmbeddings()
# 定义持久化路径
persist_directory = './data_base/vector_db/chroma'
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding # 使用zhipuai的embedding
)
print(f"向量库中存储的数量:{vectordb._collection.count()}")

2.2 创建一个 LLM
- 在这里,使用上一节的自定义智谱AI LLM
2.3 构建检索问答链
- 创建检索 QA 链的方法
RetrievalQA.from_chain_type()有如下参数:llm:指定使用的 LLM- 指定 chain type : RetrievalQA.from_chain_type(chain_type=“map_reduce”),也可以利用load_qa_chain()方法指定chain type。
- 自定义 prompt :通过在RetrievalQA.from_chain_type()方法中,指定chain_type_kwargs参数,而该参数:chain_type_kwargs = {“prompt”: PROMPT}
- 返回源文档:通过RetrievalQA.from_chain_type()方法中指定:return_source_documents=True参数;也可以使用RetrievalQAWithSourceChain()方法,返回源文档的引用(坐标或者叫主键、索引)
# 构建prompt模板
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。可以使用多段话,但是总字数控制在600字以内,保持简明扼要。总是在回答的最后说“很荣幸为您服务!”。
{context}
问题: {question}
"""
# 构建基于prompt模板的问答链
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
qa_chain = RetrievalQA.from_chain_type(zp,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
2.4 检索问答链效果测试
#提问query
question_1 = "什么是期租合同?"
question_2 = "期租合同和程租合同有什么不同?"
#question_3 = "租船合同的谈判是怎么样进行的?"
result = qa_chain({"query": question_1})
print("大模型+知识库后回答 question_1 的结果:")
print(result["result"])
result = qa_chain({"query": question_2})
print("大模型+知识库后回答 question_2 的结果:")
print(result["result"])

question_3 = "租船合同的谈判是怎么样进行的?"
- 下面是基于大模型的回答

- 下面是基于大模型+知识库的回答,可以明显看出,经过 prompt 设计,回答明显简短,但是也因此回答不够全面。由于知识库的加持,回答的内容深度足够,保证了完整性和准确性。

2.5 添加历史对话的记忆功能
- 在与语言模型交互时,会有一个关键问题 - 它们并不记得你之前的交流内容。这带来了很大的挑战,使得对话似乎缺乏真正的连续性。
记忆 Memory
- 介绍 LangChain 中的储存模块,即如何将先前的对话嵌入到语言模型中的,使其具有连续对话的能力。
- 使用
ConversationBufferMemory,它保存聊天消息历史记录的列表,这些历史记录将在回答问题时与问题一起传递给聊天机器人,从而将它们添加到上下文中。
对话检索链
对话检索链(ConversationalRetrievalChain)在检索 QA 链的基础上,增加了处理对话历史的能力。
工作流程
- 将之前的对话与新问题合并生成一个完整的查询语句。
- 在向量数据库中搜索该查询的相关文档。
- 获取结果后,存储所有答案到对话记忆区。
- 用户可在 UI 中查看完整的对话流程。
- 这种链式方式将新问题放在之前对话的语境中进行检索,可以处理依赖历史信息的查询。并保留所有信 息在对话记忆中,方便追踪。
# 记忆对话功能
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)
# 对话检索链
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
zp,
retriever=retriever,
memory=memory
)
question = "我可以学习到关于租船业务的知识吗?"
result = qa({"question": question})
print(result['answer'])
question = "为什么租船业务需要学习这些的知识?"
result = qa({"question": question})
print(result['answer'])


