






前言
构建一种基于Raft一致性算法的分布式键值存储数据库,以确保数据的一致性、可用性和分区容错性
部分参考etcd存储引擎
etcd源码
etcd源码介绍
Raft算法参考
两万字长文解析raft算法原理
一、项目大纲

- raft节点:raft算法实现的核心层,负责与其他机器的raft节点沟通,达到 分布式共识 的目的。
- raftServer:负责raft节点与k-v数据库中间的协调服务;负责持久化k-v数据库的数据(可选)。
- 上层状态机(k-v数据库):负责数据存储。
- 持久层:负责相关数据的落盘,对于raft节点,根据共识算法要求,必须对一些关键数据进行落盘处理,以保证节点宕机后重启程序可以恢复关键数据;对于raftServer,可能会有一些k-v数据库的东西需要落盘持久化。
- RPC通信:在 领导者选举、日志复制、数据查询、心跳等多个Raft重要过程中提供多节点快速简单的通信能力。
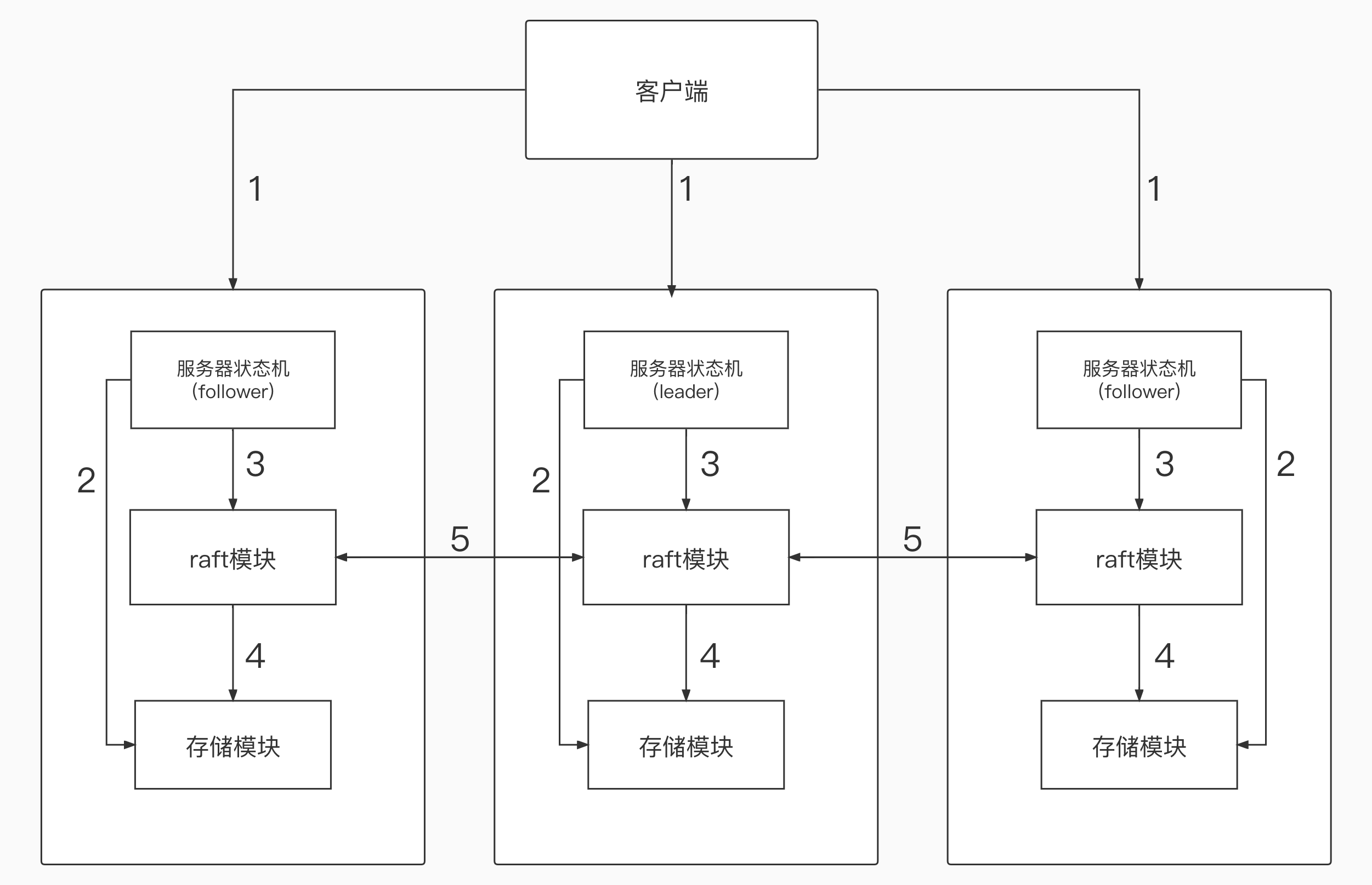
其中图中的数字表示不同模块相互通信、进行数据交互的方式
- 客户端可以访问集群中的任一节点,当访问到 leader节点时,可以进行正常读写操作;当访问到 follower节点时,会返回 leader节点的信息,并通过返回的信息访问 leader节点;
- 状态机读取存储模块的快照(snapshot)从而决定返回哪种状态的存储信息;
- 状态机启动raft模块,并通过获取raft模块的状态来决定需要返回的信息;
- raft模块调用存储模块进行持久化存储,并在存储模块保存自身信息;
- 各个节点的 raft模块相互间可以通过 RPC的方式进行通信,其中 leader模块需要用 follower模块进行心跳通信。
二、Raft模块
1.Raft介绍
参考
文章: 两万字长文解析raft算法原理
视频: 解析分布式共识算法之Raft算法
本项目用Raft解决的问题:
- 一致性: 通过Raft算法确保数据的强一致性,使得系统在正常和异常情况下都能够提供一致的数据视图。
- 可用性: 通过分布式节点的复制和自动故障转移,实现高可用性,即使在部分节点故障的情况下,系统依然能够提供服务。
- 分区容错: 处理网络分区的情况,确保系统在分区恢复后能够自动合并数据一致性。
2.大致内容
详细的看上面参考网站
Leader与选举
Raft是一个强Leader 模型,可以粗暴理解成Leader负责统领follower,如果Leader出现故障,那么整个集群都会对外停止服务,直到选举出下一个Leader。
- 节点之间通过网络通信,其他节点(follower)如何知道leader出现故障?
leader会定时向集群中剩下的节点(follower)发送AppendEntry(作为心跳,hearbeat )以通知自己仍然存活。
可以推知,如果follower在一段时间内没有接收leader发送的AppendEntry,那么follower就会认为当前的leader 出现故障,从而发起选举。
判断心跳超时,可以用一个定时器和一个标志位来实现,每到定时时间检查这期间有无AppendEntry即可。 - AppendEntry作用
- 心跳
- 携带日志entry及其辅助信息,以控制日志的同步和日志向状态机提交
- 通告leader的index和term等关键信息以便follower对比确认follower自己或者leader是否过期
- follower知道leader出现故障后如何选举出leader?
follower认为leader故障后只能通过:term增加,变成candidate,向其他节点发起RequestVoteRPC申请其他follower的选票,过一段时间之后会发生如下情况:- 赢得选举,马上成为leader (此时term已经增加了)
- 发现有符合要求的leader,自己马上变成follower 了,这个符合要求包括:leader的term≥自己的term
- 一轮选举结束,无人变成leader,那么循环这个过程
- 为了防止在同一时间有太多的follower转变为candidate导致一直无法选出leader, Raft 采用了随机选举超时(randomized election timeouts)的机制, 每一个candidate 在发起选举后,都会随机化一个新的选举超时时间。
- 符合什么条件的节点可以成为leader?
也可以称为“选举限制”,有限制的目的是为了保证选举出的 leader 一定包含了整个集群中目前已 committed 的所有日志。
当 candidate 发送RequestVoteRPC时,会带上最后一个 entry 的信息。 所有的节点收到该请求后,都会比对自己的日志,如果发现自己的日志更新一些,则会拒绝投票给该 candidate。
需要比较两个东西:最新日志entry的term和对应的index。index为日志entry在整个日志的索引。
if 两个节点最新日志entry的term不同
term大的日志更新
else
最新日志entry的index大的更新
end
这样的限制可以保证:成为leader的节点,其日志已经是多数节点中最完备的,即包含了整个集群的所有 committed entries。
日志同步、心跳
在RPC中 日志同步 和 心跳 是放在一个RPC函数AppendEntryRPC中来实现的,原因为:
- 心跳RPC 可以看成是没有携带日志的特殊的日志同步RPC。
- 对于一个follower,如果leader认为其日志已经和自己匹配了,那么在
AppendEntryRPC中不用携带日志(再携带日志属于无效信息了,但其他信息依然要携带),反之如果follower的日志只有部分匹配,那么就需要在AppendEntryRPC中携带对应的日志。
- 为什么不直接让follower拷贝leader的日志 或者 leader发送全部的日志给follower?
leader发送日志的目的是让follower同步自己的日志,当然可以让leader发送自己全部的日志给follower,然后follower接收后就覆盖自己原有的日志,但是这样就会携带大量的无效的日志(因为这些日志follower本身就有)。
因此raft的方式是:先找到日志不匹配的那个点,然后只同步那个点之后的日志。 - leader如何知道follower的日志是否与自己完全匹配?
