







本文结合原始论文[1][2]和笔者实际项目经验,对KinectFusion[1]算法做一个介绍。如有错误,欢迎评论指正。
一.简介
KinecFusion算法核心在于维护一个场景的TSDF volume(如图1所示,volume可以想象为一个空间包围盒,由多个voxel(体素)组成,其中包含了我们想要重建的场景),通过把当前视角下拍摄的局部场景的点云和颜色不断融合进该volume内,完成对场景的各视角覆盖和补全,最后从中提取网格及颜色即完成了三维重建。
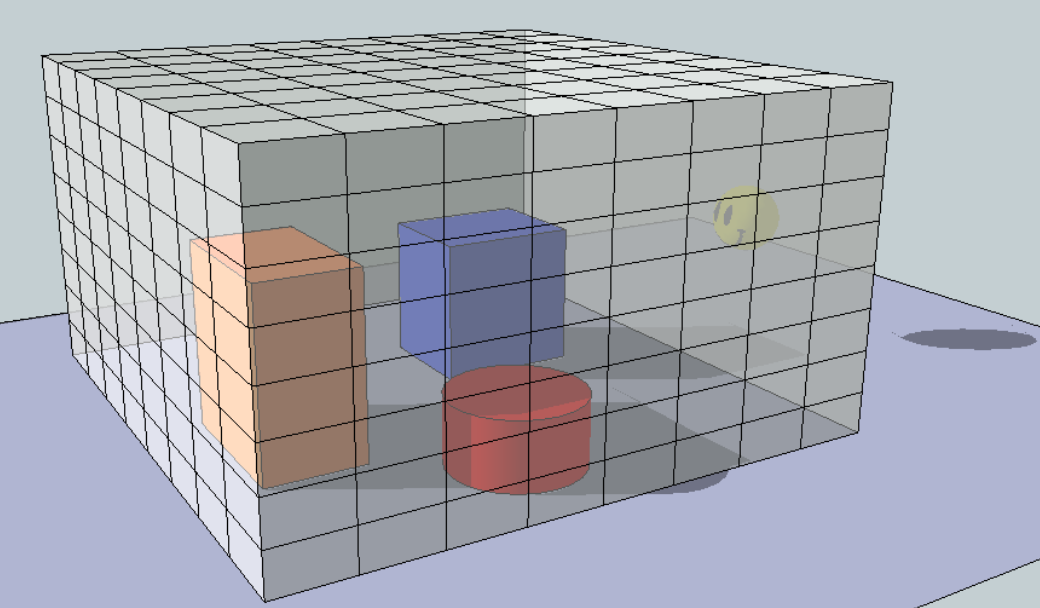
图1.tsdf volume示意
二.具体步骤
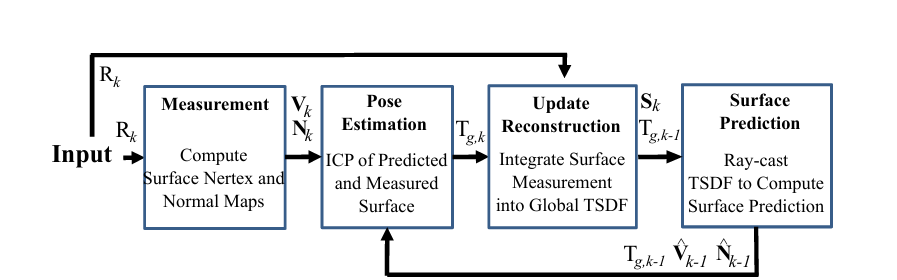
图2.KinectFusion算法流程
1.Measurement
Measurement模块用于对彩色图和深度图进行预处理,并进一步将深度图转化为点云、计算点云法线。
-
去畸变、彩色图和深度图配准
有些相机彩色图和深度图需要自己对齐,或者处于算法速度考虑需要自己手写对齐 -
对输入的深度图像计算图像金字塔
不计算金字塔也可以,直接在原始图像上就行 -
对金字塔的每一层图像进行双边滤波
-
对金字塔的每一层深度图计算顶点图
![]()
式1中,为相机内参,为像素点,为在处的深度,为在处计算的三维点坐标。
-
对金字塔的每一层顶点图计算法向图:领域点算叉乘,当然要保证法线朝外
![]()
式2.点云法线计算
式2中,表示对向量做归一化,即向量除以向量的模,为在处计算的三维点法线。
注:
-
1)笔者实际项目中一般是通过直接由像素点构建三角面片信息,然后用叉乘计算法线,最后对一个像素点的所有三角面片的法线做加权作为该点的法线;当然对于无序的点云,也可以通过对点的邻域点求解PCA得到法线;
-
2)不管采用什么方法计算法线,要注意朝向要一致;
-
3)在对法线施加变换时,只需要旋转变换,不需要平移变换;
-
4)如果是重建人脸人体或者具体物体时,深度图边缘部分的深度一般不准确,可以考虑用mask图过滤掉不用.
