







adaboost = ada+boost,其实是一种自适应的boosting算法,主要思想是利用同一组训练样本训练不同的弱分类器,所有弱分类器的分类结果叠加要可以counter住所有样本点的正确分类,并将这些弱分类器以不同的权值组合起来构成一个强分类器。
和SVM一样,adaboost也善于解决非线性分类问题。
另外,adaboost只是提供的训练框架,可以往里套各种训练算法,是不是特别贴心?
算法浅析
算法由Valiant大神提出,在他的论文中有算法的流程描述,不到20行,堪称经典:

翻译:
1.给定一个训练样本集(x1,y1)....(xm,ym) 其中x属于X样本域,y为标签,值取+1或-1
2.初始化样本集中各样本点的训练权重为均值 :

3.做如下迭代,直到所有样本点都被正确分类过,假设第t次迭代:
1)利用权重分布Dt训练弱分类器
2)统计所有被分类错误的样本点的训练权重之和为Et:

3)计算该弱分类器在强分类器中的权重at:

4)更新训练样本点的训练权重:
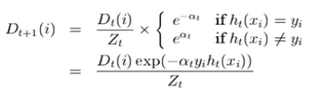
其中Z用于归一化
4.输出强分类器:

强分类器是各弱分类器与其权重at相乘之和。
Adaboost训练示例
举一个网上的二维非线性分类问题实例来看看adaboost的实现过程:
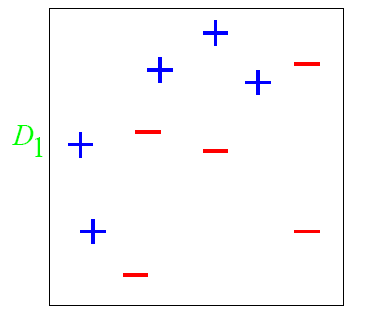
图中的+和-是已经打上了标签的训练样本,各个样本点的初始训练权重都相等,我们用直线作为分类器进行分类:

得到了弱分类器h1,将其运用于训练样本测试,发现有3个样本点分类错误,用圆圈标记出来。
计算得到该次迭代的E1,并以此计算得到分类器h1的权重at,再以此计算更新各个训练样本点的训练权重,权重的大小用样本点大小体现出来如上右图所示,分类错误的样本点得到了更大的训练权重值。
同理有第二次迭代:

再以此得到子分类器h3:
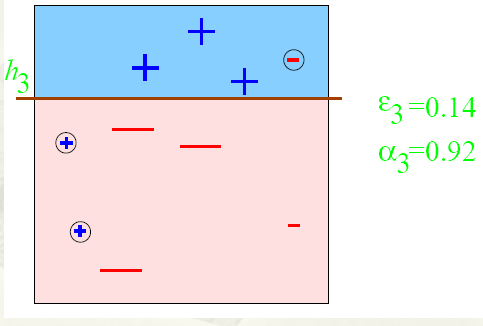
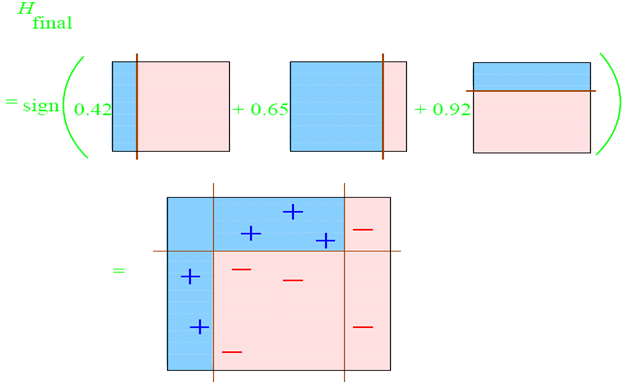
最后将带权重的弱分类器整合:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









