







本文结合自身工作和网上诸多炼丹者的经验,按不同模块梳理了有关深度学习调参的大量经验心得。特别地,加黑部分是笔者在实际项目中验证有效的。如有侵权请联系删除,如有错误欢迎评论指出。
一.调参经验
模型调整
-
尽量不要自己手写模型和乱设计玄学组件,找一个没有bug或者已经走通的模型去修改。
-
数据量较少时,最好使用带预训练参数的模型做初始化。
-
虽然pytorch等库在构建层时已内置初始化,但有时可能需要对个别层进行特殊初始化。
-
训练之前先确定好适合自己任务的准确度等衡量模型的标准。
-
使用固定的随机种子,保证运行代码两次都获得相同的结果,消除差异因素。
数据处理
-
数据决定了深度学习任务的上线,模型和trick只是去逼近这个上线。
-
数据量太大的情况下,可以先用1/10,1/100的数据先去估算一下训练或者推理时间。
-
要进行数据归一化,把数据分布分散到均值为0,方差为1的区间。
-
进行合理的数据增强,比如行人识别一般就不会加上下翻转。
-
数据要打乱。
-
在面对不均衡的问题时,需要考虑数据重采样。
-
实际业务中,相对于trick,标数据的综合收益是最大的。性能不好,继续标数据就行了,要不就业务方标要不就自己标。而trick的话,一个是别人验证有效的却不一定适用于你的任务,而且不同trick组合起来不一定能达到1+1>2的效果,整体不确定性比较大。
调参经验
-
先过拟合训练数据,然后提升在验证数据上的准确度。
-
先在一个较小的数据集上train和eval,看看它能不能过拟合。
-
观察loss胜于观察准确率。
-
看train/eval的loss曲线,正常的情况应该是train loss呈log状一直下降最后趋于稳定,eval loss开始时一直下降到某一个epoch之后开始趋于稳定或开始上升,这时候可以用early stopping保存eval loss最低的那个模型。如果loss曲线非常不正常,很有可能是数据处理出了问题,比如label对应错了,回去检查代码。
-
根据train_loss和val_loss的上升下降情况观察参数应该如何调整:
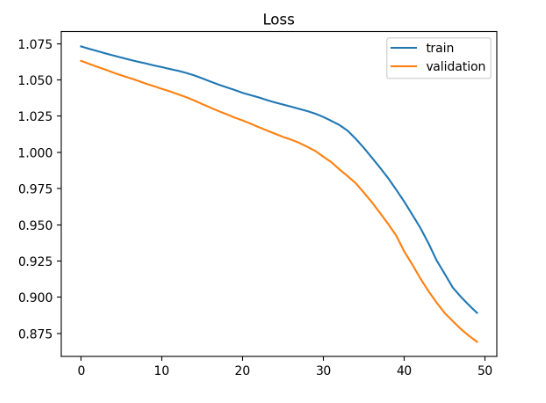
图1.欠拟合损失曲线示意
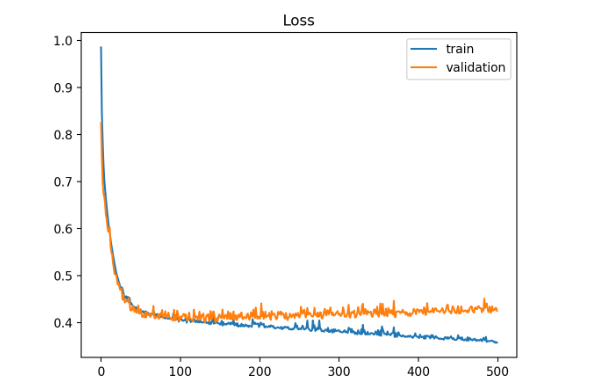
图2.过拟合损失曲线示意
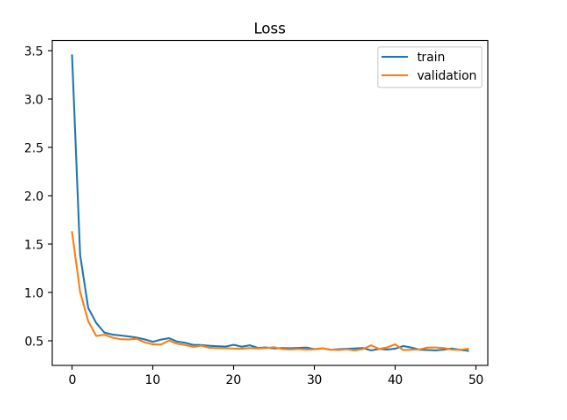
图3.理想损失曲线示意
-
train loss下降,val loss下降 :训练正常,网络仍在学习未收敛,最好的情况。loss曲线如图1所示。
-
train loss下降,val loss上升/不变:有点过拟合,可以停掉训练,用过拟合方法如数据增强、正则、dropout等。loss曲线如图2所示。
-
train loss稳定,val loss下降:数据有问题,检查数据标注有没有错,分布是否一致,数据是否打乱。
-
train loss稳定,val loss稳定:学习过程遇到瓶颈,可以尝试调小学习率或batch数量。
-
train loss上升 ,val loss上升:网络结构设计不当,参数不合理,数据集需清洗等,最差情况 。
-
理想的情况下,train loss和 val loss都是逐步下降,直至稳定。如图3所示。
-
-
超参上,learning rate 最重要,其次是 batch size 和 weight decay。当你的模型还不错的时候,可以试着做数据增广和改损失函数。
-
先调参还是先改模型?如果数据量很少,训练成本很低,可以同时进行。否则可以先调参,模型结构适当简单些,这样可以得到baseline模型的最优参数,后续在baseline模型上搭积木,叠复杂的网络结构,等模型结构调到最优一版了,最后再微调下参数。
-
在利用验证集筛选模型参数时,除设计loss函数外,还可以设置某种规则引导模型向某个想要的方向去更新参数。
-
不要只考虑在每个epoch后面验证,也可以尝试在间隔一定batch后验证。
-
一定要有很强的依据才确定给模型加某个东西。
-
不要同时研究好几个超参,每个阶段只研究一个方面,逐步获得关于当前任务的见解。
-
调参的主体部分,分为 exploration 和 exploitation两个阶段。在exploration阶段,调参的唯一目标就是获得关于任务的见解,比如模型的效果对哪个参数最敏感,对哪些参数并不敏感?又或者模型中哪些参数是相互影响的?在exploitation阶段,结合exploration阶段获得的见解,做最终的大规模调参,目标是最大程度地提升在验证集上的表现。
