







第八讲:Adaptive Boosting
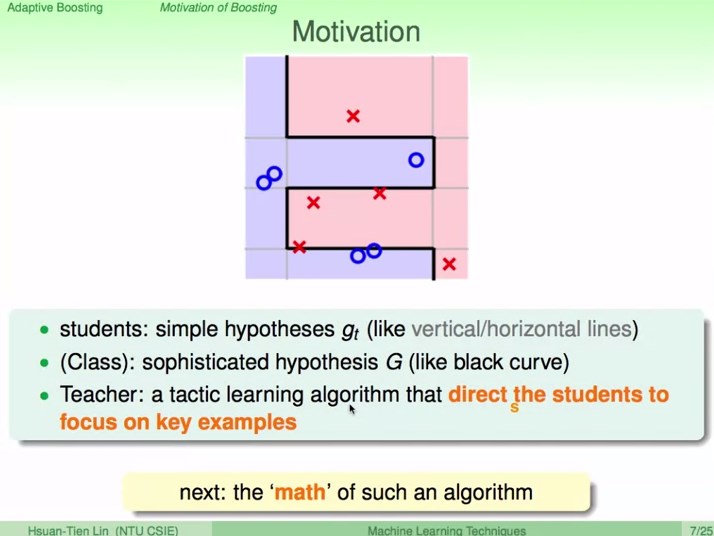
1、Motivation of Boosting
aggregate weak hypotheses for strength
例子:在一个班级中老师教学生辨识苹果。老师通过放大辨识错的图片,使得学生在下一次辨识中更专注于上一次有错的地方。
学生:简单的g
班级:融合成复杂的G
老师:引导学生专注于犯过错的地方
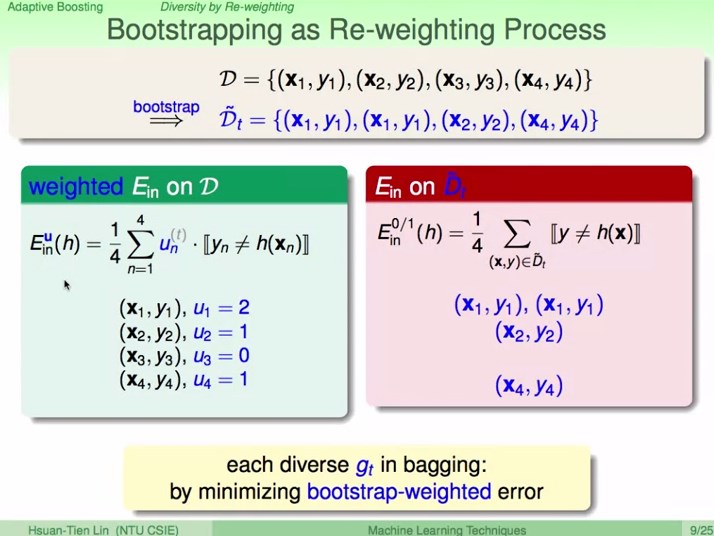
2、Diversity by Re-weighting
Bootstrapping可以看出是重新加权的过程。
在bagging中每个不同g尝试最小化通过boostrap加权后的错误。
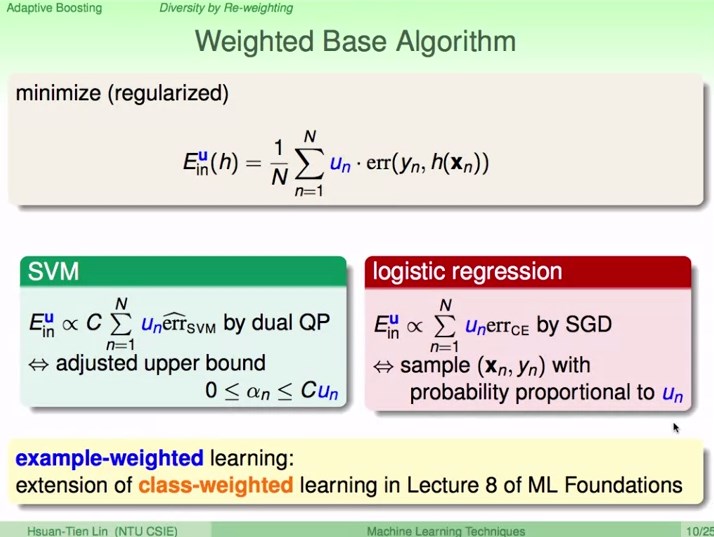
把权重u延伸到Base Algorithm里面
SVM中,相当于调整了upper bound C。
LR中,调整采样的权重。
模型差异越大,融合后表现越好。那么如何通过重新加权得到不一样的g呢?
idea:
(1)在权重u
t下表现最好的模型g
t
(2)
在权重
u
t+1
下表现最好
的模型
g
t+1
(3)调整
u
t+1使得
g
t表现不好,而
u
t+1下
模型
g
t+1
表现最好
,那么
g
t和
g
t+1的差异就大了。

犯错/(犯错 +没犯错) = 1/2
错误的*正确的比例
正确的*错误的比例
这样原来的g
t在新的一轮表现很差,就不会被base算法选中,这样和
g
t+1
就有差异了。

3、Adaptive Boosting Algorithm
错误被放大,正确被缩小,从而得到不同的hypotheses。

初步的算法:
一开始g1的权重是一样的
得到众多个g如何融合成G:线性或非线性融合,不能平均融合,因为除了g1,其他g都是重新加权的,对Ein表现不好。

线性融合
思想: 好的g,a也要大。

AdaBoost算法
三个臭皮匠,顶个诸葛亮

AdaBoost的理论保证
AdaBoost是一个逐步做到boosting的算法

4、Adaptive Boosting in Action
AdaBoost需要搭配一个弱弱的演算法
decision stump模型

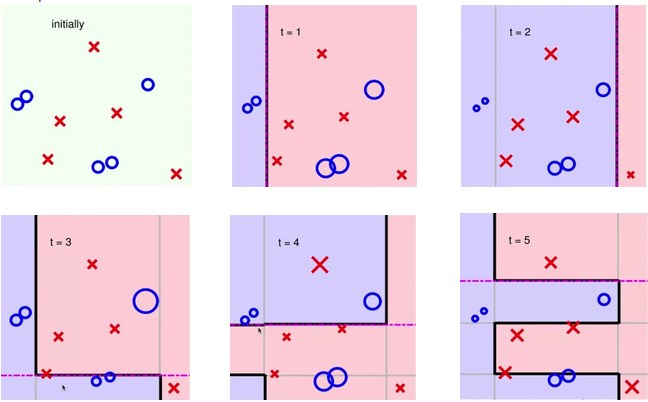
A Complicated Data Set
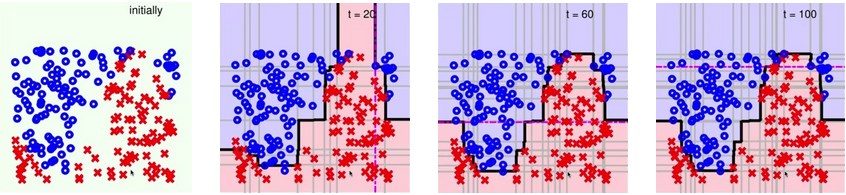
AdaBoost-Stump在人脸识别中的应用
把图片切分成很多细小的图片,看哪些细小的图片中有关键图案,把关键图案提供的信息通过AdaBoost整合起来。
选择特征或细小图片的过程


















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









