







发表至:ACL 2024 Findings
摘要
emotion2vec,一个通用的语音情感表示模型。在开源的无标签情感数据上通过自监督的在线蒸馏进行预训练,训练过程中结合了语句级损失和帧级损失。emotion2vec 在主流的 IEMOCAP 数据集上,仅通过训练线性层,就在语音情感识别任务上超越了当前最先进的预训练通用模型和情感专用模型。
此外,emotion2vec 在 10 种不同语言的语音情感识别数据集上表现出一致的改进。emotion2vec 在其他情感任务(如歌曲情感识别、对话中的情感预测和情感分析)中也表现出色。
对比实验、消融实验和可视化分析全面展示了 emotion2vec 的通用能力。据我们所知,emotion2vec 是第一个在各种情感相关任务中表现出通用能力的表征模型,填补了该领域的空白。
方法
本文主要介绍 emotion2vec 的自监督预训练方法,其核心是通过在线蒸馏范式,结合语句级损失和帧级损失来训练模型。
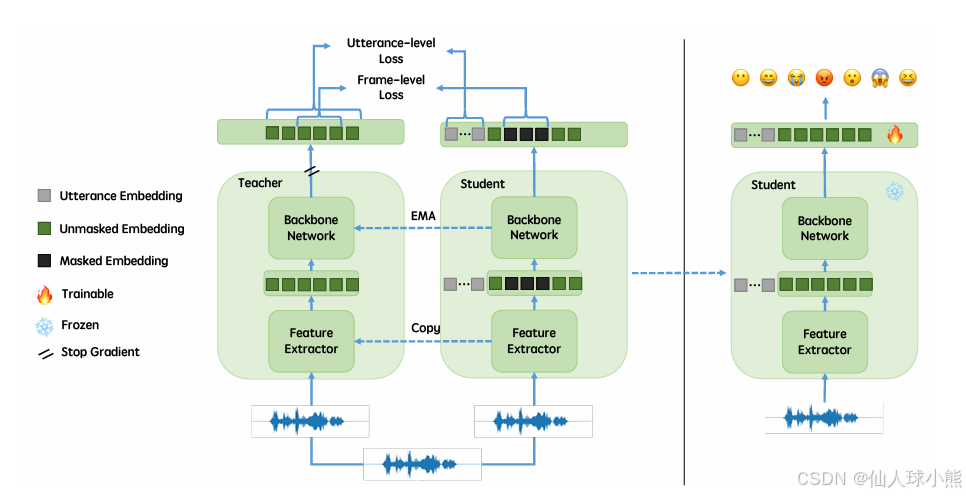
模型流程
如图 1 所示,emotion2vec 在预训练阶段包含两个网络:教师网络(Teacher Network, TTT)和学生网络(Student Network, SSS)。这两个网络共享相同的模型架构,包括:
- 特征提取器(Feature Extractor, FFF):由多层卷积神经网络(CNN)组成。
- 主干网络(Backbone Network, BBB):由多层 Transformer 组成。
这些模块可以根据需要配置为不同的架构。

- 教师网络和学生网络的架构完全相同,但教师网络的参数通过指数移动平均(EMA)更新,而学生网络的参数通过反向传播更新。
- 特征提取器的作用是将原始音频数据下采样为更紧凑的特征表示,减少计算复杂度。
- 主干网络(Transformer)进一步处理这些特征以提取更高层次的情感信息。
语句级损失(Utterance-level Loss)
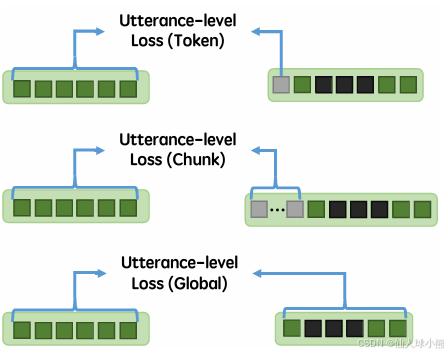
语句级损失旨在学习全局情感信息。我们构建了一个语句级的预训练任务,用于捕获音频的整体情感特征。损失函数使用均方误差(MSE)计算,公式如下:
平均池化:对时间维度上的所有帧取平均值

