






0 作者
Shuyun Gu , Xiao Wang , Chuan Shi ∗ ^∗ ∗ and Ding Xiao
1 动机
- 传统推荐系统一般只考虑购买行为,忽略了放入购物车、浏览行为;
- 本文将购买、放入购物车、浏览三个行为一起考虑;
- 考虑购买和放入购物车行为的差异,进行对比学习;
- 考虑购买和浏览行为的差异,进行对比学习。
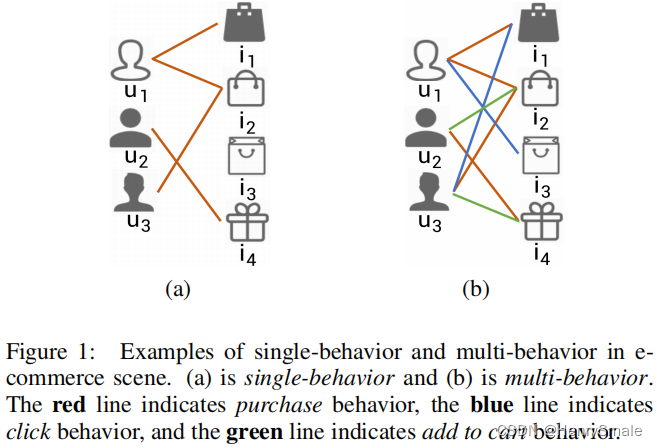
2 相关工作
Graph Neural Networks(GNN): 参考文献[3]
NGCN: 参考文献[4]
LightGCN: 参考文献[5]
3 主要算法
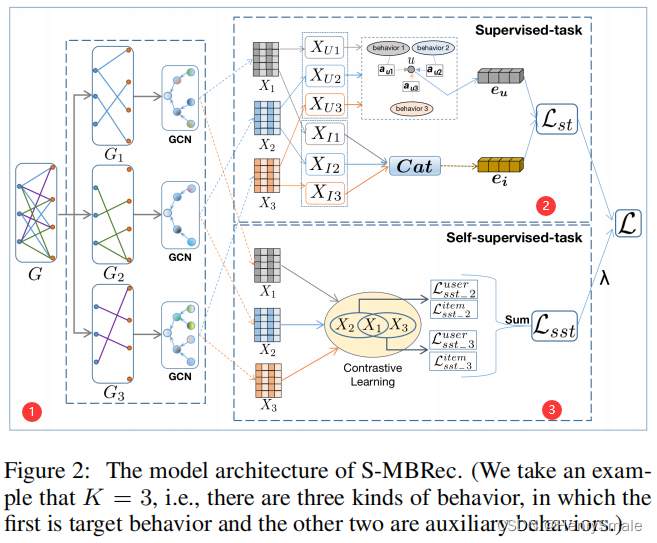
上图表明将算法主要分为三个部分。图中下标1、2、3分别表示购买、放入购物车、浏览三个行为。
- 1 ◯ \textcircled{1} 1◯利用GCN对三个行为进行编码,得到 X 1 X_{1} X1、 X 2 X_{2} X2、 X 3 X_{3} X3;
- 2 ◯ \textcircled{2} 2◯ 求出用户和商品的编码 e u e_{u} eu和 e i e_{i} ei;
- 3 ◯ \textcircled{3} 3◯利用对比学习(Contrastive Learning)来建立购买和放入购物车行为之间的差异、购买和浏览行为之间的差异。
3.1 子图 1 ◯ \textcircled{1} 1◯
子图
1
◯
\textcircled{1}
1◯: 对三个行为编码。
子图
1
◯
\textcircled{1}
1◯ 的数据说明:
- G G G:原始数据集,包含用户ID以及他们的购买、放入购物车、浏览三个行为。
- G 1 G_1 G1:用户和购买关系图;
- G 2 G_2 G2:用户和放入购物车关系图;
-
G
3
G_3
G3:用户和浏览关系图。
算法流程: - 利用GCN对三个行为进行编码,得到 X 1 X_{1} X1、 X 2 X_{2} X2、 X 3 X_{3} X3。
3.2 子图 2 ◯ \textcircled{2} 2◯
子图 2 ◯ \textcircled{2} 2◯求用户和商品的编码。 首先将 X 1 X_{1} X1、 X 2 X_{2} X2、 X 3 X_{3} X3拆分为用户在三个行为下的编码 X U 1 X_{U1} XU1、 X U 2 X_{U2} XU2、 X U 3 X_{U3} XU3和商品在三个行为下的编码 X I 1 X_{I1} XI1、 X I 2 X_{I2} XI2、 X I 3 X_{I3} XI3。接下来分别求用户的编码和商品的编码。
3.2.1 对用户编码
- 利用用户
u
u
u的购买、放入购物车、浏览三个行为的编码,对用户
u
u
u进行编码:
e u = σ { W ( ∑ k = 1 K a u k ∗ x u k ) + b } (1) \boldsymbol{e}_{\boldsymbol{u}}=\sigma\left\{\boldsymbol{W}\left(\sum_{k=1}^{K} a_{u k} * \boldsymbol{x}_{\boldsymbol{u} \boldsymbol{k}}\right)+\boldsymbol{b}\right\} \tag1 eu=σ{W(k=1∑Kauk∗xuk)+b}(1)
– a u k a_{u k} auk:用户 u u u的行为 k k k对应的权重;
– x u k \boldsymbol{x}_{\boldsymbol{u} \boldsymbol{k}} xuk:用户 u u u在行为 k k k下的编码,来源于 X U 1 , X U 2 , X U 3 X_{U1}, X_{U2}, X_{U3} XU1,XU2,XU3;
– W \boldsymbol{W} W和 b \boldsymbol{b} b:神经网络的权重和偏置; - 计算
a
u
k
a_{u k}
auk:分子为单个行为,分母为三个行为的加权累加和。
a u k = exp ( w k ∗ n u k ) ∑ m = 1 K exp ( w m ∗ n u m ) (2) a_{u k}=\frac{\exp \left(w_{k} * n_{u k}\right)}{\sum_{m=1}^{K} \exp \left(w_{m} * n_{u m}\right)} \tag2 auk=∑m=1Kexp(wm∗num)exp(wk∗nuk)(2)
– w k w_{k} wk:行为 k k k的权重,作者用的是一个全局的变量,所有用户采用相同的权重值,比如购买是0.5,放入购物车是0.3,浏览是0.2;
– n u m n_{u_m} num:用户 u u u在行为 m m m下的物品个数,比如张三购买了2个商品,将3个商品放入购物车,浏览了5个商品。 - 作者提供的代码里,本部分对应的代码如下。
– Lines181-183是式(2)的分子。在论文里, n u k n_{uk} nuk是the number of associations of user u u u under behavior k k k。但是在作者提供的代码里,使用的是各个行为下物品个数的占比。
– Lines184-186分别求出 a u 1 a_{u 1} au1、 a u 2 a_{u 2} au2、 a u 3 a_{u 3} au3。Line187 中pachas_u、cart_u以及view_u分别表示用户购买行为、放入购物车行为、浏览行为的编码矩阵。
– Line187为式(1)中的 ∑ k = 1 K a u k ∗ x u k \sum_{k=1}^{K} a_{u k} * \boldsymbol{x}_{\boldsymbol{u} \boldsymbol{k}} ∑k=1Kauk∗xuk。