在AppendEntryRPC中携带上 entry的index和对应的term(日志的term),可以通过比较最后一个日志的index和term来得出某个follower日志是否匹配。 - 如果发现不匹配,那么如何知道哪部分日志是匹配的,哪部分日志是不匹配的呢?
leader每次发送AppendEntryRPC后,follower都会根据其entry的index和对应的term来判断某一个日志是否匹配。
在leader刚当选,会从最后一个日志开始判断是否匹配,如果匹配,那么后续发送AppendEntryRPC就不需要携带日志entry了。
如果不匹配,那么下一次就发送 倒数第2个 日志entry的index和其对应的term来判断匹配,
如果还不匹配,那么依旧重复这个过程,直到遇到一个匹配的日志。
raft日志的两个特点
- 两个节点的日志中,有两个 entry 拥有相同的 index 和 term,那么它们一定记录了相同的内容/操作,即两个日志匹配
- 两个节点的日志中,有两个 entry 拥有相同的 index 和 term,那么它们前面的日志entry也相同
- 如何保证?
- 保证第一点:仅有 leader 可以生成 entry,保证一致性
- 保证第二点:leader 在通过
AppendEntriesRPC和 follower 通讯时,除了带上自己的term等信息外,还会带上entry的index和对应的term等信息,follower在接收到后通过对比就可以知道自己与leader的日志是否匹配,不匹配则拒绝请求。
leader发现follower拒绝后就知道entry不匹配,那么下一次就会尝试匹配前一个entry,直到遇到一个entry匹配,并将不匹配的entry给删除(覆盖)。
3.主要流程
1. raft类的定义
class Raft :
{
private:
std::mutex m_mtx;
std::vector<std::shared_ptr< RaftRpc >> m_peers; //需要与其他raft节点通信,这里保存与其他结点通信的rpc入口
std::shared_ptr<Persister> m_persister; //持久化层,负责raft数据的持久化
int m_me; //raft是以集群启动,这个用来标识自己的的编号
int m_currentTerm; //记录当前的term
int m_votedFor; //记录当前term给谁投票过
std::vector<mprrpc:: LogEntry> m_logs; 日志条目数组,包含了状态机要执行的指令集,以及收到领导时的任期号
// 这两个状态所有结点都在维护,易失
int m_commitIndex;
int m_lastApplied; // 已经汇报给状态机(上层应用)的log 的index
// 这两个状态是由leader来维护,易失 ,这两个部分在内容补充的部分也会再讲解
// 这两个状态的下标1开始,因为通常commitIndex和lastApplied从0开始,应该是一个无效的index,因此下标从1开始
std::vector<int> m_nextIndex; //领导者使用 m_nextIndex 来确定需要发送给追随者的下一批日志条目。
std::vector<int> m_matchIndex; //追随者使用 m_matchIndex 来记录已经成功复制的日志条目,并向领导者发送确认信息。
enum Status
{
Follower,
Candidate,
Leader
};
// 保存当前身份
Status m_status;
std::shared_ptr<LockQueue<ApplyMsg>> applyChan; // client从这里取日志,client与raft通信的接口
// ApplyMsgQueue chan ApplyMsg // raft内部使用的chan,applyChan是用于和服务层交互,最后好像没用上
// 选举超时
std::chrono::_V2::system_clock::time_point m_lastResetElectionTime;
// 心跳超时,用于leader
std::chrono::_V2::system_clock::time_point m_lastResetHearBeatTime;
// 用于传入快照点
// 储存了快照中的最后一个日志的Index和Term
int m_lastSnapshotIncludeIndex;
int m_lastSnapshotIncludeTerm;
public:
void AppendEntries1(const mprrpc::AppendEntriesArgs *args, mprrpc::AppendEntriesReply *reply); //日志同步 + 心跳 rpc ,重点关注
void applierTicker(); //定期向状态机写入日志,非重点函数
bool CondInstallSnapshot(int lastIncludedTerm, int lastIncludedIndex, std::string snapshot); //快照相关,非重点
void doElection(); //发起选举
void doHeartBeat(); //leader定时发起心跳
// 每隔一段时间检查睡眠时间内有没有重置定时器,没有则说明超时了
// 如果有则设置合适睡眠时间:睡眠到重置时间+超时时间
void electionTimeOutTicker(); //监控是否该发起选举了
std::vector<ApplyMsg> getApplyLogs();
int getNewCommandIndex();
void getPrevLogInfo(int server, int *preIndex, int *preTerm);
void GetState(int *term, bool *isLeader); //看当前节点是否是leader
void InstallSnapshot( const mprrpc::InstallSnapshotRequest *args, mprrpc::InstallSnapshotResponse *reply);
void leaderHearBeatTicker(); //检查是否需要发起心跳(leader)
void leaderSendSnapShot(int server);
void leaderUpdateCommitIndex(); //leader更新commitIndex
bool matchLog(int logIndex, int logTerm); //对应Index的日志是否匹配,只需要Index和Term就可以知道是否匹配
void persist(); //持久化
void RequestVote(const mprrpc::RequestVoteArgs *args, mprrpc::RequestVoteReply *reply); //变成candidate之后需要让其他结点给自己投票
bool UpToDate(int index, int term); //判断当前节点是否含有最新的日志
int getLastLogIndex();
void getLastLogIndexAndTerm(int *lastLogIndex, int *lastLogTerm);
int getLogTermFromLogIndex(int logIndex);
int GetRaftStateSize();
int getSlicesIndexFromLogIndex(int logIndex); //设计快照之后logIndex不能与在日志中的数组下标相等了,根据logIndex找到其在日志数组中的位置
bool sendRequestVote(int server , std::shared_ptr<mprrpc::RequestVoteArgs> args , std::shared_ptr<mprrpc::RequestVoteReply> reply, std::shared_ptr<int> votedNum) ; // 请求其他结点的投票
bool sendAppendEntries(int server ,std::shared_ptr<mprrpc::AppendEntriesArgs> args , std::shared_ptr<mprrpc::AppendEntriesReply> reply , std::shared_ptr<int> appendNums ) ; //Leader发送心跳后,对心跳的回复进行对应的处理
//rf.applyChan <- msg //不拿锁执行 可以单独创建一个线程执行,但是为了同意使用std:thread ,避免使用pthread_create,因此专门写一个函数来执行
void pushMsgToKvServer(ApplyMsg msg); //给上层的kvserver层发送消息
void readPersist(std::string data);
std::string persistData();
void Start(Op command,int* newLogIndex,int* newLogTerm,bool* isLeader ) ; // 发布发来一个新日志
// 即kv-server主动发起,请求raft(持久层)保存snapshot里面的数据,index是用来表示snapshot快照执行到了哪条命令
void Snapshot(int index , std::string snapshot );
public:
void init(std::vector<std::shared_ptr< RaftRpc >> peers,int me,std::shared_ptr<Persister> persister,std::shared_ptr<LockQueue<ApplyMsg>> applyCh); //初始化
关键函数
- Raft的主要流程:
- 领导选举(
sendRequestVote,RequestVote) - 日志同步、心跳(
sendAppendEntries,AppendEntries)
- 定时器的维护:
- Raft向状态机定时写入(
applierTicker) - 心跳维护定时器(
leaderHearBeatTicker) - 选举超时定时器(
electionTimeOutTicker)
- 持久化相关:
- 哪些内容需要持久化,什么时候需要持久化(persist)
m_nextIndex 和 m_matchIndex作用
m_nextIndex 保存leader下一次应该从哪一个日志开始发送给follower;
m_matchIndex表示follower在哪一个日志是已经匹配了的(由于日志安全性,某一个日志匹配,那么这个日志及其之前的日志都是匹配的)
一个比较容易弄错的问题是:m_nextIndex 与m_matchIndex 是否有冗余,即使用一个m_nextIndex 可以吗?
