






源自:软件学报
作者:陈哲涵 黎学臻
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
摘 要
图数据, 如引文网络, 社交网络和交通网络, 广泛地存在现实生活中. 图神经网络凭借强大的表现力受到广泛关注, 在各种各样的图分析应用中表现卓越. 然而, 图神经网络的卓越性能得益于标签数据和复杂的网络模型, 而标签数据获取困难且计算资源代价高昂. 为了解决数据标签的稀疏性和模型计算的高复杂性问题, 知识蒸馏被引入到图神经网络中. 知识蒸馏是一种利用性能更好的大模型(教师模型)的软标签监督信息来训练构建的小模型(学生模型), 以期达到更好的性能和精度. 因此, 如何面向图数据应用知识蒸馏技术成为重大研究挑战, 但目前尚缺乏对于图知识蒸馏研究的综述. 旨在对面向图的知识蒸馏进行全面综述, 首次系统地梳理现有工作, 弥补该领域缺乏综述的空白. 具体而言, 首先介绍图和知识蒸馏背景知识; 然后, 全面梳理3类图知识蒸馏方法, 面向深度神经网络的图知识蒸馏、面向图神经网络的图知识蒸馏和基于图知识的模型自蒸馏方法, 并对每类方法进一步划分为基于输出层、基于中间层和基于构造图知识方法; 随后, 分析比较各类图知识蒸馏算法的设计思路, 结合实验结果总结各类算法的优缺点; 此外, 还列举图知识蒸馏在计算机视觉、自然语言处理、推荐系统等领域的应用; 最后对图知识蒸馏的发展进行总结和展望. 还将整理的图知识蒸馏相关文献公开在GitHub平台上, 具体参见: https://github.com/liujing1023/Graph-based-Knowledge-Distillation.
关键词
图数据; 图神经网络; 知识蒸馏
图数据(graph data)[1], 作为一种表示物体与物体之间关系的重要数据类型, 被广泛地应用在现实世界中任务场景中, 如用户推荐[2]、药物发现[3]、交通预测[4]、点云分类[5]和芯片设计[6]等. 不同于欧氏空间中的结构化数据, 图数据的结构复杂, 蕴含着丰富的信息. 为了从复杂的图数据中学习到包含充分信息的向量化表示, 越来越多的研究开始将深度学习方法应用到图数据领域. 借鉴卷积神经网络[7]的思想, 图神经网络(GNN)[8]被提出. 实践证明, 图神经网络已经在节点分类[9]、链接预测[10]、图分类[11]等任务得到了有效应用.
然而, 随着卷积算子的完善和大图规模的发展, 研究者开始考虑如何训练出高精度且高效的图卷积神经网络, 如尝试训练更深的网络来增强模型的泛化能力. 众所周知, 图神经网络作为半监督学习的方法, 其卓越的性能严重依赖于大量的高质量标签数据和高度复杂的网络模型, 而数据标签获取困难且大规模图模型计算存储代价高昂.
为了有效缓解GNN面临的数据标签稀疏性和模型计算的高复杂性问题, 知识蒸馏[12]技术被引入到图分析研究中. 知识蒸馏是一种基于“教师-学生(teacher-student, T-S)”网络思想的训练方法, 旨在通过将复杂、学习能力强的大网络模型(教师模型)学到的软标签知识蒸馏出来, 传递给参数量小、学习能力弱的小网络模型(学生模型), 用以提高小网络模型的性能, 从而达到接近大网络模型的效果, 最终实现模型压缩的目的. 由于知识蒸馏简单有效, 在学术界和工业界也获得一系列显著的成功应用, 如计算机视觉[13]、语音识别[14]、自然语言处理[15]等.
近年来, “教师-学生”知识蒸馏框架在训练图神经网络方面显示出其潜力. 受到知识蒸馏在卷积神经网络上成功应用的驱动, 研究者尝试在图数据上或直接在图神经网络上设计知识蒸馏算法, 将知识蒸馏和图神经网络相结合. LSP[16]是第1个将知识蒸馏应用到图卷积神经网络(GCN)[17]上的工作, 利用提出的局部结构保留模块将预训练深层GCN教师模型中的局部图结构知识蒸馏到具有较少参数的浅层GCN学生模型中. 随后, 也有一些其他面向图的知识蒸馏工作陆续被提出. 尽管知识蒸馏在图神经网络上取得了令人鼓舞的进展, 但现有的知识蒸馏方法一直集中在以结构化网格数据作为输入的卷积神经网络(CNN)上, 而在具有不规则数据处理能力的图神经网络上的研究却很少, 且目前缺乏对于图知识蒸馏研究的综述. 本文旨在对面向图的知识蒸馏进行全面综述, 首次系统地梳理现有知识蒸馏在图上的工作, 以弥补该领域缺乏综述的空白.
本文组织结构如后文图1所示, 本文第1节介绍图和知识蒸馏定义并给出图知识蒸馏研究的最新进展. 第2节梳理了面向图的知识蒸馏方法, 包括面向深度神经网络的图知识蒸馏、面向图神经网络的图知识蒸馏和基于图知识的模型自蒸馏3大类方法. 第3、4、5节按照蒸馏位置的不同, 针对不同类别的图知识蒸馏方法进一步细分为基于输出层、基于中间层和基于构造图的知识蒸馏方法, 并对现有的方法进行详细归纳和总结. 第6节对比分析经典的图知识蒸馏算法. 第7节列举图知识蒸馏方法在计算机视觉、自然语言处理、推荐系统等场景中的应用. 第8节展望面向图的知识蒸馏未来研究方向. 最后一节总结全文.
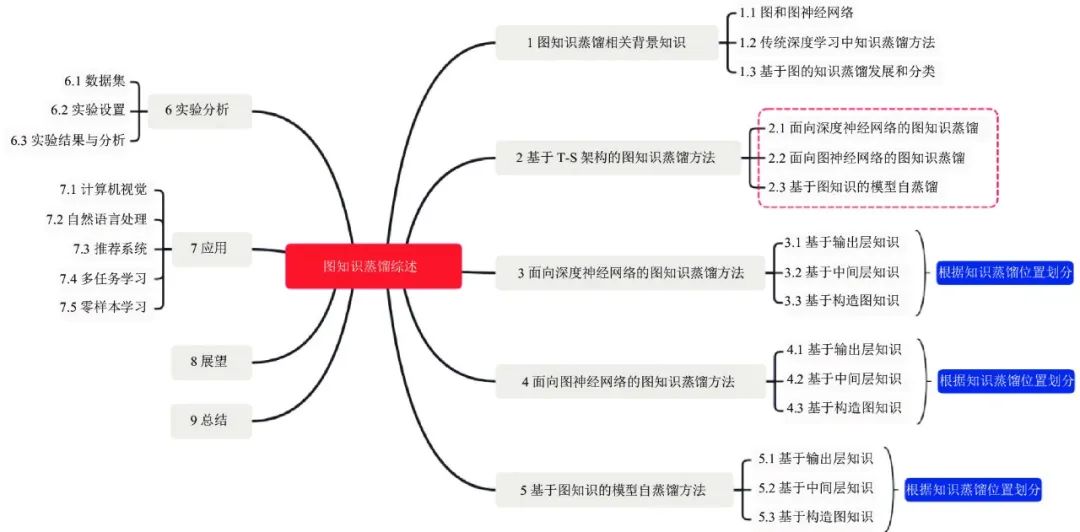
图 1 本文的组织结构图
1 图知识蒸馏相关背景知识
在具体介绍图知识蒸馏方法之前, 本节先给出图知识蒸馏技术涉及的基本概念和符号定义, 接着对图知识蒸馏方法的发展和划分标准进行简要说明.
1.1 图和图神经网络
尽管深度学习已经在欧氏空间的结构化数据中取得了很大的成功, 但现实生活中的数据一般自然的建模为图这样的非结构化数据. 图(graph)作为一种常见的数据结构, 可以表示为顶点V和边E的集合, 记为G=(V,E). 由于图结构的强大表现力, 其被广泛地应用于图分析研究中. 例如, 在电商推荐[18]领域, 需要一个基于图的学习系统, 能够利用用户和产品之间的交互实现高度精准的推荐. 图数据的复杂性对现有机器学习算法提出了重大挑战: 每张图大小不同、节点无序, 且一张图中的每个节点都有不同数目的邻居节点, 使得深度学习中常规的卷积运算无法直接应用于图数据. 近年来, 借鉴CNN的卷积思想, 研究者开始尝试将深度学习方法应用到图分析领域. 自此, 图神经网络(GNN)[8]诞生, 由于其较好的性能和可解释性, GNN 最近已成为一种广泛应用的图分析方法.
最近, 深度学习领域关于图神经网络的研究热情日益高涨, 已经成为各大领域的研究热点. GNN处理非结构化数据时的出色能力使其在生物化学[19]、物理建模[20]、知识图谱[21]和电路设计[22]等方面都取得了新的突破. 随着图神经网络模型的发展, GNN主要可以分为谱方法和空间方法.
一方面, 基于谱的方法从图信号处理的角度引入滤波器来定义图卷积. 2013年Bruna等人[23]基于谱理论[24]将频域卷积操作的概念引入到图神经网络中, 首次提出了频域卷积神经网络模型(spectral CNN). 自此, 在基于谱的图卷积网络方法得到了进一步改进和拓展[25-28]. 例如, ChebyNet[25]利用切比雪夫多项式的矩阵形式参数化核卷积, 极大地减少了spectral CNN参数量和计算复杂度, 从而使得谱方法变得实用起来. 但是, 谱方法在计算的时候通常需要同时处理整个图, 并且需要承担矩阵分解时的高时间复杂度, 难以并行或扩展到大图上. 因而, 基于空域的图卷积网络开始快速发展.
另一方面, 基于空间的方法直接在图结构上执行卷积操作, 将图卷积表示为从邻域聚合特征信息. GCN[17]作为空间方法的代表性工作, 对频域图卷积进行一阶近似来进一步简化, 使得图卷积的操作能够在空域进行, 极大地提升了图卷积模型的计算效率. 此外, 为了加快图网络的训练, GNN还可以和采样策略相结合, 包括SAGE[29]、FastGCN[30]、LADIES[31]等方法, 通过将计算限定在一个批量的节点而不是整个图中以实现高效计算的目的(缓解训练时间和内存需求等问题). 随后, 为了使GCN更强大, 更多的基于空域的图卷积神经网络模型 [32-36]被提出, 并在多种图数据相关的任务上取得了令人瞩目的成效. 鉴于该方法的自由度高、可计算性好、推理效率高等优点, 空间方法得到了广泛关注和发展. 另外, 有很多学者从不同角度(如方法、应用等)对图神经网络模型进行梳理和总结, 具体可以参考综述[37-47].
尽管图神经网络已经被证明是一种强大的非网格数据模型, 但是原始GNN依旧存在一定的局限性, 主要有两点: (1)现有的GNN模型大多是半监督学习, 这就使得其性能会严重依赖于高质量标签数据; (2)随着图数据规模的发展, 现有的图模型设计得越来越复杂, 这对图模型计算和图数据存储带来了一定挑战. 知识蒸馏在计算机视觉上的成功应用, 为上面两个挑战提供了一种可行的方案. 本文的第1.2节将简单回顾知识蒸馏在深度学习中的发展.
1.2 传统深度学习中知识蒸馏方法
知识蒸馏[12]最初被提出用于模型压缩, 不同于模型压缩中的剪枝和量化, 知识蒸馏(knowledge distillation, KD)采用教师-学生(teacher-student, T-S)模式预先训练一个大的教师模型来蒸馏得到一个轻量化的学生模型, 以此来增强学生模型的泛化能力, 达到更好的性能和精度. 通过蒸馏, 教师模型中的“知识”(软标签监督信息)会转移到学生模型中. 通过这种方式, 学生模型可以减少时间和空间的复杂性, 还可以学习到在独热标签上学不到的软标签信息(这些里面包含了类别间信息), 从而不会失去预测的质量. 通常, 根据知识迁移方式的不同, 知识蒸馏可以被分成2种技术路线.
第1种是目标蒸馏, 该方法与标签平滑密切相关[48], 利用教师模型的输出类别概率作为平滑标签来训练学生. 文献[12]是知识蒸馏的开山之作, 由Hinton等人在2015年提出, 首次提出将教师模型的Softmax层输出的类别的概率作为“Soft-target”迁移到学生模型中, 从而提高小网络性能. 为了学习学生网络中的反馈信息, DML[49]提出深度相互学习策略, 让一组学生网络同时训练, 通过真实标签的监督和同伴网络输出结果的学习经验实现相互学习共同进步. BAN[50]基于蒸馏的思想, 使用集成的思路训练学生模型, 使其网络结构和教师模型一样, 同时在计算机视觉和语言建模下游任务上明显优于其教师模型.
另一类知识蒸馏思路是特征蒸馏方法, 利用教师网络结构中的中间层特征表示所包含的语义信息作为知识迁移到学生模型中. FitNet[51]是最早采用这种方法的经典工作, 利用教师网络的输出和中间层的特征作为监督信息, 对文献[12]的知识蒸馏方法进行扩展, 实现深度模型网络压缩的问题. 基于特征蒸馏的方法现已成为主流, 包括注意力机制的使用[52], 特征空间的概率分布匹配[53,54]等. 在此之后, 基于特征蒸馏的方法还衍生出了一些基于关系蒸馏的新方法[55-61], 不过它们均旨在将Teacher中的特征知识迁移给Student.
无论是哪一种蒸馏策略, 这些方法大多都是针对以网格数据为输入的卷积神经网络设计的. 幸运的是, 最近涌现出了在图和图神经网络上设计知识蒸馏的方法. 在接下来的内容中, 本文将简要梳理总结出在图上设计知识蒸馏算法的图蒸馏方法.
1.3 基于图的知识蒸馏发展和分类
随着知识蒸馏技术的发展, 仅蒸馏单个样本信息的蒸馏方法不再适用, 因为它们所提供的信息有限. 为了提取不同数据样本间的丰富相关性信息, 关系知识蒸馏方法[55-61]被提出, 这类方法通过隐式/显式构建样本间关系图, 充分挖掘教师网络中样本间的结构化特征知识. 随后, 图神经网络作为一种强大的非结构化建模工具, 可以直接在图关系数据上建模, 因此借助图神经网络进行蒸馏可以轻松实现图拓扑结构知识和样本间语义监督信息的提取和传递. 因此, 本文将基于深度神经网络的关系知识蒸馏方法和基于图神经网络的蒸馏方法统称为图知识蒸馏方法. 图知识蒸馏旨在将教师模型中直接/间接构造的样本关系语义信息蒸馏到学生模型中, 以获得更加通用的、丰富的、充分的知识.
虽然GNN这种强大架构在建模非结构化数据时有着很好的性能表现, 但GNN的卓越性能需要依靠高质量的标签数据和复杂的网络模型, 而标签数据获取困难且计算资源代价高昂. 所以, 面对图神经网络中存在的数据标签的稀疏性和模型计算的高复杂性问题, 如何在保证性能的情况下设计出更小、更快速的网络, 成为研究的重点. 基于这种思想, 在图数据上设计知识蒸馏算法的方法脱颖而出, 涌现出了各种各样的方法. 同时随着知识蒸馏在图分析任务上卓越的表现, 图知识蒸馏研究受到广泛的关注.
