







集成学习系列:
Adaptive Boosting
1 - Motivation of Boosting
1.1 - 回顾
上一篇介绍了 aggregation model a g g r e g a t i o n m o d e l ,就是通过一定的方法将很多的 g g 进行融合变成一个。首先我们介绍了 blending b l e n d i n g ,如果我们已经有了很多的 g g ,可以让它们的投票,或者线性的投票,或者非线性的将它们进行组合; 如果没有现成可用的 g g ,那么可以通过的机制来得到不同的资料,通过这些不同的资料来得到不一样的 g g ,我们称这样的学习算法为。根据各个弱分类器之间是否存在依赖关系,可以将基于 bootstrap bootstrap 机制的算法分为两类:一种是弱学习器之间存在强依赖关系,一系列的个体学习器基本都需要串行生成,其中代表算法有 boosting boosting 系列;一种是弱学习器之间不存在强依赖关系,一系列个体学习器可以并行生成,代表算法是随机森林 random forest random forest 系列。
1.2 - Apple Recognition Problem
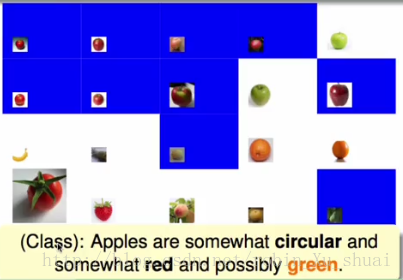
通过以下20个样本,其中前十个是苹果,后十个不是苹果,老师想要教会小孩子们如何识别苹果。

老师:Michael,前十张图片是苹果,下面的十张不是,通过观测,你觉得苹果长什么样子呢?
Michael:我觉得苹果是圆的
如果根据Michael所说的规则, 所有的小孩子们都会觉得圆形的就是苹果,在这种简单的规则下有一些苹果被正确的识别出来,自然也会有一些犯错的判断,如图中蓝色的部分所示。

这时候老师做了一件非常棒的事情, 让小孩子们将更多的注意力放在他们判断错误的样本上,在图中我们将这些犯错的样本放大,将已经判断正确的样本适当的缩小来达到这个目的。这样所有的样本就变成了下图的这个样子。

老师:的确, 苹果大部分都是圆的, 但是只靠这个特征的话我们可能会犯一些错误,那么从这些放错误的样本上, 你觉得苹果还有什么特征呢?
Tina:苹果是红色的
又会有一些样本点被判断错误,同样我们将这些错误的点高亮出来。

同样老师将犯错误的样本点放大, 其他的缩小。新的样本如下图:

老师:根据现在的观察,还有什么规则吗?
Joey:苹果可能是绿色的。
把在这条规则下犯错误的点高亮出来,我们发现,有很多的样本都被划分错了, 但是那些犯错的样本点并不是Joey集中注意力关注的, 都是一些比较小的错误。
将犯错误的样本点放大, 其他的缩小。

Jessica:苹果看起来是有梗的
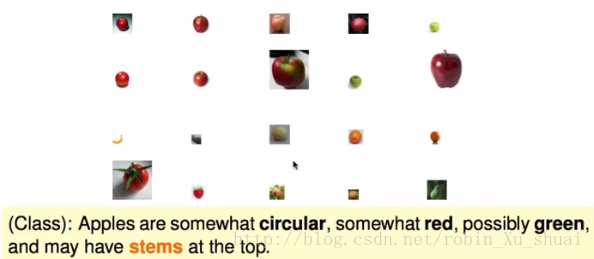
所以在经过了这么多轮的交互之后,小孩子们学到了一个关于判定苹果的比较复杂的规则,例如苹果是圆的,可能是红的,绿的并且是有梗的。这样的想法可能会比原来每一个人的单一的想法能更好的帮助他们来识别苹果。这个过程就是我们接下来要学习的一个算法。这些小孩子代表一些很简单的 hypothesis h y p o t h e s i s ,或者说 gt g t ;整个班级有很多的小孩子,将他们的判断融合起来就得到了一个比较复杂的判定准则 G G ;这其中有一个很关键的角色就是老师, 老师扮演的就是我们将要学习的算法的作用,他的主要功能就是让小孩子专注在犯错的样本上。
2 - Diversity by Re-weighting
根据上一篇的介绍,的核心是 bootstrap b o o t s t r a p ,我们从原来的 D D 经过抽样得到 D~t D ~ t 。
在这个例子中第一个样本被抽样了两次,第二个和第四个样本分别被抽样了一次,第三个样本没有被抽到。接下来 base algorithm b a s e a l g o r i t h m 将会想办法在这样的数据上最小化 E0/1in E i n 0 / 1 。
|[◯]|=1, | [ ◯ ] | = 1 , 如果 ◯ ◯ 成立; |[◯]|=0, | [ ◯ ] | = 0 , 如果 ◯ ◯ 不成立;