显然是不行的,m_nextIndex 的作用是用来寻找m_matchIndex ,不能直接取代。我们可以从这两个变量的变化看,在当选leader后,m_nextIndex 初始化为最新日志index,m_matchIndex 初始化为0,如果日志不匹配,那么m_nextIndex 就会不断的缩减,直到遇到匹配的日志,这时候m_nextIndex 应该一直为m_matchIndex+1 。
如果一直不发生故障,那么后期m_nextIndex就没有太大作用了,但是raft考虑需要考虑故障的情况,因此需要使用两个变量。
2.启动初始化
void Raft::init(std::vector<std::shared_ptr<RaftRpc>> peers, int me, std::shared_ptr<Persister> persister, std::shared_ptr<LockQueue<ApplyMsg>> applyCh) {
m_peers = peers; //与其他结点沟通的rpc类
m_persister = persister; //持久化类
m_me = me; //标记自己,毕竟不能给自己发送rpc吧
m_mtx.lock();
//applier
this->applyChan = applyCh; //与kv-server沟通
// rf.ApplyMsgQueue = make(chan ApplyMsg)
m_currentTerm = 0; //初始化term为0
m_status = Follower; //初始化身份为follower
m_commitIndex = 0;
m_lastApplied = 0;
m_logs.clear();
for (int i =0;i<m_peers.size();i++){
m_matchIndex.push_back(0);
m_nextIndex.push_back(0);
}
m_votedFor = -1; //当前term没有给其他人投过票就用-1表示
m_lastSnapshotIncludeIndex = 0;
m_lastSnapshotIncludeTerm = 0;
m_lastResetElectionTime = now();
m_lastResetHearBeatTime = now();
// initialize from state persisted before a crash
readPersist(m_persister->ReadRaftState());
if(m_lastSnapshotIncludeIndex > 0){
m_lastApplied = m_lastSnapshotIncludeIndex;
//rf.commitIndex = rf.lastSnapshotIncludeIndex 崩溃恢复不能读取commitIndex
}
m_mtx.unlock();
// start ticker 开始三个定时器
std::thread t(&Raft::leaderHearBeatTicker, this);
t.detach();
std::thread t2(&Raft::electionTimeOutTicker, this);
t2.detach();
std::thread t3(&Raft::applierTicker, this);
t3.detach();
}
从上面可以看到一共产生了三个定时器,分别维护:选举、日志同步和心跳、raft节点与kv-server的联系。相互之间是比较隔离的
3.竞选leader
在Raft算法中,每个节点(无论是追随者(follower)还是候选人(candidate))都有一个选举定时器。如果追随者在一定的时间内没有收到任何来自领导者或候选人的消息,它会认为当前没有有效的领导者,然后启动选举定时器。一旦定时器到期,追随者会转换为候选人状态,并开始新一轮的领导者选举。

electionTimeOutTicker:负责查看是否该发起选举,如果该发起选举就执行doElection发起选举。doElection:实际发起选举,构造需要发送的rpc,并多线程调用sendRequestVote处理rpc及其相应。sendRequestVote:负责发送选举中的RPC,在发送完rpc后还需要负责接收并处理对端发送回来的响应。RequestVote:接收别人发来的选举请求,主要检验是否要给对方投票。
electionTimeOutTicker:
选举定时器,负责查看是否该发起选举,如果该发起选举就执行doElection发起选举。
void Raft::electionTimeOutTicker() {
// Check if a Leader election should be started.
while (true) {
m_mtx.lock();
auto nowTime = now(); //睡眠前记录时间
auto suitableSleepTime = getRandomizedElectionTimeout() + m_lastResetElectionTime - nowTime;
m_mtx.unlock();
if (suitableSleepTime.count() > 1) {
std::this_thread::sleep_for(suitableSleepTime);
}
if ((m_lastResetElectionTime - nowTime).count() > 0) { //说明睡眠的这段时间有重置定时器,那么就没有超时,再次睡眠
continue;
}
doElection();
}
}
在死循环中,
首先计算距离上次重置选举计时器的时间m_lastResetElectionTime - nowTime加上随机化的选举超时时间getRandomizedElectionTimeout,
计算得到距离下一次超时应该睡眠的时间suitableSleepTime,然后线程根据这个时间决定是否睡眠。
若超时时间未到,线程进入睡眠状态,若在此期间选举计时器被重置,则继续循环。
若超时时间已到,调用doElection() 函数启动领导者选举过程。
随机化的选举超时时间是为了避免多个追随者几乎同时成为候选人,导致选举失败
doElection
实际发起选举,构造需要发送的rpc,并多线程调用sendRequestVote处理rpc及其相应。
void Raft::doElection() {
lock_guard<mutex> g(m_mtx); //c11新特性,使用raii避免死锁
if (m_status != Leader) {
DPrintf("[ ticker-func-rf(%d) ] 选举定时器到期且不是leader,开始选举 \n", m_me);
//当选举的时候定时器超时就必须重新选举,不然没有选票就会一直卡住
//重竞选超时,term也会增加的
m_status = Candidate;
///开始新一轮的选举
m_currentTerm += 1; //无论是刚开始竞选,还是超时重新竞选,term都要增加
m_votedFor = m_me; //即是自己给自己投票,也避免candidate给同辈的candidate投
persist();
std::shared_ptr<int> votedNum = std::make_shared<int>(1); // 使用 make_shared 函数初始化
// 重新设置定时器
m_lastResetElectionTime = now();
// 发布RequestVote RPC
for (int i = 0; i < m_peers.size(); i++) {
if (i == m_me) {
continue;
}
int lastLogIndex = -1, lastLogTerm = -1;
getLastLogIndexAndTerm(&lastLogIndex, &lastLogTerm);//获取最后一个log的term和下标,以添加到RPC的发送
//初始化发送参数
std::shared_ptr<mprrpc::RequestVoteArgs> requestVoteArgs = std::make_shared<mprrpc::RequestVoteArgs>();
requestVoteArgs->set_term(m_currentTerm);
requestVoteArgs->set_candidateid(m_me);
requestVoteArgs->set_lastlogindex(lastLogIndex);
requestVoteArgs->set_lastlogterm(lastLogTerm);
std::shared_ptr<mprrpc::RequestVoteReply> requestVoteReply = std::make_shared<mprrpc::RequestVoteReply>();
//使用匿名函数执行避免其拿到锁
std::thread t(&Raft::sendRequestVote, this, i, requestVoteArgs, requestVoteReply,
votedNum); // 创建新线程并执行函数,并传递参数
t.detach();
}
}
}
sendRequestVote
负责发送选举中的RPC,在发送完rpc后还需要根据调用RequestVote得到的reply响应结果,负责接收并处理对端发送回来的响应,对发起投票的候选者状态进行更新
bool Raft::sendRequestVote(int server, std::shared_ptr<mprrpc::RequestVoteArgs> args, std::shared_ptr<mprrpc::RequestVoteReply> reply,
std::shared_ptr<int> votedNum) {
bool ok = m_peers[server]->RequestVote(args.get(),reply.get());
if (!ok) {
return ok;//rpc通信失败就立即返回,避免资源消耗
}
lock_guard<mutex> lg(m_mtx);
if(reply->term() > m_currentTerm){
//回复的term比自己大,说明自己落后了,那么就更新自己的状态并且退出
m_status = Follower; //三变:身份,term,和投票
m_currentTerm = reply->term();
m_votedFor = -1; //term更新了,那么这个term自己肯定没投过票,为-1
persist(); //持久化
return true;
} else if ( reply->term() < m_currentTerm ) {
//回复的term比自己的term小,不应该出现这种情况
return true;
}
if(!reply->votegranted()){ //这个节点因为某些原因没给自己投票,没啥好说的,结束本函数
return true;
}
//给自己投票了
*votedNum = *votedNum + 1; //voteNum多一个
if (*votedNum >= m_peers.size()/2+1) {
//变成leader
*votedNum = 0; //重置voteDNum,如果不重置,那么就会变成leader很多次,是没有必要的,甚至是错误的!!!
// 第一次变成leader,初始化状态和nextIndex、matchIndex
m_status = Leader;
int lastLogIndex = getLastLogIndex();
for (int i = 0; i <m_nextIndex.size() ; i++) {
m_nextIndex[i] = lastLogIndex + 1 ;//有效下标从1开始,因此要+1
m_matchIndex[i] = 0; //每换一个领导都是从0开始,见论文的fig2
}
std::thread t(&Raft::doHeartBeat, this); //马上向其他节点宣告自己就是leader
t.detach();
persist();
}
return true;
}
RequestVote
得到投票请求后,节点根据传递来的信息进行判断是否对其投票,构造reply返回值
void Raft::RequestVote( const mprrpc::RequestVoteArgs *args, mprrpc::RequestVoteReply *reply) {
lock_guard<mutex> lg(m_mtx);
Defer ec1([this]() -> void { //应该先持久化,再撤销lock,因此这个写在lock后面
this->persist();
});
//对args的term的三种情况分别进行处理,大于小于等于自己的term都是不同的处理
//reason: 出现网络分区,该竞选者已经OutOfDate(过时)
if (args->term() < m_currentTerm) {
reply->set_term(m_currentTerm);
reply->set_votestate(Expire);
reply->set_votegranted(false);
return;
}
//论文fig2:右下角,如果任何时候rpc请求或者响应的term大于自己的term,更新term,并变成follower
if (args->term() > m_currentTerm) {
m_status = Follower;
m_currentTerm = args->term();
m_votedFor = -1;
// 重置定时器:收到leader的ae,开始选举,透出票
//这时候更新了term之后,votedFor也要置为-1
}
// 现在节点任期都是相同的(任期小的也已经更新到新的args的term了)
// 要检查log的term和index是不是匹配的了
int lastLogTerm = getLastLogIndex();
//只有没投票,且candidate的日志的新的程度 ≥ 接受者的日志新的程度 才会授票
if (!UpToDate(args->lastlogindex(), args->lastlogterm())) {
//日志太旧了
reply->set_term(m_currentTerm);
reply->set_votestate(Voted);
reply->set_votegranted(false);
return;
}
// 当因为网络质量不好导致的请求丢失重发就有可能!!!!
