






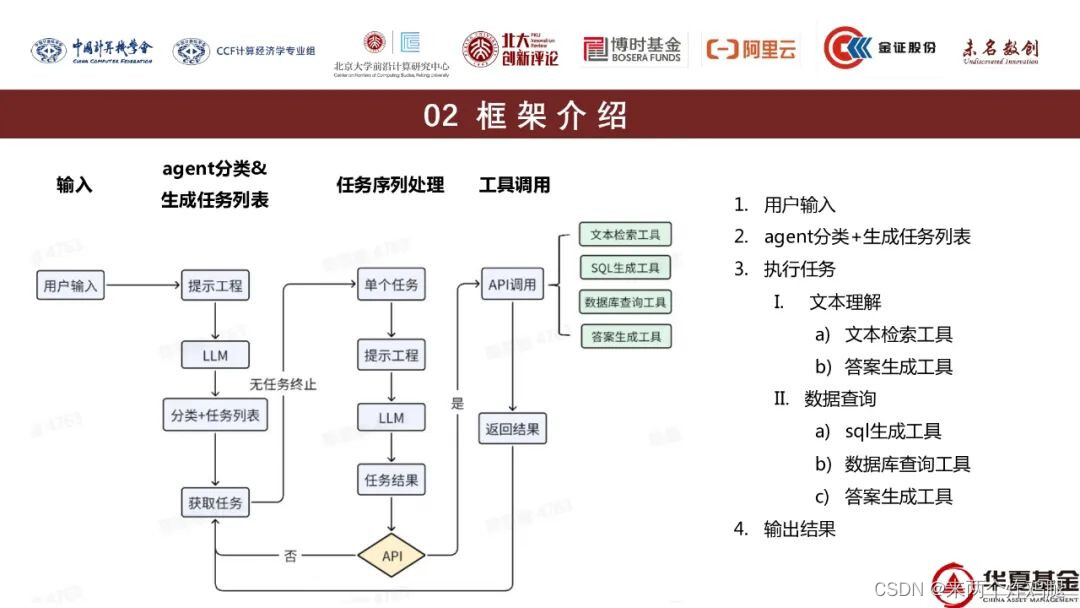
 本文介绍了ChatGLM大模型及其API在Python中的应用,重点讨论了如何通过同步和异步调用来创建正则表达式Agent,以及如何结合数据库解析,展示如何使用SQLAgent进行SQL查询。
本文介绍了ChatGLM大模型及其API在Python中的应用,重点讨论了如何通过同步和异步调用来创建正则表达式Agent,以及如何结合数据库解析,展示如何使用SQLAgent进行SQL查询。
文章目录
任务1 初始大模型与 Agent
大模型介绍
- GLM 是智谱AI推出的新一代基座大模型,相比上一代有着显著提升的性能,逼近 GPT-4。
- GLM 支持更长的上下文(128k),具备强大的多模态能力,并且推理速度更快,支持更高的并发。
- GLM 的 API 接口为开发者提供了在自己应用中利用 GLM 进行语言生成的机会,为多种领域的任务提供了新的解决方案。
ChatGLM
- 官网: https://open.bigmodel.cn/
- API 文档:https://open.bigmodel.cn/dev/api
- API 计费说明:https://open.bigmodel.cn/pricing
Agent 介绍
- 大模型的 Agent 指的是以大型语言模型 (如 GPT-3、GPT-4 等) 为核心,构建的具有一定自主性和智能的软件实体。
- 这些 Agent 能够执行多种任务,包括但不限于自然语言处理、决策制定、任务规划和执行等。
特点
- 上下文学习能力
- 推理能力
- 任务规划与执行
- 自然语言交互
- 自主智能
- 多模态能力
任务2 ChatGLM API - Python
- 这里采用
GLM-3-Turbo
同步调用
- 接口请求
| 传输方式 | https |
| 请求地址 | https://open.bigmodel.cn/api/paas/v4/chat/completions |
| 调用方式 | 同步调用,等待模型执行完成并返回最终结果或 SSE 调用 |
| 字符编码 | UTF-8 |
| 接口请求格式 | JSON |
| 响应格式 | JSON 或标准 Stream Event |
| 接口请求类型 | POST |
| 开发语言 | 任意可发起 HTTP 请求的开发语言 |
- 接口请求参数
| 参数名称 | 类型 | 是否必填 | 参数说明 |
|---|---|---|---|
| model | String | 是 | 所要调用的模型编码 |
| messages | List | 是 | 调用语言模型时,将当前对话信息列表作为提示输入给模型, 按照 {"role": "user", "content": "你好"} 的json 数组形式进行传参; 可能的消息类型包括 System message、User message、Assistant message 和 Tool message。 |
| request_id | String | 否 | 由用户端传参,需保证唯一性;用于区分每次请求的唯一标识,用户端不传时平台会默认生成。 |
| do_sample | Boolean | 否 | do_sample 为 true 时启用采样策略,do_sample 为 false 时采样策略 temperature、top_p 将不生效 |
| stream | Boolean | 否 | 使用同步调用时,此参数应当设置为 fasle 或者省略。表示模型生成完所有内容后一次性返回所有内容。 如果设置为 true,模型将通过标准 Event Stream ,逐块返回模型生成内容。Event Stream 结束时会返回一条 data: [DONE]消息。注意:在模型流式输出生成内容的过程中,我们会分批对模型生成内容进行检测,当检测到违法及不良信息时,API会返回错误码(1301)。开发者识别到错误码(1301),应及时采取(清屏、重启对话)等措施删除生成内容,避免其造成负面影响。 |
| temperature | Float | 否 | 采样温度,控制输出的随机性,必须为正数 取值范围是: (0.0, 1.0],不能等于 0,默认值为 0.95,值越大,会使输出更随机,更具创造性;值越小,输出会更加稳定或确定建议您根据应用场景调整 top_p 或 temperature 参数,但不要同时调整两个参数 |
| top_p | Float | 否 | 用温度取样的另一种方法,称为核取样 取值范围是: (0.0, 1.0) 开区间,不能等于 0 或 1,默认值为 0.7 模型考虑具有 top_p 概率质量tokens的结果 例如:0.1 意味着模型解码器只考虑从前 10% 的概率的候选集中取tokens 建议您根据应用场景调整 top_p 或 temperature 参数,但不要同时调整两个参数 |