我们可以得到这个问题的另一种表述:用一个参数 un u n 来表示每一个样本被选到的次数(每一个样本的权重),那么第一个样本被抽样了两次,所以 u1=2 u 1 = 2 ;第二个和第四个样本分别被抽样了一次, 所以 u2=u4=1 u 2 = u 4 = 1 ;第三个样本没有被抽到,所以 u3=0 u 3 = 0 。那么在进行了 bootstrap b o o t s t r a p 之后我们可以使用 base algorithm b a s e a l g o r i t h m 最小化如下的问题:
其中
utn
u
n
t
的上角标
t
t
表示是在的第
t
t
轮中的权重。
所以
bagging
b
a
g
g
i
n
g
可以看成是使用
bootstrap
b
o
o
t
s
t
r
a
p
的方式产生
un
u
n
,然后使用
base learner
b
a
s
e
l
e
a
r
n
e
r
来最小化使用
u
u
作为权重的(称为
u(t) weighted
u
(
t
)
w
e
i
g
h
t
e
d
-
0/1 error
0
/
1
e
r
r
o
r
),最后来得到(不一样)的
gt
g
t
。所以我们希望
base learner
b
a
s
e
l
e
a
r
n
e
r
可以处理这些带有权重的最小化问题,我们称这样的算法为
weighted base algorithm
w
e
i
g
h
t
e
d
b
a
s
e
a
l
g
o
r
i
t
h
m
,其要解决的问题的形式如下:
我们来分析如果 base learner b a s e l e a r n e r 是 logistic regression l o g i s t i c r e g r e s s i o n 的话,怎么解决有权重 un u n 的情况。当 logistic regression l o g i s t i c r e g r e s s i o n 使用 SGD S G D 方法来进行最优化的时候,每一次要随机的选择一个样本点求解梯度得到权重需要更新的方向。那么当 error e r r o r 和 un u n 有关的时候, un u n 比较大就说明对于 error e r r o r 的影响比较大,所以应该有比较大的几率来沿着这个点的梯度方向进行更新。所以在 SGD S G D 的 logistic regression l o g i s t i c r e g r e s s i o n 中,我们可以将 un u n 作为 SGD S G D 抽样的比例来使得 weighted w e i g h t e d - error e r r o r 最小( weighted w e i g h t e d - error e r r o r 就是指带有权重 u(t) u ( t ) 的 Ein E i n )。
如果 base learner b a s e l e a r n e r 是 SVM S V M 的话,怎么解决有权重 un u n 的情况呢?因为 un u n 的本质是样本被抽样到了几次或者有几份,那么在 SVM S V M 中将 un u n 加入 errsvm e r r s v m 就可以实现这一考虑, Ein∝C∑Nn=1unerrˆsvm E i n ∝ C ∑ n = 1 N u n e r r ^ s v m ,可以看到 Cun C u n 就是 (xn,yn) ( x n , y n ) 犯错需要惩罚的大小。经过对偶问题可以得到 0≤αn≤Cun 0 ≤ α n ≤ C u n 。
如果我们的 base algorithm b a s e a l g o r i t h m 会根据 un u n ( un u n 其实决定了样本是长什么样子的)来选择 gt g t 的话,那么我们怎么设置 un u n 的取值,可以让 gt g t 非常的多样性呢?之所以要求多样性是因为对于 aggregation a g g r e g a t i o n 来说, gt g t 越多样性的话,最后的结果会越好。所以我们要怎么得到不同的 gt g t 呢?