// 因此需要避免重复投票
if (m_votedFor != -1 && m_votedFor != args->candidateid()) {
reply->set_term(m_currentTerm);
reply->set_votestate(Voted);
reply->set_votegranted(false);
return;
} else {
//同意投票
m_votedFor = args->candidateid();
m_lastResetElectionTime = now();//认为必须要在投出票的时候才重置定时器,
reply->set_term(m_currentTerm);
reply->set_votestate(Normal);
reply->set_votegranted(true);
return;
}
}
4.日志复制、心跳

leaderHearBeatTicker:负责查看是否该发送心跳了,如果该发起就执行doHeartBeat。doHeartBeat:实际发送心跳,判断到底是构造需要发送的rpc,并多线程调用sendRequestVote处理rpc及其响应。sendAppendEntries:负责发送日志的RPC,在发送完rpc后还需要负责接收并处理对端发送回来的响应。leaderSendSnapShot:负责发送快照的RPC,在发送完rpc后还需要负责接收并处理对端发送回来的响应。AppendEntries:接收leader发来的日志请求,主要检验用于检查当前日志是否匹配并同步leader的日志到本机。InstallSnapshot:接收leader发来的快照请求,同步快照到本机。
leaderHearBeatTicker
心跳定时器,负责查看是否该发送心跳了,如果该发起就执行doHeartBeat。
void Raft::leaderHearBeatTicker() {
while (true) {
auto nowTime = now();
m_mtx.lock();
auto suitableSleepTime = std::chrono::milliseconds(HeartBeatTimeout) + m_lastResetHearBeatTime - nowTime;
m_mtx.unlock();
if (suitableSleepTime.count() < 1) {
suitableSleepTime = std::chrono::milliseconds(1);
}
std::this_thread::sleep_for(suitableSleepTime);
if ((m_lastResetHearBeatTime - nowTime).count() > 0) { //说明睡眠的这段时间有重置定时器,那么就没有超时,再次睡眠
continue;
}
doHeartBeat();
}
}
其基本逻辑和选举定时器electionTimeOutTicker一模一样
不一样之处在于设置的休眠时间不同,这里是根据HeartBeatTimeout来设置,固定时间。
而electionTimeOutTicker中是根据getRandomizedElectionTimeout() 设置,随机一个时间。
doHeartBeat
实际发送心跳,判断是Leader则构造需要发送的rpc,并多线程调用sendRequestVote处理rpc及其响应。
void Raft::doHeartBeat() {
std::lock_guard<mutex> g(m_mtx);
if (m_status == Leader) {
auto appendNums = std::make_shared<int>(1); //正确返回的节点的数量
//对Follower(除了自己外的所有节点发送AE)
for (int i = 0; i < m_peers.size(); i++) {
if(i == m_me){ //不对自己发送AE
continue;
}
//日志压缩加入后要判断是发送快照还是发送AE
if (m_nextIndex[i] <= m_lastSnapshotIncludeIndex) {
//应该发送的日志已经被压缩成快照,必须发送快照了
std::thread t(&Raft::leaderSendSnapShot, this, i);
t.detach();
continue;
}
//发送心跳,构造发送值
int preLogIndex = -1;
int PrevLogTerm = -1;
getPrevLogInfo(i, &preLogIndex, &PrevLogTerm); //获取本次发送的一系列日志的上一条日志的信息,以判断是否匹配
std::shared_ptr<mprrpc::AppendEntriesArgs> appendEntriesArgs = std::make_shared<mprrpc::AppendEntriesArgs>();
appendEntriesArgs->set_term(m_currentTerm);
appendEntriesArgs->set_leaderid(m_me);
appendEntriesArgs->set_prevlogindex(preLogIndex);
appendEntriesArgs->set_prevlogterm(PrevLogTerm);
appendEntriesArgs->clear_entries();
appendEntriesArgs->set_leadercommit(m_commitIndex);
// 作用是携带上prelogIndex的下一条日志及其之后的所有日志
//leader对每个节点发送的日志长短不一,但是都保证从prevIndex发送直到最后
if (preLogIndex != m_lastSnapshotIncludeIndex) {
for (int j = getSlicesIndexFromLogIndex(preLogIndex) + 1; j < m_logs.size(); ++j) {
mprrpc::LogEntry *sendEntryPtr = appendEntriesArgs->add_entries();
*sendEntryPtr = m_logs[j];
}
} else {
for (const auto& item: m_logs) {
mprrpc::LogEntry *sendEntryPtr = appendEntriesArgs->add_entries();
*sendEntryPtr = item;
}
}
int lastLogIndex = getLastLogIndex();
//初始化返回值
const std::shared_ptr<mprrpc::AppendEntriesReply> appendEntriesReply = std::make_shared<mprrpc::AppendEntriesReply>();
std::thread t(&Raft::sendAppendEntries, this, i, appendEntriesArgs, appendEntriesReply,
appendNums); // 创建新线程并执行b函数,并传递参数
t.detach();
}
m_lastResetHearBeatTime = now(); //leader发送心跳,重置心跳时间,
}
}
sendAppendEntries
负责发送日志的RPC,在发送完rpc后还需要负责接收并处理对端发送回来的响应。
bool
Raft::sendAppendEntries(int server, std::shared_ptr<mprrpc::AppendEntriesArgs> args, std::shared_ptr<mprrpc::AppendEntriesReply> reply,
std::shared_ptr<int> appendNums) {
// todo: paper中5.3节第一段末尾提到,如果append失败应该不断的retries ,直到这个log成功的被store
bool ok = m_peers[server]->AppendEntries(args.get(), reply.get());
if (!ok) {
return ok;
}
lock_guard<mutex> lg1(m_mtx);
//对reply进行处理
// 对于rpc通信,无论什么时候都要检查term
if(reply->term() > m_currentTerm){
m_status = Follower;
m_currentTerm = reply->term();
m_votedFor = -1;
return ok;
} else if (reply->term() < m_currentTerm) {//正常不会发生
return ok;
}
if (m_status != Leader) { //如果不是leader,那么就不要对返回的情况进行处理了
return ok;
}
//term相等
if (!reply->success()){
//日志不匹配,正常来说就是index要往前-1,既然能到这里,第一个日志(idnex = 1)发送后肯定是匹配的,因此不用考虑变成负数
//因为真正的环境不会知道是服务器宕机还是发生网络分区了
if (reply->updatenextindex() != -100) { //-100只是一个特殊标记而已,没有太具体的含义,这里表示任期落后了
// 优化日志匹配,让follower决定到底应该下一次从哪一个开始尝试发送
m_nextIndex[server] = reply->updatenextindex();
}
// 如果感觉rf.nextIndex数组是冗余的,看下论文fig2,其实不是冗余的
} else {
*appendNums = *appendNums +1; //到这里代表同意接收了本次心跳或者日志
m_matchIndex[server] = std::max(m_matchIndex[server],args->prevlogindex()+args->entries_size() ); //同意了日志,就更新对应的m_matchIndex和m_nextIndex
m_nextIndex[server] = m_matchIndex[server]+1;
int lastLogIndex = getLastLogIndex();
if (*appendNums >= 1 + m_peers.size()/2) { //可以commit了
//两种方法保证幂等性,1.赋值为0 2.上面≥改为==
*appendNums = 0; //置0
//日志的安全性保证!!!!! leader只有在当前term有日志提交的时候才更新commitIndex,因为raft无法保证之前term的Index是否提交
//只有当前term有日志提交,之前term的log才可以被提交,只有这样才能保证“领导人完备性{当选领导人的节点拥有之前被提交的所有log,当然也可能有一些没有被提交的}”
//说白了就是只有当前term有日志提交才会提交
if(args->entries_size() >0 && args->entries(args->entries_size()-1).logterm() == m_currentTerm){
m_commitIndex = std::max(m_commitIndex,args->prevlogindex() + args->entries_size());
}
}
}
return ok;
}
m_nextIndex[server] = reply->updatenextindex(); 中涉及日志寻找匹配加速的优化
对于leader只有在当前term有日志提交的时候才更新commitIndex这个安全性保证,详情看参考公众号文章的:7.6是否一项提议只需要被多数派通过就可以提交?