3.2.2 对商品进行编码
- 将第
i
i
i个商品在行为
k
k
k下的编码拼接起来(Cat(
⋅
\cdot
⋅)),并利用多层感知机
g
(
⋅
)
g(\cdot)
g(⋅)计算
e
i
\boldsymbol{e}_{\boldsymbol{i}}
ei。
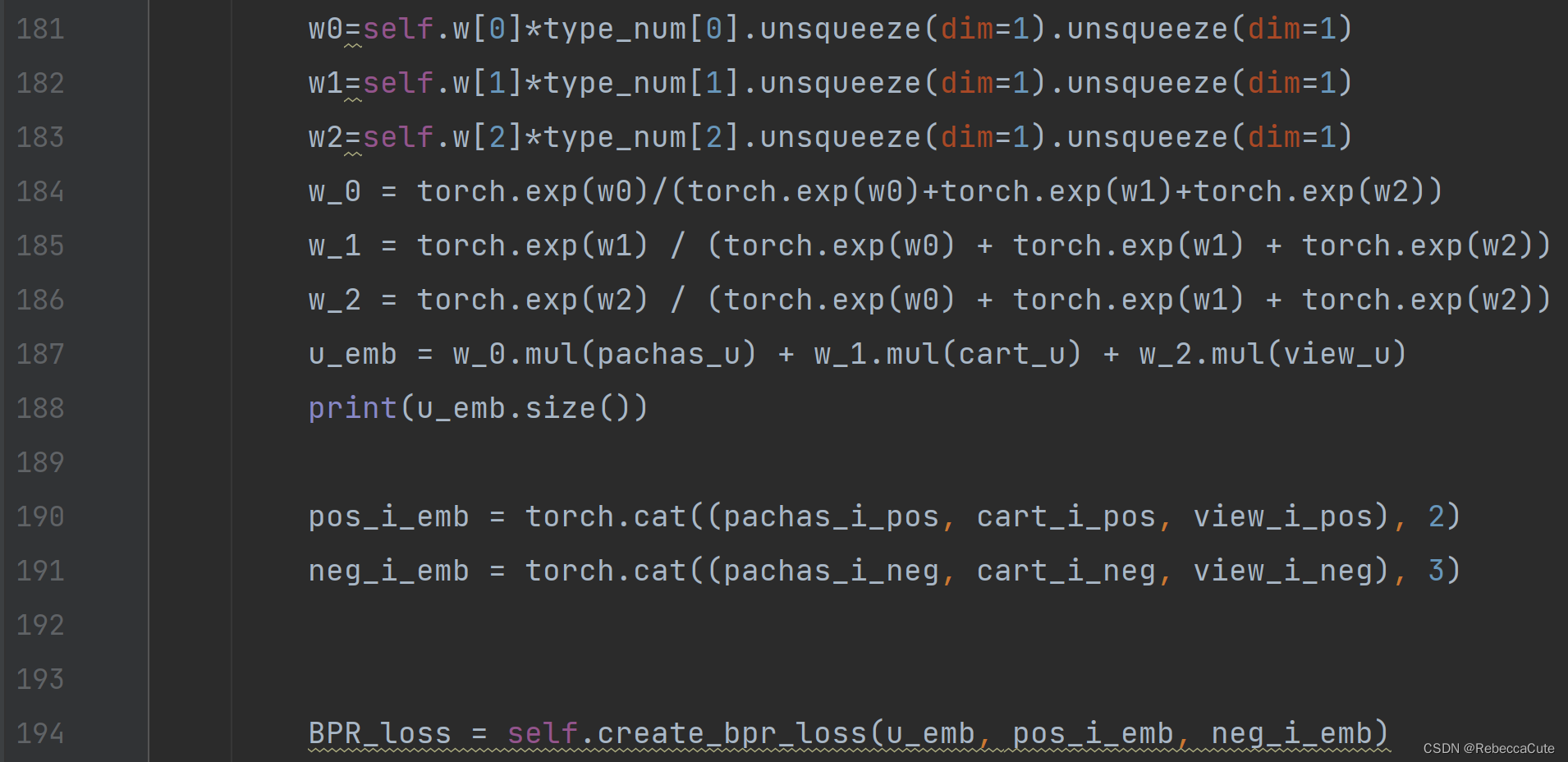
e i = g { Cat ( x i k ) } (3) \boldsymbol{e}_{\boldsymbol{i}}=g\left\{\operatorname{Cat}\left(\boldsymbol{x}_{\boldsymbol{i k}}\right)\right\} \tag3 ei=g{Cat(xik)}(3) - 作者提供的代码里,本部分对应的代码如上图。
– Line190和Line191是将物品三个行为的编码矩阵按照第二维和第三维进行拼接,得到pos_i_emb和neg_i_emb。
– Line194计算BPR loss。将Lines 187、190、191的 u _ e m b u\_emb u_emb、 p o s _ i _ e m b pos\_i\_emb pos_i_emb、 n e g _ i _ e m b neg\_i\_emb neg_i_emb作为输入,带入BPR loss计算式中,求得BPR loss。
3.3 子图 3 ◯ \textcircled{3} 3◯
子图 3 ◯ \textcircled{3} 3◯ 为利用constractive learning计算两两行为之间的差异:购买和放入购物车之间的差异、购买和浏览之间的差异。以下分两个方面考虑:用户购买和放入购物车之间的差异、购买和浏览之间的差异以及商品被购买和被放入购物车之间的差异、被购买和被浏览之间的差异。
3.3.1 计算用户购买和放入购物车之间的差异、购买和浏览之间的差异
计算式如下:
L
s
s
t
_
k
′
u
s
e
r
=
∑
u
∈
U
−
log
∑
u
+
∈
U
exp
{
(
x
u
1
)
T
x
u
+
k
′
/
τ
)
}
∑
u
−
∈
U
exp
{
(
x
u
1
)
T
x
u
−
k
′
/
τ
}
(4)
\mathcal{L}_{s s t\_k^{\prime}}^{u s e r}=\sum_{u \in U}-\log \frac{\left.\sum_{u^{+} \in U} \exp \left\{\left(\boldsymbol{x}_{\boldsymbol{u} \boldsymbol{1}}\right)^{T} \boldsymbol{x}_{\boldsymbol{u}^+\boldsymbol{k}^{\prime}} / \tau\right)\right\}}{\sum_{u^{-} \in U} \exp \left\{\left(\boldsymbol{x}_{\boldsymbol{u} \boldsymbol{1}}\right)^{T} \boldsymbol{x}_{\boldsymbol{u}^{-} \boldsymbol{k}^{\prime}} / \tau\right\}} \tag4