三种计算语句级损失的方法:
- Token Embedding:使用单个 token 表示全局情感信息。
- Chunk Embedding:使用多个 token 表示全局情感信息,允许更多的全局信息聚合。
- Global Embedding:不添加额外的语句 token,而是直接对帧级输出进行时间池化。
解读:
- 语句级损失的目标是捕获音频的整体情感特征,例如音频的整体情绪是“愤怒”还是“高兴”。
- Chunk Embedding 提供了更丰富的全局信息聚合能力,因此在实验中表现最佳。
帧级损失(Frame-level Loss)
帧级损失旨在学习上下文情感信息。我们仅在被掩码的部分计算损失,这是掩码语言建模(MLM)任务的常见做法。帧级损失的公式如下:
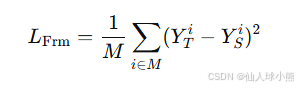
其中:
- M 表示帧级输出嵌入Ys被掩码的索引序列。
- M 是被掩码的 token 总数。
解读:
- 损失计算:只在被掩码的帧上计算损失,未被掩码的帧不参与损失计算,帧级损失的目标是捕获音频的局部情感特征,例如某一时刻的情绪变化。
- 预测任务:被掩码的是当前帧,模型需要根据上下文(未被掩码的帧)来预测被掩码帧的原始特征或类别。通过掩码的方式,模型可以学习到更强的上下文依赖性。
框架细节提炼:
- 教师的全局特征:教师网络的全局特征是通过所有的 token(帧级特征)计算的,没有额外的 token,也没有 mask 操作。
- 学生的全局特征:学生网络的全局特征是通过额外的 chunk token(或其他形式的全局 token)计算的,这些 token 是专门设计用来捕获全局信息的。
- 教师的帧级特征:教师网络的帧级特征是在无 mask 的条件下直接预测的,完整地利用了输入的所有信息。
- 学生的帧级特征:学生网络的帧级特征是在 mask 条件下预测的,即部分输入被遮盖,学生需要通过上下文推断被遮盖的部分。
这样设计的目的是什么?
- 教师网络的作用:教师网络在无 mask 条件下预测帧级特征,能够完整地捕获输入的全局和局部信息,生成高质量的特征表示。这些特征可以作为学生网络的学习目标,提供指导价值。
- 学生网络的作用:学生网络在 mask 条件下预测帧级特征,目的是通过上下文推断被遮盖的信息,从而学习更强的上下文建模能力。这种能力对于情感表示(尤其是语音情感)非常重要,因为情感通常依赖于语音的上下文信息。
- 全局特征的差异:学生网络通过额外的 chunk token 或全局 token 来捕获全局信息,而教师网络直接通过所有帧级特征的聚合来捕获全局信息。这种差异可以让学生网络在学习过程中更专注于如何从局部特征中提取全局信息。
教师对学生的指导价值
- 高质量的目标特征:教师网络生成的帧级特征和全局特征是高质量的,学生网络通过模仿这些特征可以学习到更好的表示。
- 对比学习的框架:通过对比教师和学生的特征,学生网络可以不断优化自身的特征表示,使其在 mask 条件下的预测能力逐渐接近教师网络的无 mask 特征。
- 逐步提升学生的能力:教师网络的特征是完整的,而学生网络的特征是通过不完整输入推断的。通过这种设计,学生网络可以逐步学习如何在不完整的输入条件下生成高质量的特征。
在线蒸馏:
这种在线蒸馏方法的优点在于:
- 动态更新:教师网络在训练过程中不断更新,能够适应学生网络的变化。
- 高效学习:学生网络通过对比教师网络的输出,能够更快地学习到高质量的特征表示。
- 稳定性:EMA 的引入使得教师网络的输出更加平滑,避免了训练过程中的震荡。


















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