AppendEntries
接收leader发来的日志请求,主要检验用于检查当前日志是否匹配并同步leader的日志到本机。
void Raft::AppendEntries1(const mprrpc:: AppendEntriesArgs *args, mprrpc::AppendEntriesReply *reply) {
std::lock_guard<std::mutex> locker(m_mtx);
// 不同的人收到AppendEntries的反应是不同的,要注意无论什么时候收到rpc请求和响应都要检查term
if (args->term() < m_currentTerm) {
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(-100); // 论文中:让领导人可以及时更新自己
DPrintf("[func-AppendEntries-rf{%d}] 拒绝了 因为Leader{%d}的term{%v}< rf{%d}.term{%d}\n", m_me, args->leaderid(),args->term() , m_me, m_currentTerm) ;
return; // 注意从过期的领导人收到消息不要重设定时器
}
Defer ec1([this]() -> void { this->persist(); });//由于这个局部变量创建在锁之后,因此执行persist的时候应该也是拿到锁的. //本质上就是使用raii的思想让persist()函数执行完之后再执行
if (args->term() > m_currentTerm) {
// 三变 ,防止遗漏,无论什么时候都是三变
m_status = Follower;
m_currentTerm = args->term();
m_votedFor = -1; // 这里设置成-1有意义,如果突然宕机然后上线理论上是可以投票的
// 这里可不返回,应该改成让改节点尝试接收日志
// 如果是领导人和candidate突然转到Follower好像也不用其他操作
// 如果本来就是Follower,那么其term变化,相当于“不言自明”的换了追随的对象,因为原来的leader的term更小,是不会再接收其消息了
}
// 如果发生网络分区,那么candidate可能会收到同一个term的leader的消息,要转变为Follower,为了和上面,因此直接写
m_status = Follower; // 这里是有必要的,因为如果candidate收到同一个term的leader的AE,需要变成follower
// term相等
m_lastResetElectionTime = now(); //重置选举超时定时器
// 不能无脑的从prevlogIndex开始阶段日志,因为rpc可能会延迟,导致发过来的log是很久之前的
// 那么就比较日志,日志有3种情况
if (args->prevlogindex() > getLastLogIndex()) { //追随者的日志比领导者的要短。这种情况,追随者需要从领导者那里接收缺失的日志条目。
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(getLastLogIndex() + 1);
return;
} else if (args->prevlogindex() < m_lastSnapshotIncludeIndex) { // 如果prevlogIndex还没有更上快照
//追随者可能已经通过快照机制截断了其日志 或 追随者接受了一个快照,丢弃了快照索引之前的日志 或 领导者的日志落后
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(m_lastSnapshotIncludeIndex + 1); //不会浪费时间重试发送追随者已经用快照截断的日志条目
}
// 本机日志有那么长,冲突(same index,different term),截断日志
// 注意:这里目前当args.PrevLogIndex == rf.lastSnapshotIncludeIndex与不等的时候要分开考虑,可以看看能不能优化这块
if (matchLog(args->prevlogindex(), args->prevlogterm())) {
//日志匹配,那么就复制日志
for (int i = 0; i < args->entries_size(); i++) {
auto log = args->entries(i);
if (log.logindex() > getLastLogIndex()) { //超过就直接添加日志
m_logs.push_back(log);
} else { //没超过就比较是否匹配,不匹配再更新,而不是直接截断 检查当前日志条目是否已经存在于追随者的日志中。
//判断追随者日志中相应索引位置的日志条目的任期是否与请求中的日志条目的任期相同。如果任期不同,说明日志不匹配。
//参考前面公众号文章 4.1 写 case3
if (m_logs[getSlicesIndexFromLogIndex(log.logindex())].logterm() != log.logterm()) { //不匹配就更新
m_logs[getSlicesIndexFromLogIndex(log.logindex())] = log;
}
}
}
if (args->leadercommit() > m_commitIndex) {
m_commitIndex = std::min(args->leadercommit(), getLastLogIndex());// 这个地方不能无脑跟上getLastLogIndex(),因为可能存在args->leadercommit()落后于 getLastLogIndex()的情况
}
// 领导会一次发送完所有的日志
reply->set_success(true);
reply->set_term(m_currentTerm);
return;
} else {
// 不匹配,不匹配不是一个一个往前,而是有优化加速
// PrevLogIndex 长度合适,但是不匹配,因此往前寻找 矛盾的term的第一个元素
// 为什么该term的日志都是矛盾的呢?也不一定都是矛盾的,只是这么优化减少rpc而已
// ?什么时候term会矛盾呢?很多情况,比如leader接收了日志之后马上就崩溃等等
reply->set_updatenextindex(args->prevlogindex());
for (int index = args->prevlogindex(); index >= m_lastSnapshotIncludeIndex; --index) {
if (getLogTermFromLogIndex(index) != getLogTermFromLogIndex(args->prevlogindex())) {
reply->set_updatenextindex(index + 1);
break;
}
}
reply->set_success(false);
reply->set_term(m_currentTerm);
return;
}
}
日志寻找匹配加速
这部分在AppendEntries函数最后部分。
// 不匹配,不匹配不是一个一个往前,而是有优化加速
// PrevLogIndex 长度合适,但是不匹配,因此往前寻找 矛盾的term的第一个元素
// 为什么该term的日志都是矛盾的呢?也不一定都是矛盾的,只是这么优化减少rpc而已
// ?什么时候term会矛盾呢?很多情况,比如leader接收了日志之后马上就崩溃等等
reply->set_updatenextindex(args->prevlogindex());
for (int index = args->prevlogindex(); index >= m_lastSnapshotIncludeIndex; --index) {
if (getLogTermFromLogIndex(index) != getLogTermFromLogIndex(args->prevlogindex())) {
reply->set_updatenextindex(index + 1);
break;
}
}
reply->set_success(false);
reply->set_term(m_currentTerm);
return;
之前说过,如果日志不匹配的话可以一个一个往前的倒退。但是这样的话可能会设计很多个rpc之后才能找到匹配的日志,那么就一次多倒退几个数。
倒退几个呢?这里认为如果某一个日志不匹配,那么这一个日志所在的term的所有日志大概率都不匹配,那么就倒退到 最后一个日志所在的term的最后那个命令。
5.snapshot快照
快照是什么?
当在Raft协议中的日志变得太大时,为了避免无限制地增长,系统可能会采取快照(snapshot)的方式来压缩日志。快照是系统状态的一种紧凑表示形式,包含在某个特定时间点的所有必要信息,以便在需要时能够还原整个系统状态。
如果你学习过redis,那么快照说白了就是rdb,而raft的日志可以看成是aof日志。rdb的目的只是为了崩溃恢复的加速,如果没有的话也不会影响系统的正确性,这也是为什么选择不详细讲解快照的原因,因为只是日志的压缩而已。
何时创建快照?
快照通常在日志达到一定大小时创建。这有助于限制日志的大小,防止无限制的增长。快照也可以在系统空闲时(没有新的日志条目被追加)创建。
快照的传输
快照的传输主要涉及:kv数据库与raft节点之间;不同raft节点之间。
kv数据库与raft节点之间:因为快照是数据库的压缩表示,因此需要由数据库打包快照,并交给raft节点。当快照生成之后,快照内设计的操作会被raft节点从日志中删除(不删除就相当于有两份数据,冗余了)。
不同raft节点之间:当leader已经把某个日志及其之前的内容变成了快照,那么当涉及这部的同步时,就只能通过快照来发送。
三.持久化
持久化就是把不能丢失的数据保存到磁盘。
1.持久化介绍
持久化的内容为两部分:
1.raft节点的部分信息;2.kvDb的快照
1.raft节点的部分信息
m_currentTerm :当前节点的Term,避免重复到一个Term,可能会遇到重复投票等问题。
m_votedFor :当前Term给谁投过票,避免故障后重复投票。
m_logs :raft节点保存的全部的日志信息。
不妨想一想,其他的信息为什么不用持久化,比如说:身份、commitIndex、applyIndex等等。
applyIndex不持久化是经典raft的实现,在一些工业实现上可能会优化,从而持久化。
即applyIndex不持久化不会影响“共识”。
2.kvDb的快照
m_lastSnapshotIncludeIndex :快照的信息,快照最新包含哪个日志Index
m_lastSnapshotIncludeTerm :快照的信息,快照最新包含哪个日志Term,与m_lastSnapshotIncludeIndex 是对应的。
Snapshot是kvDb的快照,也可以看成是日志,因此:全部的日志 = m_logs + snapshot
因为Snapshot是kvDB生成的,kvDB肯定不知道raft的存在,而什么term、什么日志Index都是raft才有的概念,因此snapshot中肯定没有term和index信息。所以需要raft自己来保存这些信息。
故,快照与m_logs联合起来理解即可。
2.为什么要持久化这些内容
两部分原因:共识安全、优化。
除了snapshot相关的部分,其他部分都是为了共识安全。
而snapshot是因为日志一个一个的叠加,会导致最后的存储非常大,因此使用snapshot来压缩日志。
为什么snashot可以压缩日志?
