







来自 B 站刘二大人的《PyTorch深度学习实践》P11 的学习笔记
GoogLeNet
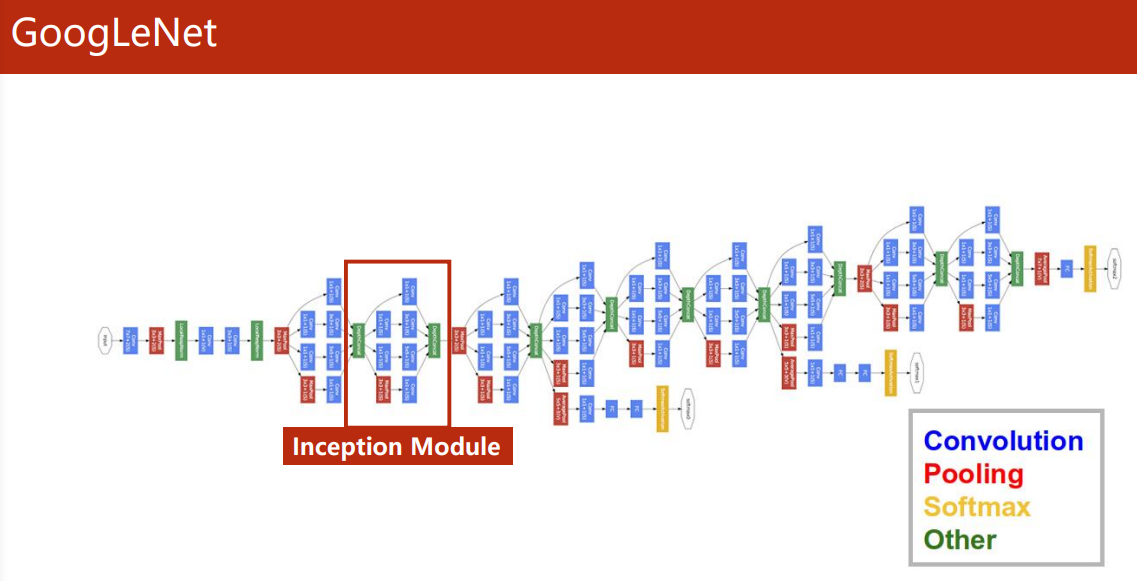
-
1×1 卷积
上一篇我们知道,卷积的个数取决于输入图像的通道数。
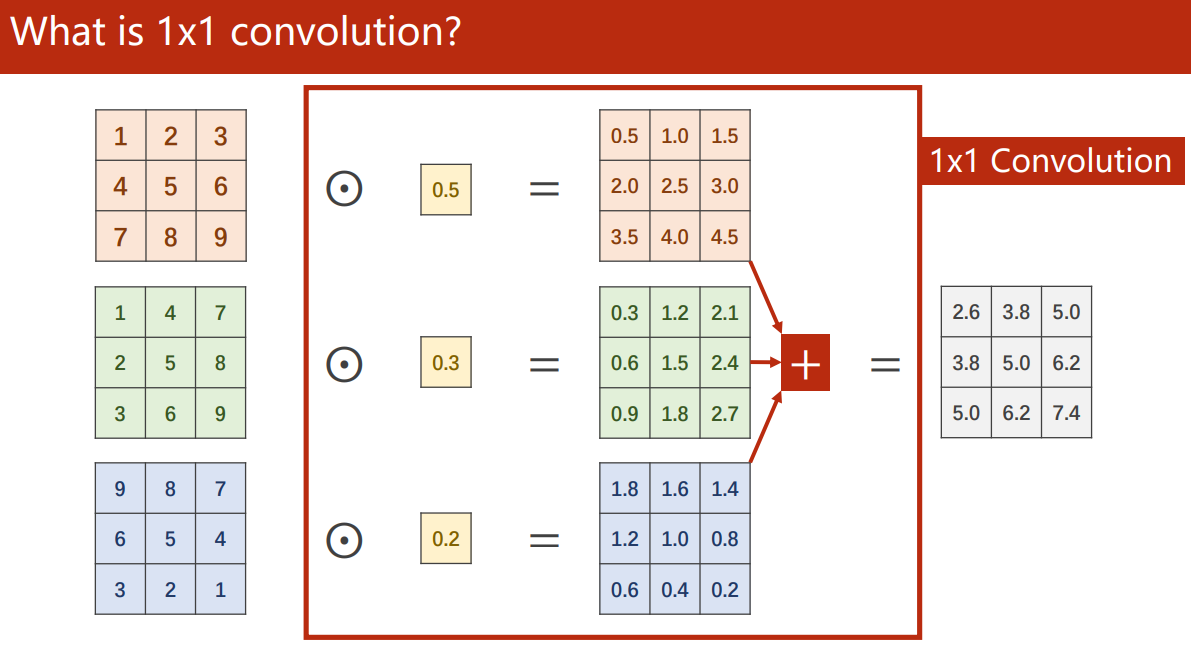
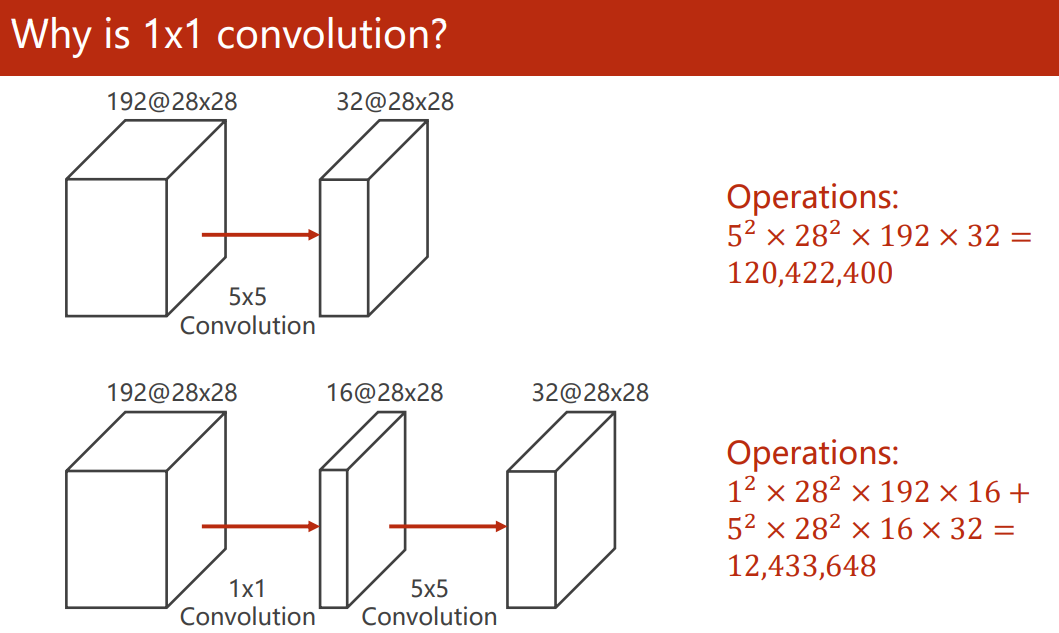
1×1 卷积能起到特征融合、改变通道数和减少计算量的效果,被称为神经网络中的神经网络最先用 1×1 卷积替换全连接层的是 NiN 模型(Network in Network1) ,使用 1×1 卷积目的就是为了避免全连接带来的参数爆炸。
例如,我们先通过 1×1 卷积减少了通道的数量,让大的卷积核计算更少的通道数,能大大减少计算量:
-
Inception Module
Inception(盗梦空间) Module 的目的在于给神经网络提供并行的卷积的、池化 配置路线,通过不同窗口形状的卷积层和池化层来并行抽取信息,并使用 1×1 卷积层来减少通道数从而降低模型复杂度。
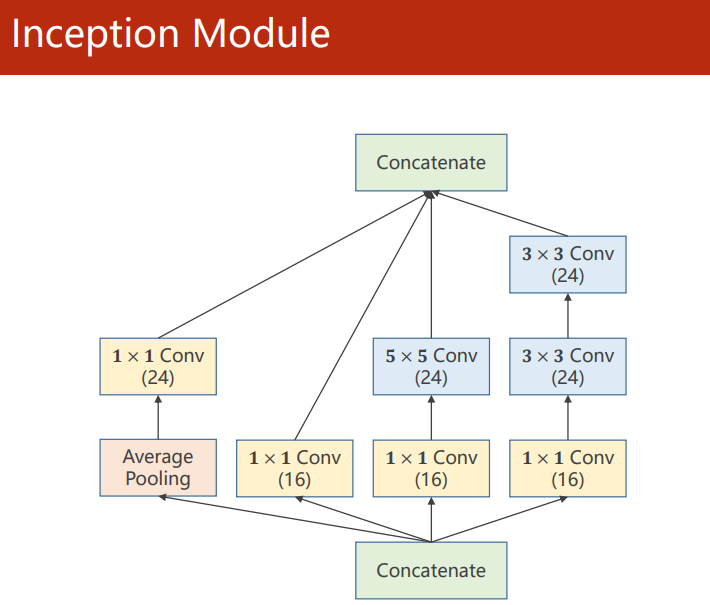