本文采用层次化的分类方法对图知识蒸馏方法[16, 56-59, 61-119]进行分类, 首先将图知识蒸馏方法分为面向深度神经网络的图知识蒸馏方法、面向图神经网络的图知识蒸馏方法和基于图知识的模型自蒸馏方法, 再进一步根据方法蒸馏位置的不同将其分为基于输出层、基于中间层和构造图的知识蒸馏方法, 具体分类以及代表方法如图2所示. 需要注意的是, 在归纳总结基于图知识的模型自蒸馏方法时, 本文重点围绕图神经网络模型中的自蒸馏方法展开, 由于模型自蒸馏方法和GNN的结合近年来才被大家关注并研究, 因而方法相对于前两种比较少.
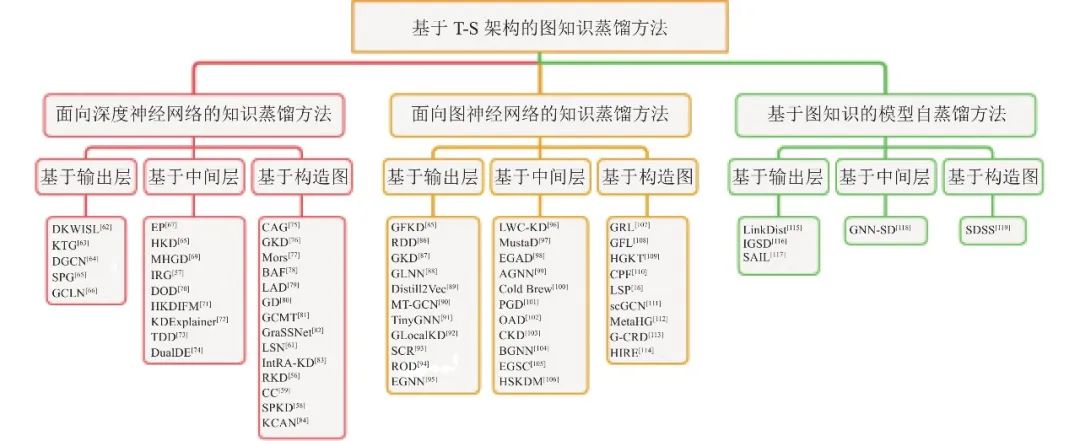
图 2 图知识蒸馏方法分类
2 基于T-S架构的图知识蒸馏方法
本节根据知识蒸馏算法设计的特点, 将图知识蒸馏方法分为面向深度神经网络的图知识蒸馏方法、面向图神经网络的图知识蒸馏方法和基于图知识的模型自蒸馏方法, 并对这3类方法分别进行介绍和分析. 其中, 表1汇总了全文中常见的符号及其表示的含义.
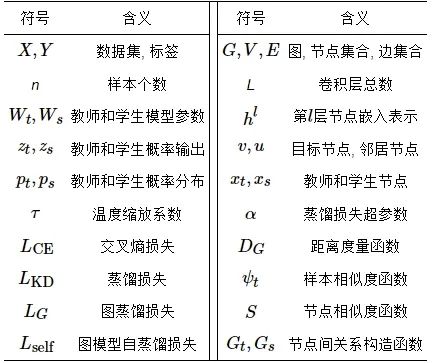
表 1 符号定义
2.1 面向深度神经网络的图知识蒸馏
首先, 为了简化表示, 本文将参数为Wt 的表现良好的教师模型记做T, 同样地, 将参数为Ws 的学生网络模型记做S . 卷积神经网络输入数据集记为X={x1,x2,…,xn} , 对应的标签记为Y={y1,y2,…,yn} , n 表示数据集中的样本个数. 由于深度神经网络可以看作是由多个非线性层叠加而成的映射函数, 则教师和学生的非归一化的概率输出分别记为zt=ϕ(X;Wt) 和zs=ϕ(X;Ws) , 其中ϕ 是映射函数. pt=Softmax(zt) 和ps=Softmax(zs) 分别表示教师和学生的最终预测概率.
知识蒸馏最早由Hinton 等人[12]提出, 目的是将隐藏在大型网络(教师模型)中的知识传递到轻量级小型网络(学生模型)中, 使得学生模型获得更好的性能. 知识蒸馏的基本思想是通过温度τ�缩放Softmax输出层软化类概率分布, 得到软目标:
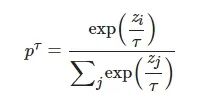
(1)
其中, τ表示温度缩放系数, 用于软化教师模型的输出, 当τ越大, 输出概率越平滑.
Hinton 等人[12]还发现了在训练过程中将软目标和真实标签一起指导学生模型, 会进一步提升学习效果, 具体是通过将这两部分的损失函数进行加权. 于是, 知识蒸馏的损失可以表示为:
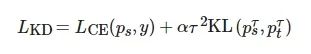
(2)
其中, 第1部分LCE 就是传统的交叉熵损失, 即学生模型的预测输出ps 与真实标签y 的交叉熵, 第2部分就是学生模型经过τ 平滑后的预测输出pτs 与教师模型经过温度τ 平滑后的预测输出pτt 的交叉熵, α 为调节两个损失函数比例的超参数, KL为Kullback-Leibler散度.
然而, 传统的深度学习中的知识蒸馏方法(如公式(2)所示)大多都是针对单个样本进行学习. 为了进一步提升性能, 研究人员提出了特征蒸馏[51-54]和关系蒸馏[55-61]方法. 其中, 蒸馏效果最为显著的是关系知识蒸馏方法, 这类方法在本文中称为隐式构造图方法. 后续更是涌现出大量在中间卷积层或输出层中构建显式的样本关系图知识蒸馏方法, 尝试令学生模型去模拟教师模型中样本间的相似性而不再是模拟教师模型中单个样本的输出结果. 因此, 借助于构建的隐式/显式的样本关系辅助图, 学生模型可以充分挖掘教师网络中样本间的结构化特征信息, 实现从教师模型中提取通用的、丰富的、充分的知识来指导学生模型, 其概念图如图3所示.
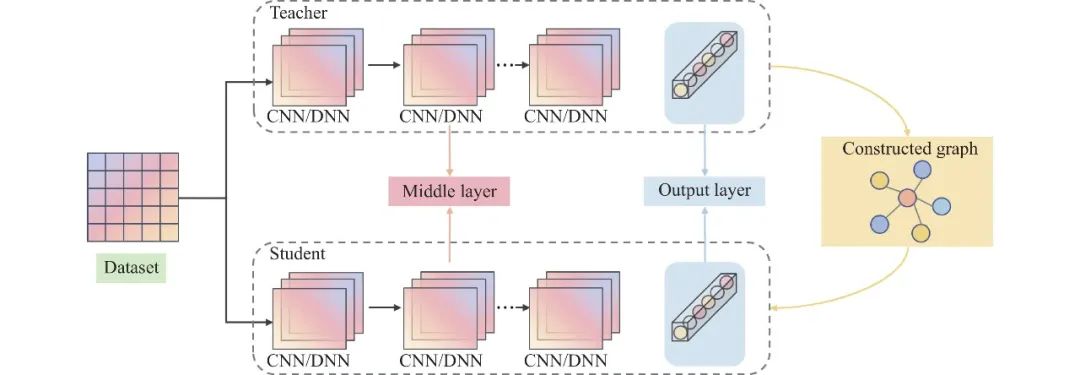
图 3 面向深度神经网络的图知识蒸馏方法框架
● 方法实现: (1)首先, 分别针对CNN/DNN框架下的教师和学生模型得到的样本特征表示, 构造其各自的样本关系图(如图3所示的constructed graph部分), 其中不同颜色的顶点表示不同的训练样本. (2)其次, 使用相似性函数分别计算教师和学生网络样本间的相似性. (3)最后, 使用距离度量函数最小化学生和教师的特征分布, 以保证学生模型可以学习多个输入样本在教师模型特征空间的相关性.
因此, 面向深度神经网络中的图知识蒸馏方法的最终的损失计算如公式(3)所示:
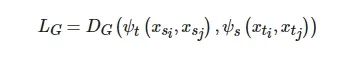
(3)
其中, xsi 和xsj 表示学生网络中的两个输入样本i,j , 同理xti 和xtj 表示教师网络中的两个样本. ψt(⋅) 和ψs(⋅) 分别表示学生和教师网络中样本间相似度函数(如余弦相似度、Jaccard相似度等), DG 表示最小化学生和教师网络中构造图的距离度量函数, 可以是任意距离函数, 如欧氏距离、MSE、KL等.
● 特点和优势: 隐式/显式构造图方法大多发生在中间卷积层上, 如图3所示, 借助于构建好的构造图, 学生模型可以将教师模型学习到的丰富样本间相关性知识直接提取到学习模型中, 而不再只是拟合教师模型中单个输入样本的输出类概率分布. 这样做的益处在于: 学生模型可以捕获到教师模型输入样本间的空间几何特征知识, 实现更准确地衡量样本特征之间的相似性, 进而提高学生模型的知识蒸馏学习效果. 在深度神经网络的知识蒸馏方法中, 基于构造图进行知识蒸馏的方法[56-59, 61-84]成为当下的研究热点, 相关工作将在第3节根据知识蒸馏位置的不同进行详细的分类和介绍. 然而, 如何正确地构造图来建模数据的结构知识仍然是一个具有挑战性的研究.
2.2 面向图神经网络的图知识蒸馏
本节首先对图神经网络的嵌入表示学习进行简化描述. 图作为一种常见的数据结构, 被用来广泛描述各种关系型数据. 其形式化表达如下, 图可以被表示为G=(V,E) , 其中V 是顶点集合, |V|=N 表示图上共有N 个节点, E是边集合. 同时, 本文用x表示图G 上的节点特征, 其中x∈RN×D,xi∈RD 表示第i 个节点的特征, xij 表示第i 个节点的第j 个特征. 图表示学习主要是遵循消息传递范式[34]: 针对每一个节点v∈V , 经过多层迭代聚合其邻域节点信息和节点本身的特征来更新节点的特征, l 次迭代后, 得到v 的节点嵌入表示:
![]()
(4)
其中, u 是节点v 的邻居节点, Nv 是节点v 的邻域节点集合; AGG 是聚合函数, 如sum, mean或max; Φ 是消息函数, 如MLPs (multilayer perceptrons); σ 是更新函数, 如ReLU激活函数.
尽管GNN现已成为当下图数据挖掘的研究热点, 并成功应用在医药、推荐、芯片设计等工业领域, 但GNN的性能严重依赖于大量高质量有标签数据和高度复杂的网络模型. 为了获得一个具有强泛化能力的GNN模型, 研究人员聚焦于在图数据上设计知识蒸馏算法, 将知识蒸馏与图神经网络相结合.
相比于深度神经网络中构建辅助图进行图知识蒸馏, 图神经网络作为一种强大的非结构化建模工具, 可以直接对图数据进行建模, 从而自然地挖掘教师模型中的图结构知识信息并传递到学生模型中. 面向图神经网络的图知识蒸馏方法类似于深度神经网络中的方法, 也是从图卷积中间层/输出层进行知识的提取. 为了进一步分析输入图数据结构节点间的关系, 在图神经网络中也会进一步借助构造图来学习教师模型图拓扑结构和节点关系信息, 以深入挖掘教师模型所学知识, 其概念图如图4所示.
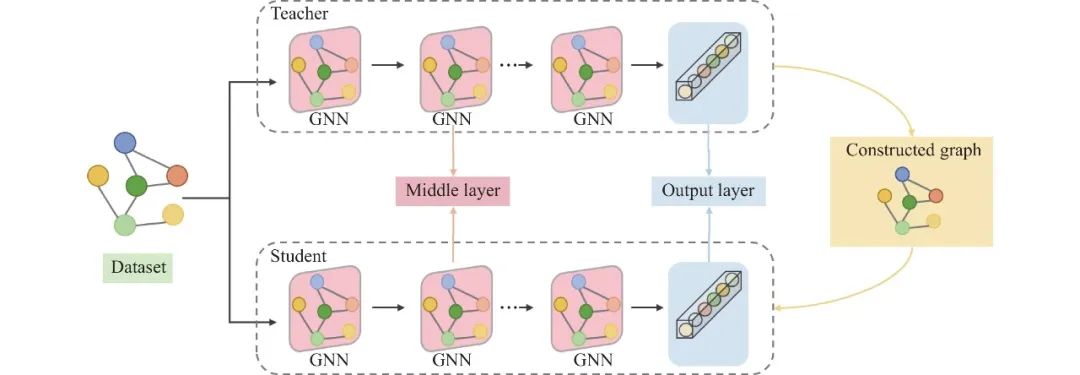
图 4 面向图神经网络的图知识蒸馏方法框架
● 同样地, 面向图神经网络的图知识蒸馏方法也主要分为以下4个步骤: (1)首先, 分别基于GNN框架下教师和学生模型的中间特征表示, 构造其各自的节点间关系图(如图4所示的constructed graph部分), 其中不同颜色的顶点表示不同的节点(异构图中则表示不同类型的异构节点). (2)其次, 使用相似性函数度量教师和学生网络内部拓扑结构节点间的相关性. (3)然后, 使用距离度量函数计算教师和学生网络的各自内部节点表示之间的差异损失. (4)最后, 将所有用于传递知识层的损失进行累加, 从而将图数据中的拓扑结构知识和样本关系知识迁移到学生模型中.
因此, 在图神经网络中, 图知识蒸馏最终的损失计算如下所示:
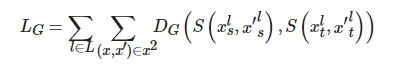
(5)
其中,
![]()
表示GNN第l 层中学生网络模型中的两个节点x, x′ , 同理
![]()
表示GNN第l 层教师网络模型中的两个节点. S 表示GNN卷积层/输出层中节点间相似度构造函数, DG 表示最小化学生和教师中构造图的距离度量函数, 如Huber、MSE、KL、MAE等.
● 特点和优势: 与面向深度神经网络的图知识蒸馏方法相比, 基于GNN的图蒸馏方法最大区别在于: GNN是建模图数据的强大工具, 可以直接在中间层/输出层进行知识蒸馏, 就可以将图数据节点间的拓扑结构知识传授给学生模型. 后续为了进一步挖掘特征空间中局部样本节点间的关系, 不少工作尝试在中间图卷积层构造节点间的关系图来提取节点间的相关性知识传递给学生模型, 如LSP[16]、HIRE[114]等. 知识蒸馏在图神经网络上的成功应用吸引了学术界和工业界的广泛关注, 涌现出了大量工作[16, 85-114]. 本文将其统一归纳为面向图神经网络的图知识蒸馏方法, 相关工作将在第4节根据知识蒸馏位置的不同进行详细的划分和介绍. 然而, 在GNN中, 如何更充分地挖掘图拓扑结构和语义信息进行知识迁移仍然是一个具有挑战性的研究.
2.3 基于图知识的模型自蒸馏
自蒸馏是一种基于T-S架构的图知识蒸馏方法的特例, 它是指不借助额外教师模型下进行知识迁移的特殊蒸馏方式. 自蒸馏, 顾名思义, 即单个网络模型既是学生模型又是教师模型, 通常是将自身深层和浅层之间的信息进行传递来指导自身的学习, 而无需教师模型的辅助. 与两阶段式的T-S图蒸馏方法相比, 自蒸馏方法简单高效, 成为当前实际落地项目中的首选, 其概念图如图5所示 (本文只针对图神经网络模型中的自蒸馏方法进行总结, 不包括面向深度神经网络中的自蒸馏方法) .