Lsst_k′user=u∈U∑−log∑u−∈Uexp{(xu1)Txu−k′/τ}∑u+∈Uexp{(xu1)Txu+k′/τ)}(4)
–
k
′
k^{\prime}
k′:取值为2和3,2代表放入购物车,3代表浏览;
–
u
+
u^{+}
u+和
u
−
u^{-}
u−:以用户
u
u
u为基础,找到用户
u
u
u的正用户集和负用户集,
P
M
I
P M I
PMI值用于衡量两个用户
u
u
u和
u
′
u'
u′的相似度。当该大于某个阈值时,
u
′
u'
u′为
u
u
u的正用户,否则为
u
u
u的负用户。计算方法如下:
P
M
I
(
u
,
u
′
)
=
log
p
(
u
,
u
′
)
p
(
u
)
p
(
u
′
)
p
(
u
)
=
∣
I
(
u
)
∣
∣
I
∣
p
(
u
,
u
′
)
=
∣
I
(
u
)
∩
I
(
u
′
)
∣
∣
I
∣
(5)
\begin{array}{c} P M I\left(u, u^{\prime}\right)=\log \frac{p\left(u, u^{\prime}\right)}{p(u) p\left(u^{\prime}\right)} \\ p(u)=\frac{|I(u)|}{|I|} \\ p\left(u, u^{\prime}\right)=\frac{\left|I(u) \cap I\left(u^{\prime}\right)\right|}{|I|} \end{array} \tag5
PMI(u,u′)=logp(u)p(u′)p(u,u′)p(u)=∣I∣∣I(u)∣p(u,u′)=∣I∣∣I(u)∩I(u′)∣(5)
式(5)中第一行对数后方的分子:为式(5)中第三行。式(5)中第三行计算两个用户
u
u
u和
u
′
u'
u′的相似度,其分子为两个用户在同一个行为下的相同商品的个数,分母为所有商品的个数。
式(5)中第一行对数后方的分母:为式(5)中第二行。计算用户
u
u
u在某个行为下的商品个数/所有商品的个数。
–
τ
\tau
τ:温度参数,作者的代码里
τ
\tau
τ取值为1。
3.3.2 计算商品被购买和被放入购物车之间的差异、被购买和被浏览之间的差异
- 计算商品被购买和放入购物车之间的差异、商品被购买和浏览之间的差异,计算方法与用户类似。 计算式如下:
L s s t _ k ′ i t e m = ∑ i ∈ I − log ∑ i + ∈ I exp { ( x i 1 ) T x i + k ′ / τ ) } ∑ i − ∈ I exp { ( x i 1 ) T x i − k ′ / τ } (6) \mathcal{L}_{s s t\_k^{\prime}}^{item}=\sum_{i \in I}-\log \frac{\left.\sum_{i^{+} \in I} \exp \left\{\left(\boldsymbol{x}_{\boldsymbol{i} \boldsymbol{1}}\right)^{T} \boldsymbol{x}_{\boldsymbol{i}^+\boldsymbol{k}^{\prime}} / \tau\right)\right\}}{\sum_{i^{-} \in I} \exp \left\{\left(\boldsymbol{x}_{\boldsymbol{i} \boldsymbol{1}}\right)^{T} \boldsymbol{x}_{\boldsymbol{i}^{-} \boldsymbol{k}^{\prime}} / \tau\right\}} \tag6 Lsst_k′item=i∈I∑−log∑i−∈Iexp{(xi1)Txi−k′/τ}∑i+∈Iexp{(xi1)Txi+k′/τ)}(6)
3.3.3 Contrastive learning中的问题
在作者提供的代码里,并没有看到PMI的计算。式(4)和(6)也与代码不一致。在代码里,Contrastive learning 的计算步骤为:
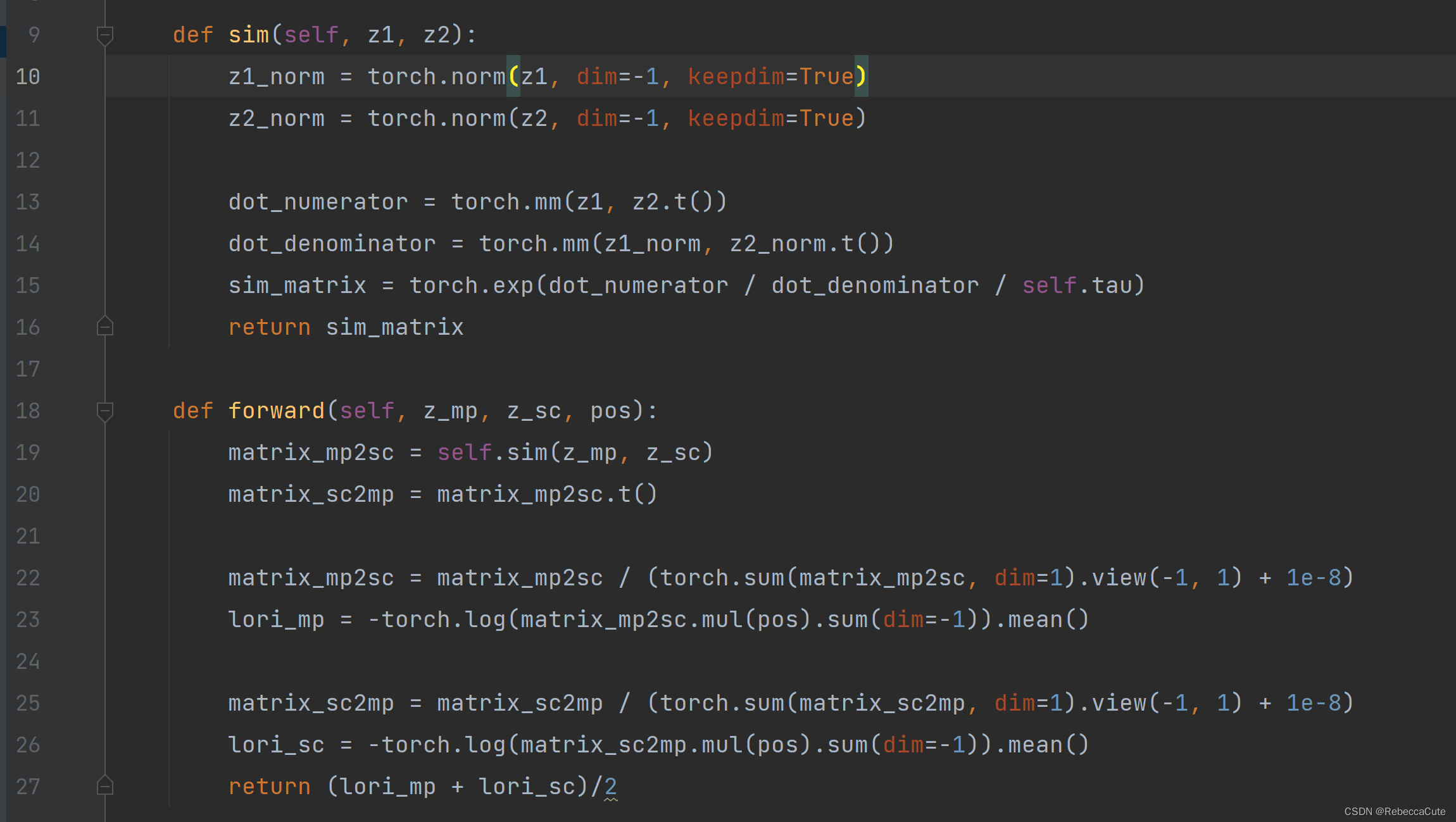
- Line 19调用Lines 9-16计算两个行为的相似度矩阵sim()
Lines10-11:分别计算用户在两个行为下的二范数。
Lines13-14:(未完待续) - 计算…(未完待续)
3.4 损失函数
总的损失函数如下:
L
=
L
s
t
+
λ
L
s
s
t
+
μ
∥
Θ
∥
2
2
(8)
\mathcal{L}=\mathcal{L}_{s t}+\lambda \mathcal{L}_{s s t}+\mu\|\Theta\|_{2}^{2} \tag8
L=Lst+λLsst+μ∥Θ∥22(8)
第一项为BPR Loss:
L
s
t
=
∑
(
u
,
i
,
j
)
∈
O
−
log
{
σ
(
e
u
T
e
i
−
e
u
T
e
j
)
}
(9)
\mathcal{L}_{s t}=\sum_{(u, i, j) \in O}-\log \left\{\sigma\left(e_{u}^{T} e_{i}-e_{u}^{T} e_{j}\right)\right\} \tag9
Lst=(u,i,j)∈O∑−log{σ(euTei−euTej)}(9)
- e u e_u eu:用户 u u u的编码;
- e i e_i ei:用户 u u u购买过、或放入购物车、或浏览过的商品编码;