2.1 - Optimal re-weighting
gt g t 是通过从数据 {u(t)n} { u n ( t ) } 上学习得到的, 即:
gt+1
g
t
+
1
是通过从数据
{u(t+1)n}
{
u
n
(
t
+
1
)
}
上学习得到的, 即:
现在我们的目的是要产生一个不同于 gt g t 的 gt+1 g t + 1 。试想一下,如果 gt g t 在使用某个权重 u(t+1)n u n ( t + 1 ) 的时候表现非常的不好,那么把这组权重应用在 t+1 t + 1 轮的时候,不仅仅 gt g t 不会被选择出来,和 gt g t 相似的那些 hypothesis h y p o t h e s i s 也不会被选择到。 gt g t 是固定的, 所以我们要做的就是构造一个权重 u(t+1)n u n ( t + 1 ) (其实也就是构造新的训练集,不过不用再通过 bootstrap b o o t s t r a p 了,只需要变变权重 un u n 就好),构造的准则就是让 gt g t 的表现变得很差。对于二元分类来说,表现很差的意思就是 gt g t 在一半的数据上都划分错误:即划分错误的样本点数与总的样本点数的比值为 1/2 1 / 2 :
为了便于理解和分析做一些简单的记号:
其中: ■t+1 ◼ t + 1 表示的是判断错误的点的权重的和; ◯ ◯ 表示的是判断正确的点的权重的和。现在我们的目的就是想要 ■t+1=◯t+1 ◼ t + 1 = ◯ t + 1 。
例如现在的情况是所有判断错误的点的权重和是1126,所有判断正确的点的权重的和是6211,这是一个合理的假设,因为 gt g t 在当前权重 ut u t ,或者直接理解为在当前数据集上的表现应该是判断正确的数据点比误判的数据点要多,我们想要做的就是更换数据集,也就是更新权重让 gt g t 的表现变差,那么其中一种更新的方式是:
- 对于错误的点: u(t+1)n←u(t)n⋅6211, u n ( t + 1 ) ← u n ( t ) ⋅ 6211 ,
- 对于正确的点: u(t+1)n←utn⋅1126 u n ( t + 1 ) ← u n t ⋅ 1126
或者另一种方式,首先计算分类错误率:判断错误的点的权重的占比
ϵ=11267337
ϵ
=
1126
7337
,那么判断正确的点的权重的占比为
1−ϵ=62117377
1
−
ϵ
=
6211
7377
。
那么构造
t(t+1)n
t
n
(
t
+
1
)
的方法是:每一个正确的点的权重乘以
ϵ
ϵ
,每一个错误的点的权重乘以
1−ϵ
1
−
ϵ
。
通过这样的计算我们就完成了
■t+1=◯t+1
◼
t
+
1
=
◯
t
+
1
,在这样的权重
u(t+1)n
u
n
(
t
+
1
)
下,
gt
g
t
的表现就会很差,那么在
t+1
t
+
1
轮中就会选到和
gt
g
t
很不一样的
gt+1
g
t
+
1
。其实可以理解为是应用了在
bagging
b
a
g
g
i
n
g
学习方法中的
bootstrap
b
o
o
t
s
t
r
a
p
的思想,只不过在这里并没有真正的去进行有放回的的多次采样,而是通过更新权重值来达到这个目的。
3 - Adaptive Boosting Algorithm
3.1 - 缩放因子
我们刚刚描述了如何做最优的权重设置( optimal re o p t i m a l r e - weighting w e i g h t i n g ), 这个方法的目的是让 gt+1 g t + 1 和 gt g t 很不同, 具体的做法是先将 gt g t 的错误率 ϵt ϵ t 通过公式 (1) ( 1 ) 计算出来,然后正确数据点的权重放缩 ϵt ϵ t 倍;错误的数据点的权重放缩 1−ϵt 1 − ϵ t 倍。
(其中 1=|[◯]| 1 = | [ ◯ ] | , 如果 ◯ ◯ 成立; 0=|[◯]| 0 = | [ ◯ ] | , 如果 ◯ ◯ 不成立)
这里我们定义一个新的变量,称为放缩因子 ⧫t ⧫ t :
这样得到 optimal re o p t i m a l r e - weight w e i g h t 的过程可以简单的表示为:正确数据点的权重除以 ⧫t ⧫ t ;错误的数据点的权重乘以 ⧫t ⧫ t 。为什么可以这么做呢?通常 gt g t 的错误率 ϵt≤1/2 ϵ t ≤ 1 / 2 ,所以就有 ⧫t≥1 ⧫ t ≥ 1 。这样的话,错误就被放大了, 正确的就被缩小了, 正如在第一节中老师所做的事情那样, 让学生可以 focus f o c u s 在错误上, 这其实有点像 perceptron learning algorithm(PLA) p e r c e p t r o n l e a r n i n g a l g o r i t h m ( P L A ) 做的事情一样, 将注意力放在划分错误的点, 并将其修正。