3 部署知识库助手
3.1 Streamlit 简介
Streamlit是一个用于快速创建数据应用程序的开源 Python 库。它的设计目标是让数据科学家能够轻松地将数据分析和机器学习模型转化为具有交互性的 Web 应用程序,而无需深入了解 Web 开发。
- Streamlit 提供了一组简单而强大的基础模块,用于构建数据应用程序:
- st.write():这是最基本的模块之一,用于在应用程序中呈现文本、图像、表格等内容。
- st.title()、st.header()、st.subheader():这些模块用于添加标题、子标题和分组标题,以组织应用程序的布局。
- st.text()、st.markdown():用于添加文本内容,支持 Markdown 语法。
- st.image():用于添加图像到应用程序中。
- st.dataframe():用于呈现 Pandas 数据框。
- st.table():用于呈现简单的数据表格。
- st.pyplot()、st.altair_chart()、st.plotly_chart():用于呈现 Matplotlib、Altair 或 Plotly 绘制的图表。
- st.selectbox()、st.multiselect()、st.slider()、st.text_input():用于添加交互式小部件,允许用户在应用程序中进行选择、输入或滑动操作。
- st.button()、st.checkbox()、st.radio():用于添加按钮、复选框和单选按钮,以触发特定的操作。
3.2 构建应用程序
- 源码来自于 llm-universe https://github.com/datawhalechina/llm-universe/blob/main/notebook/C4%20%E6%9E%84%E5%BB%BA%20RAG%20%E5%BA%94%E7%94%A8/streamlit_app.py
- 只是进行了一些适应性修改
import streamlit as st
# from langchain_openai import ChatOpenAI
import os
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
import sys
sys.path.append("./utils")
from zhipuai_embedding import ZhipuAIEmbeddings
from zhipuai_llm import ZhipuAILLM
from langchain.vectorstores.chroma import Chroma
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
#export OPENAI_API_KEY=
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
def generate_response(input_text, zhipuai_api_key):
llm = ZhipuAILLM(model = "GLM-4-0520", temperature = 0.1, zhipuai_api_key=zhipuai_api_key)
output = llm.invoke(input_text)
output_parser = StrOutputParser()
output = output_parser.invoke(output)
#st.info(output)
return output
def get_vectordb():
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = './data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
return vectordb
#带有历史记录的问答链
def get_chat_qa_chain(question:str,zhipuai_api_key:str):
vectordb = get_vectordb()
# llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0,openai_api_key = openai_api_key)
llm = ZhipuAILLM(model = "GLM-4-0520", temperature = 0.1, zhipuai_api_key=zhipuai_api_key)
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)
