







 本文介绍了词向量在NLP中的重要性,展示了其如何通过捕捉语义信息改善检索效果。同时,详细讲解了向量数据库的原理、优势以及主流选项如Weaviate和Qdrant,强调了EmbeddingAPI在构建大模型应用中的实用价值。
本文介绍了词向量在NLP中的重要性,展示了其如何通过捕捉语义信息改善检索效果。同时,详细讲解了向量数据库的原理、优势以及主流选项如Weaviate和Qdrant,强调了EmbeddingAPI在构建大模型应用中的实用价值。
系列文章目录
动手学大模型应用开发第一章:大模型简介
动手学大模型应用开发第二章:使用 LLM API 开发应用
动手学大模型应用开发第三章:搭建知识库
动手学大模型应用开发第四章:构建 RAG 应用
动手学大模型应用开发第五章:系统评估与优化
前言
本文内容来自 https://datawhalechina.github.io/llm-universe
1. 词向量及向量知识库
1.1 词向量
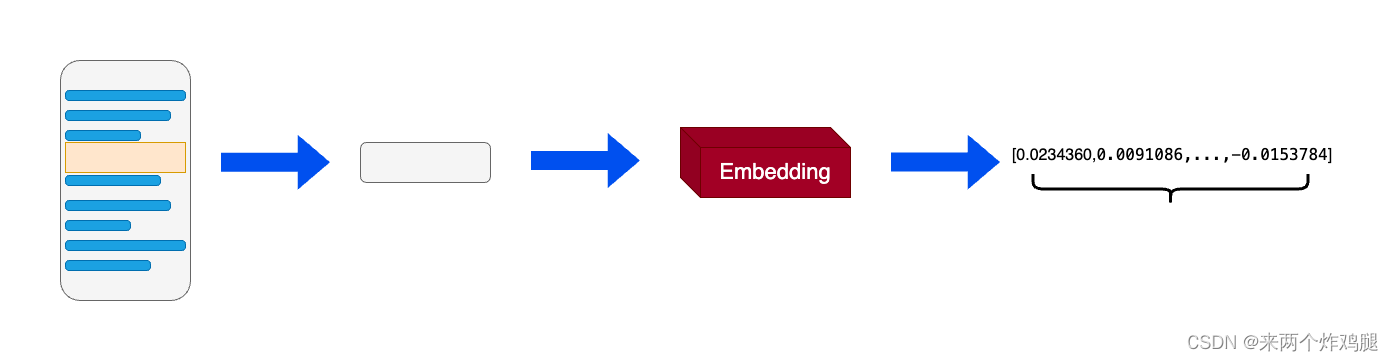
- 在 自然语言处理(NLP) 中,词向量(Embeddings) 是一种将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。
- Embeddings,也可以叫做 嵌入 ,背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。

- 上图为例,使用词嵌入(word embeddings)来表示文本数据。在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。
- 例如,“king” 和 “queen” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的含义相似。而 “apple” 和 “orange” 也会很接近,因为它们都是水果。而 “king” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
1.2 词向量的优势
- 在 RAG(Retrieval Augmented Generation,检索增强生成) 方面词向量的优势主要有两点:
词向量比文字更适合检索
- 当我们在数据库检索时,如果数据库存储的是文字,主要通过检索关键词(词法搜索)等方法找到相对匹配的数据,匹配的程度是取决于关键词的数量或者是否完全匹配查询句的;
- 但是词向量中包含了原文本的语义信息,可以通过计算问题与数据库中数据的 点积、余弦距离、欧几里得距离 等指标,直接获取问题与数据在语义层面上的相似度;
词向量比其它媒介的综合信息能力更强
- 当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;但是词向量却可以通过多种向量模型将多种数据映射成统一的向量形式。
1.3 一般构建词向量的方法
- 在搭建 RAG 系统时,可以通过使用嵌入模型来构建词向量,通常选择:
- 使用各个公司的 Embedding API;
- 在本地使用嵌入模型将数据构建为词向量。
2. 向量数据库
2.1 向量数据库介绍
-
向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是 向量数据的特性和相似性。
-
在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
2.2 向量数据库的原理及核心优势
- 向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索。
- 向量数据库通过计算与目标向量的余弦距离、点积等获取与目标向量的相似度。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
- 向量数据库是用于高效计算和管理大量向量数据的解决方案。
2.3 主流的向量数据库
Chroma
- 一个轻量级向量数据库,拥有丰富的功能和简单的 API,具有简单、易用、轻量的优点,但功能相对简单且不支持GPU加速,适合初学者使用。
Weaviate
- 一个开源向量数据库。除了支持相似度搜索和最大边际相关性(MMR,Maximal Marginal Relevance)搜索外还可以支持结合多种搜索算法(基于词法搜索、向量搜索)的混合搜索,从而搜索提高结果的相关性和准确性。
Qdrant
- 使用 Rust 语言开发,有极高的检索效率和RPS(Requests Per Second),支持本地运行、部署在本地服务器及Qdrant云三种部署模式。且可以通过为页面内容和元数据制定不同的键来复用数据。
3. 使用 Embedding API
3.1 使用智谱 AI
- 智谱有封装好的 SDK,直接调用即可。
代码片段
def get_embedding(text: str):
'''
智谱的Embedding调用接口
'''
response = client.embeddings.create(
model="embedding-2",
input=text,
)
return response
4. 数据处理
4.1 源文档选取
- 这里选取的 16个md文档,内容均是与租船业务相关。