-
同一个任务不同数据集的数据分布差别很大的时候,把数据集混在一起训练,可能会导致大数据集效果比小数据集还差(a+b训练,结果比单独a或者单独b差),这个时候可以考虑一个用于预训练,另一个用于微调。另外需要注意这种任务如果训练太多epoch很容易过拟合。
-
多模型融合组合是刷结果的终极核武器。以分类任务举例,融合的方法可以为probs融合、投票法。融合模型的来源可以为:
-
同样的参数,不同的初始化方式;
-
不同的参数,通过交叉验证,选取最好的几组;
-
同样的参数,模型训练的不同阶段,即不同迭代次数的模型;
-
不同的模型,如传统算法与深度学习相互融合。
-
-
如果随机种子没有固定,多次预测得到的结果可能不同,也可作为一种模型融合。
-
调参一定要做好笔记,每次只调1个参数。
-
注意实验的可复现性和一致性,注意养成良好的实验记录习惯。
超参数-优化参数
学习率
-
用小一些的学习率warmup,回退到大的学习率,lr scheduler用余弦退火。用这个lr_scheduler加上adam系的optimizer基本就不用怎么调学习率了。
-
优化器只推荐 Momentum 和 Adam。在这些方面做尝试意义不大,如果性能提升反倒可能说明模型不成熟。
-
多年调参经验总结一句话adam快速收敛,sgd接着微调,总是能够获得很不错的精度。
-
微调阶段别用自适应optimizer。
- 人工调整学习率一般是根据我们的经验值进行尝试,首先在整个训练过程中学习率肯定不会设为一个固定的值,原因是设置大了得不到局部最优值,设置小了收敛太慢也容易过拟合。通常我们会尝试性的将初始学习率设为:0.1,0.01,0.001,0.0001等来观察网络初始阶段epoch的loss情况:
-
如果训练初期loss出现梯度爆炸或NaN这样的情况(暂时排除其他原因引起的loss异常),说明初始学习率偏大,可以将初始学习率降低10倍再次尝试;
-
如果训练初期loss下降缓慢,说明初始学习率偏小,可以将初始学习率增加5倍或10倍再次尝试;
-
如果训练一段时间后loss下降缓慢或者出现震荡现象,可能训练进入到一个局部最小值或者鞍点附近。如果在局部最小值附近,需要降低学习率使训练朝更精细的位置移动;如果处于鞍点附件,需要适当增加学习率使步长更大跳出鞍点。
-
如果网络权重采用随机初始化方式从头学习,有时会因为任务复杂,初始学习率需要设置的比较小,否则很容易梯度飞掉带来模型的不稳定(振荡)。这种思想也叫做Warmup,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
-
如果网络基于预训练权重做的微调,由于模型在原数据集上以及收敛,有一个较好的起点,可以将初始学习率设置的小一些进行微调,比如0.0001。
-
-
学习率直接影响模型的收敛状态,batch size则影响模型的泛化性能。
-
可以试试SAM(Sharpness-Aware Minimization)优化,笔者实测对泛化性更好。
bacth size
-
对于一个固定的学习率,存在一个最优的batch size能够最大化测试精度。
-
改变batch size需要重新调整大多数超参数。
-
小batch size带更强的噪音,配合逐步减少的learning rate可以起到传统的随机退火的效果,调的好效果会很不错。大batch size有时会嫌太平稳,最终收敛的数值不一定更好,想要更稳定的梯度减少learning rate就可以了。
-
前期用小batch size引入噪声,有利于跳出sharp minima,后期用大batch size避免震荡,同样目的也可以通过调小learning rate做到,同比例地增大batch size和同比例地减小learning rate能得到极相近的loss-epoch曲线,即衰减学习率可以通过增加batchsize来实现类似的效果,不过前者更新次数会少很多。
-
如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
-
尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。
-
在使用batchnorm的情况下相对更大的batch size是肯定更有益的。
-
大batch size:优点:loss下降更加的平滑;迭代一轮数据速度快 缺点:容易局部最优不收敛。小batch size:优点:梯度更新次数多,收敛快,容易跳出局部最优解; 缺点:训练速度慢,梯度不稳定。