| max_tokens | Integer | 否 | 模型输出最大 tokens,最大输出为 8192,默认值为 1024 |
| stop | List | 否 | 模型在遇到 stop 所制定的字符时将停止生成,目前仅支持单个停止词,格式为["stop_word1"] |
| tools | List | 否 | 可供模型调用的工具列表, tools 字段会计算 tokens ,同样受到 tokens 长度的限制 |
| tool_choice | String 或 Object | 否 | 用于控制模型是如何选择要调用的函数,仅当工具类型为 function 时补充。默认为 auto,当前仅支持 auto。 |
异步调用
- 接口请求
| 传输方式 | https |
| 请求地址 | https://open.bigmodel.cn/api/paas/v4/async/chat/completions |
| 调用方式 | 异步调用,需通过查询接口获取结果 |
| 字符编码 | UTF-8 |
| 接口请求格式 | JSON |
| 响应格式 | JSON |
| 接口请求类型 | POST |
| 开发语言 | 任意可发起 http 请求的开发语言 |
-
接口请求参数 - 与同步调用的接口请求参数相同
-
接口响应参数
| 参数名称 | 类型 | 参数说明 |
|---|---|---|
| request_id | String | 用户在客户端请求时提交的任务编号或者平台生成的任务编号 |
| id | String | 智谱 AI 开放平台生成的任务订单号,调用请求结果接口时请使用此订单号 |
| model | String | 本次调用的模型名称 |
| task_status | String | 处理状态,PROCESSING(处理中),SUCCESS(成功),FAIL(失败)。需通过查询获取结果 |
正则表达式 Agent
- Prompt Engineering 是指在 NLP 中,特别是在使用预训练语言模型时,设计和优化 输入 即提示 以引导模型产生期望的输出的过程。
- 构建 Agent 时可能会用到提示工程的技术,提示工程是实现 Agent 功能的一部分。
- 提示工程的关键在于如何构造问题或指令,是的模型能够理解并生成转却、相关和有用的回答或内容。
具体任务
- 使用GLM API完成正则表达式Agent:
- 编写prompt能写一个能识别首字母大写单词的正则。
- 编写prompt让ChatGPT写一个能识别首字母大写且字符个数小于10的正则。
- 编写prompt让ChatGPT写一个能识别单词末尾为标点符号的正则。
- 通过Python代码验证正则的有效性。
- 以下为部分代码
def ask_glm(question, nretry=5):
if nretry == 0:
return None
client = ZhipuAI(api_key=api_key)
try:
response = client.chat.completions.create(
model = m3, # 模型名称
messages=[
{"role": "user", "content": question}
],
)
return response
except:
return ask_glm(question, nretry-1)
def regex_agent(question):
prompt_template = '''你是一个专业的python的工程师,擅长编写各种的正则表达式。将下面的要求转换为正则匹配表达式,只需要输出表达式,不要有其他的输出。
{0}
'''.format(question)
return ask_glm(prompt_template).choices[0].message.content
def remove_spec_char(s, char):
# 去除字符串前后的特定字符
return s.strip(char)
if __name__ == "__main__":
regex1 = regex_agent("识别首字母大写单词的正则")
regex2 = regex_agent("识别首字母大写且字符个数小于10的正则")
regex3 = regex_agent("识别单词末尾为标点符号的正则")
regex1 = remove_spec_char(regex1, '```')
regex2 = remove_spec_char(regex2, '```')
print(regex1)
print(regex2)
print(regex3)
# 待验证的string
str1 = 'This is a Unbelieveable Test sentence.'