2.Pose Estimation
Pose Estimation模块估计相机位姿。
由于采用的是逐帧匹配,两帧之间一般相机差异不会太大,一般不需要做粗配准(KinectFusion里面提到的粗配准指的是会将最上面下采样图层的配准结果作为下一层的初值),而是直接进行ICP精细配准,具体采用的是Point to Plane ICP。
配准的对象为当前深度帧计算而来的点云(source点云)和已重建的场景(target点云,从TSDF场中提取而来)。
*匹配点搜索,
这里不是采用的KNN查找最近邻的方法,而是采用的投影法。其背后的思想是相机帧率足够,从而相邻两帧相机位姿变化不会太大,因此可以将施加了上一帧计算的相机位姿后的target点云用相机内参投影到当前深度帧上(对应于source点云),据此来查找最近点。
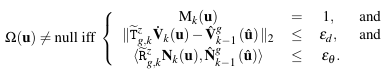
式3.有效匹配点
式3中,表示搜索得到的当前帧像素点的最近点,为source点云利用内参在当前帧上的投影像素点,表示当前深度是否有效(1有效,0无效),为当前帧旋转和平移变换矩阵,为当前帧旋转变换矩阵。第一行表示选取当前帧具有有效深度的点(有些深度可能被过滤掉不采用),第二行表示要求两点的距离小于,第三行表示要求两点的法线夹角要小于。
-
构建优化方程,迭代的求解相机位姿
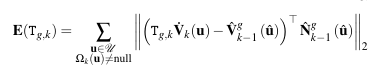
式4.配准的优化目标函数
式4中,注意法线是target点云上的,此时的误差其实就是在Point to Point ICP求两点之间的欧式距离的基础上,又在法线的方向做了投影。
注:
-
1)
point to plane icp与point to point icp不同,无法直接通过原始点云的构建协方差矩阵进行svd分解求解,可以当作一个常规的非线性最小二乘问题,采用高斯牛顿法或LM算法求解。但是,实际工程化中会对求解的旋转变换做一些近似,最终转化成了和point to point icp相同的线性最小二乘问题,通过对A进行分解求解变换矩阵,避免了非线性最小二乘问题中jacobi矩阵的计算,简化了问题。具体可参考[5]; -
2)关于源点云,笔者实际项目中最后未采用后面将提及的
RayCast算法从TSDF提取的点云,而是直接用MarchingCube算法从中提取网格,配准效果实测更好; -
3)这块配准其实有很多改进,除了
frame to frame,frame to model这种都是配准对象在点云或网格上,还有直接作用在TSDF上的如frame to tsdf,tsdf to tsdf,感兴趣的读者可以去搜索了解了解。
3.Update Reconstruction
Update Reconstruction模块利用相机位姿把当前视角所拍摄的场景点云融合到全局TSDF volume里,volume中每个体素存储了场景物体的深度信息.
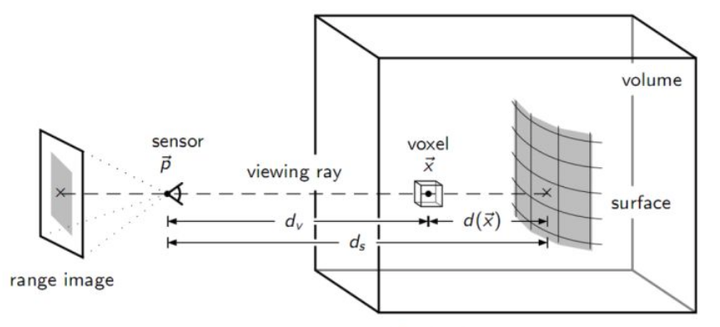
图3. sdf计算
此种表达相比直接合并点云对相机姿态不准确和噪声更为鲁棒,其步骤为
-
遍历每一组数据(彩色图,深度图,当前姿态);
-
遍历体素,利用当前姿态将每个体素中心从世界坐标系变换到相机坐标,并进一步利用相机内参投影到图片上;
-
将投影处深度与相机坐标系下的体素坐标的深度(涉及到距离变深度,即从相机光心->相机平面)相减得到
SDF值,并截断得到TSDF值;
![]()
式5.体素存储的值
式5中,指的是体素存储了两个值,分别是TSDF值和权重。最简单的权重设置为1即可。
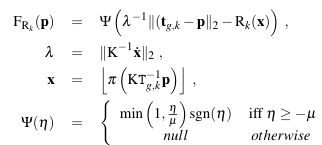
式6中,为截断函数,为体素在深度图上投影的像素点,指的是体素到相机中心的距离,该距离乘以即可转化为当前体素的深度(图3中的),而为体素投影在当前深度图上所取的深度(图3中的)。
-
按相应公式更新该体素的权重和
TSDF值。
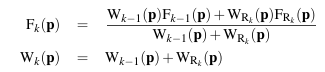
式7中,下标表示当前已融合TSDF值和权重,为当前帧将要融合的TSDF值和权重。