由于每条路线的最终结果需要堆叠起来,所以需要保证输出的特征图大小一致,对于 Average Pooling 池化层,需要通过 padding 和 stride 来保证最后的输出大小。
实现
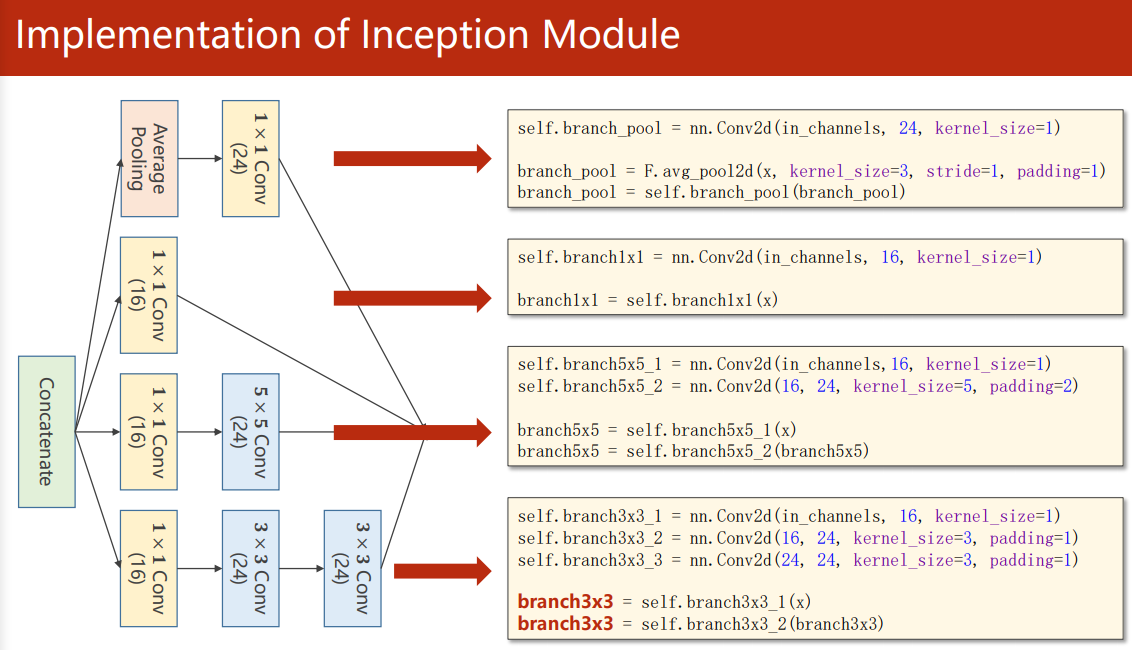
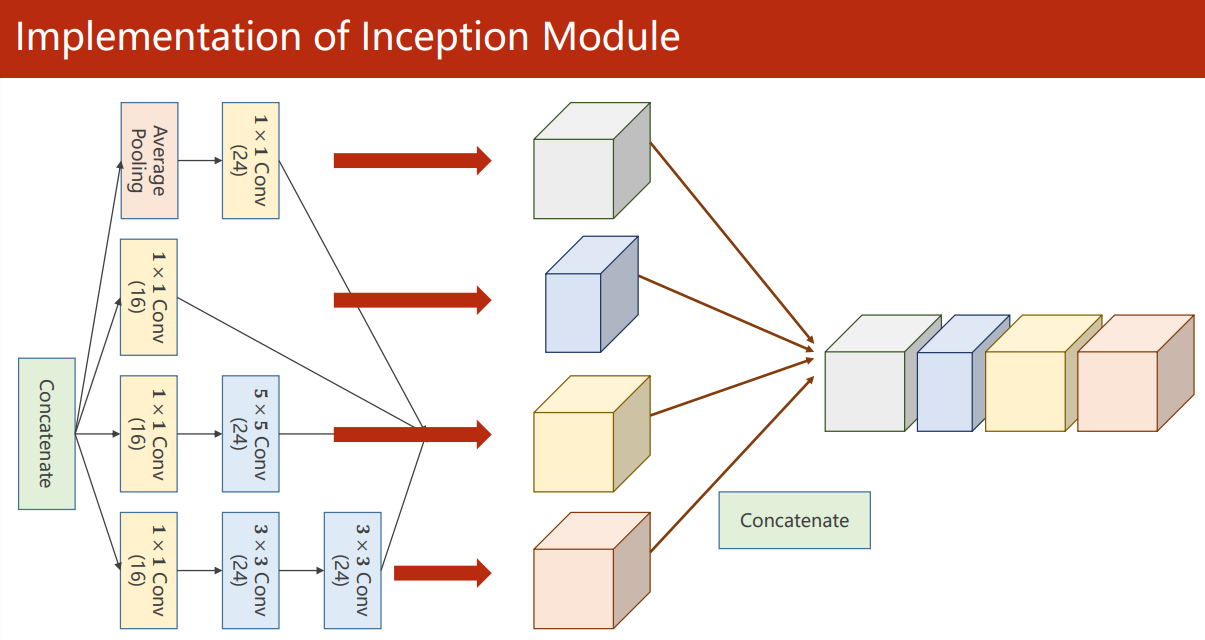
把输出拼接到一起再输入下一层
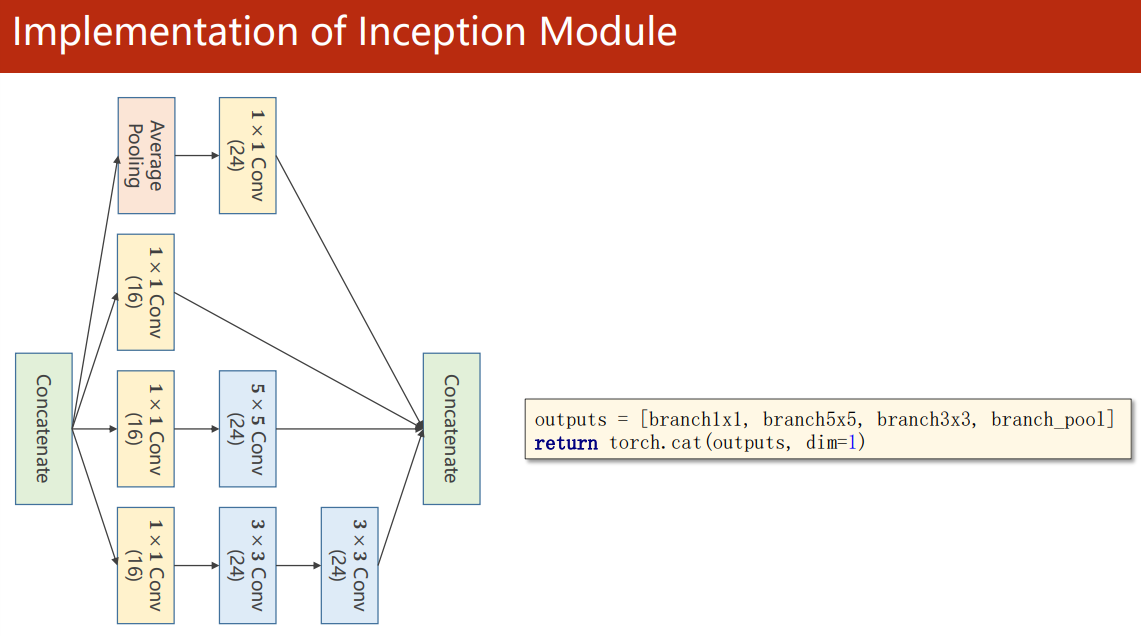
torch.cat(outputs, dim=1) 中,dim=1 指的是以通道维度拼接(N,C,W,H)
用了两个 Inception Module:
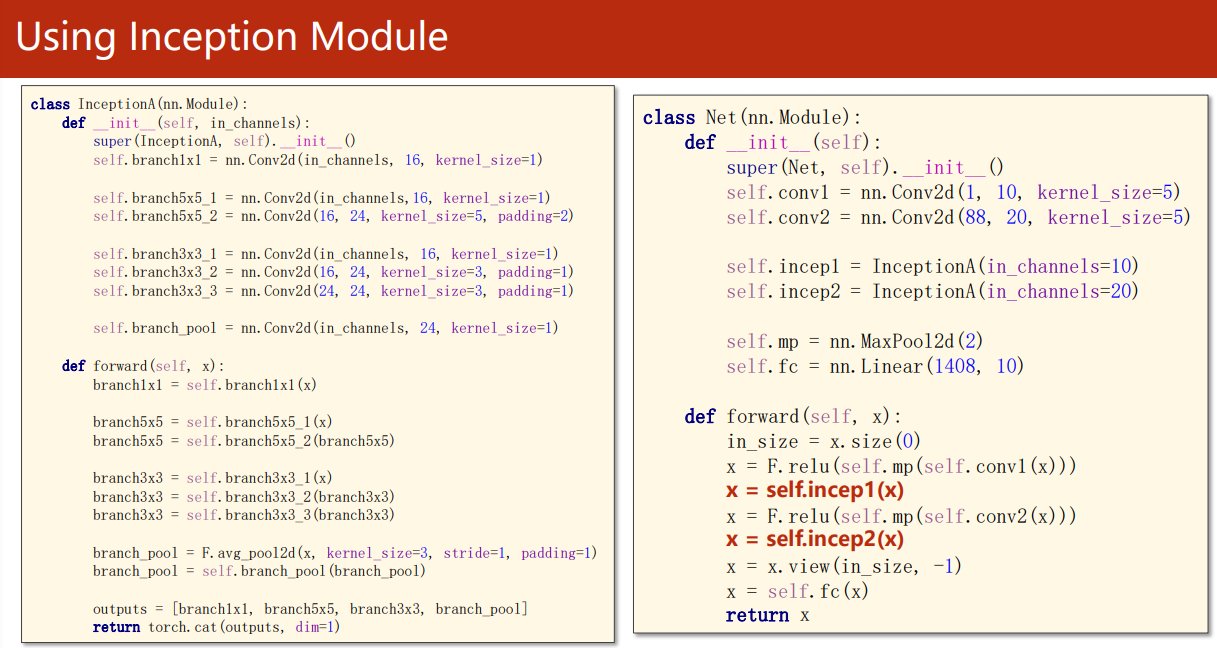
我们只需要把上一篇代码中的神经网络部分换成 GoogleNet,即可使用它来识别 MNIST 数据集:
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
"""
由于特征图要拼接,所以需要通过设置padding、stride来保证卷积过后特征图大小不变;
由于在Inception块之前还有卷积层,所以输入的通道数不是一样的,需要把输入通道数作为一个参数。