result1 = re.findall(regex1, str1)
result2 = re.findall(regex2, str1)
result3 = re.findall(regex3, str1)
print(result1)
print(result2)
print(result3)
- 生成的正则结果,清除了前后特殊字符:
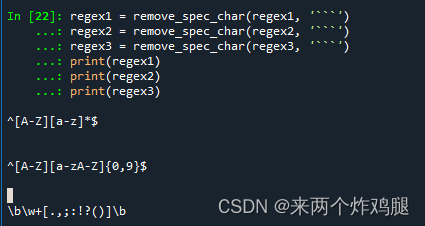
- 跑了四次,模型生成的正则正确率不高

任务3 数据库内容解析
数据库是存储、检索和管理数据的系统化方式。它允许用户和应用程序以结构化的形式存储大量数据,并能够高效地查询和操作这些数据。
- 数据模型: 定义数据的结构和存储方式。常见的数据模型有关系模型、如 SQL 数据库,文档模型、如 MongoDB,键值存储模型、如 Redis,图形模型、如 Neo4j 等。
- 数据库管理系统: DBMS 是软件,提供了创建、管理和操作数据库所需的工具和服务。允许用户执行各种 CRUD 操作。流行的 DBMS: MySQL、PostgreSQL、Oracle、SQL Server、SQLite。
- 数据表和字段:在关系型数据库中,数据通常存储在表中,表由 行(记录) 和 列(字段) 组成。每个字段都有一个特定的数据类型,如证书、字符串、日期等。
- 索引:数据库中的一种结构,它可以加快数据检索速度。类似于书籍的目录,允许数据库系统快速定位到特定的数据记录。
- 对数据库进行解析通常涉及一下几个步骤:
- 连接数据库:使用数据库链接库来建立连接,需提供数据库地址、端口、用户名、密码登
- 检索数据库模式:使用 SQL 查询来获取数据库的模式信息,这可能包括表明、列名、数据类型、索引、外键约束等。
- 分析查询结果:对检索到的模式信息进行分析,以便理解数据库的结构;涉及到解析 SQL 查询的结果集,提取表和列的元数据。
- 构建数据模型:根据解析出的数据库模式,构建数据模型,这可以是 对象关系映射 ORM 模型,也可以是其他形式的数据结构;数据模型应该呢我能够反映出数据库中的关系和数据类型。
- 执行查询:使用构建的数据模型来执行具体的 SQL 查询。
- 处理查询结果:分析和处理查询结果,这可能包括 ETL,将结果转换为应用程序或用户所需的格式。
-
如果对单张表格进行解析,可以解析列名和类型。
-
接着对每个字段执行一系列统计操作。这些操作包括计算唯一值的数量(
distinct_count),确定最频繁出现的值(mode),统计缺失值(nan_count),以及获取最大值(max)和最小值(min)。 -
整体代码如下:
'''数据库解析'''
from typing import Union # 类型注解库
import traceback # 打印或检索堆栈回溯
from sqlalchemy import create_engine, inspect, func, select, Table, MetaData
import pandas as pd
class DBParser:
'''DBParser'''
def __init__(self, db_url:str) -> None:
'''初始化
db_url: 数据库链接地址
'''
# 判断数据库类型
if 'sqlite' in db_url:
self.db_type = 'sqlite'
elif 'mysql' in db_url:
self.db_type = 'mysql'
# 链接数据库
self.engine = create_engine(db_url, echo=False)
self.conn = self.engine.connect()
self.db_url = db_url
# 查看表明
self.inspector = inspect(self.engine)
self.table_names = self.inspector.get_table_names()
self._table_fields = {} # 数据表字段
self.foreign_keys = [] # 数据库外键
self._table_sample = {} # 数据表样例
# 依次对每张表的字段进行统计
for table_name in self.table_names:
print("Table ->", table_name)
self._table_fields[table_name] = {}
# 累计外键
self.foreign_keys += [
{
'constrained_table': table_name,
'constrained_columns': x['constrained_columns'],
'referred_table': x['referred_table'],
'referred_columns': x['referred_columns'],
} for x in self.inspector.get_foreign_keys(table_name)
]
# 获取当前表的字段信息
table_instance = Table(table_name, MetaData(), autoload_with=self.engine)
table_columns = self.inspector.get_columns(table_name)
self._table_fields[table_name] = {x['name']:x for x in table_columns}
# 对当前字段进行统计
for column_meta in table_columns:
# 获取当前字段
column_instance = getattr(table_instance.columns, column_meta['name'])
# 统计unique
query = select(func.count(func.distinct(column_instance)))
distinct_count = self.conn.execute(query).fetchone()[0]
self._table_fields[table_name][column_meta['name']]['distinct'] = distinct_count
# 统计most frequency value
field_type = self._table_fields[table_name][column_meta['name']]['type']