日志是追加写的,对于一个变量的重复修改可能会重复保存,理论上对一个变量的反复修改会导致日志不断增大。
而snapshot是原地写,即只保存一个变量最后的值,自然所需要的空间就小了。
3.什么时候持久化
需要持久化的内容发送改变的时候就要注意持久化。
比如term 增加,日志增加等等。
*具体查看代码中的void Raft::persist() 相关内容
4.谁来调用持久化
谁来调用都可以,只要能保证需要持久化的内容能正确持久化。
代码中选择的是raft类自己来完成持久化。因为raft类最方便感知自己的term之类的信息有没有变化。
注意,虽然持久化很耗时,但是持久化这些内容的时候不要放开锁,以防其他线程改变了这些值,导致其它异常。
5.具体怎么实现持久化/使用哪个函数持久化
其实持久化是一个非常难的事情,因为持久化需要考虑:速度、大小、二进制安全。
因此代码中目前采用的是使用boost库中的持久化实现,将需要持久化的数据序列化转成std::string 类型再写入磁盘。
当然其他的序列化方式也少可行的,可以看到这一块还是有优化空间的。
四.kvServer
1.kvServer介绍
图中是raftServer,这里叫成kvServer,是一样的。
kvServer其实是个中间组件,负责沟通kvDB和raft节点。
那么外部请求是Server来负责,加入后变成了:

2.kvServer怎么和上层kvDB沟通,怎么和下层raft节点沟通
std::shared_ptr<LockQueue<ApplyMsg> > applyChan; //kvServer和raft节点的通信管道
std::unordered_map<std::string, std::string> m_kvDB; //kvDB,用unordered_map来替代
kvDB:使用的是unordered_map来代替上层的kvDB,因此没啥好说的。
raft节点:其中LockQueue 是一个并发安全的队列,这种方式其实是模仿的go中的channel机制。
在raft类中这里可以看到,raft类中也拥有一个applyChan,kvSever和raft类都持有同一个applyChan,来完成相互的通信。
3.kvServer怎么处理外部请求
从上面的结构图中可以看到kvServer负责与外部clerk通信。
那么一个外部请求的处理可以简单的看成:
- 接收外部请求。
- 本机内部与raft和kvDB协商如何处理该请求。
- 返回外部响应。
4.接收与响应外部请求
对于1和3,请求和返回的操作我们可以通过http、自定义协议等等方式实现,但是既然我们已经写出了rpc通信的一个简单的实现,就使用rpc来实现
而且rpc可以直接完成请求和响应这一步,后面就不用考虑外部通信的问题了,好好处理好本机的流程即可。
相关函数是:
void PutAppend(google::protobuf::RpcController *controller,
const ::raftKVRpcProctoc::PutAppendArgs *request,
::raftKVRpcProctoc::PutAppendReply *response,
::google::protobuf::Closure *done) override;
void Get(google::protobuf::RpcController *controller,
const ::raftKVRpcProctoc::GetArgs *request,
::raftKVRpcProctoc::GetReply *response,
::google::protobuf::Closure *done) override;
见名知意,请求分成两种:get和put(也就是set)。
如果是putAppend,clerk中就调用PutAppend 的rpc。
如果是Get,clerk中就调用Get 的rpc。
5.与raft节点沟通
在正式开始之前我们必须要先了解 线性一致性 的相关概念。
线性一致性
参考: 线性一致性和 Raft
一个系统的执行历史是一系列的客户端请求,或许这是来自多个客户端的多个请求。如果执行历史整体可以按照一个顺序排列,且排列顺序与客户端请求的实际时间相符合,那么它是线性一致的。当一个客户端发出一个请求,得到一个响应,之后另一个客户端发出了一个请求,也得到了响应,那么这两个请求之间是有顺序的,因为一个在另一个完成之后才开始。一个线性一致的执行历史中的操作是非并发的,也就是时间上不重合的客户端请求与实际执行时间匹配。并且,每一个读操作都看到的是最近一次写入的值。
一个稍微通俗一点的理解为:
如果一个操作在另一个操作开始前就结束了,那么这个操作必须在执行历史中出现在另一个操作前面。
要理解这个你需要首先明白:
对于一个操作来说,从请求发出到收到回复,是一个时间段。因为操作中包含很多步骤,至少包含:网络传输、数据处理、数据真正写入数据库、数据处理、网络传输。
那么操作真正完成(数据真正写入数据库)可以看成是一个时间点。
操作真正完成 可能在操作时间段的任何一个时间点完成。
raft如何做的
每个 client 都需要一个唯一的标识符,它的每个不同命令需要有一个顺序递增的 commandId,clientId 和这个 commandId,clientId 可以唯一确定一个不同的命令,从而使得各个 raft 节点可以记录保存各命令是否已应用以及应用以后的结果。
即对于每个client,都有一个唯一标识,对于每个client,只执行递增的命令。
在保证线性一致性的情况下如何写kv
具体的思想在上面已经讲过,这里展示一下关键的代码实现:
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) {//通过超时pop来限定命令执行时间,如果超过时间还没拿到消息说明命令执行超时了。
if (ifRequestDuplicate(op.ClientId, op.RequestId)) {
reply->set_err(OK);// 超时了,但因为是重复的请求,返回ok,实际上就算没有超时,在真正执行的时候也要判断是否重复
} else {
reply->set_err(ErrWrongLeader); ///这里返回这个的目的让clerk重新尝试
}
} else {
//没超时,命令可能真正的在raft集群执行成功了。
if (raftCommitOp.ClientId == op.ClientId &&
raftCommitOp.RequestId == op.RequestId) { //可能发生leader的变更导致日志被覆盖,因此必须检查
reply->set_err(OK);
} else {
reply->set_err(ErrWrongLeader);
}
}
需要注意的是,这里的命令执行成功是指:本条命令在整个raft集群达到同步的状态,而不是一台机器上的raft保存了该命令。
在保证线性一致性的情况下如何读kv
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) {
int _ = -1;
bool isLeader = false;
m_raftNode->GetState(&_, &isLeader);
if (ifRequestDuplicate(op.ClientId, op.RequestId) && isLeader) {
//如果超时,代表raft集群不保证已经commitIndex该日志,但是如果是已经提交过的get请求,是可以再执行的。
// 不会违反线性一致性
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader); //返回这个,其实就是让clerk换一个节点重试
}
} else {
//raft已经提交了该command(op),可以正式开始执行了
//todo 这里感觉不用检验,因为leader只要正确的提交了,那么这些肯定是符合的
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
}
}
个人感觉读与写不同的是,读就算操作过也可以重复执行,不会违反线性一致性。
因为毕竟不会改写数据库本身的内容。
以GET请求为例看一看流程
以一个读操作为例看一看流程:
首先外部RPC调用GET,
void KvServer::Get(google::protobuf::RpcController *controller, const ::raftKVRpcProctoc::GetArgs *request,
::raftKVRpcProctoc::GetReply *response, ::google::protobuf::Closure *done) {
KvServer::Get(request,response);
done->Run();
}
然后是根据请求参数生成Op,生成Op是因为raft和raftServer沟通用的是类似于go中的channel的机制,然后向下执行即可。
注意:在这个过程中需要判断当前节点是不是leader,如果不是leader的话就返回ErrWrongLeader ,让其他clerk换一个节点尝试。
// 处理来自clerk的Get RPC
void KvServer::Get(const raftKVRpcProctoc::GetArgs *args, raftKVRpcProctoc::GetReply *reply) {
Op op;
op.Operation = "Get";
op.Key = args->key();
op.Value = "";
op.ClientId = args->clientid();
op.RequestId = args->requestid();
int raftIndex = -1;
int _ = -1;
bool isLeader = false;
m_raftNode->Start(op, &raftIndex, &_, &isLeader);//raftIndex:raft预计的logIndex ,虽然是预计,但是正确情况下是准确的,op的具体内容对raft来说 是隔离的
if (!isLeader) {
reply->set_err(ErrWrongLeader);
return;
}
// create waitForCh
m_mtx.lock();
if (waitApplyCh.find(raftIndex) == waitApplyCh.end()) {
waitApplyCh.insert(std::make_pair(raftIndex, new LockQueue<Op>()));
}
auto chForRaftIndex = waitApplyCh[raftIndex];
m_mtx.unlock(); //直接解锁,等待任务执行完成,不能一直拿锁等待
// timeout
Op raftCommitOp;
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) {
int _ = -1;
bool isLeader = false;
m_raftNode->GetState(&_, &isLeader);
if (ifRequestDuplicate(op.ClientId, op.RequestId) && isLeader) {
//如果超时,代表raft集群不保证已经commitIndex该日志,但是如果是已经提交过的get请求,是可以再执行的。