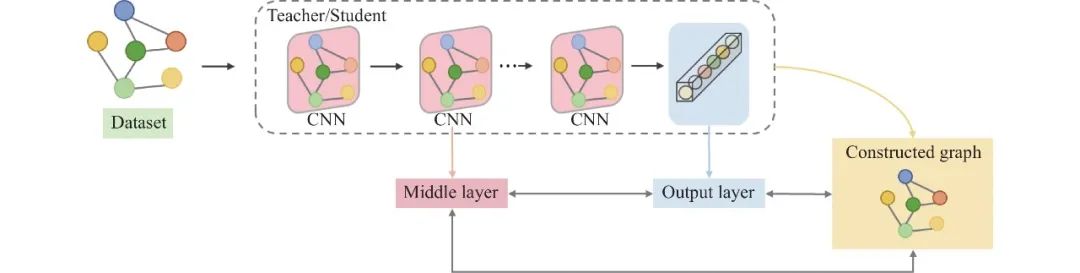
图 5 基于图知识的模型自蒸馏方法框架
● 基于图知识的模型自蒸馏方法实现步骤如下: (1)首先, 基于GNN框架下的模型的中间层/输出层特征表示, 构造节点间关系图(如图5所示的constructed graph部分), 其中不同颜色的顶点表示不同的节点(异构图中则表示不同类型的异构节点). (2)然后, 使用相似性函数度量GNN模型浅层和深层在特征空间中各自的内部拓扑结构节点表示间的相似性. (3)最后, 使用距离度量函数计算浅层和深层网络的差异损失, 通过多次迭代计算可以学习到更加多样性的知识.
因此, 在图神经网络中, 基于图知识的模型自蒸馏方法整体损失如下所示:
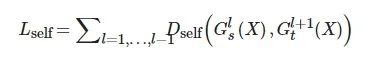
(6)
其中, X表示整图节点表示,
![]()
表示GNN浅层第l 层中节点间关系知识构造函数, 同理
![]()
表示GNN深层第l+1 节点间关系知识构造函数, Dself 表示浅层和深层构造图的距离度量函数, 如InfoCE、KL、MSE等.
● 特点和优势: 与传统两阶段T-S蒸馏方式相比, 自蒸馏的学习模式可以极大地节省模型训练时间, 大幅提高训练的效率, 而且可以实现在无教师指导下达到模型性能的提升. 但是自蒸馏也存在一定的不足: (1)缺乏了丰富的外部知识, 若可以显式地引入外部知识, 如与知识图谱结合使用, 或许对提升学生模型的性能有一定的帮助. (2)传统两阶段的T-S蒸馏方式和自蒸馏方式孰优孰劣暂无结论, 目前缺少对它们在相同的实验环境和任务上的对比分析, 值得进一步研究. (3)自蒸馏的理论分析还需进一步研究, 目前在CNN/DNN上的自蒸馏侧重于深层向浅层蒸馏效果, 而在GNN上则相反, 且缺乏理论支撑. 因此, 自蒸馏方法的通用性和灵活性有待进一步探讨.
3 面向深度神经网络的图知识蒸馏方法
知识蒸馏的核心在于知识的提取, 而知识存在于模型中的不同位置. 因此, 根据知识蒸馏的位置, 针对深度神经网络的图蒸馏方法, 将其划分为输出层、中间层和构造图知识. 本节主要对这3类知识传递形式进行介绍, 下面介绍的相关图蒸馏方法都是以此为基础, 具体见表2. 在具体图知识蒸馏方法描述时仅重点介绍各类图蒸馏算法最显著的知识蒸馏形式, 即若同时具有输出层、中间层知识的蒸馏方法默认划分为中间层知识蒸馏方法, 若同时具有这3类知识的蒸馏方法则默认划分为构造图知识蒸馏方法.
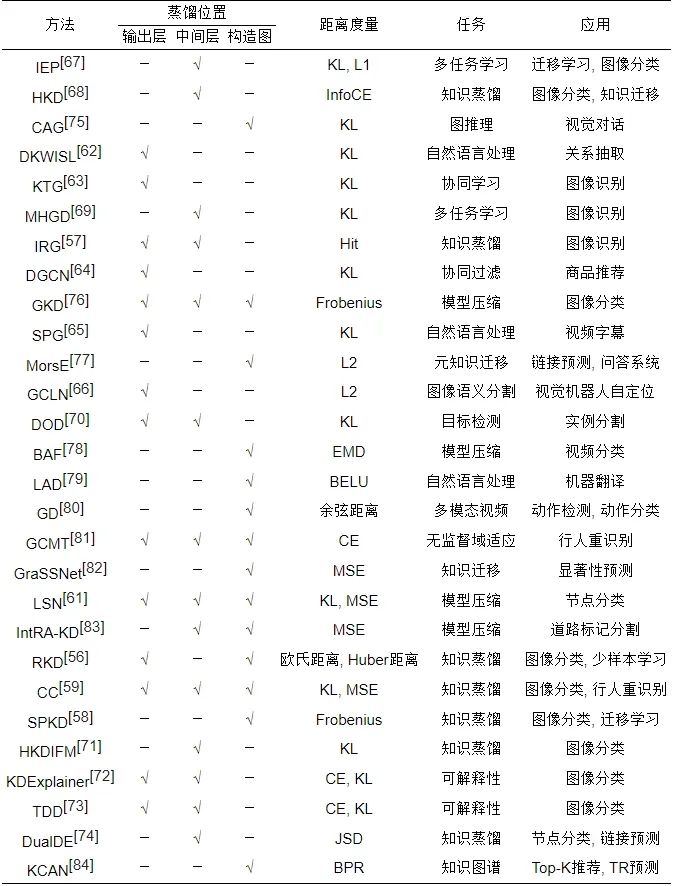
表 2 面向深度神经网络的图知识蒸馏方法汇总
● 相同点: 针对面向深度神经网络的图知识蒸馏方法中基于输出层、中间层和构造图这3类知识蒸馏形式, 每类图知识蒸馏算法的共性在于它们均是基于相同位置处知识的提取.
● 不同点: 针对每类图知识蒸馏算法, 它们的差异性体现在多个方面, 如具体方法实现、距离度量函数、下游任务及应用等方面上, 具体参见表2. 如在基于输出层知识的图知识蒸馏这类方法中: DKWISL[62]采用KL距离度量方式将知识蒸馏应用在自然语言处理上的关系抽取中, KTG[63]使用KL度量教师和学生间的分布差异将知识蒸馏用于协同学习的图像识别应用上, 而GCLN[66]则利用L2距离度量方式将知识蒸馏用于下游任务图像语义分割的视觉机器人自定位场景中. 在基于中间层知识的图知识蒸馏这类方法中: IEP[67]利用KL和L1相结合的距离度量方式将知识用于多任务学习上的迁移学习和图像分类中, HKD[68]使用InfoCE度量方法在图推理的视觉对话任务中引入知识蒸馏技术, 而IRG[57]则采用Hit度量方式将知识蒸馏运用于图像识别场景上.
同样地, 基于构造图知识的图知识蒸馏方法也是类似的: CAG[75]采用构造图知识蒸馏技术提升学生模型在下游图推理任务上的视觉对话表现, GKD[76]利用Frobenius最小化教师和学生间的分布差异并对学生模型进行压缩, MorsE[77]则使用L2度量方法进行元知识的迁移以提升学生模型在链接预测和问答系统上的表现.
3.1 基于输出层知识
基于输出层知识是网络模型最后一层预测输出所蕴含的标签监督信息, 是目前深度神经网络中最流行的知识蒸馏形式, 自KD[12]方法被提出以来, 这类方法便受到学者的广泛关注, 随后衍生出了大量优秀工作, 本节重点关注CNN/DNN上输出层借助于辅助图的图蒸馏方法, 即考虑样本间关系的图知识蒸馏方法.
最早的输出层图知识蒸馏可以追溯到Minami等人[63]提出基于图来控制知识转移的方法KTG, 通过知识转移统一视图, 来表示不同的知识转移模式, 同时还引入4种类型的门函数控制网络训练时的反向传播, 来探索不同的知识转移组合形式. 同年, Wang等人[64]借助于GNN模型, 将GCN模型中的排名信息蒸馏到二进制模型中, 以充分挖掘商品数据中用户和商品间的丰富连接信息, 成功实现在线推荐模型的性能提升和隐式反馈推荐的加速. 同时, Zhang等人[62]也提出将输出层软标签和GCN模型结合使用, 成功将输出层知识应用在自然语言处理领域中. 具体地, DKWISL首先从整个语料库获得类型限制的soft rules, 而后教师模型将设计的soft rules与GCN相结合并针对每个实例得到最终的软标签, 其模型架构见图6.
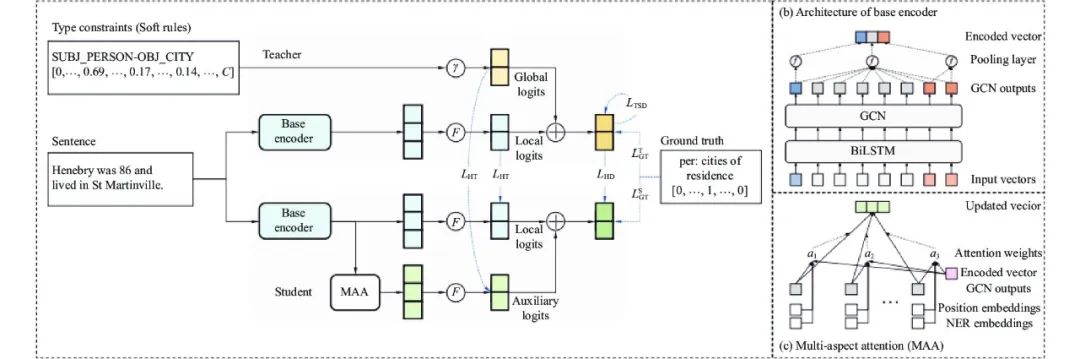
图 6 DKWISL[62]的输出层知识蒸馏
此外, 还有一些相关工作被提出. Pan等人[65]认为以往视频描述模型没有清晰地建模对象间的相互作用, 提出一个新颖时空图网络明确利用时空对象交互, 同时引入一种具有对象感知的知识蒸馏机制SPG, 利用局部对象信息对全局场景特征进行正则化, 解决了时空图模型中存在的噪声特征学习问题. Koji等人[66]将输出层知识蒸馏应用于机器人自定位应用中, 即通过设计一种基于秩匹配的教师-学生知识转移方案GCLN, 将现有的教师自定位模型的倒数秩向量输出作为暗知识转移到学生模型中.
3.2 基于中间层知识
考虑到输出层知识蒸馏方式的单一性, 为了进一步挖掘教师网络中蕴含的丰富知识, 很多研究学者开始研究如何将中间卷积层中的特征知识也转移到学生网络中, 以获得更充分的特征表示. FitNets[51]是最先使用中间层特征蒸馏的方法, 旨在利用教师模型特征提取器的中间层输出作为hints, 对更深更窄的学生模型进行知识蒸馏. 不同于简单的中间层特征蒸馏. 本节重点介绍基于中间层特征关系知识, 汇总在深度神经网络上进行蒸馏的方法. 在这类方法中, 最具有代表的工作是Liu等人[57]在2019年CVPR上提出的IRG方法(见图7).

图 7 IRG[57]的中间层知识蒸馏
从图7得知, 不同于只考虑实例特征知识, IRG还额外引入实例关系、特征空间变化这两种知识. 具体地, 该模型为了建模网络中间层的抽象知识, 通过将实例特征和实例关系分别作为顶点和边来构建一个实例关系图IRG, 并基于此提出IRG变换的跨层特征空间的图蒸馏方法, 实验验证了该方法有效地捕获整个网络上的知识, 同时对不同的网络结构具有较强的鲁棒性.
IRG图蒸馏方法的成功, 催生了大量相关工作. 比如, Lee等人[69]提出一种利用多头注意机制将教师嵌入过程中的知识提取为图, 并通过多任务学习使学生具有关系归纳偏置的能力的MHGD图知识蒸馏方法. Passalis等人[71]认为现有的KD方法通常忽略了神经网络在训练过程中经历的不同学习阶段, 提出在关键学习阶段令学生模型模拟教师模型的信息流, 以确保网络各层次之间形成必要的连接, 旨在实现知识的有效传递. Lee等人[67]认为良好的知识应该能够解释嵌入过程, 于是提出一种基于主成分分析的可解释嵌入过程(IEP)知识生成方法, 利用MPNN[34]提取该知识, 并通过可视化证实了IEP对嵌入过程知识的可解释性. Zhou等人[68]认为当前个体知识和关系知识之间的关系被忽略, 提出基于实例间的属性图来从教师网络中提取整体知识, 实现个体知识和关系知识的融合, 同时保留了两种知识之间的相关性, 使得学生模型在训练时获得充足的知识. Xue等人[72]提出KDExplainer来阐明在KD过程中软目标的工作机制, 发现KD可以隐式调节子任务间的知识冲突, 比标签平滑更有效, 同时基于这些观察结果, 还提出了一个便携式紧凑模块VAM, 进一步改善基础KD的结果. Song等人[73]为了弄清楚预训练的教师模型背后解决问题的过程, 提出了一种新的树状决策蒸馏(TDD), 通过layer-wise方式剖析教师决策过程, 并将相同的决策约束强加于学生模型, 促使学生掌握相同的问题解决方案, 最终, TDD成功探索了教师的决策过程, 发现教师的决策过程以从粗(浅层获得粗粒度判别)到细(深层获得细粒度判别)的方式进行. Zhu等人[74]在蒸馏过程中考虑了教师和学生之间的双重影响, 提出了一种名为DualDE的新型知识图谱表示蒸馏方法, 通过将教师和学生的三元组输出分数和中间层嵌入结构知识均蒸馏给彼此, 并引入软标签评估机制来评估教师/学生提供的软标签质量, 以实现学生和教师的双重优化. Chen等人[70]基于每个感兴趣区(RoI)实例之间的关系设计了一个结构化实例图, 同时利用实例特征和特征间的相似性, 以结构化的方式传递知识, 保证学生模型可以捕获全局拓扑结构知识和软标签知识.
基于中间层知识的蒸馏方法不仅可以蒸馏单个样本的知识, 还可以蒸馏特征空间样本关系知识到学生网络中, 成为当前深度神经网络中图知识蒸馏的重要方法之一.
3.3 基于构造图知识
为了更好地建模教师网络中样本间关系监督信息, 构造图知识蒸馏方法被提出. 基于构造图的知识蒸馏方法是中间层图知识方法的扩展, 旨在通过构造显式的辅助图结构模块来深入挖掘教师网络中样本特征间的高阶关联知识. RKD[56]是该类方法的代表工作, 由Park等人在2019年提出, 通过实验证明了提取样本间的关系结构信息优于提取单个样本的特征信息, 如图8所示.