现在我们通过构造 u(t) u ( t ) 来得到不同的 gt g t ,这里的 u(t+1)n u n ( t + 1 ) 是第 n n 个样本的权重,的更新规则就是根据 ⧫t ⧫ t ,目的是使得当前的 gt g t 变得很差以至于下一轮可以选出不同于 gt g t 的 gt+1 g t + 1 。现在还剩两个问题没有解决:
- 初始的 u(1)n u n ( 1 ) 应该如何赋值
- 在得到了很多的 gt g t 之后,如何融合为一个 G G
对于第一个问题,通常的做法是每一个都取值为
1N
1
N
,可以理解为就是在原始的数据上来最小化
Ein
E
i
n
,所以得到的第一个
g1
g
1
应该是对
Ein
E
i
n
来说还不错的。
对于第二个问题,或许我们可以使用类似于
bagging
b
a
g
g
i
n
g
的方法,将这些
g
g
通过的形式融合起来, 但是考虑刚刚说过的一个问题,
g1
g
1
对
Ein
E
i
n
来说是很好的, 那么理论上说
g2
g
2
对
Ein
E
i
n
来说就应该是不好的, 因为根据我们前面讨论的机制
g2
g
2
和
g1
g
1
是很不相同的。所以如果做
uniform
u
n
i
f
o
r
m
的话,可能不是一个很好的选择。 在这里我们介绍一个可以在决定了
gt
g
t
之后就能确定以什么样的权重
αt
α
t
将其融合到
G
G
的方法。
基本的思路是,如果的表现很好, 那么 αt α t 就大一点,反之就小一点。那么怎么判断一个 gt g t 的表现呢?我们可以通过已经计算出来的 ϵt ϵ t 来决定,好点的 gt g t 的 ϵt ϵ t 应该是很小的, ⧫t ⧫ t 就会比较大, 反之 ⧫t ⧫ t 就比较小。所以 αt α t 和 ⧫t ⧫ t 应该有一个单调的关系。这里取:
分析下这样的取法的物理意义是什么:
- 当 ϵ=12 ϵ = 1 2 的时候,表明 gt g t 表现的很差,这时 ⧫t=1 ⟶αt=0 ⧫ t = 1 ⟶ α t = 0 ,因为 gt g t 表现很差, 所以权重 αt=0 α t = 0 。
- 当 ϵ=0 ϵ = 0 的时候,表明 gt g t 的表现很好,这时 ⧫t=∞ ⟶αt=∞ ⧫ t = ∞ ⟶ α t = ∞ , 因为 gt g t 的表现很好,所有可以只由它来决定最后的分类。
3.2 - Adaptive Boosting算法
上面所有的这些综合起来就得到了 Adaptive Boosting A d a p t i v e B o o s t i n g 算法。该算法主要包括3个元素:比较弱的 base learning algorithm A b a s e l e a r n i n g a l g o r i t h m A (学生)用来得到 gt g t ;能够调整样本权重得到 optimal weight o p t i m a l w e i g h t 的 ⧫t ⧫ t (老师);最后对 gt g t 进行融合的 linear aggregatino l i n e a r a g g r e g a t i n o (整个班级对苹果的认识)。
Adaptive boosting(AdaBoost) A d a p t i v e b o o s t i n g ( A d a B o o s t )
u(1)=[1N,1N,⋯,1N]
u
(
1
)
=
[
1
N
,
1
N
,
⋯
,
1
N
]
for t=1,2,⋯,T
f
o
r
t
=
1
,
2
,
⋯
,
T
- obtain gt by A(D,u(t)) ,where A tries to minimize u(t) o b t a i n g t b y A ( D , u ( t ) ) , w h e r e A t r i e s t o m i n i m i z e u ( t ) - weighted 0/1 error w e i g h t e d 0 / 1 e r r o r
-
update u(t) to u(t+1) by
u
p
d
a
t
e
u
(
t
)
t
o
u
(
t
+
1
)
b
y
- |[yn≠gt(xn)]|: u(t+1)n⟵u(t)n⋅⧫t | [ y n ≠ g t ( x n ) ] | : u n ( t + 1 ) ⟵ u n ( t ) ⋅ ⧫ t
-
|[yn=gt(xn)]|: u(t+1)n⟵u(t)n/⧫t
|
[
y
