






解决的问题:
在十亿级用户规模下,在现代推荐系统采用替代性的建模形式需要克服三大挑战
1️⃣ 推荐系统中的特征缺乏显式结构
尽管在小规模场景中已经探索了序列化的建模形式,但在工业级的 DLRM 模型中,异构特征——包括高基数ID(类别特别多的离散标识类特征也就是ID型特征)、交叉特征、统计值、比率等——起着关键作用
这些异构特征非常难处理
2️⃣ 推荐系统使用的是会持续变化的十亿级词表
与语言领域中约十万级且静态的词表相比,十亿级的动态词表在训练上带来挑战,并且由于需要以目标感知的方式考虑数万个候选项,从而导致推理开销很高。
PS:语言里的词表通常是单词或子词的集合;推荐系统里的词表通常是用户、物品以及各类离散特征的ID集合(而且往往有很多个词表)
语言领域:词表就是模型可识别的“token”集合(单词/子词/符号)。每个 token 有一个索引,模型用一个嵌入矩阵把它映射为向量。
推荐系统:有多个“字段”的词表,例如 user_id、item_id、shop_id、brand_id、ad_id、category_id、tag_id、query_id、city_id,甚至把连续特征离散化后的桶(如 price_bucket_37)也构成词表的一部分。每个字段通常有自己的词表和对应的嵌入表 ENDPS
3️⃣ 计算成本是支撑大规模序列模型的主要瓶颈
GPT-3 使用数千张 GPU 在 1–2 个月内训练了总计 3000 亿个 token。这个规模看起来令人望而却步,但与用户行为的规模相比就不算什么了。最大的互联网平台服务着数十亿日活用户,用户每天会与数十亿条帖子、图片和视频互动。用户序列的长度可高达 10^5。因此,推荐系统每天需要处理的 token 数量,比语言模型在 1–2 个月内处理的还要多出几个数量级。
为了解决这三个问题,提出了一个新的生成式推荐框架,可以应用于召回、排序和混排。同时提出了一个新的模型HSTU,使得训练和推理的速度都变得非常快。
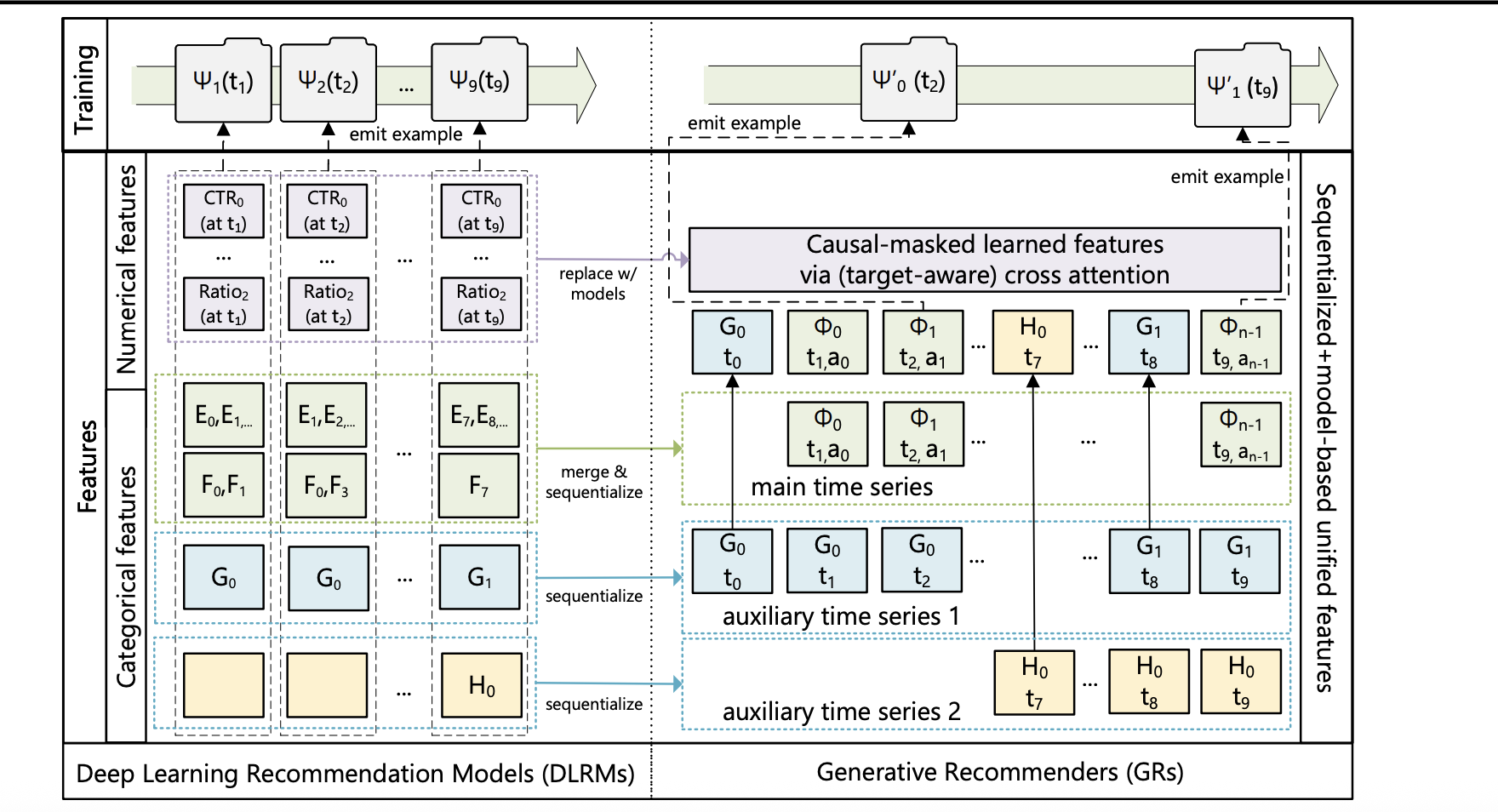
生成式推荐框架:从DLRM到GR
我们对 DLRM 中的异构特征空间进行序列化与统一;当序列长度趋于无穷时,该新方法可逼近完整的 DLRM 特征空间。
PS:
- 序列化:把一次或一段交互中的所有信息,按时间和预定的字段顺序,编码成一串“事件 token”。每个 token 代表一个属性或子编码(如 item 分层码、action、time bucket、device、creator、topic、数值分桶等),用户历史则是这些事件片段按时间排列,适配自回归/转导模型