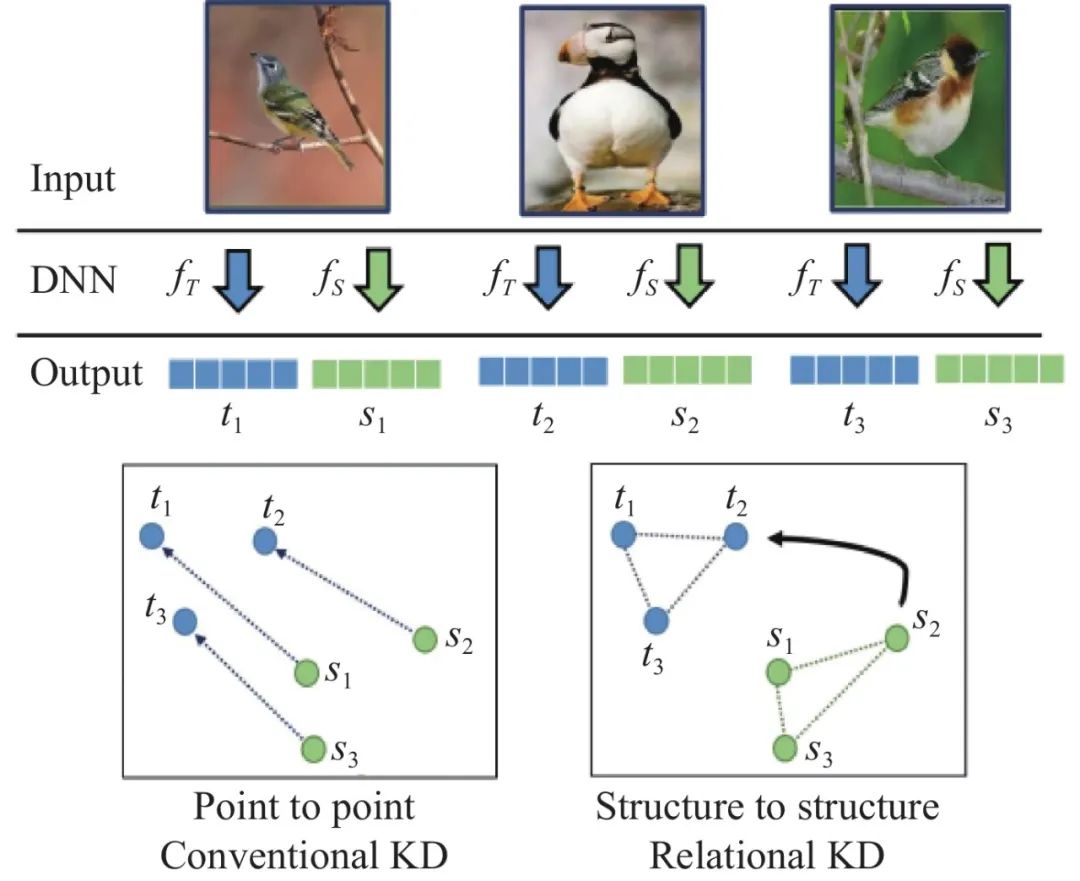
图 8 RKD[56]的核心思想
RKD这种通过以模型输出的结构信息进行蒸馏的方式被提出后, 基于构造图的知识蒸馏方法成为面向深度神经网络的图知识蒸馏研究热点. 与之相关的基于构造图知识工作应运而生. 例如, Zhang等人[78]认为当前视频表示学习局限在一个学习任务中且计算代价高昂, 提出利用logits和中间特征构造两个辅助图, 将多个自监督教师的知识传递给学生, 实现模型压缩的目标. Chen等人[61]从特征嵌入的新视角看待师生蒸馏范式, 通过引入局部位置保留损失LSN, 借助图来维持教师网络中高维空间中样本之间的关系知识, 鼓励学生网络生成低维特征, 以保留教师网络中对应的高维特征的实例间的关系信息. Peng等人[59]认为除了实例一致性之外, 实例之间的相关性也是增强学生表现的有价值知识. 于是提出相关一致性知识蒸馏框架CC, 该框架在传递知识时不仅考虑了输出层知识和中间特征知识, 还使用了基于图的知识(实例间的关联信息). Tung等人[58]观察到相似语义的输入往往会引发相似的激活模式, 因此引入了保持相似性知识蒸馏SPKD指导学生网络的训练, 使得学生不需要模仿教师的表征空间, 只需在其自身表征空间中保留成对的相似性. Lassance等人[76]扩展了RKD方法, 借助图捕获潜在空间的几何信息, 从而图将知识从教师架构转移到学生网络中.
另外, 除了将构造图知识蒸馏用于模型压缩和模型增强外, 很多学者探究KD在其他领域上的应用. He等人[79]引入语言图的概念, 并进一步提出了图蒸馏算法LAD来提高机器翻译的准确性. Luo等人[80]提出跨模态动态蒸馏方法GD, 将图蒸馏和域迁移技术相结合, 先在源域上训练, 然后固定基础模型在目标域上进行蒸馏, 实现多模态之间的知识迁移. Liu等人[81]针对无监督域自适应行人重识别任务, 通过在教师和学生网络之间构建图一致性约束, 提出了一种基于图一致性的均值教学(GCMT)方法, 有效地优化了包含更多样本相似关系的学生网络的蒸馏训练过程. Zhang等人[82]一种新的图语义显著性网络(GraSSNet), 借助于构造的辅助图, 对从外部知识中学习到的语义关系进行编码, 用于实现显著性预测. Tu等人[84]研究了如何引入外部知识图谱结构信息到推荐网络中, 通过局部条件注意力在采样子图上传播个性化信息来蒸馏知识图谱. Chen等人[77]针对知识图谱任务(KGs), 提出了一种新的任务元知识转移方法MorsE, 将元知识从构造的源KGs转移到新的目标KGs, 在链接预测和问答系统上均获得了优异的表现. Guo等人[75]提出了一个用于视觉对话的细粒度上下文感知图(CAG)蒸馏方案, 如图9所示, 旨在通过发现部分相关的情境并构建适当的图结构, 并从中获得广义意识能力, 来解决视觉对话任务中存在的噪声问题. Hou等人[83]将构造图知识蒸馏成功应用在道路标记分割场景中, 如图10所示, 基于构建的affinity graph特征相似图表征不同类型的道路标记, 即将给定的道路场景图像分解为不同的区域, 并将每个区域表示为图中的节点, 然后根据特征分布的相似性建立节点间的成对关系, 将结构知识提取到学生网络中.
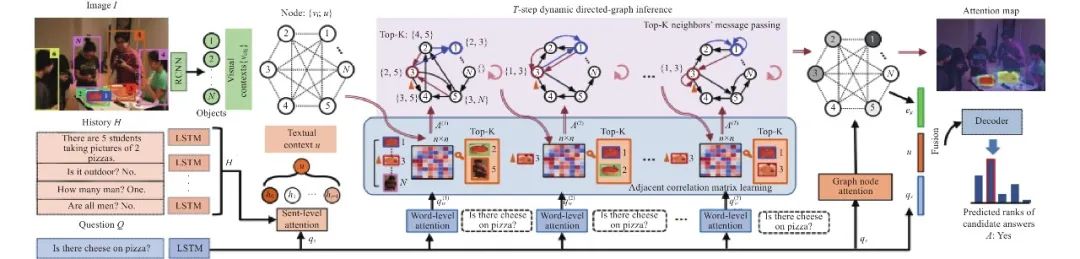
图 9 CAG[75]的构造图知识蒸馏用于视觉对话
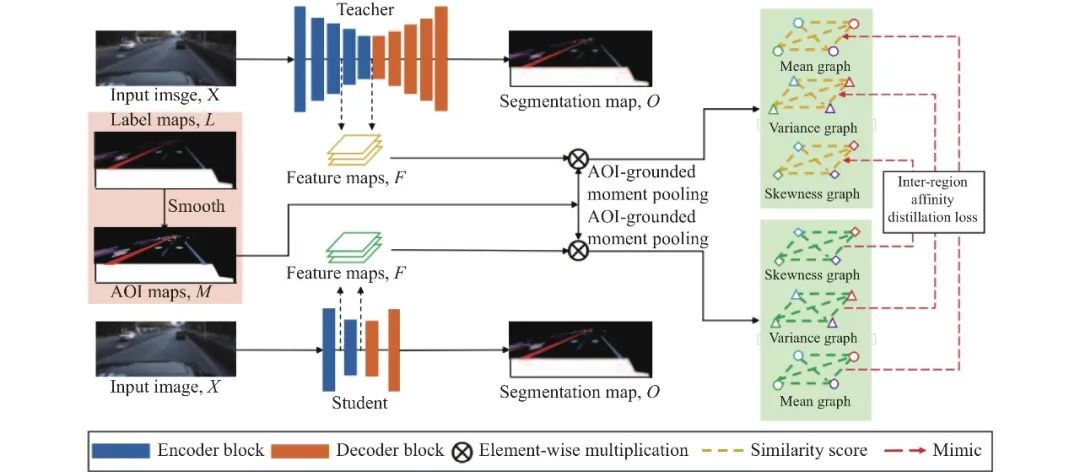
图 10 IntRA-KD[83]的构造图知识蒸馏用于道路标记分割
尽管面向深度神经网络的图知识蒸馏方法展现出了巨大的潜力, 并成功应用在多种下游任务中. 但是这类方法聚焦于CNN/DNN, 无法直接应用具有图结构形式的数据上. 近年来, 大量研究人员尝试将KD应用在GNN上, 并取得了令人印象深刻的成果, 这部分内容将在第4节进行具体阐述.
4 面向图神经网络的图知识蒸馏方法
类似地, 针对图神经网络中的知识蒸馏方法, 本节仍依照知识蒸馏的位置, 将其分类为基于输出层知识、基于中间层知识和基于构造图知识. 本节对面向图神经网络的图知识蒸馏方法进行细致划分, 具体如表3所示. 同样地, 这里仅重点介绍各类图蒸馏算法最显著的知识蒸馏形式, 即若同时具有输出层、中间层知识的蒸馏方法默认划分为中间层知识蒸馏方法, 若同时具有这3类知识的蒸馏方法则默认划分为构造图知识蒸馏方法.
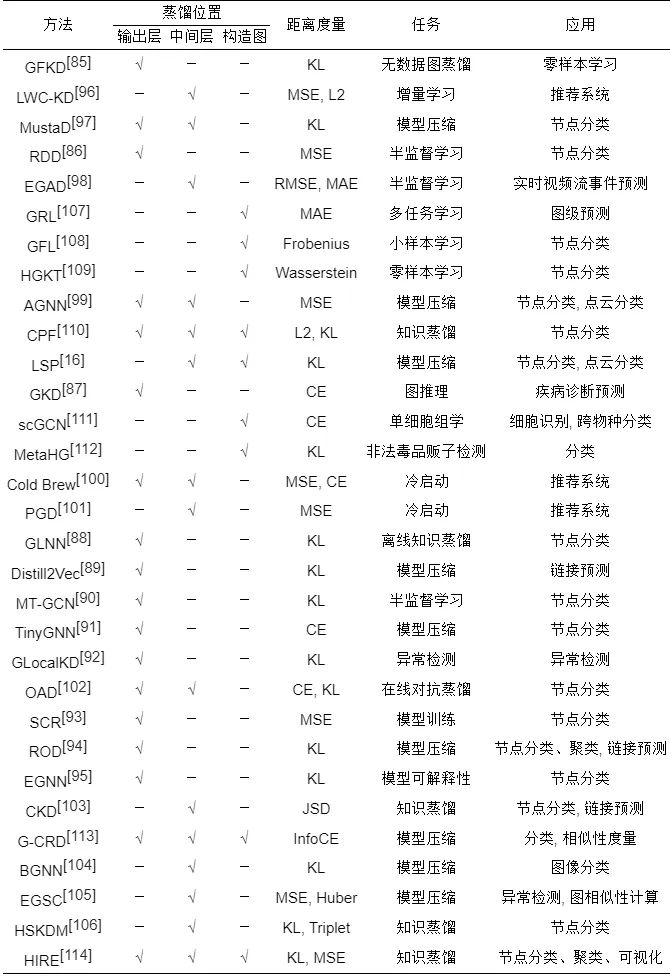
表 3 面向图神经网络的图知识蒸馏方法汇总
● 相同点: 针对面向图神经网络的图知识蒸馏方法中基于输出层、中间层、和构造图这3类知识蒸馏形式, 每类图知识蒸馏算法的共性在于它们均是基于相同位置处知识的提取.
● 不同点: 针对每类图知识蒸馏算法, 它们的差异性体现在多个方面, 如具体方法实现、距离度量函数、下游任务及应用等方面上, 具体参见表3. 如在图知识蒸馏中用KL散度的, 基于输出层有GFKD[85], GLNN[88], Distill2Vec[89]和MT-GCN[90]等; 基于中间层有MustaD[97], OAD[102], BGNN[104]和HSKDM[106]; 基于构造图有CPF[110], LSP[16], MetaHG[112]和HIRE[114]. 同样地, 用MSE度量方式的, 基于输出层有RDD[86]和SCR[93]; 基于中间层有LWC-KD[96], AGNN[99], Cold Brew[100]和EGSC[105]; 基于构造图有HIRE[114]. 此外, 还有一些使用其他距离度量函数来度量教师和学生模型之间分布差异的, 具体统计见表3.
4.1 基于输出层知识
受深度学习中图蒸馏技术的启发, 图神经网络相关研究人员将KD和GNN技术相结合, 已经成功应用在图数据挖掘的各种应用场景中, 包括推荐学习、异常检测、和细胞识别等. 本节重点关注GNN中基于输出层知识蒸馏方法.
KD在GNN上的应用近年来才开始受到大家关注, 输出层蒸馏工作最早可以追溯到2020年TinyGNN[91]工作的提出, 其蒸馏训练过程可见图11. TinyGNN是为了解决浅层GNN和深层GNN之间的邻居信息差距. 具体地, Yan等人提出了对等感知模块(PAM)和邻居蒸馏策略(NDS), 分别显式和隐式建模局部节点信息结构. 通过这种方式, TinyGNN可以有效地表征局部结构, 学习到更好的节点表示, 从而达到和深层GNNs相同甚至更好的表现.