注:
-
颜色也维护一个
TSDF volume,可以用于可视化。作为纹理来看效果比较差,后续还是要通过相机位姿来构建一个UV贴图效果要更好。
4.Surface Prediction
Surface Prediction模块用于从全局TSDF场里提取当前视角下的场景点云及颜色,用于可视化和为下一次Pose Estimation模块提供目标源点云用于配准。
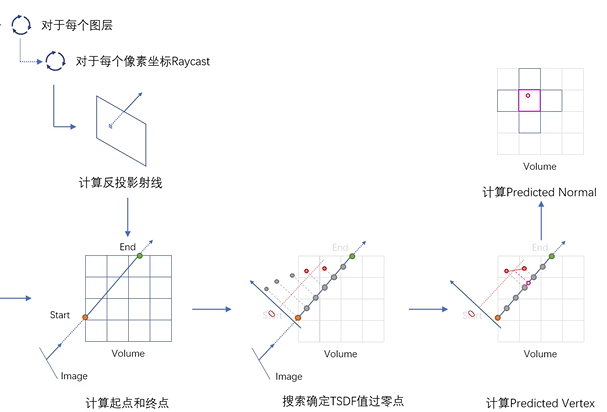
图4. raycast算法
-
对每个像素坐标,计算反投影射线(与NeRF里生成光线类似),即确定光线原点,光线方向;
-
计算起点(都进入)和终点(有一个射出),确定最大最小间隔,;
-
搜索确实
TSDF值过零点;
按一定间隔逐步获取光线上的点,然后获取TSDF值符号变化时的两个位置, 最后采用线性插值得到过零点
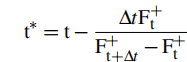
式9.点计算
-
计算
predicted vertex,代入计算计即可; -
计算
predicted normal,这里直接类比图像梯度,取·xyz·方向的TSDF值之差作为近似。
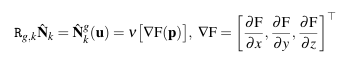
式10.法线计算
5.补充:MarchingCube
MarchingCube模块用于从TSDF volume中提取网格,包含三维点及三维点构建的三角面片。
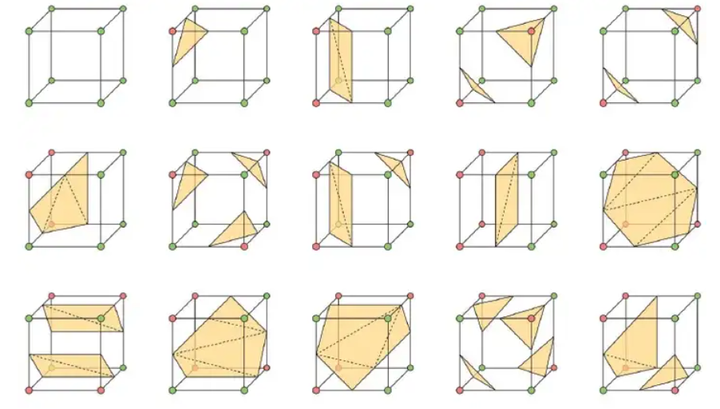
图5.体元配置
相关博客和论文一般把MarchingCube算法一笔带过了,这里为了完整性补充下。
-
遍历体元(注:和图1对不上,相当于将图1中每个体素用其中心点替换,然后也能构成一个volume结构,此时每个顶点代表一个体素,八个体素构成一个体元),根据其 8 个顶点的值确定其体元配置(注:在本项目中即确定了每个顶点的状态是在重建表面外部还是重建表面内部;八个顶点共有256中种状态,但考虑到旋转对称性,最终只有15种基本体元配置,如图5所示,配置决定了物体表面空间点的提取,以及空间点如何连接成三角形面片);
-
根据体元配置,获取在三角形索引表(注:体元配置与三角形面片之间会事先构建此索引表)中的对应的数组;
-
若数组首个元素部位-1,则为边界体元,其内部包含三角面片,我们每三个一组,可获取顶点所在边的索引,假设获得了 N 组;
-
对 N 组边索引,首先找到其两端点,然后插值得到顶点坐标,即为三角面片的三个顶点坐标;
-
返回顶点坐标及三角面片。
三.代码实现
笔者比较推荐的一个开源实现[8],代码非常规范。
四.参考
[1] KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera
[2] KinectFusion: Real-Time Dense Surface Mapping and Tracking
{3]RGBD稠密重建开山之作-KinectFusionLib代码解析(上)_哔哩哔哩_bilibili
[4]【泡泡机器人公开课】第十四课:KinectFusion 和 ElasticFusion 三维重建方法-付兴银_哔哩哔哩_bilibili
[5] Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration
[6]ugweb.cs.ualberta.ca/~vis/courses/CompVis/readings/3DReconstruction/kinectfusion.pdf
[7] Marching cubes算法解析(MC) - 知乎 (zhihu.com)
[8] chrdiller/KinectFusionLib: Implementation of the KinectFusion approach in modern C++14 and CUDA (github.com)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









