






emotion2vec 是一个由上海交通大学、阿里巴巴、复旦大学和香港中文大学的研究者们共同开发的通用语音情感表征模型。该模型通过自监督学习方法,在大量无标记的公开情感数据上进行预训练,以学习到高度通用的语音情感特征。模型旨在训练语音情感识别领域的“耳语”,通过数据驱动的方法克服语言和记录环境的影响,以实现通用、强大的情感识别能力。
2024年5月,语音情感基座模型emotion2vec的新版本发布emotion2vec+。emotion2vec+ 的迭代过程最终是在 160,000 小时的语音情感数据中筛选出 40,000 小时的数据来训练 emotion2vec+ large 模型。emotion2vec+在 Hugging Face的表现明显超过其他高下载开源机型,详图如下:
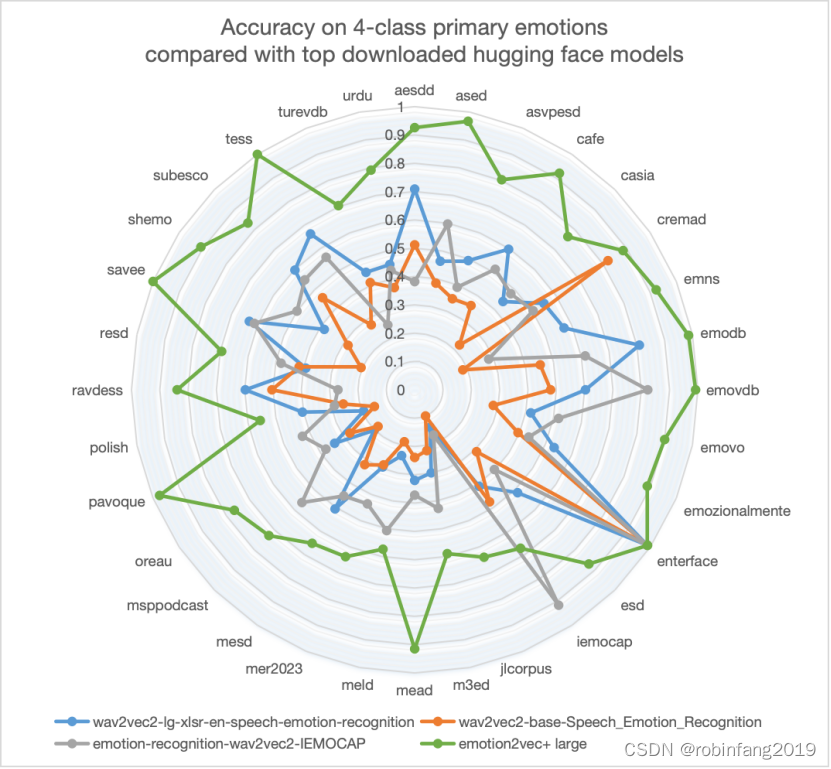
emotion2vec+包含以下三个版本:
- emotion2vec+ seed:使用学术演讲情感数据进行微调
- emotion2vec+ base:使用过滤的大规模伪标记数据进行微调,以获得基本大小模型(~90M)
- emotion2vec+ large:使用过滤的大规模伪标记数据进行微调,以获得大尺寸模型(~300M)
1、技术框架
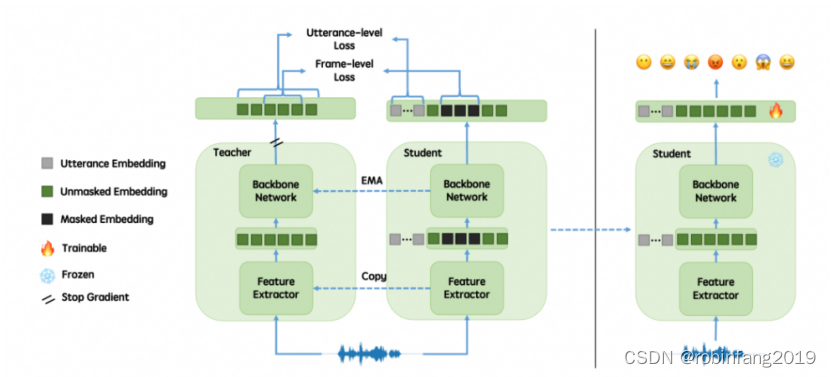
1.1 句子级别损失(Utterance-level Loss)
通过均方误差(MSE)计算整体全局情绪,能够捕捉到整个句子的情感信息。
包括单嵌入(Token Embedding)、块嵌入(Chunk Embedding)和全局嵌入(Global Embedding)三种方法,这些方法可以根据具体需求选择使用。
1.2 帧级别损失(Frame-level Loss)
设计为一个逐帧的预设任务,用于学习上下文中的情绪信息。在预训练过程中,结合帧级别损失来进一步细化情感表征,使模型能够更好地理解短时间内的情感变化。
1.3 在线蒸馏(Online Distillation)
一种自监督学习策略,适用于教师-学生(Teacher-Student)学习框架。采用在线蒸馏范式,即在预训练过程中不断地从大规模未标记的情感数据中提取特征,并通过在线蒸馏不断优化模型。这种在线蒸馏方法使得模型能够从师生两个网络中迭代学习,不断提升模型对情感特征的捕捉和理解能力。