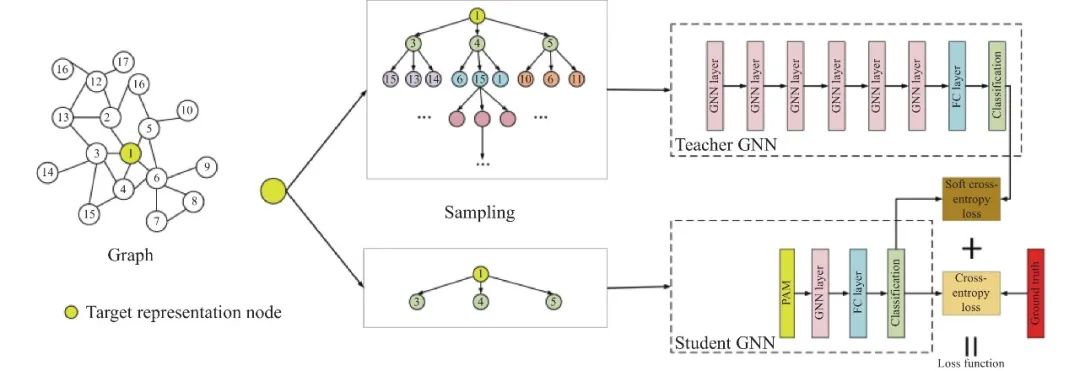
图 11 TinyGNN[91]的输出层知识蒸馏
随后, 研究人员提出大量基于输出层知识蒸馏的相关工作. 譬如, Zhang等人[86]认为教师模型预测不可靠将导致额外的计算开销和高偏差, 设计了可靠数据蒸馏(RDD)方法, 通过定义图中节点的可靠性和边的可靠性以更好地利用高质量的数据, 从而优化传统KD并增强模型表征能力. Antaris等人[89]设计了一个基于Kullback-Leibler散度的蒸馏损失函数, 将获取的知识从基于离线数据训练的教师模型转移到基于在线数据训练的小型学生模型中, 同时还采用了一种自注意机制来捕捉学习到的节点嵌入中的图演化. Deng等人[85]考虑到因数据隐私等问题导致的数据不可用问题, 设计一种从无图数据的 GNN 中进行知识蒸馏的GFKD框架. 具体地, GFKD 首先学习教师GNN模型中知识更容易集中的fake graphs, 然后利用这些fake graphs将知识迁移给GNN学生模型. 为了实现这一目标, GFKD提出了一种结构学习策略, 对多元伯努利分布的图拓扑进行建模, 然后引入梯度估计对其进行优化. Ghorbani等人[87]使用标签传播算法将所有与图相关的知识注入到教师模型产生的伪标签中, 然后使用该伪标签训练学生网络. Zhan等人[90]提出了一种简单而有效的基于图半监督学习的蒸馏方法MT-GCN, 将高置信度预测作为伪标签来扩展标签集, 以便选择更多的样本来更新GCN模型. Zhang等人[93]通过知识蒸馏来研究一致性正则化在半监督图神经网络训练中的作用, 提出可以通过计算学生和教师模型之间的一致性损失来指导模型的训练. Zhang等人[94]为了解决GNN边缘稀疏性和标签稀疏性问题, 首次提出在线蒸馏方法ROD, 通过整合多尺度感知图知识来动态训练强大的教师/学生模型. Ma等人[92]提出了一种新颖的深度异常检测方法GLocalKD, 该方法通过对图和节点的联合随机蒸馏来学习图数据丰富的全局和局部的图正则化模式信息. Li等人[95]基于知识蒸馏思想, 提出一种用于图表示的可解释浅层图神经网络模型EGNN. 具体地, EGNN结合知识蒸馏, 同时通过设计透明、可解释的邻居选择策略, 来解释图神经网络模型的聚合操作.
不同于上面的师生模型框架一致的知识蒸馏方案, Zhang等人[88]提出一种新的蒸馏框架GLNN, 通过将教师GNN中的logits知识提取到学生MLP模型中, 大大减少了节点分类的推理时间. 图12展示了GLNN的模型框架图.

图 12 GLNN[88]的输出层知识蒸馏
具体来说, GLNN是一个从GNN到MLP的KD蒸馏范式, 由此得到的GLNN是通过KD优化的MLP, 其在训练中具备图上下文感知能力, 且在推理过程中没有图的依赖性, 推理速度与MLP一样快. 因此, GLNN模型既有MLP的低延迟和无图依赖性的优点, 又可以达到和GNN相同的表现, 从而解决GNN延迟性高的问题.
虽然基于输出层知识在GNN上展现出了巨大的优势, 但是这类方法只是套用在了文献[12]提出的KD框架上, 仅利用了输出层类别概率分布这一种监督信息, 未能充分挖掘教师GNN中的知识.
4.2 基于中间层知识
鉴于GNN中输出层知识对教师模型信息提取的有限性, 中间层知识的引入可以进一步丰富知识的表示形式且能够有效提高学生模型下游任务的性能. 本节对面向图神经网络中的中间层知识蒸馏方法进行汇总, 这类方法根据下游任务, 主要分为两大类.
一类是用于常见的图挖掘任务中的节点分类等任务中. 例如, Jing等人[99]提出多对一的师生蒸馏框架AGNN(见图13), 即用多个教师网络来共同训练一个学生网络, 使学生能够从具有不同特征维度的教师那里学习. Kim等人[97]整合教师网络中间图卷积层的聚合信息和输出层的软标签知识, 提取到学生网络中. Wang等人[102]为GNN设计出首个在线对抗蒸馏方法OAD, 核心思想是在知识蒸馏训练过程中引入生成对抗学习和循环学习技术, 以有效捕捉图神经网络的结构变化. Wang等人[103]首次尝试用协同知识精馏方法对异构信息网络中元路径嵌入之间的相关性进行建模, 可以有效地在最终嵌入过程中保持全局相似度和蒸馏局部知识. Huang等人[106]为了提高GNN在类别不平衡图数据中的分类性能, 提出了一种基于硬样本的知识蒸馏方法HSKDM, 通过联合训练多个GNN模型, 将模型的中间层和输出层知识一起提取到学生网络中, 最后显著提高了节点分类性能.

图 13 AGNN[99]的中间层知识蒸馏
另一类是将中间层知识图蒸馏方法用于其他图分析任务, 如推荐系统[96, 100, 101]等任务中. 如图14所示, Zheng等人[100]采用知识蒸馏技术, 通过利用图结构将教师节点嵌入到低维流形上, 并要求学生学习从节点特征到该流形的映射, 而将GNN推广到推荐系统中的冷启动研究问题中. 同年, Wang等人[96]将对比学习和蒸馏学习相结合, 提出逐层对比蒸馏框架LWC-KD用于增量学习的推荐场景中. Wang等人[101]利用图学习和知识蒸馏在特权信息建模中的优势, 提出了一种新的特权图蒸馏模型(PGD), 以提高GNN模型在冷启动问题上的性能表现. 此外, GNN的中间层知识蒸馏还应用于其他任务. 如Antaris等人[98]首次研究并提出动态图表示学习的知识蒸馏方法EGAD, 在连续动态图卷积网络之间引入带权重的自注意机制来捕捉实时视频流事件图的演化, 并准确地学习潜在节点表示. Bahri等人[104]介绍了一种基于XNOR-Net++和知识蒸馏的二值化图神经网络BGNN, 通过研究各种策略和设计决策来探究对二值化图神经网络图像分类性能的影响. Qin等人[105]针对图相似度学习缓慢的问题, 设计了一种新颖的基于共同注意的多级GNN特征融合模型, 并采用知识蒸馏的方法从该模型中提取知识蒸馏到学生模型.
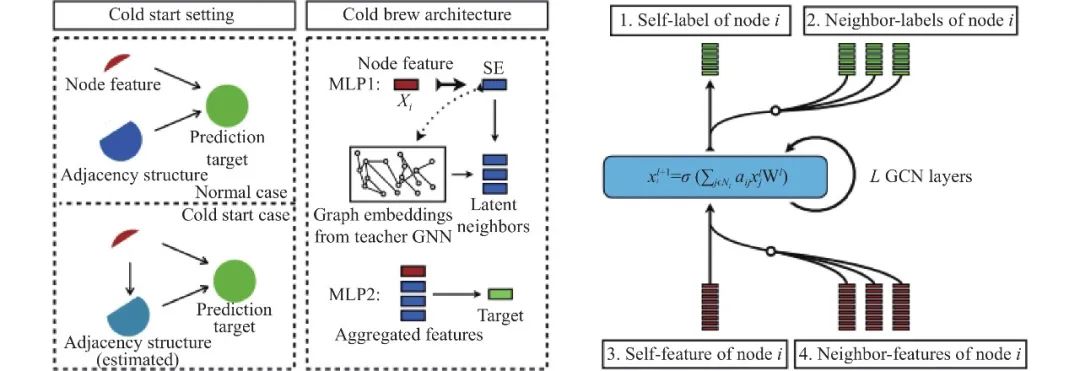
图 14 Cold Brew[100]的中间层知识蒸馏
GNN上的中间层图蒸馏方法的在各种图分析任务中的成功应用, 表明了中间层知识对图蒸馏技术的重要性.
4.3 基于构造图知识
为了进一步丰富并提供更通用的知识, 在GNN中也会进一步借助构造图[16, 107-114]来学习教师模型图拓扑结构和节点关系信息, 以深入挖掘教师模型中蕴含的知识. 在这类方法中, LSP[16]是首个专门为同构图神经网络设计的知识蒸馏框架, 图15展示了LSP的蒸馏过程.

图 15 LSP[16]的构造图知识蒸馏
如图15所示, Yang等人[16]在GNN中设计了一个局部结构保持模块LSP来捕获图拓扑信息, 将来自教师和学生的局部结构信息建模为分布信息, 通过最小化分布之间的距离实现从教师到学生模型的知识迁移. 受到LSP方法的启发, CPF蒸馏方法[110]被提出, 该方法将学生模型设计为参数化标签传播和特征转换模块的可训练组合, 使得学生可以从教师模型中基于结构和特征的先验知识中获益, 从而比教师模型具有更好的预测表现. Joshi等人[113]在LSP的基础上, 设计新型图对比学习表示蒸馏框架G-CRD, 该框架基于对比学习的思想对齐教师与学生的节点嵌入表示来隐式保留全局拓扑结构. Song等人[111]提出一种单细胞图卷积网络模型scGCN, 并结合知识蒸馏技术, 实现跨越不同数据集之间的有效知识转移. 具体地, scGCN通过预处理, 将稀疏的原始数据集转变为包含跨数据相关信息的映射图, 这使得在参考数据集和未知数据集之间共享信息, 识别标签间相互关系, 并迁移到未知数据集上成为可能. Qian等人[112]提出了一个元学习蒸馏框架MetaHG, 旨在通过联合建模社交媒体上结构化关系和非结构化内容信息为异构图, 并引入元学习将图结构知识从训练任务中转移并有效泛化到下游测试非法毒品交易任务中, 以解决标签稀疏问题. Ma等人[107]提出了一种新的多任务知识蒸馏方法(GRL)用于图级表示学习, 该方法通过多任务学习, 将基于网络理论的图度量作为辅助任务来学习更好的图表示. Yao等人[108]提出了图少样本学习模型GFL, 为了更好地捕捉全局信息, 借助于构造的辅助图结构学习一个可迁移的度量空间, 同时蒸馏局部节点级和全局图级关系结构知识到模型中. Wang等人[109]提出了一种基于异构图的知识转移方法(HGKT), 借助于构建的结构化异构图, 同时捕获类间和类内关系, 通过转移不可见类的邻接类的知识, 来计算不可见类的节点表示.
此外, 除了针对同构图的知识蒸馏模型, Liu等人[114]还提出了HIRE, 专门为HGNN设计的高阶关系知识蒸馏框架, 该方法成为一种实用且通用的训练方法, 适用于任意的异构图神经网络, 不仅提升了异构学生模型的性能和泛化能力, 而且保证了对异构图神经网络的节点级和关系级知识提取. 图16展示了HIRE基于构造图的师生蒸馏过程.
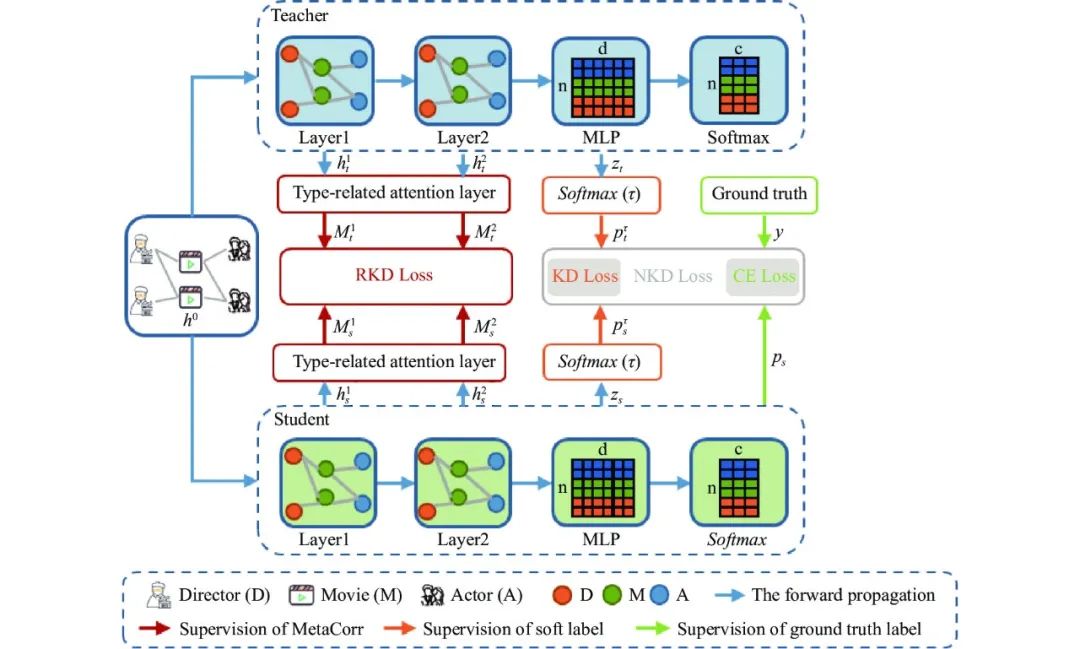
图 16 HIRE[114]的构造图知识蒸馏
如图16所示, HIRE方法主要由两部分组成, 包括节点级知识蒸馏(node-level knowledge distillation, NKD)和关系级知识蒸馏(relation-level knowledge distillatio, RKD). 其中, NKD用以对预训练异构教师模型的单个节点语义进行编码; RKD用来对预训练异构教师模型的不同类型节点之间的语义关系进行建模. 最后, HIRE通过整合节点级知识蒸馏和系级知识蒸馏, 同时考虑单个节点软标签和不同节点类型之间的相关性知识.
综上, 基于构造图的图蒸馏方法在GNN上均取得了令人印象深刻的性能提升, 已成为当前GNN蒸馏学习新范式. 由于面向图神经网络的图蒸馏方法最近几年才被广大学者关注, 因此该领域还有很多问题需要探索和亟需解决, 具体可参见第8节展望部分.
5 基于图知识的模型自蒸馏方法
随着图知识蒸馏的发展, 还有一类模型自蒸馏方法被提出, 这极大地吸引了学者广泛的关注, 成为当前研究的热点之一. 因此, 本节将重点针对图神经网络模型中的自蒸馏方法进行汇总, 将基于图知识的模型自蒸馏方法依据蒸馏位置归类为输出层、中间层和构造图这3类知识, 具体细分见表4. 同样地, 这里仅重点介绍各类图蒸馏算法最显著的知识蒸馏形式, 即若同时具有输出层、中间层知识的蒸馏方法默认划分为中间层知识蒸馏方法, 若同时具有这3类知识的蒸馏方法则默认划分为构造图知识蒸馏方法.
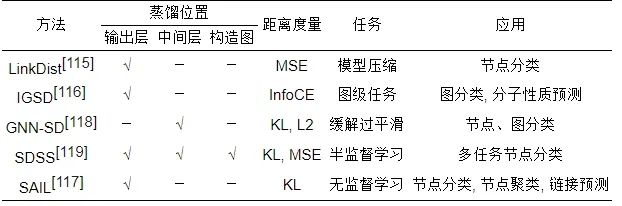
表 4 基于图知识的模型自蒸馏方法汇总
● 相同点: 针对基于图知识的模型自蒸馏方法中基于输出层、中间层和构造图这3类知识蒸馏形式, 每类图知识蒸馏算法的共性在于它们均是基于相同位置处知识的提取.