// 不会违反线性一致性
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader); //返回这个,其实就是让clerk换一个节点重试
}
} else {
//raft已经提交了该command(op),可以正式开始执行了
// DPrintf("[WaitChanGetRaftApplyMessage<--]Server %d , get Command <-- Index:%d , ClientId %d, RequestId %d, Opreation %v, Key :%v, Value :%v", kv.me, raftIndex, op.ClientId, op.RequestId, op.Operation, op.Key, op.Value)
//todo 这里还要再次检验的原因:感觉不用检验,因为leader只要正确的提交了,那么这些肯定是符合的
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader);
}
}
m_mtx.lock(); //todo 這個可以先弄一個defer,因爲刪除優先級並不高,先把rpc發回去更加重要
auto tmp = waitApplyCh[raftIndex];
waitApplyCh.erase(raftIndex);
delete tmp;
m_mtx.unlock();
}
6.RPC如何实现调用
这里以Raft类为例讲解下如何使用rpc远程调用的。
- 写protoc文件,并生成对应的文件
- 继承生成的文件的类 class Raft : public raftRpcProctoc::raftRpc
- 重写rpc方法即可:
// 重写基类方法,因为rpc远程调用真正调用的是这个方法
//序列化,反序列化等操作rpc框架都已经做完了,因此这里只需要获取值然后真正调用本地方法即可。
void AppendEntries(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::AppendEntriesArgs *request,
::raftRpcProctoc::AppendEntriesReply *response,
::google::protobuf::Closure *done) override;
void InstallSnapshot(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::InstallSnapshotRequest *request,
::raftRpcProctoc::InstallSnapshotResponse *response,
::google::protobuf::Closure *done) override;
void RequestVote(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::RequestVoteArgs *request,
::raftRpcProctoc::RequestVoteReply *response,
::google::protobuf::Closure *done) override;
可以参考protoc相关资料
五、clerk
1.主要功能
clerk相当于就是一个外部的客户端了,其作用就是向整个raft集群发起命令并接收响应。
2.代码实现
在kvServer一节中有过提及,clerk与kvServer需要建立网络链接,那么既然我们实现了一个简单的RPC,那么我们不妨使用RPC来完成这个过程。
clerk本身的过程还是比较简单的,唯一要注意的:对于RPC返回对端不是leader的话,就需要另外再调用另一个kvServer的RPC重试,直到遇到leader。
clerk的调用代码:
int main(){
Clerk client;
client.Init("test.conf");
auto start = now();
int count = 500;
int tmp = count;
while (tmp --){
client.Put("x",std::to_string(tmp));
std::string get1 = client.Get("x");
std::printf("get return :{%s}\r\n",get1.c_str());
}
return 0;
}
可以看到这个代码逻辑相当简单,没啥难度,不多说了。
让我们看看Init函数吧,这个函数的作用是连接所有的raftKvServer节点,方式依然是通过RPC的方式,这个是raft节点之间相互连接的过程是一样的。
//初始化客户端
void Clerk::Init(std::string configFileName) {
//获取所有raft节点ip、port ,并进行连接
MprpcConfig config;
config.LoadConfigFile(configFileName.c_str());
std::vector<std::pair<std::string,short>> ipPortVt;
for (int i = 0; i < INT_MAX - 1 ; ++i) {
std::string node = "node" + std::to_string(i);
std::string nodeIp = config.Load(node+"ip");
std::string nodePortStr = config.Load(node+"port");
if(nodeIp.empty()){
break;
}
ipPortVt.emplace_back(nodeIp, atoi(nodePortStr.c_str())); //沒有atos方法,可以考慮自己实现
}
//进行连接
for (const auto &item:ipPortVt){
std::string ip = item.first; short port = item.second;
//2024-01-04 todo:bug fix
auto* rpc = new raftServerRpcUtil(ip,port);
m_servers.push_back(std::shared_ptr<raftServerRpcUtil>(rpc));
}
}
接下来让我们看看put函数吧,put函数实际上调用的是PutAppend。
void Clerk::PutAppend(std::string key, std::string value, std::string op) {
// You will have to modify this function.
m_requestId++;
auto requestId = m_requestId;
auto server = m_recentLeaderId;
while (true){
raftKVRpcProctoc::PutAppendArgs args;
args.set_key(key);
args.set_value(value);
args.set_op(op);
args.set_clientid(m_clientId);
args.set_requestid(requestId);
raftKVRpcProctoc::PutAppendReply reply;
bool ok = m_servers[server]->PutAppend(&args,&reply);
if(!ok || reply.err()==ErrWrongLeader){
DPrintf("【Clerk::PutAppend】原以为的leader:{%d}请求失败,向新leader{%d}重试 ,操作:{%s}",server,server+1,op.c_str());
if(!ok){
DPrintf("重试原因 ,rpc失敗 ,");
}
if(reply.err()==ErrWrongLeader){
DPrintf("重試原因:非leader");
}
server = (server+1)%m_servers.size(); // try the next server
continue;
}
if(reply.err()==OK){ //什么时候reply errno为ok呢???
m_recentLeaderId = server;
return ;
}
}
}
这里可以注意。
m_requestId++; m_requestId每次递增。
m_recentLeaderId; m_recentLeaderId是每个clerk初始化的时候随机生成的。
这两个变量的作用是为了维护上一篇所述的“线性一致性”的概念。
server = (server+1)%m_servers.size(); 如果失败的话就让clerk循环节点进行重试。
六、RPC
1.原理
最开始到现在我们都一直在使用RPC的相关功能,但是作为底层的基础构件,这里对RPC的实现做一些简单的介绍。
RPC 是一种使得分布式系统中的不同模块之间能够透明地进行远程调用的技术,使得开发者可以更方便地构建分布式系统,而不用过多关注底层通信细节,调用另一台机器的方法会表现的像调用本地的方法一样。
那么无论对外表现如何,只要设计多个主机之间的通信,必不可少的就是网络通讯这一步
2.运行流程
我们可以看看一次RPC请求到底干了什么?
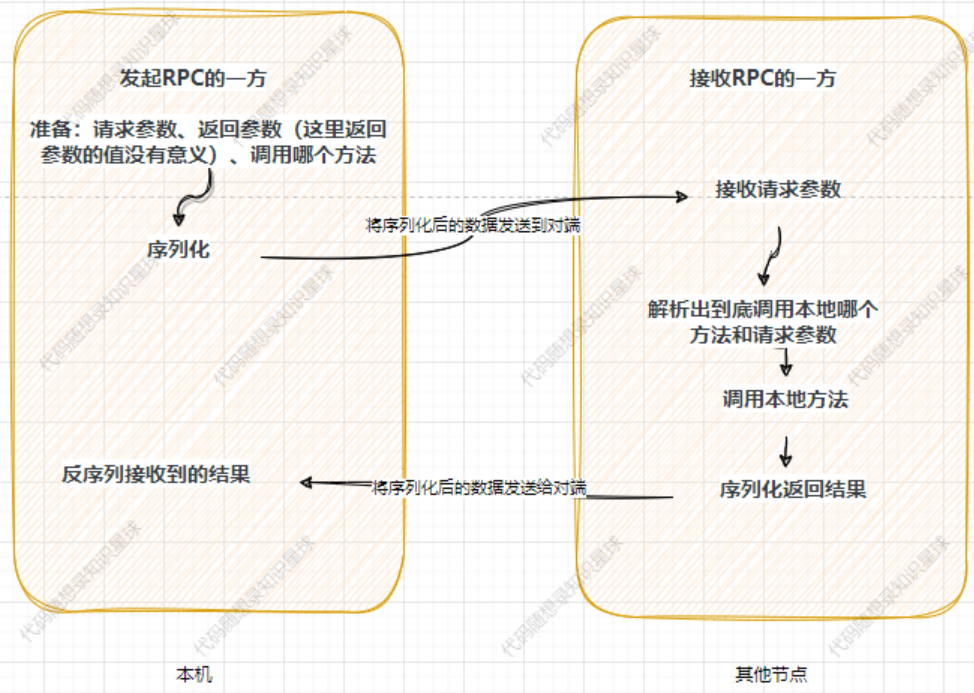
首先【准备:请求参数、返回参数(这里返回参数的值没有意义)、调用哪个方法】这一步,这一步需要发起者自己完成,如下:
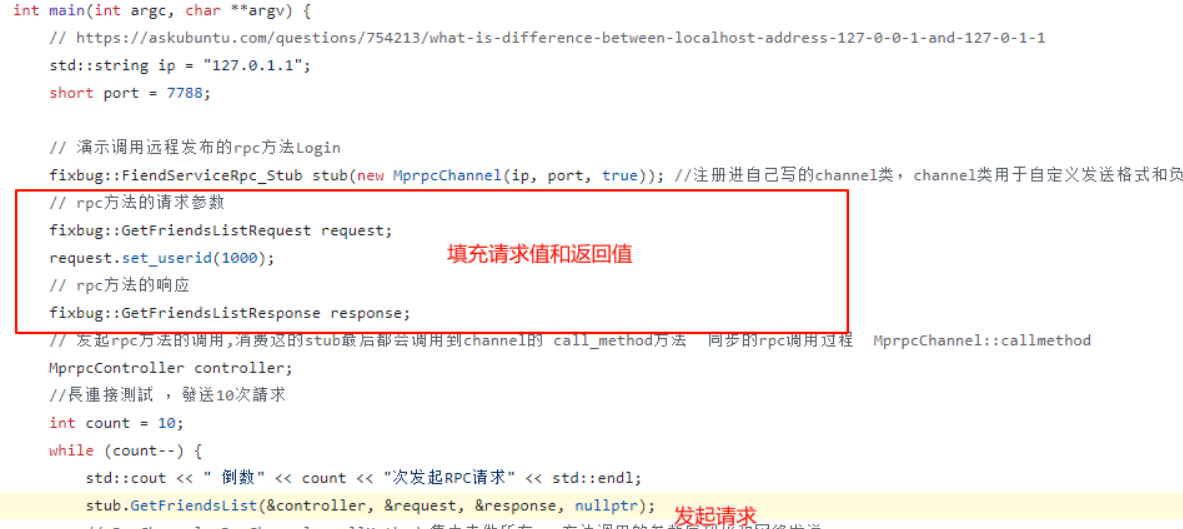
在填充完请求值和返回值之后,就可以实际调用方法了。
void FiendServiceRpc_Stub::GetFriendsList(::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::fixbug::GetFriendsListRequest* request,
::fixbug::GetFriendsListResponse* response,
::google::protobuf::Closure* done) {
channel_->CallMethod(descriptor()->method(0),
controller, request, response, done);
}
可以看到这里相当于是调用了channel_->CallMethod方法,只是第一个参数变成了descriptor()->method(0),其他参数都是我们传进去的参数没有改变,而这个descriptor()->method(0)存在的目的其实就是为了表示我们到底是调用的哪个方法。
到这里远端调用的东西就齐活了:方法、请求参数、响应参数。
还记得在最开始生成stub的我们写的是:fixbug::FiendServiceRpc_Stub stub(new MprpcChannel(ip, port, true));,因此这个channel_本质上是我们自己实现的MprpcChannel类,而channel_->CallMethod本质上就是调用的MprpcChannel的CallMethod方法。
我们简单看下这个CallMethod方法干了什么?