2、详细训练过程
2.1 数据准备
emotion2vec模型利用大量无标记的公开情感数据进行预训练。
使用四万小时的情感数据进行训练。
2.2 自监督学习方法
通过自监督在线蒸馏(self-supervised online distillation)进行预训练。
结合句子级损失和帧级损失,以更好地捕捉情感信息。
2.3 预训练策略
在预训练过程中,结合句子级损失和帧级损失,以提高模型对情感信息的捕捉能力。
通过这种策略,情感2vec能够在不同的任务、语言和场景中提取情感表征。
2.4 模型结构
emotion2vec模型通过仅训练线性层来实现高效的预训练,这使得其在多种任务中表现优异。
2.5 安装环境和用法
安装环境:pip install -U funasr modelscope。
input: 16k Hz 的语音
granularity:
"utterance": 提取整句语音特征
"frame": 提取帧级别特征(50 Hz)
extract_embedding: 是否提取特征
3、性能评价
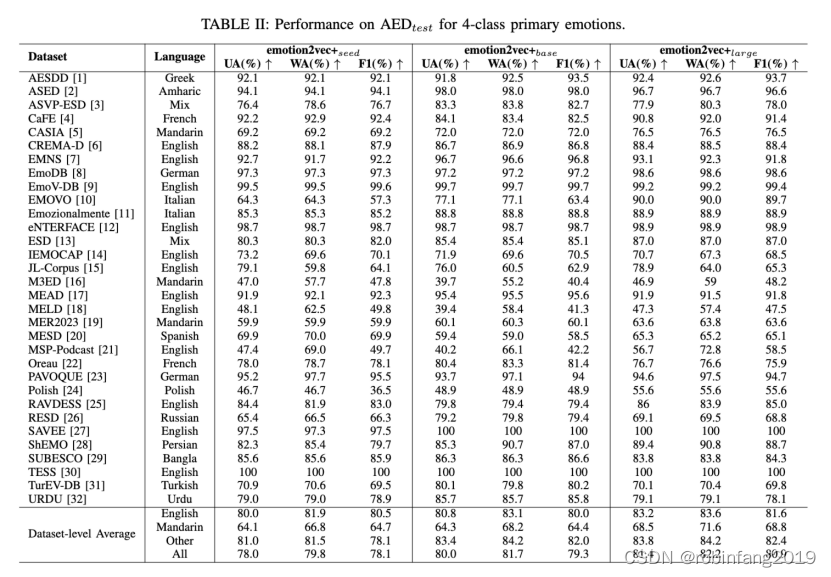
AED(自动错误检测)测试中的UA(用户接受度)、WA(错误率)和F1(精确度-召回率比)是评估系统性能的关键指标。
用户接受度(UA):这是衡量系统正确拒绝不相关或错误输入的能力。在安全相关的应用中,如AED系统,高用户接受度意味着系统能够有效地识别并阻止潜在的恶意输入,从而保护系统免受攻击。例如,通过对抗性训练和音频去噪等方法可以显著提高分类器在遭受攻击时的性能,这些方法可以增加近五十个百分点的性能提升。
错误率(WA):这是衡量系统正确识别语音输入的比例。在AED测试中,错误率越低,表明系统的识别能力越强。
精确度-召回率比(F1分数):这是一个综合指标,用于衡量系统在特定任务上的整体表现。它结合了精确度和召回率两个方面,提供了一个平衡这两者的方式。在上述提到的非母语阿拉伯语的发音错误检测和诊断研究中,最佳模型在识别任务中达到了3.83%的错误率,并且在MDD任务中获得了70.53%的F1分数。
4、相关资源
下载链接:
emotion2vec在线体验:

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