● 不同点: 针对每类图知识蒸馏算法, 它们的差异性体现在多个方面, 如具体方法实现、距离度量函数、下游任务及应用等方面上, 具体参见表4. 如在图知识蒸馏中用KL散度的, 基于输出层有SAIL[117], 基于中间层有GNN-SD[118], 基于构造图有SDSS[119]. 具体地, 在输出层知识进行蒸馏的方法中: LinkDist[115]采用MSE距离度量方式将图知识蒸馏应用在模型压缩的节点分类应用场景中, IGSD[116]利用MSE度量方式对学生模型压缩并用于节点分类任务上, SAIL[117]则使用KL将图知识蒸馏用于图无监督学习的常见下游节点分类、节点聚类和链接预测上; 基于中间层知识进行蒸馏的GNN-SD[118]方法使用KL和L2距离度量方式用于下游图级任务的图分类和分子性质预测上; 基于构造图知识进行蒸馏的SDSS[119]则利用KL和MSE结合的距离度量方式将图知识蒸馏用于下游半监督学习的多任务节点分类中.
5.1 基于输出层知识
基于输出层知识同样也是自蒸馏最基础且最常用的方法, 本质上就是提取预训练教师模型所蕴含的标签类别相关知识. 在图学习任务中, 尤其图的半监督甚至自监督学习中, 面临着标签数据难以获取这一大难题. 基于此, 研究人员开始尝试将模型自蒸馏方法应用在GNN上. 其中, 最具有代表性的工作就是Zhang等人[116]在2020年提出的一种基于自蒸馏的图级表示学习框架IGSD, 该框架通过对图实例的增广视图进行实例判别来迭代地执行师生蒸馏. IGSD的自蒸馏架构如图17所示.
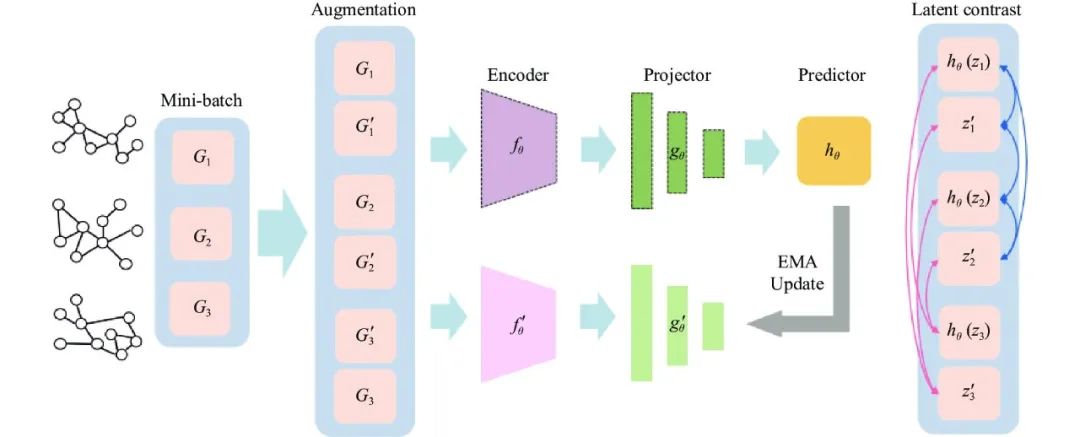
图 17 IGSD的输出层知识蒸馏[116]
与传统的知识蒸馏不同, IGSD用学生模型的指数移动平均值构建教师模型, 并提取自身的知识, 通过图增广视图迭代地执行教师与学生之间的蒸馏. 本质就是在对比学习的框架下, 结合自蒸馏技术使得教师网络和学生网络同时进行训练, 进而增强图的表示能力. 同时, 该工作还将IGSD扩展到半监督学习场景, 通过联合使用监督和自监督的对比损失来优化GNN. 最后, IGSD在半监督图分类和分子性质预测任务中超越了最先进的方法, 并在自监督图分类任务中实现了与最先进的方法相当的性能.
随后, Luo等人[115]提出LinkDist自蒸馏方法, 旨在通过从图网络的边中蒸馏知识, 使得MLP在图分类任务上达到了甚至超过了GCN模型表现力. 此外, 作者还从随机点对中蒸馏“逆边”的知识, 进一步提升了模型的效果. IGSD和LinkDist这两项工作, 很好地验证了输出层知识方法的优越性, 表明基于图知识模型自蒸馏的输出层知识蒸馏方式在GNN上的巨大潜力.
5.2 基于中间层知识
基于输出层知识虽然简单有效, 但仅依靠GNN模型输出类别标签这一类监督信息的话, 模型的表达能力有限. 于是, 研究者开始探索GNN中间图卷积层位置模型蕴含的丰富信息, 希望挖掘到更具节点特征表达能力的知识, 代表性方法有GNN-SD[118]和SAIL[117].
如图18所示, 考虑到两阶段T-S蒸馏方法训练耗时且学生模型的性能受限于教师模型的选取, Chen等人[118]提出GNN-SD方法来替代传统两阶段的GNN蒸馏方法, 将GNN中间层知识从浅层蒸馏到深层以缓解GNN面临的过平滑问题, 同时显著增强GNN的性能.

图 18 GNN-SD的中间层知识蒸馏[118]
具体地, 该方法提出邻域差异率(neighborhood discrepancy rate, NDR)指标, 用于量化图嵌入浅层的非光滑性, 将此作为知识提炼到GNN的深层表示中. 通过这种方法, 模型通过自身的蒸馏策略保持了从初始嵌入图到最终嵌入输出的非光滑性. 同时, 在NDR的基础上, GNN-SD还设计了自适应偏差保留(adaptive discrepancy retaining, ADR)正则化器, 以增强知识的可转移性, 使知识在GNN层之间保持较高的邻域偏差. 通过在多个流行的GNN模型上进行实验, GNN-SD方法的有效性和泛化能力得到了验证, 确实可以有效地缓解GNN过平滑问题, 同时还能够大大降低两阶段知识蒸馏的训练成本.
另一个具有代表性的工作是, Yu等人[117]在2022年提出的GNN上第1个通用的自监督蒸馏框架SAIL, 其模型框架图见图19.
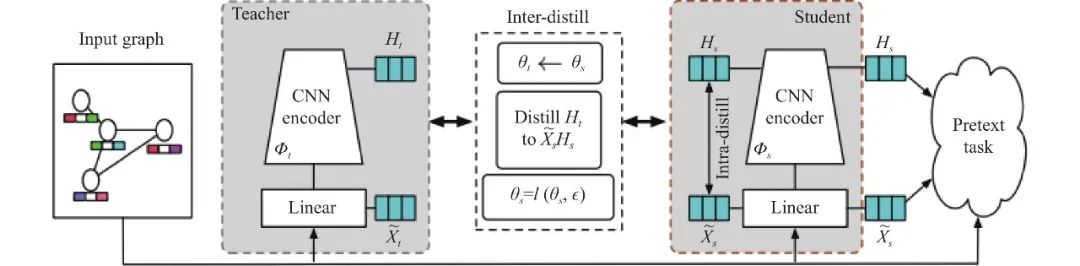
图 19 SAIL的中间层知识蒸馏[117]
在这项工作中, 作者发现GNN的性能取决于节点特征的平滑性和图结构的局部性. 于是, SAIL设计了两个自蒸馏正则化模块来平滑图拓扑和节点特征的近似度差异. 从图19可以得知, SAIL框架主要包含两个互补的自蒸馏模块, 即Intra-distill和Inter-distill蒸馏模块, 通过Intra-distill和Inter-distill 来迭代的利用GNN中间层平滑节点特征来修正GNN浅层表示. 为了评估学习到的节点表示能力, SAIL进行了丰富的实验, 包括节点分类、节点聚类和链接预测任务. 实验结果表明, SAIL有助于学习具有强竞争力的浅层GNN, 优于当前有监督或无监督方式训练得到的GNN.
GNN-SD和SAIL这两项工作的初步研究成果, 揭示了一种很有前途的实现GNN自蒸馏的方法.
5.3 基于构造图知识
除了输出层和中间层知识蒸馏形式外, 研究人员也关注到了基于构造图的知识蒸馏形式. 相比于前面两种知识, 构造图知识可以提取到模型中节点特征之间的关联信息, 可以充分挖掘并利用模型知识, 为基于图知识模型自蒸馏的研究打开了新的视角. 图20展示了在GNN上利用基于构造图知识进行自蒸馏的训练过程.
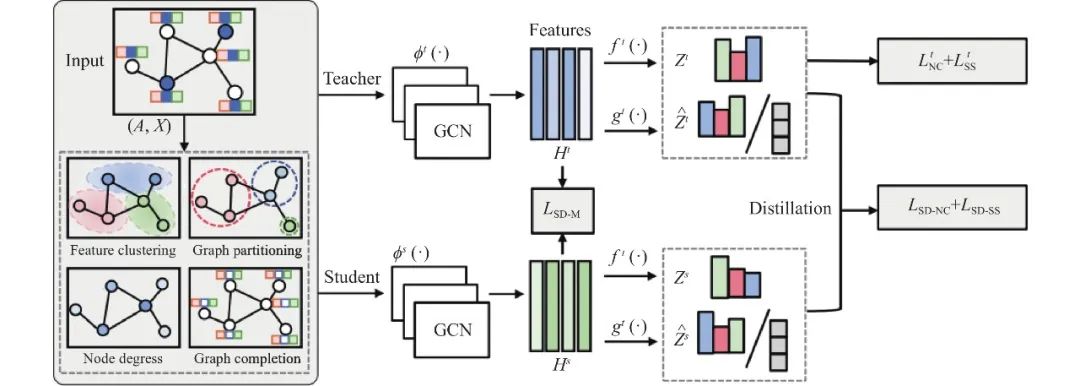
图 20 SDSS的构造图知识蒸馏[119]
Ren等人[119]认为图结构和标签之间的不匹配影响模型的性能, 提出了一个多任务的自蒸馏框架SDSS, 将自监督学习和自蒸馏注入图卷积网络中, 通过挖掘图和标签中的信息, 解决结构端和标签端不匹配问题. 具体地, SDSS方法利用4个基于前置任务的自监督学习来提取不同层次的图相似度信息, 以促进图卷积网络的局部特征聚合. 实验结果表明, 该方法在几种经典的图卷积模型上都取得了令人印象深刻的性能提升. SDSS方法的成功, 表明自监督和自蒸馏在GNN框架中得到了很好的结合, 这为之后的研究人员提供了新的思路和方向.
6 实验分析
本节对面向深度神经网络的图知识蒸馏方法、面向图神经网络的图知识蒸馏方法和基于图知识的模型自蒸馏方法分别展开实验进行对比分析. 首先, 本节介绍常用的数据集; 然后对实验设置进行介绍; 最后对图知识蒸馏方法的实验结果进行分析.
6.1 数据集
为了对比面向深度神经网络的图知识蒸馏方法前后的实验效果, 本文选用深度神经网络中常用的2个数据集, 包括CIFAR-10[120]和CIFAR-100[120]. 数据集具体信息如表5所示.
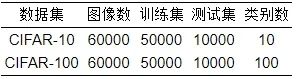
表 5 面向深度神经网络的图知识蒸馏领域常用数据集
为了对比面向图神经网络的图知识蒸馏方法前后的实验效果, 本文选用图神经网络中常用的7个数据集, 包括Cora、CiteSeer、PubMed、Amazon-Photo (A-P)、Amazon-Computers (A-C)、Coauthor-Physics (Physics)、Coauthor-CS (CS). 数据集具体信息如表6所示.
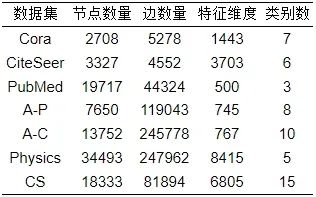
表 6 面向图神经网络的图知识蒸馏领域常用数据集
CIFAR-10: 是一个小型彩色图像数据集, 共有60000张彩色图像, 一共分为10个类, 每类6000张图. 其中, 这里面有50000张图像用于训练, 另外10000图像用于测试.
CIFAR-100: 由100个类的60000个彩色图像组成, 每个类包含600个图像. 其中, 每类各有500个训练图像和100个测试图像.
Cora: 是一个由机器学习论文构成的一个基准引文数据集[121]. 节点表示论文, 边表示引用关系. 每个节点都有一个1433维的特征, 类标签表示每篇论文所属研究领域, 任务是根据引文网络将论文分类为不同的领域.
CiteSeer: 是另一个常用的基准引文数据集[121]. 其中, 每个节点代表一篇论文, 每条边代表两篇论文之间的引用关系, 节点特征维度是3703维, 类标签有6种, 任务是预测某出版物的所属类别.
PubMed: 也是一个引文网络[121], 包含19717个节点, 44324条边. 其中节点表示与糖尿病相关的文章, 边表示引用文章间的关系. 节点特征为TF/IDF加权词频, 有500维. 类别标签有3类, 任务是预测论文的糖尿病类型.
A-P和A-C: 是亚马逊的一个商品购买网络[122]. 节点表示商品, 连边表示两种经常被一起购买. 节点特征用商品评论的词袋表示, 任务是预测商品的类别.
Physics和CS: 是常用的引用网络, 是从2016年KDD杯挑战赛的微软学术合著图提取出来的[122]. 节点表示作者, 边表示作者之间是否是合作关系. 节点特征用每个作者发表论文的关键词表示, 类别标签表示每个作者的研究领域. 给定每个作者论文的关键词, 任务是将作者划分到他们各自的研究领域.
6.2 实验设置
面向深度神经网络的图知识蒸馏: 为了实验的简洁性, 本文选取具有代表性的ResNet-20[123]模型作为深度神经网络模型框架, 测试图知识蒸馏方法在上述2个数据集图像分类任务上的表现. 其中, 在分类指标上, 本文选取的是Accuracy指标. 在知识蒸馏方法的选取上, 本文使用的是经典的KD和IRG、RKD以及CC这3种常用的图知识蒸馏方法. 具体分类效果可见表7.
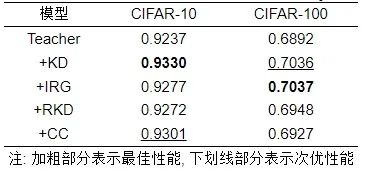
表 7 面向深度神经网络的图知识蒸馏方法Accuracy效果对比
面向图神经网络的图知识蒸馏: 在节点分类任务的对比实验中, 本文选用最具代表性的图神经网络模型(即GCN[17]、GAT[32]、和SAGE[29]), 在上述7个数据集上进行节点分类对比实验. 其中, 在知识蒸馏方法的选取上, 本文使用的是经典的KD和CPF图蒸馏方法. 在分类指标上, 本文选取的是F1-Micro和F1-Macro指标. 具体分类效果可见表8–表10. 同样地, 在聚类任务上, 本文采用NMI和ARI聚类指标, 使用GCN、GAT和SAGE这3个图神经网络模型在Cora等7个数据集上应用KD和CPF知识蒸馏方法, 具体实验结果见第6.3节. 此外, 为了进一步定量分析知识蒸馏效果, 本文还给出了节点可视化实验结果. 具体地, 就是对GCN、GAT和SAGE模型知识蒸馏前后的节点表示进行t-SNE降维, 可视化结果见图21–图23.