- 统一:。原来的异构特征各自有独立的嵌入表或处理支路,输入是“多路并行、无序拼接”的。把所有原本分散在不同塔/表/分支里的字段,都映射到同一个离散词表/编码体系中(或一组共享/分层词表),由同一套序列模型处理,不再需要为不同字段定制独立的网络结构。这样排序与召回也可用同一个自回归(或转导)目标统一建模
1️⃣ 在 DLRM 中统一异质特征空间
类别型(“稀疏”)特征
对这些特征进行序列化处理,具体步骤如下:首先,选择最长的时间序列,通常通过合并表示用户互动 Item 的特征来构建主时间序列。其余特征通常为随时间变化缓慢的时间序列,如人口统计信息或用户关注的创作者。通过对每个连续时间段仅保留最早的一个条目来压缩这些时间序列,然后将结果合并到主时间序列中。鉴于这些时间序列变化极为缓慢,这种方法不会显著增加整体序列长度。
数值型(“密集”)特征
相较于类别特征,这些特征变化更为频繁,几乎每发生一次交互都可能发生变化。因此,从计算和存储角度来看,完全序列化这些特征是不可行的。因此,在 GR 中我们可以去除数值特征;只要采用具有足够表达能力的序列转导架构,并结合目标感知的建模方式,随着我们在 GR 中增加整体序列长度与计算量,模型就能有效地捕获这些数值特征。
PS:
- 非目标感知(如经典双塔 Two-Tower):先独立得到用户向量 u 和内容向量 v,最后用点积 u·v 或 MLP(u, v) 打分。用户向量与具体目标无关,属于“晚期交互”。
- 目标感知(如 DIN,Zhou et al., 2018):给定候选 v,用它去“查询”用户历史序列,计算对 v 专属的注意力权重(不同 v 得到不同的 u_v。),再汇聚出 u_v,最后用 MLP([u_v, v, 其他特征]) 打分。
- 在GR中,把候选内容 Φi+1 当作一个“目标 token”插入到序列中,让它对之前的历史 token 做跨注意力(cross-attention)。这样得到的表示天然是“目标条件的”。
2️⃣ 将排序和召回表述为生成式任务
召回 Retrieval
排序 Ranking

高性能自注意力Encoder:HSTU
HSTU 由一系列通过残差连接相互关联的相同层堆叠而成。每一层包含 3 个子层:
Pointwise Projection (Equation 1)
Spatial Aggregation (Equation 2)
Pointwise Transformation (Equation 3)