函数的定义在include/mprpcchannel.cpp
按照下图将所需要的参数来序列化,序列化之后再通过send函数循环发送即可。

到了这一步,所有的报文已经发送到了对端,即接收RPC的一方,如图,那么此时应该在对端进行:
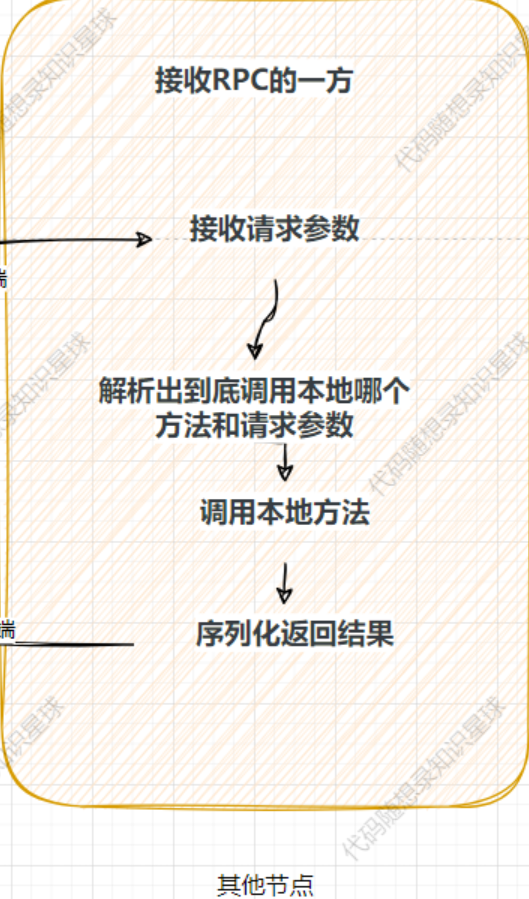
这一系列步骤的主要函数发生在:RpcProvider::OnMessage
我们看下这个函数干了什么:
首先根据上方序列化的规则进行反序列化,解析出相关的参数。
然后根据你要调用的方法名去找到实际的方法调用即可。
相关函数是在NotifyService函数中中提前注册好了,因此这里可以找到然后调用。
在这个过程中使用了protobuf提供的closure绑定了一个回调函数用于在实际调用完方法之后进行反序列化相关操作。
为啥这么写就算注册完反序列化的回调了呢?肯定是protobuf为我们提供了相关的功能,在后面代码流程中也会看到相对应的过程。
google::protobuf::Closure *done = google::protobuf::NewCallback<RpcProvider, const muduo::net::TcpConnectionPtr &, google::protobuf::Message *>(this, &RpcProvider::SendRpcResponse,conn, response);
真正执行本地方法是在 service->CallMethod(method, nullptr, request, response, done);,为什么这个方法就可以调用到本地的方法呢?
这个函数会因为多态实际调用生成的pb.cc文件中的CallMethod方法。
void FiendServiceRpc::CallMethod(const ::PROTOBUF_NAMESPACE_ID::MethodDescriptor* method,
::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::PROTOBUF_NAMESPACE_ID::Message* request,
::PROTOBUF_NAMESPACE_ID::Message* response,
::google::protobuf::Closure* done)
我们看下这个函数干了什么
switch(method->index()) {
case 0:
GetFriendsList(controller,
::PROTOBUF_NAMESPACE_ID::internal::DownCast<const ::fixbug::GetFriendsListRequest*>(request),
::PROTOBUF_NAMESPACE_ID::internal::DownCast<::fixbug::GetFriendsListResponse*>(response),
done);
break;
default:
GOOGLE_LOG(FATAL) << "Bad method index; this should never happen.";
break;
}
这个函数和上面讲过的FiendServiceRpc_Stub::GetFriendsList方法有似曾相识的感觉。都是通过xxx->index来调用实际的方法。
正常情况下校验会通过,即触发case 0。
然后会调用我们在FriendService中重写的GetFriendsList方法。
// 重写基类方法
void GetFriendsList(::google::protobuf::RpcController *controller,
const ::fixbug::GetFriendsListRequest *request,
::fixbug::GetFriendsListResponse *response,
::google::protobuf::Closure *done) {
uint32_t userid = request->userid();
std::vector<std::string> friendsList = GetFriendsList(userid);
response->mutable_result()->set_errcode(0);
response->mutable_result()->set_errmsg("");
for (std::string &name: friendsList) {
std::string *p = response->add_friends();
*p = name;
}
done->Run();
}
这个函数逻辑比较简单:调用本地的方法,填充返回值response。
然后调用回调函数done->Run();,还记得我们前面注册了回调函数吗?
google::protobuf::Closure *done = google::protobuf::NewCallback<RpcProvider,
const muduo::net::TcpConnectionPtr &,google::protobuf::Message *>
(this, &RpcProvider::SendRpcResponse, conn, response);
在回调真正执行之前,我们本地方法已经触发了并填充完返回值了。
此时回看原来的图,我们还需要序列化返回结果和将序列化后的数据发送给对端。
done->Run()实际调用的是:RpcProvider::SendRpcResponse。
这个方法比较简单,不多说了。
到这里,RPC提供方的流程就结束了。
从时间节点上来说,此时应该对端来接收返回值了,接收的部分在这里,还在 MprpcChannel::CallMethod部分:
/*
从时间节点来说,这里将请求发送过去之后rpc服务的提供者就会开始处理,返回的时候就代表着已经返回响应了
*/
// 接收rpc请求的响应值
char recv_buf[1024] = {0};
int recv_size = 0;
if (-1 == (recv_size = recv(m_clientFd, recv_buf, 1024, 0)))
{
close(m_clientFd); m_clientFd = -1;
char errtxt[512] = {0};
sprintf(errtxt, "recv error! errno:%d", errno);
controller->SetFailed(errtxt);
return;
}
// 反序列化rpc调用的响应数据
// std::string response_str(recv_buf, 0, recv_size); // bug:出现问题,recv_buf中遇到\0后面的数据就存不下来了,导致反序列化失败
// if (!response->ParseFromString(response_str))
if (!response->ParseFromArray(recv_buf, recv_size))
{
char errtxt[1050] = {0};
sprintf(errtxt, "parse error! response_str:%s", recv_buf);
controller->SetFailed(errtxt);
return;
}
将接受到的数据按照情况实际序列化成response即可。
这里就可以看出现在的RPC是不支持异步的,因为在MprpcChannel::CallMethod方法中发送完数据后就会一直等待着去接收。
protobuf库中充满了多态,因此推荐阅读的时候采用debug的方式。
注:因为目前RPC的网络通信采用的是muduo,muduo支持函数回调,即在对端发送信息来之后就会调用注册好的函数,函数注册代码在:
m_muduo_server->setMessageCallback(std::bind(&RpcProvider::OnMessage, this, std::placeholders::_1,
std::placeholders::_2, std::placeholders::_3));
这里讲解的RPC其实是比较简单的,并没有考虑:服务治理与服务发现、负载均衡,异步调用等功能。
后续再优化的时候可以考虑这些功能。
七、辅助功能
这里稍微提一下在整个项目运行中的一些辅助的小组件的实现思路以及一些优化的思路。
1.LockQueue的实现
其实就是按照线程池最基本的思路,使用锁和条件变量来控制queue。
那么一个可能的问题就是由于使用了条件变量和锁,可能在内核和用户态会来回切换,有没有更优秀的尝试呢?
比如:无锁队列,使用自旋锁优化,其他。。。。
2.Defer函数等辅助函数的实现
在代码中经常会看到Defer类,这个类的作用其实就是在函数执行完毕后再执行传入Defer类的函数,是收到go中defer的启发。
主要是RAII的思想,如果面试的时候提到了RAII,那么就可以说到这个Defer,然后就牵扯过来了。
3.怎么使用boost库完成序列化和反序列化的
主要参考BoostPersistRaftNode类的定义和使用。
待续


















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