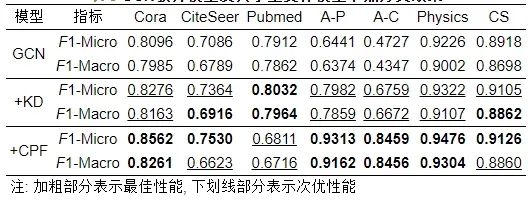
表 8 GCN教师模型及其学生变体模型节点分类效果
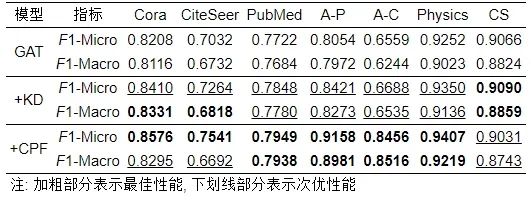
表 9 GAT教师模型及其学生变体模型节点分类效果
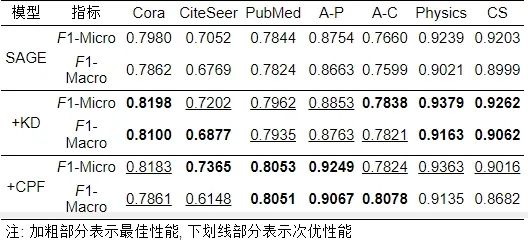
表 10 SAGE教师模型及其学生变体模型节点分类效果
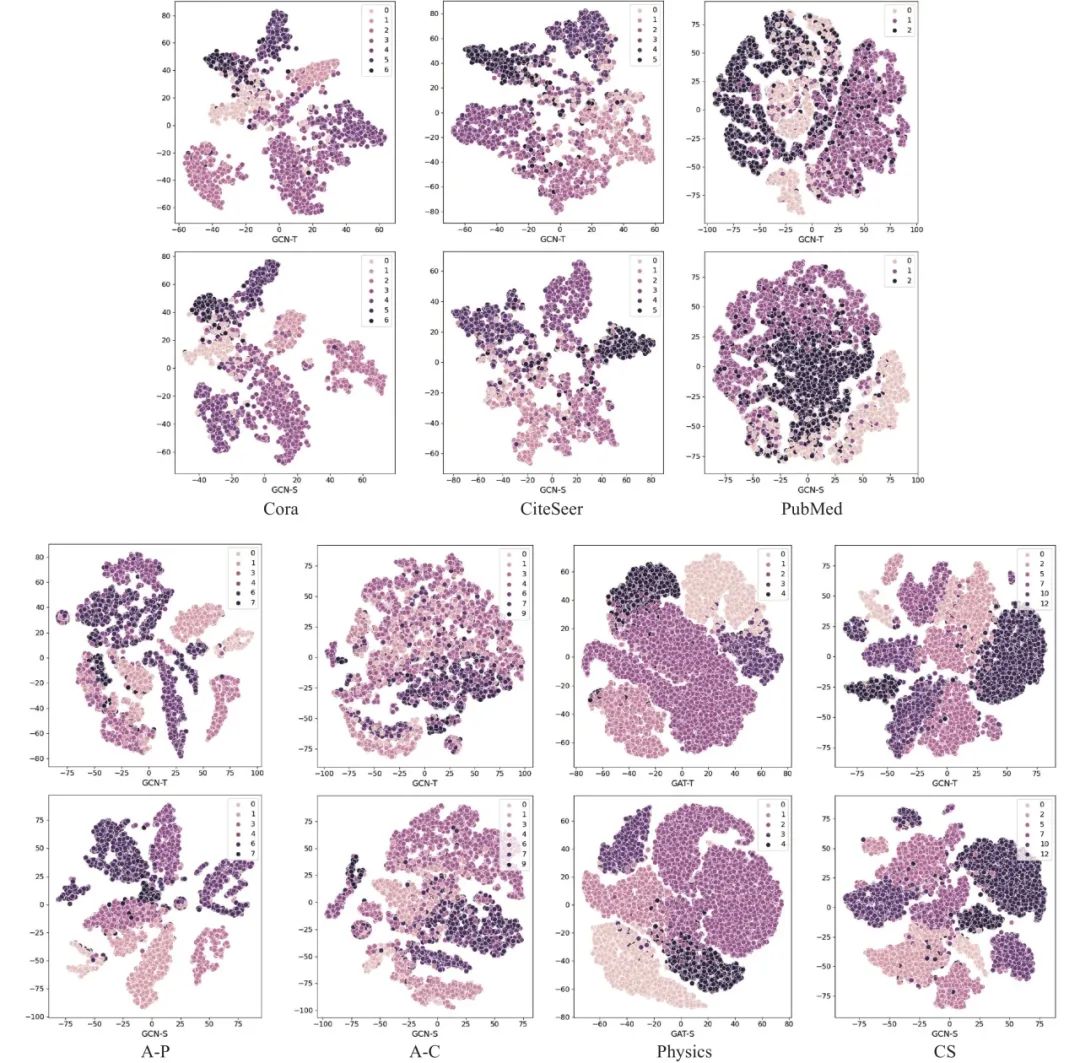
图 21 GCN教师模型及其学生变体节点可视化效果

图 21 GCN教师模型及其学生变体节点可视化效果(续)

图 22 GAT教师模型及其学生变体节点可视化效果
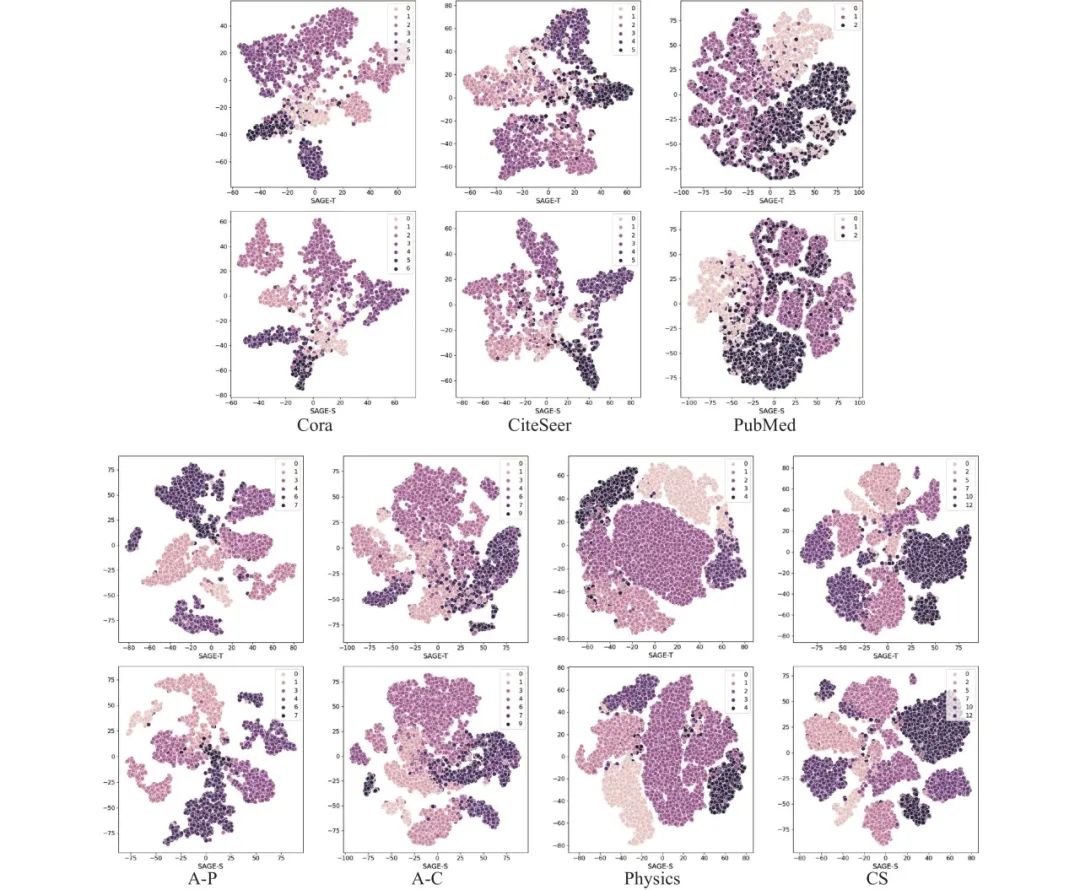
图 23 SAGE教师模型及其学生变体节点可视化效果
基于图知识的模型自蒸馏方法实验: 为了实验的简洁性, 本文选取经典的GCN模型作为图神经网络模型框架, 以节点分类作为任务, 在具有代表性的Cora、CiteSeer和PubMed这3个数据集上测试图知识蒸馏效果. 其中, 在分类指标上, 本文选取的是Accuracy指标. 在知识蒸馏方法的选取上, 本文使用的是经典的KD和LinkDist、SAIL以及SDSS这3种模型自蒸馏方法. 具体分类效果可见表11.

表 11 基于图知识的模型自蒸馏方法Accuracy效果对比
本文所做的全部实验都运行在NVIDIA Tesla的V100 GPU上, 并基于PyTorch-1.6.0版本为0.6的DGL图学习库实现.
6.3 实验结果与分析
● 面向深度神经网络的图知识蒸馏实验结果分析. 从前文表7可以得知, KD和IRG、RKD以及CC这3种图知识蒸馏方法均一致显著提升了ResNet-20教师模型的图像分类效果. 其中, KD在CIFAR-10的蒸馏表现最佳, CC表现次之. 在CIFAR-100数据集上: IRG的蒸馏效果最好, 将教师模型的图像分类性能从0.6982提升到了0.7037; KD的表现次之, 将教师模型的图像分类性能从0.6982提升到了0.7036. 尽管KD和IRG、RKD以及CC这3种图知识蒸馏方法对ResNet-20模型的增益效果不尽相同, 但是他们的性能相差不大, 表现相当. 这一定程度上反映了深度神经网络和知识蒸馏算法的结合工作对ResNet-20模型的提升到达了一定的瓶颈. 可以探索新的图蒸馏学习范式进一步提升面向深度神经网络的图知识蒸馏方法的蒸馏效果, 如与对抗学习、神经架构搜索、图神经网络等新技术结合, 这部分的讨论具体可见第8节 (5) 图蒸馏学习新范式.
● 面向图神经网络的图知识蒸馏节点分类实验结果分析. 由前文表8–表10节点分类结果可以看出, 无论在经典KD还是CPF图蒸馏的指导下, GCN、GAT和SAGE学生变体在Cora等7个数据集上的分类性能均获得了一致显著的提升. 尤其是通过表8和表9, 可以明显发现在GCN和GAT模型框架下, CPF的蒸馏效果远好于经典KD蒸馏效果. 但是SAGE的学生变体模型表现相反, 尽管在SAGE模型框架下, 大多数情况下KD蒸馏效果好于CPF, 但它们相差不多(+KD≈+CPF), 表现相当. 此外, 尽管CPF是多个位置知识蒸馏的集成方法, 但是该图蒸馏方法在一些数据集上的表现不如KD, 如GCN模型在PubMed数据集上的蒸馏表现, GAT模型在CS数据集上的蒸馏表现以及SAGE模型在Cora、Physics和CS数据集上的蒸馏表现均低于KD蒸馏效果. 综上, 虽然KD和CPF图知识蒸馏方法均一致显著提升了GNN模型的节点分类性能, 但它们无法在Cora、CiteSeer、PubMed、A-P、A-C、Physics和CS这7个数据集上的性能同时保持最佳. 同样地, 同一种图知识蒸馏算法在不同的GNN模型上的蒸馏效果不尽相同. 例如CPF图蒸馏算法可以将GCN性能从80.6%提升到85.62%, 将GAT模型从82.08%提升到85.76%, 将SAGE模型从79.80%提升到81.83% (这里以节点分类F1-Micro指标为例). 这反映了, 在设计图知识蒸馏算法时, 不仅要考虑不同蒸馏位置知识的组合性, 而且要考虑GNN模型的适用性, 还需要考虑数据集的普适性. 也就是说, 需要设计一种可以适用于任意图神经网络模型的强大图知识蒸馏算法, 同时可以在任意的数据集上获得SOTA (state-of-the-art) 蒸馏效果.
● 面向图神经网络的图知识蒸馏节点聚类实验结果分析. 除了执行节点分类任务外, 本文还针对GCN等3个模型在Cora等7个数据集上进行了节点聚类实验. 具体的聚类效果见表12–表14.
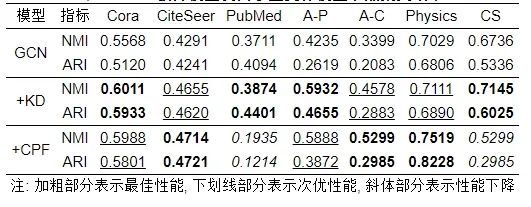
表 12 GCN教师模型及其学生变体模型节点聚类效果
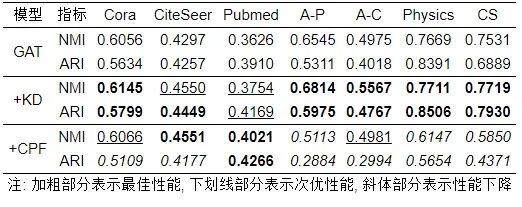
表 13 GAT教师模型及其学生变体模型节点聚类效果
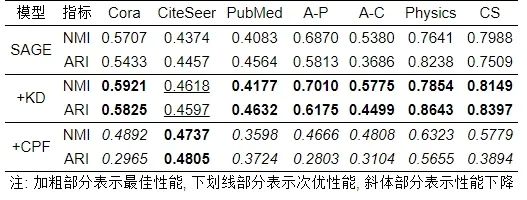
表 14 SAGE教师模型及其学生变体模型节点聚类效果
从表12–表14可以得知, KD和CPF带给GNN教师模型的增益效果相差较大. 整体上, 经过KD知识蒸馏, GCN、GAT和SAGE的学生模型聚类性能均得到了一定的性能提升, 但是它们的蒸馏效果表现不尽相同. 其中, 从表12得知: 在Cora、PubMed、A-P和 CS 数据集上KD效果远大于CPF, 然而在CiteSeer、A-C和Physics上CPF效果好于KD. 从表13和表14可以观察出: 在GAT和SAGE模型骨架下, KD效果整体好于CPF甚至于可以使得对应学生模型在各个数据集下的性能保持最佳.
另外, 本文发现图知识蒸馏实验中的一个有趣的实验现象, CPF图知识蒸馏算法会损害GNN模型性能. 特别地, 在GAT和SAGE模型框架下, CPF在Cora等7个数据集上反而会降低其对应教师模型的节点聚类性能. 例如, 经过CPF蒸馏, 基于SAGE模型框架下的CS数据集的教师性能从79.88%降低到57.79% (这里以节点聚类NMI指标为例), 这和CPF图知识蒸馏算法在节点分类上表现大相径庭. 这一定程度上说明GNN和图蒸馏算法的结合工作仍有很大挑战, 如何更好地将图知识蒸馏应用在GNN上仍旧需要进一步的探索. 关于这部分, 本文在第8节进行了深度讨论和展望.