fi(X) 表示 MLP,f1 和 f2 均采用单一线性层
rabp,t 表示相对注意力偏置,其整合了位置(p)与时序(t)信息
ϕ1 和 ϕ2 代表非线性函数,此处选用 SiLU
Norm 为 LayerNorm
1️⃣ Pointwise aggregated attention
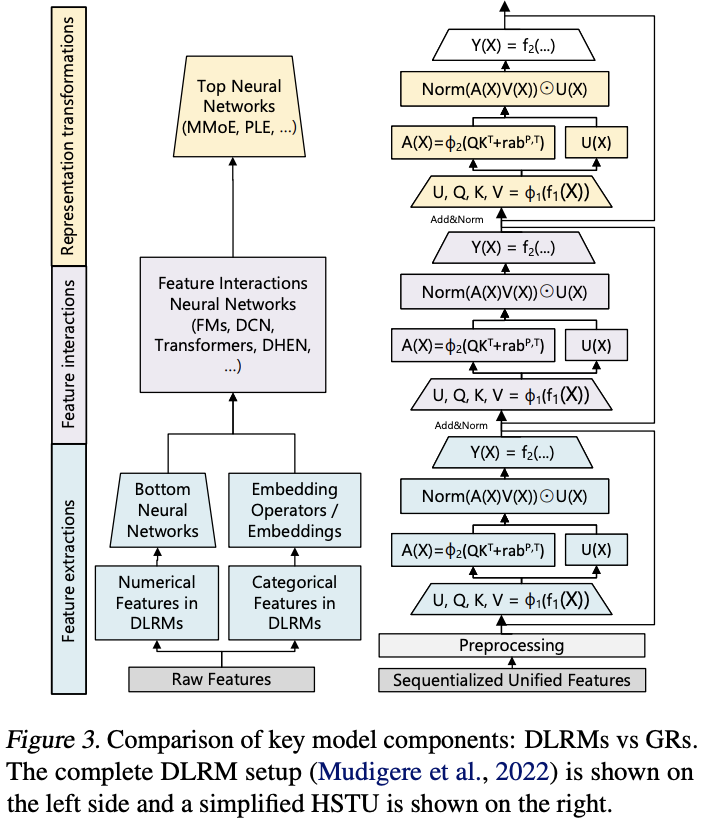
DLRM 实际可理解为 3 个主要阶段:
- 特征提取
- 特征交互:DLRM 中最关键的部分。HSTU 通过Norm (A(X)V(X)) ⊙ U (X) 实现 Attention 池化特征与其他特征的“交互”来取代 DLRM 的特征交互。
- 表征转换:
HSTU 采用新的 Pointwise 聚合(归一化)Attention 机制(Softmax Attention 在整个序列上计算归一化因子)。这一设计基于两个因素:
- 与 Target 相关的先验数据点的数量作为强特征,能够指示用户偏好的强度,而Softmax 归一化后很难捕获这一特征。这一点至关重要,因为需要同时预测用户参与的强度(如,在某一个 Item 上花费的时间)以及 Item 的相对顺序(如,预测最大 AUC 的排序)。
- 尽管 Softmax 激活在结构上对噪声具有鲁棒性,但在流式场景中处理非恒定词表时,其适应性较差。
点式聚合(pointwise aggregated)不在序列维度上做归一化,每个相关元素贡献可以被“累加”进来,因此总贡献随相关项数量/强度增长,更容易保留“先验数据点数量”这类强度特征。
2️⃣ M-FALCON(新的训练与推理算法)
我们要解决的最后一个挑战是在线服务时需要处理的大量候选
对于召回阶段,编码器成本可以被完全摊销,并且无论是利用量化、哈希或分区的最大内积搜索(MIPS),还是在非 MIPS 情况下采用束搜索或分层召回,都已有高效算法。
对于排序,我们通常需要处理上万级的候选,因此提出一种算法 M-FALCON,用于在输入序列长度为 n 的情况下对 m 个候选进行推理
在一次前向计算中,M-FALCON 通过修改注意力掩码和 r_abp,t 偏置,使得对 b_m 个候选执行的注意力操作完全相同,从而并行处理这 b_m 个候选
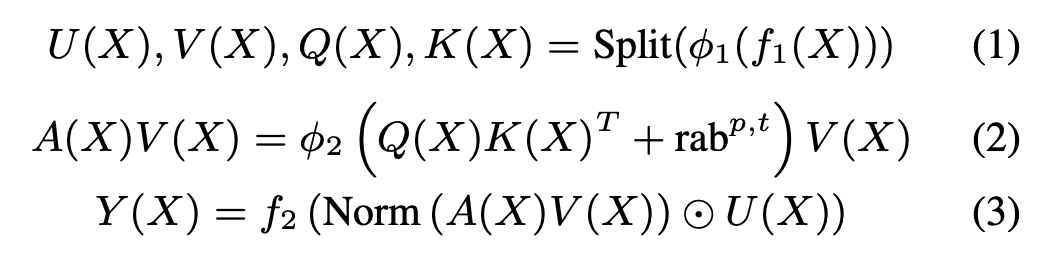


















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