-
工业级推荐场景一般就512配合Adam。然后看训练曲线:极度震荡不收敛,往大调batch,如果不震荡但是平的不下降,往小调。
-
不建议先小batch然后大batch,那还不如调学习率呢,先大点学习率,后面调小,而且现在optimizer也支持,所以batch size别瞎搞
-
大batch size相当于小lr,反之亦然。可以根据收敛速度进行一定选择。
-
如果用了batchnorm,batch size别太小。如果不用batchnorm,可以考虑用小batch size甚至1来得到最优的结果。
-
微调时,batch size设置小一点通常会有一些提升,某些任务batch size设成1有奇效。
-
通常当我们增加batch size为原来的N倍时,要保证经过同样的样本后更新的权重相等,按照线性缩放规则,学习率应该增加为原来的 N 倍。但是如果要保证权重的方差不变,则学习率应该增加为原来的 sqrt{N} 倍。目前这两种策略都被研究过,使用前者的明显居多。
超参数-正则化参数
-
batchnorm和dropout可以试,放的位置很重要。优先尝试放在最后输出层之前,以及embedding层之后。RNN可以试layernorm。不过无绝对,有些任务上加了这些层可能会有负作用。
-
当你的模型有batchnorm,初始化通常不需要操心,激活函数默认 relu 即可。
-
给卷积网络用dropout2d。不过使用需谨慎,因为这种操作似乎跟批量归一化不太合得来。
-
减少过拟合,可增加权重衰减 (Weight Decay) 的惩罚力度。
超参数-网络参数
-
Loss function是Model和数据之外,第三重要的参数。具体使用MSE、Cross entropy、Focal还是其他自定义,需要具体问题具体分析。
-
参数初始化,lstm的h用orthogonal,其它用he或xavier。
-
激活函数用relu一般就够了,也可以试试leaky relu。当你的模型有batchnorm,初始化通常不需要操心,激活函数默认 relu 即可。
-
embedding层的维度可以小一些(64 or 128),之后LSTM或CNN的hiddensize要稍微大一些(256 or 512)。
-
SE在分类上是个涨点必备的工具,在其他任务的使用并不是一帆风顺,比如在检测上有些情况下会掉点。
其它方面
-
蒸馏能提点。
-
在评价测试集损失或准确率时,对整个测试集进行评估。
-
测试时数据也可以增强。
-
新任务和基础任务有相关性时,可以基于基础任务模型上进行微调。使用较小的学习率来训练网络,初始阶段原始层的参数可以先固定,新加层的学习率要适当调大,然后逐渐放开原始高层的参数一起训练,但是要控制学习率这中间放开哪些层,每层的学习率,都需要实验调一下。
-
微调时,如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
-
有一些自动数据增强库RandAug和自动调参库 optuna,也可以试试。
二.参考
[1] http://karpathy.github.io/2019/04/25/recipe/ [2] https://github.com/schrodingercatss/tuning_playbook_zh_cn
[3] 该问题下各位炼丹者的回答:https://www.zhihu.com/question/25097993/answer/3332902044
[4] https://www.cnblogs.com/simmons99/p/13667586.html
[5] https://blog.csdn.net/qq_41917697/article/details/115706565
[6] https://blog.csdn.net/ytusdc/article/details/128502800
[7] https://www.imooc.com/article/305024
[8] https://blog.csdn.net/zhangyingjie09/article/detail
[9] https://www.cnblogs.com/andre-ma/p/8676186.html
最后,创作不易,希望点赞收藏评论+关注,谢谢。

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