- e j e_j ej:用户 u u u未购买过、或未放入购物车、或未浏览过的商品编码,作者在代码里面选的64个未产生过行为的商品。
第二项为对比学习产生的Loss:
L
s
s
t
=
∑
k
′
=
2
K
(
L
s
s
t
−
k
′
u
s
e
r
+
L
s
s
t
−
k
′
i
t
e
m
)
(10)
\mathcal{L}_{s s t}=\sum_{k^{\prime}=2}^{K}\left(\mathcal{L}_{s s t-k^{\prime}}^{u s e r}+\mathcal{L}_{s s t{-k^{\prime}}}^{i t e m}\right) \tag{10}
Lsst=k′=2∑K(Lsst−k′user+Lsst−k′item)(10)
- L s s t _ k ′ u s e r \mathcal{L}_{s s t\_k^{\prime}}^{u s e r} Lsst_k′user:同公式(4);
- L s s t _ k ′ i t e m \mathcal{L}_{s s t{\_k^{\prime}}}^{i t e m} Lsst_k′item:商品的Loss。
参考文献
[1] Self-supervised Graph Neural Networks for Multi-behavior Recommendation
[2] 源代码:https://github.com/GuShuyun/MBRec
[3]Chen Gao, Yu Zheng, Nian Li, Yinfeng Li, Yingrong Qin, Jinghua Piao, Yuhan Quan, Jianxin Chang,
Depeng Jin, Xiangnan He, et al. Graph neural networks for recommender systems: Challenges, methods, and directions.arXiv preprint arXiv:2109.12843, 2021.
[4]Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR conference on Research and Development in Information Retrieval, pages 165–174, 2019.
[5]Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. LightGCN:
Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 639–648, 2020.















 1389
1389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