● 面向图神经网络的图知识蒸馏节点可视化实验结果分析. 除了进行节点分类和聚类定量分析图知识蒸馏效果外, 本文还进行了节点可视化定性分析. GCN、GAT和SAGE变体模型的节点表征经过 t-sne 算法降维后的可视化结果如图见图21–图23. 其中, 第1行是对应教师模型节点可视化效果, 第2行是对应学生模型在图蒸馏下的可视化结果. 通过这3个图, 可以清晰发现经过知识蒸馏, GCN、GAT和SAGE的学生聚类效果均得到了改善, 不同种类节点间的边界间隔变大, 相同种类的节点聚拢更加紧密. 尽管图知识蒸馏算法可以提升GNN模型的节点表示能力, 使得不同类别标签的分类界面变得更加清晰, 但是它们在不同的数据集上的效果不尽相同. 这说明当前图知识蒸馏在GNN上的研究仍有巨大的潜力, 还有很多问题值得进一步研究和探索, 关于这部分我们在后面第8节部分进行了深度的讨论和展望.
● 基于图知识的模型自蒸馏实验结果分析. 由前文表11节点分类结果可以看出, 无论在经典KD还是LinkDist、SAIL和SDSS这3种模型自蒸馏方法图蒸馏的指导下, GCN学生变体在Cora等3个数据集上的分类性能或多或少得到了一定的性能提升. 特别地, SAIL和SDSS的蒸馏效果远好于经典KD蒸馏效果, 且大幅度提升了GCN教师模型的性能. 但是LinkDist的表现不尽相同, 其蒸馏表现在Cora和PubMed数据集上低于KD的蒸馏效果. 同时, 本文还发现KD和LinkDist在Cora和PubMed数据集上反而会降低其对应教师模型的节点分类性能. 综上, 虽然KD和模型自蒸馏方法可以提升图神经网络模型的节点分类性能, 但它们无法在Cora、CiteSeer和PubMed这3个数据集上的性能同时保持最佳. 这同样反映了, 在设计图知识蒸馏算法时, 还需要考虑蒸馏方式选择的适当与否, 同时蒸馏位置和距离度量的函数选择也影响着蒸馏效果, 有关这部分的讨论具体可见第8节. 此外, 基于图知识的模型自蒸馏方法目前处于初步探索阶段, 研究方法鲜少且缺乏理论支撑, 需要充分探索图知识蒸馏方法背后的蒸馏数学原理机制, 从而设计出高效图知识蒸馏方法, 有关这部分的讨论具体可见第8节 (4) 可解释性理论分析.
综上, 这3类方法图知识蒸馏方法凭借其模型压缩、模型增强、简单高效等优势可以提升CNN/GNN模型性能, 成功应用在推荐系统等实际应用场景中. 尽管这些方法取得了不错的成效, 但它们仍然存在一定的不足. 本文接下来在第8节对图知识蒸馏的可改进方向进行了展望: (1) 蒸馏位置的确定; (2) 蒸馏方式的选择; (3) 距离度量的函数选取; (4) 可解释性理论分析; (5) 图蒸馏学习新范式.
7 应 用
知识蒸馏自提出以来, 受到了学术界和工业界的大量关注. 随着知识蒸馏技术的发展, 图知识蒸馏在模型压缩和模型增强等方面均取得了优异的表现, 而且在计算机视觉、自然语言处理、推荐系统等领域有着非常重要的应用和广阔的前景. 在本节中, 总结了图知识蒸馏常见的几个应用场景, 这对更好地理解和使用图知识蒸馏技术至关重要(比如大多采用T-S蒸馏方式; KD和GNN等技术的结合), 也是未来值得关注的研究工作.
7.1 计算机视觉
图知识蒸馏作为一种有效的模型压缩/模型增强技术, 广泛应用在人工智能的不同领域, 尤其是在计算机视觉(computer vision)领域中. 近年来, 各种各样的图知识蒸馏算法被提出应用于不同的视觉任务中. 其中, 图知识蒸馏主要应用在图像分类 [58, 68, 71-73, 76] 下游任务中, 实现模型增强、可解释性、模型压缩等目标. 图知识蒸馏在图像识别[57, 63, 69]上, 也有着非常重要的应用, 通过构造辅助图作为知识的载体, 挖掘教师模型中样本间的关系知识传递到学生模型中, 进一步提升学生模型的性能. 此外, 在无监督学习场景下, 图知识蒸馏方法也被用于计算机视觉领域中的行人重识别[59, 81]建模问题中. 另外, 如表15所示, 图知识蒸馏还可以用于目标检测[70, 80]、机器人定位[66]、视频分类[78]、事件预测[98]和道路标记[83]等视觉任务中.
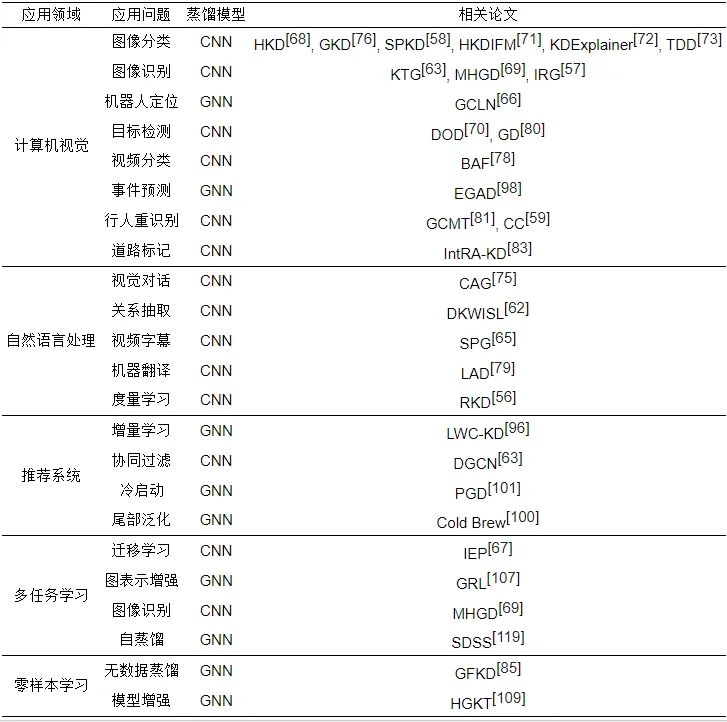
表 15 图知识蒸馏应用领域总结表
7.2 自然语言处理
自然语言处理(natural language processing, NLP) 是计算机科学领域和人工智能领域中的一个重要分支, 是当前热点研究领域之一. NLP模型发展日新月异, 从RNN、Transformer、ELMo、GPT、BERT再到如今的GPT-3, 其模型结构和参数量变得越来越复杂且庞大, 这严重阻碍了语言模型的部署和训练. 知识蒸馏的出现, 提供了一种有效的轻量化深度语言模型知识迁移方法, 可以简单高效地解决语言模型部署问题, 成为NLP领域的研究热点. 如今, 越来越多的图知识蒸馏工作被提出来处理NLP问题, 包括视觉对话[75]、机器翻译[79]、关系抽取[62]等任务, 具体见表15.
7.3 推荐系统
推荐系统(recommended system), 顾名思义, 就是根据用户的属性、历史行为等信息来建模用户的偏好, 进而产生用户喜欢的推荐. 随着深度学习的快速发展, 推荐系统的模型结构变得越来越复杂, 网络深度越来越深, 模型参数也变得越来越多. 同样地, 在推荐系统领域也面临着模型计算昂贵, 无法在移动端或嵌入式设备上运行的难题. 为了解决模型效果和响应速度之间的矛盾, 图知识蒸馏应运而生. 利用图知识蒸馏技术, 预训练的强大教师模型中的丰富知识可以被蒸馏到在线推荐的轻量化学生模型中, 实现增强推荐系统学生模型的泛化能力, 从而达到推荐模型轻松部署上线的目标. 此外, 图知识蒸馏和推荐系统的结合还可以用来解决冷启动[101]、尾部泛化[100]、增量学习[96]等问题. 前文表15列举了图知识蒸馏和推荐系统相结合的代表性工作.
7.4 多任务学习
图知识蒸馏技术除了在上述计算机视觉、自然语言处理和推荐系统上具有广泛应用外, 还和其他新兴技术如图神经网络、迁移学习结合使用, 用于下游多任务学习(multi-task learning)上. 具体地, Lee等人[67]提出一种基于主成分分析的可解释嵌入过程(IEP)知识蒸馏方法, 以解释和理解深度神经网络模型嵌入表示的过程. Ma等人[107]利用构造图来控制教师的知识转移, 通过多任务学习将基于网络理论的图度量作为辅助任务来学习更好的图表示. Lee等人[69]使用多头注意将教师嵌入过程中的知识提取出来, 并通过多任务学习使学生模型具有关系归纳偏置能力. Ren等人[119]则是将自蒸馏和多任务学习相结合, 提出了一个两阶段训练的多任务自蒸馏框架表15整理了目前图知识蒸馏在该任务上的部分工作, 可供研究人员参考.
7.5 零样本学习
同样地, 在零样本学习(zero-shot learning)领域, 图知识蒸馏也表现优异. 例如, Deng等人[85]首次提出针对GNN量身定制的无数据蒸馏方法, 该方法通过使用多元伯努利分布从预训练的GNN建模图结构来进行知识迁移, 并引入梯度估计器来优化这个框架. Wang等人[109]提出了一种基于异构图的知识转移方法HGKT, 借助于构造的结构化异构图来表示数据之间的关系, 将知识从可见类转移到新的不可见类, 解决了可见类和不可见类实例分类的问题. 前文表15给出了这部分工作所使用的主流方法.
8 展 望
作为一种知识迁移技术, 图知识蒸馏凭借其模型压缩、模型增强、简单高效等优势提升深度神经网络和新兴的图神经网络的模型性能, 成功应用在推荐系统等实际业务场景中. 虽然图知识蒸馏取得了令人满意的性能表现, 成为当前热门的研究邻域, 但它仍然有很多需要注意的问题和值得进一步探索的方向. 针对目前图知识蒸馏方法的不足, 本节提出图知识蒸馏研究的几个潜在研究方向.
(1) 蒸馏位置的确定. 通过对图蒸馏工作的归纳分析, 现有大多数图蒸馏方法都是利用不同类型的知识源组合, 包括输出层、中间层、和构造图知识. 然而, 目前还不清楚哪个位置的知识起着重要的影响, 尤其对于中间层和构造图知识, 有的选择中间某一卷积层, 有的选择所有卷积层, 但是具体选择哪一层进行蒸馏, 目前鲜有研究. 如何设计出一种速度更快、更加通用、精度有保证且可以同时建模各种类型知识的图蒸馏模型仍存在挑战, 特别是分析出输出层知识、中间层知识和构造图知识这三者之间的关系如何, 它们是如何相互作用和影响的, 这对于图结构数据信息的合理利用和对知识的充分挖掘至关重要, 这是图知识蒸馏邻域未来研究的重点.
(2) 蒸馏方式的选择. 当前流行的两大图蒸馏方式有T-S蒸馏模式和自蒸馏模式. T-S蒸馏方式因其灵活可控和易于操作, 适用于大规模复杂教师模型的模型压缩任务上. 模型自蒸馏方式因其结构简单和训练高效, 广泛应用在开销较大的下游实际业务场景中. 但是这两种蒸馏方式仍存在不足: T-S操作复杂、训练耗时, 自蒸馏缺少理论支撑且局限于教师和学生模型性能相当的问题场景中. 然而, 目前缺乏对两者蒸馏方式的对比研究. 为此, 研究蒸馏方式的选择如何影响KD的有效性, 以及如何设计出一个高效的蒸馏框架, 是十分必要的.
(3) 距离度量的函数选取. 图蒸馏的表现与训练损失中距离度量函数的选取密不可分. 因为知识蒸馏是从教师模型中提取知识蒸馏到学生模型中, 该知识迁移的效果好坏体现在模型训练中损失函数的设计上, 即只能通过评估学生模型与教师模型中节点/节点间特征的接近程度来展现. 于是, 设计出一个好的图蒸馏损失函数至关重要. 然而, 损失函数选取方法多样, 有KL、MSE、InfoCE等, 对于在图蒸馏过程中具体选择哪一种损失函数以更好指导学生模型训练过程, 尚无定论. 因此, 如何根据具体场景和问题选取合适的距离度量函数成为图蒸馏技术中亟待解决的问题.
(4) 可解释性理论分析. 尽管已有大量的图知识蒸馏工作被成功应用在各种实际业务场景中, 但对知识蒸馏的可解释性理论分析仍然较少. 最近, 对知识蒸馏的可解释性已有一些初步的尝试, 如Yuan等人[48]从标签平滑角度解释了KD的原理, 认为KD的成功并不完全是因为教师类别之间的相似性信息, 而是由于软目标的正则化. 然而, 该发现只适用于分类任务, 并不适用于没有标签的任务[124]. Cheng等人[125]从量化知识的角度来解释知识蒸馏, 即通过定义并量化神经网络中层特征的“知识量”, 从神经网络表达能力的角度来解释知识蒸馏算法的成功机理. Mobahi 等人[126]通过在希尔伯特空间对训练数据的拟合, 首次证明了自蒸馏起着L2正则化器作用, 从而为自蒸馏方法提供了一定的理论分析. 然而, 对于中间层、构造图等知识的解释十分有限, 背后的蒸馏机制尚不清楚. 因此, 蒸馏效果背后的数学原理在很大程度上未被充分探索, 图知识蒸馏方法的理论研究仍然值得进一步探究和关注, 这对探索新的高效图蒸馏方法具有重要指导意义.
(5) 图蒸馏学习新范式. 由于图知识蒸馏在许多任务中表现出了令人印象深刻的性能改善, 大量的研究人员开始尝试将其与现有的深度学习新技术相结合, 包括对抗学习(adversarial learning)、神经架构搜索(neural architecture search)、图神经网络(graph network networks)、强化学习(reinforcement learning)、增量学习(incremental learning)、联邦学习(federated learning)、量化与剪枝(quantization and prunning)等. 知识蒸馏技术与其他技术结合使用, 衍生出了大量具有实用价值的应用. 例如, 知识蒸馏可以作为一种有效策略防御深度神经网络中的对抗扰动[127,128], 并可以用于解决数据隐私和安全问题 [129,130]. 但是这些方法目前还在探索阶段, 方法还不成熟. 因此, 如何将知识蒸馏与其他技术方案更好地结合, 对于图蒸馏扩展到其他用途和应用是一个很有价值和意义的未来方向.
9 总 结
本文从图数据和知识蒸馏的基本概念出发, 对图知识蒸馏方法进行了全面的梳理分析. 首先, 根据图蒸馏算法的设计特点, 可以将其划分为面向深度神经网络的图知识蒸馏、面向图神经网络的图知识蒸馏和基于图知识的模型自蒸馏这3大类方法. 其次, 根据方法对知识蒸馏位置的处理手段, 可进一步细分为输出层、中间层和构造图知识方法. 接着, 通过实验对比了主流图知识蒸馏方法的算法性能. 此外, 还总结了图知识蒸馏在其他领域的重要应用场景. 最后, 对近年来图知识蒸馏学习的研究方向进行了总结和展望. 希望本文可以给图表示学习和知识蒸馏的研究人员提供一些参考, 促进该领域的持续发展.
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章















 1802
1802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