n
=
g
t
(
x
n
)
]
|
:
u
n
(
t
+
1
)
⟵
u
n
(
t
)
/
⧫
t
where ⧫t=1−ϵtϵt−−−−√ and ϵt=∑Nn=1u(t)n|[yn≠h(xn)]|∑Nn=1u(t)n w h e r e ⧫ t = 1 − ϵ t ϵ t a n d ϵ t = ∑ n = 1 N u n ( t ) | [ y n ≠ h ( x n ) ] | ∑ n = 1 N u n ( t )
- compute αt=ln(⧫t) c o m p u t e α t = l n ( ⧫ t )
return G(x)=sign(∑Tt=1αtgt(x)) r e t u r n G ( x ) = s i g n ( ∑ t = 1 T α t g t ( x ) )
算法描述:刚开始的时候,所有的点的权重都是相同的, u(1)=[1N,1N,⋯,1N] u ( 1 ) = [ 1 N , 1 N , ⋯ , 1 N ] 。在 t t 轮的时候,使用得到一个 gt g t , 计算这个 gt g t 在 D~t D ~ t 的错误率 ϵt ϵ t , 进而可以计算相应的 ⧫t ⧫ t ,然后就可以对所有样本点的权重 u(t)n u n ( t ) 做更新得到 u(t+1)n u n ( t + 1 ) 用于下一轮的 gt+1 g t + 1 的计算,(具体的更新的规则是,如果对于第 n n 笔资料资料来说, gt(xn)≠yn g t ( x n ) ≠ y n 那么 u(t+1)n⟵u(t)n⋅⧫t u n ( t + 1 ) ⟵ u n ( t ) ⋅ ⧫ t ; 如果 gt(xn)=yn g t ( x n ) = y n 那么 u(t+1)n⟵u(t)n⋅⧫t u n ( t + 1 ) ⟵ u n ( t ) ⋅ ⧫ t 。直观上来说,就是要把被预测准确样本点的权重缩小;把被预测错误的样本点的权重增大), ⧫t ⧫ t 也可以用于 gt g t 的权重值 αt α t 的计算,用来对 gt g t 进行融合得到 G G 。这就是算法。简称 AdaBoost A d a B o o s t 。
关于 AdaBoost A d a B o o s t ,如果 base linear b a s e l i n e a r 的表现很弱,但至少比乱猜要好的话, 即 ϵt≤ϵ<12 ϵ t ≤ ϵ < 1 2 ,就可以通过 AdaBoost A d a B o o s t 使得 A A 越变越强,强到 Ein=0 E i n = 0 ,并且 Eout E o u t 也很小。理论分析得到在 T=O(logN) T = O ( l o g N ) 轮之后可以得到 Ein(G)=0 E i n ( G ) = 0 。
4 - Adaptive Boosting in Action
4.1 - Decision Stump
从刚刚的分析中我们知道
AdaBoost
A
d
a
B
o
o
s
t
只要搭配上一个在
weighted
w
e
i
g
h
t
e
d
-
error
e
r
r
o
r
上比乱猜做得好的
base learner
b
a
s
e
l
e
a
r
n
e
r
就可以有很好的效果。这样看来
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
就是一个不错的选择。
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
这个算法有三个参数,
(feature i,threshold θ,direction s)
(
f
e
a
t
u
r
e
i
,
t
h
r
e
s
h
o
l
d
θ
,
d
i
r
e
c
t
i
o
n
s
)
。
feature
f
e
a
t
u
r
e
指定我们使用哪个特征用于划分数据;
threshold
t
h
r
e
s
h
o
l
d
给出在
feature
f
e
a
t
u
r
e
上进行划分的边界值;
direction
d
i
r
e
c
t
i
o
n
决定划分之后哪一边是取正值,哪一边取负值。我们可以搜索所有的三种参数的组合,来选择使得
Ein
E
i
n
最小的
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
。对于在
AdaBoost
A
d
a
B
o
o
s
t
中的
weighted Ein
w
e
i
g
h
t
e
d
E
i
n
我们也可以搜索所有的组合, 来得到最好的划分的方式。
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