field_type = str(field_type)
if 'text' in field_type.lower() or 'char' in field_type.lower():
query = (
select([column_instance, func.count().label('count')])
.group_by(column_instance)
.order_by(func.count().desc())
.limit(1)
)
top1_value = self.conn.execute(query).fetchone()[0]
self._table_fields[table_name][column_meta['name']]['mode'] = top1_value
# 统计missing个数
query = select(func.count()).filter(column_instance == None)
nan_count = self.conn.execute(query).fetchone()[0]
self._table_fields[table_name][column_meta['name']]['nan_count'] = nan_count
# 统计max
query = select(func.max(column_instance))
max_value = self.conn.execute(query).fetchone()[0]
self._table_fields[table_name][column_meta['name']]['max'] = max_value
# 统计min
query = select(func.min(column_instance))
min_value = self.conn.execute(query).fetchone()[0]
self._table_fields[table_name][column_meta['name']]['min'] = min_value
# 任意取值
query = select(column_instance).limit(10)
random_value = self.conn.execute(query).all()
random_value = [x[0] for x in random_value]
random_value = [str(x) for x in random_value if x is not None]
random_value = list(set(random_value))
self._table_fields[table_name][column_meta['name']]['random'] = random_value[:3]
# 获取表样例(第一行)
query = select([table_instance])
self._table_sample[table_name] = pd.DataFrame([self.conn.execute(query).fetchone()])
self._table_sample[table_name].columns = [x['name'] for x in table_columns]
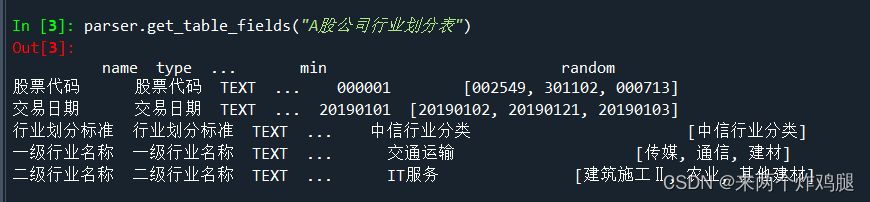
def get_table_fields(self, table_name) -> pd.DataFrame:
'''获取表字段信息'''
return pd.DataFrame.from_dict(self._table_fields[table_name]).T
def get_data_relations(self) -> pd.DataFrame:
'''获取数据库链接信息(主键和外键)'''
return pd.DataFrame(self.foreign_keys)
def get_table_sample(self, table_name) -> pd.DataFrame:
'''获取数据表样例'''
return self._table_sample[table_name]
def check_sql(self, sql) -> Union[bool, str]:
'''检查sql是否合理
参数
sql: 待执行句子
返回: 是否可以运行 报错信息
'''
try:
self.engine.execute(sql)
return True, 'ok'
except:
err_msg = traceback.format_exc()
return False, err_msg
def execute_sql(self, sql) -> bool:
'''运行SQL'''
result = self.engine.execute(sql)
return list(result)
if __name__ == '__main__':
parser = DBParser('sqlite:///./bs_challenge_financial_14b_dataset/dataset/博金杯比赛数据.db')
- 查看数据表名

SQL Agent
- 创建一个 sql agent
def sql_agent(table_name, table_info, question):
prompt_template = '''你是一个sql专家,基于已有的表格信息,请将下面的问题转换为sql查询语句。直接输出sql,不要输出其他内容。
表名称:{0}
表格信息:
{1}
待查询问题:{2}
'''.format(table_name, table_info, question)
return ask_glm(prompt_template)['choices'][0]['message']['content']
if __name__ == '__main__':
sql = sql_agent(
"A股公司行业划分表",
parser.get_table_fields("A股公司行业划分表").to_markdown(),
'查询下总共有多少个股票'
)
sql = sql.replace('```sql', '').replace('```', '').strip()

















 3164
3164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