4.2 数据读取
- 这里主要使用markdown读取
代码片段
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
def get_md_pages(file_path):
"""
获取md文件内容
"""
loader = UnstructuredMarkdownLoader(file_path)
md_pages = loader.load()
return md_pages
4.3 数据清洗
- 让数据尽量保持有序、优质、精简
- 但是也要分析具体文档中的字符来决定如何处理
代码片段
import re
def text_re(text):
'''
文本清洗
'''
# 使用正则删除换行符
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), text)
# 去掉 ![[Pastedimage20230606134554.png]]! ,即粘贴的图片
pattern = r'!\[\[Pasted\s+image\s+\d{14}\.png\]\]'
content = re.sub(pattern, '', text)
return content
def text_clean(text):
# 使用 replace 函数删除空格
content = text.replace(' ', '')
# 使用 replace 函数替换连续两个换行符
content = content.replace('\n\n', '')
# 使用 replace 函数替换制表符
content = content.replace('\t', '')
return content
4.4 文档分割
由于单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此,在构建向量知识库的过程中,往往需要对文档进行分割。
- 将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
- 在检索时,会以
chunk作为检索的元单位,也就是每一次检索到k个chunk作为模型可以参考来回答用户问题的知识,这个k是我们可以自由设定的。
Langchain 切分文本示例

-
chunk_size指每个块包含的字符或 Token (如单词、句子等)的数量 -
chunk_overlap指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息。 -
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
- RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter(): 按字符来分割文本。
- MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
- TokenTextSplitter(): 按token来分割文本。
- SentenceTransformersTokenTextSplitter(): 按token来分割文本
- Language(): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
代码片段
from langchain.text_splitter import RecursiveCharacterTextSplitter
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),
这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:
* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
# 知识库中单段文本长度
CHUNK_SIZE = 300
# 知识库中相邻文本重合长度
OVERLAP_SIZE = 30
def get_splitted_text(text, chunk_size = CHUNK_SIZE, chunk_overlap = OVERLAP_SIZE):
'''
文本切割函数,返回分割后的文本
文本块大小,文本重叠度如果不指定则采用默认值
'''
# 使用递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
return text_splitter.split_text(text)
def get_splitted_docs(documents, chunk_size = CHUNK_SIZE, chunk_overlap = OVERLAP_SIZE):
'''
切分文档集合函数,返回分割后的文档集合
'''
#使用递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
return text_splitter.split_documents(documents)
5. 搭建向量数据库
5.2 构建 Chroma 向量数据库
- 将以上的数据处理步骤执行一遍,然后实例化 Chroma,将处理过的数据经过大模型的 embedding 模型转化为向量,持久化到硬盘上。
代码片段
import sys
sys.path.append("./utils")
import os
from markdownReader import get_md_pages
from dataProcess import text_re, text_clean
from textSplitter import get_splitted_docs
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain_community.vectorstores.chroma import Chroma
ASSETS_PATH = "./assets"
md_pages = []
# 循环读取目录下所有md文件,并保存到 md_pages 中
for root, dir, files in os.walk(ASSETS_PATH):
for file in files:
print(os.path.join(root, file)) # 打印文件名
# 读取 Markdown,保存到 md_pages
md_pages.append(get_md_pages(os.path.join(root, file))[0])
print(f"载入后的变量类型为:{type(md_pages)},", f"该 Markdown 一共包含 {len(md_pages)} 页")
# 读取最后一个md文档
# md_page = md_pages[-1]
# print(f"每一个元素的类型:{type(md_page)}.",
# f"该文档的描述性数据:{md_page.metadata}",
# f"查看该文档的内容:\n{md_page.page_content[0:][:200]}",
# sep="\n------\n")
# 文档清洗
for md_page in md_pages:
md_page.page_content = text_re(md_page.page_content)
md_page.page_content = text_clean(md_page.page_content)
# print(f"每一个元素的类型:{type(md_page)}.",
# f"该文档的描述性数据:{md_page.metadata}",
# f"查看该文档的内容:\n{md_page.page_content}",
# sep="\n------\n")
docs = get_splitted_docs(md_pages)
print(f"切分后的文件数量:{len(docs)}")
print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in docs])}")
# 定义embeddings
embedding = ZhipuAIEmbeddings()
# 定义持久化路径
persist_directory = './data_base/vector_db/chroma'
vectordb = Chroma.from_documents(
documents=docs,
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
vectordb.persist()
print(f"向量库中存储的数量:{vectordb._collection.count()}")