的时间复杂度为
O(d⋅NlogN)
O
(
d
⋅
N
l
o
g
N
)
, 其中
d
d
为特征的维度,为样本的个数。
从物理意义上来看, 其实就是在一个二维的平面上通过垂直的线或者水平的线来对数据进行二分类。所以
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
的能力是十分有限的。但是
AdaBoost
A
d
a
B
o
o
s
t
只需要一个弱弱的算法就可以。
4.2 - 一个简单的例子
以下看一个例子,即
AdaBoost+decision stump
A
d
a
B
o
o
s
t
+
d
e
c
i
s
i
o
n
s
t
u
m
p
来做资料的分类:
原始的数据如下:
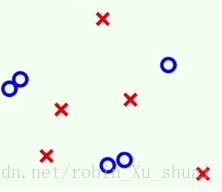
所有的数据的权重都是相同的, 使用
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
划分一次得到如下图的结果。
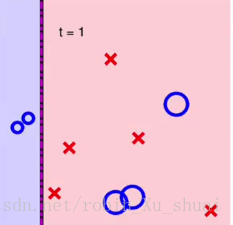
图1
三个蓝色的 ◯ ◯ 被划分错误,将其放大。其余判别正确的样本缩小,然后再使用 decision stump d e c i s i o n s t u m p 进行划分。
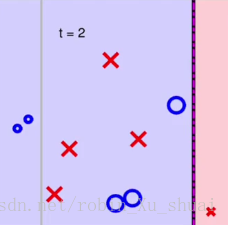
图2
由于在图1上 decision stump d e c i s i o n s t u m p 更多关注的是三个被放大的蓝色的 ◯ ◯ ,所以这次在图2的划分中这三个点划分正确了,但是另外的4个红色的 × × 被划分错误了。同样错误的放大, 正确的缩小。再做一次 decision stump d e c i s i o n s t u m p
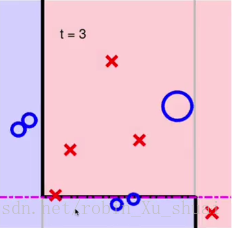
图3
如果把这样的三个分界线通过 AdaBoost A d a B o o s t 的机制融合起来的话,就得到了一个非线性的分界线 G G 。重复上面的操作在进行一次。
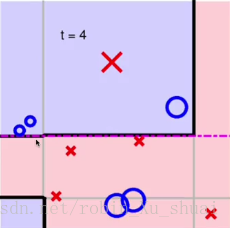
图4
进行第五次
decision stump
d
e
c
i
s
i
o
n
s
t
u
m
p
。所有的样本都已经被
G
G
完美的划分正确了。
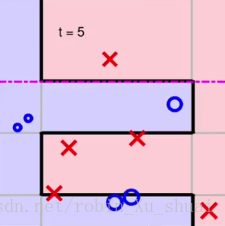
图5
4.3 - 一个更复杂的例子
原始的数据是这样的。

经过100次的之后,融合的 G G 如下图所示:
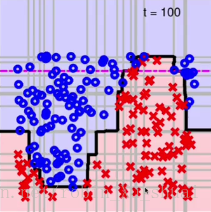
可以看到效果已经很好了。这样通过简单的的融合,我们最终得到了一个非线性的模型。相比于我们做 kernel k e r n e l 的 SVM S V M ,这个非线性的模型非常的高效, 不需要转换到一个高维甚至是无穷维度的空间中去求解一个复杂的二次规划的问题。
5 - 总结
本篇主要讲解了
Adaptive Boosting
A
d
a
p
t
i
v
e
B
o
o
s
t
i
n
g
算法。第一小节通过一个例子引出了该算法的基本思想,通过将一个个比较简单的,弱弱的学生的想法融合起来,最终可以得到一个比较复杂的模型。这个算法中一个很关键的步骤是每一轮中给所有的样本重新分配不一样权重,具体的做法是提高错误样本的权重;降低正确样本的权重,以此来得到不同的
gt
g
t
, 最后将这些
gt
g
t
整合起来就得到了一个很好的非线性的分类器。最后给出了
AdaBoost
A
d
a
B
o
o
s
t
配合
Decision Stump
D
e
c
i
s
i
o
n
S
t
u
m
p
的实际效果。
之前讲解了
Bagging
B
a
g
g
i
n
g
,这是
uniform
u
n
i
f
o
r
m
的
aggregation
a
g
g
r
e
g
a
t
i
o
n
;讲解了
AdaBoost
A
d
a
B
o
o
s
t
,这是
linear
l
i
n
e
a
r
的
aggregation
a
g
g
r
e
g
a
t
i
o
n
, 下一篇我们将介绍一个
conditional
c
o
n
d
i
t
i
o
n
a
l
的
aggregation
a
g
g
r
e
g
a
t
i
o
n
的方法
Decision Tree
D
e
c
i
s
i
o
n
T
r
e
e
。














 1706
1706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