result = qa({"question": question})
return result['answer']
#不带历史记录的问答链
def get_qa_chain(question:str,zhipuai_api_key:str):
vectordb = get_vectordb()
llm = ZhipuAILLM(model = "GLM-4-0520", temperature = 0.1, zhipuai_api_key=zhipuai_api_key)
# llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0,openai_api_key = openai_api_key)
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。可以使用多段话,但是总字数控制在600字以内,保持简明扼要。总是在回答的最后说“很荣幸为您服务!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
result = qa_chain({"query": question})
return result["result"]
# Streamlit 应用程序界面
def main():
st.title('🦜🔗 航运租船知识助手')
# openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')
zhipuai_api_key = st.sidebar.text_input('ZhiPu AI API Key', type='password')
#添加一个选择按钮来选择不同的模型
# selected_method = st.sidebar.selectbox("选择模式", ["qa_chain", "chat_qa_chain", "None"])
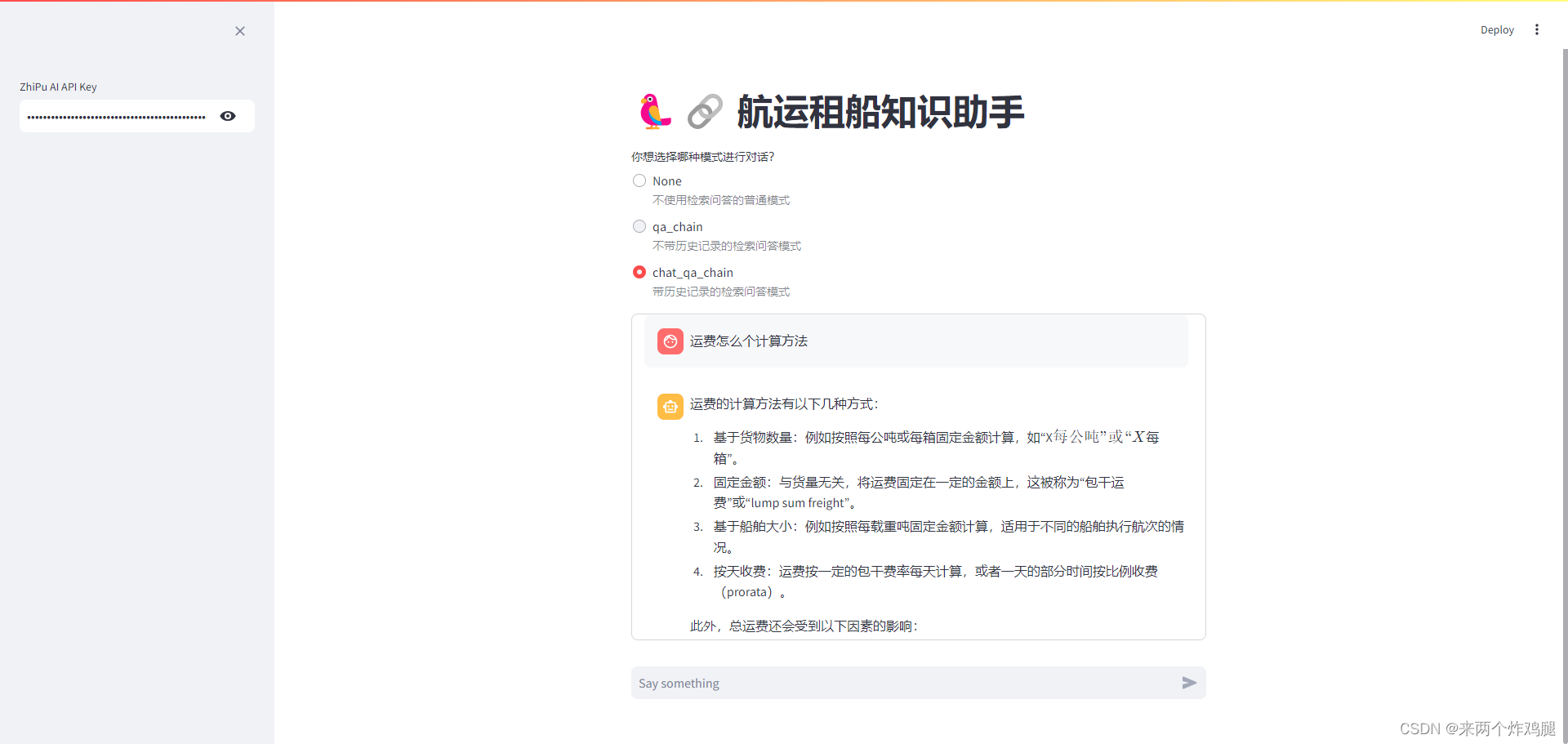
selected_method = st.radio(
"你想选择哪种模式进行对话?",
["None", "qa_chain", "chat_qa_chain"],
captions = ["不使用检索问答的普通模式", "不带历史记录的检索问答模式", "带历史记录的检索问答模式"])
# 用于跟踪对话历史
if 'messages' not in st.session_state:
st.session_state.messages = []
messages = st.container(height=400)
if prompt := st.chat_input("Say something"):
# 将用户输入添加到对话历史中
st.session_state.messages.append({"role": "user", "text": prompt})
if selected_method == "None":
# 调用 respond 函数获取回答
answer = generate_response(prompt, zhipuai_api_key)
elif selected_method == "qa_chain":
answer = get_qa_chain(prompt,zhipuai_api_key)
elif selected_method == "chat_qa_chain":
answer = get_chat_qa_chain(prompt,zhipuai_api_key)
# 调用 respond 函数获取回答
# answer = generate_response(prompt, zhipuai_api_key)
# 检查回答是否为 None
if answer is not None:
# 将LLM的回答添加到对话历史中
st.session_state.messages.append({"role": "assistant", "text": answer})
# 显示整个对话历史
for message in st.session_state.messages:
if message["role"] == "user":
messages.chat_message("user").write(message["text"])
elif message["role"] == "assistant":
messages.chat_message("assistant").write(message["text"])
if __name__ == "__main__":
main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