6 使用向量数据库
6.1 加载持久化的向量数据库
- 这里直接使用上面已经数据持久化后的向量数据库
代码片段
import sys
sys.path.append("./utils")
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain_community.vectorstores import Chroma
# 定义embeddings
embedding = ZhipuAIEmbeddings()
# 定义持久化路径
persist_directory = './data_base/vector_db/chroma'
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding # 使用zhipuai的embedding
)
# print(vectordb._collection.count())
5.3 向量检索
相似度检索
-
Chroma的相似度搜索使用的是余弦距离,即:
s i m i l a r i t y = c o s ( A , B ) = A ⋅ B ∥ A ∥ ∥ B ∥ = ∑ 1 n a i b i ∑ 1 n a i 2 ∑ 1 n b i 2 similarity = cos(A, B) = \frac{A \cdot B}{\parallel A \parallel \parallel B \parallel} = \frac{\sum_1^n a_i b_i}{\sqrt{\sum_1^n a_i^2}\sqrt{\sum_1^n b_i^2}} similarity=cos(A,B)=∥A∥∥B∥A⋅B=∑1nai2∑1nbi2∑1naibi -
其中 a i a_i ai、 b i b_i bi分别是向量 A A A、 B B B的分量。
-
当需要数据库返回严谨的按余弦相似度排序的结果时可以使用
similarity_search函数。
代码片段
# 提问的query
question="什么是租船"
# 进行向量相似度检索
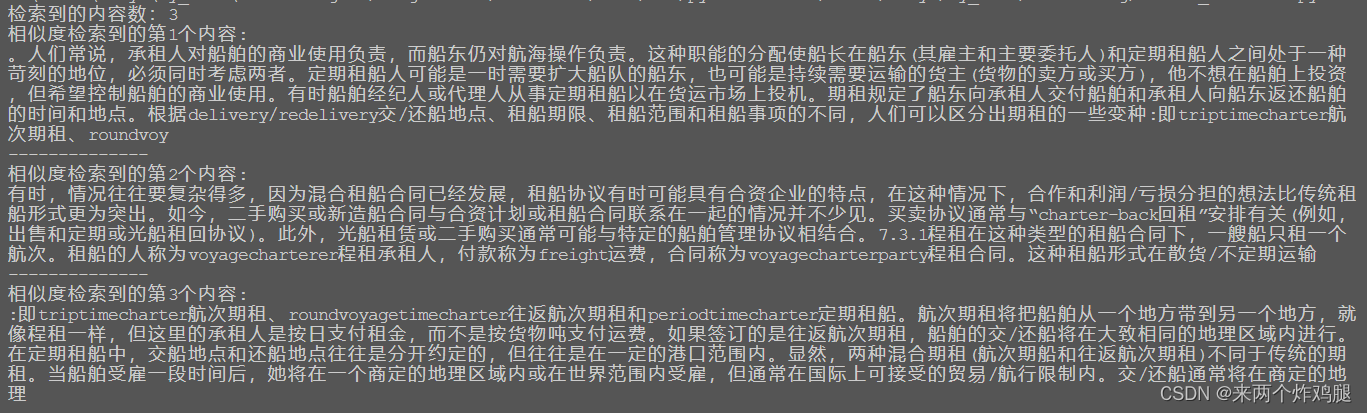
sim_docs = vectordb.similarity_search(question,k=3) # 设置k=3,取三个检索结果
print(f"相似度检索到的内容数:{len(sim_docs)}")
for i, sim_doc in enumerate(sim_docs):
print(f"相似度检索到的第{i+1}个内容: \n{sim_doc.page_content}", end="\n--------------\n")
MMR 检索
-
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。
-
最大边际相关性 (
MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。 -
核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。
代码片段
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3)
print(f"MMR 检索到的内容数:{len(mmr_docs)}")
for i, sim_doc in enumerate(mmr_docs):
print(f"MMR 检索到的第{i+1}个内容: \n{sim_doc.page_content}", end="\n--------------\n")

总结
- 本章认识了词向量和向量数据库,在NLP领域,embeddings 是一个极其重要的概念,正是词向量的提出改变了机器学习时代NLP的词表示方法,是大模型产生的前提。
- 向量数据库则是一个新颖的事物,众所周知,词向量会是一组连续稠密的低维向量,借助于预训练的大模型所拥有的嵌入模型,将文字进行 embeddings 并保存到向量数据库,做到随取随用。
- 如何进行向量之间的搜索匹配呢,这里采用了余弦相似度和最大编辑相关性两种算法。















 2750
2750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