:return:
输出的通道数为 16+24×3=88,故返回 N,88,*,* 的特征图
"""
def __init__(self, in_channels):
super(Inception, self).__init__()
self.pool_conv1x1 = nn.Conv2d(in_channels, 24, kernel_size=1) # 池化+一个1×1卷积,输出24通道
self.conv1x1 = nn.Conv2d(in_channels, 16, kernel_size=1) # 三个同样的1×1卷积,输出16通道
self.conv3x3_16 = nn.Conv2d(16, 24, kernel_size=3, padding=1) # 输入为16通道的3×3卷积,输出24通道
self.conv3x3_24 = nn.Conv2d(24, 24, kernel_size=3, padding=1) # 输入为24通道的3×3卷积,输出24通道
self.conv5x5 = nn.Conv2d(16, 24, kernel_size=5, padding=2) # 一个5×5卷积,输出24通道
def forward(self, x):
out1 = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) # N,*,,
out1 = self.pool_conv1x1(out1) # N,24,,
out2 = self.conv1x1(x) # N,16,,
out3 = self.conv1x1(x) # N,16,,
out3 = self.conv5x5(out3) # N,24,,
out4 = self.conv1x1(x) # N,16,,
out4 = self.conv3x3_16(out4) # N,24,,
out4 = self.conv3x3_24(out4) # N,24,,
outputs = (out1, out2, out3, out4)
return torch.cat(outputs, dim=1) # N,88,,
class GoogleNet(nn.Module):
def __init__(self):
super(GoogleNet, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # return N,10,,
self.incep1 = Inception(in_channels=10) # return N,88,,
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep2 = Inception(in_channels=20) # return N,88,,
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) # N,10,12,12
x = self.incep1(x) # N,88,12,12
x = F.relu(self.mp(self.conv2(x))) # N,20,4,4
x = self.incep2(x) # N,88,4,4
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = GoogleNet()
Go Deeper
GoogleNet 借助 Inception Module 实现并行特征学习的网络来提高性能(宽度大),但是,神经网络的强大能力一直在被验证为是深度起决定性作用。

受深度的重要性的驱动,一个问题出现了:学习更好的网络是否像叠加更多层一样容易?回答这个问题就不得不提到一个障碍——臭名昭著的梯度消失 / 爆炸问题。
ResNet
-
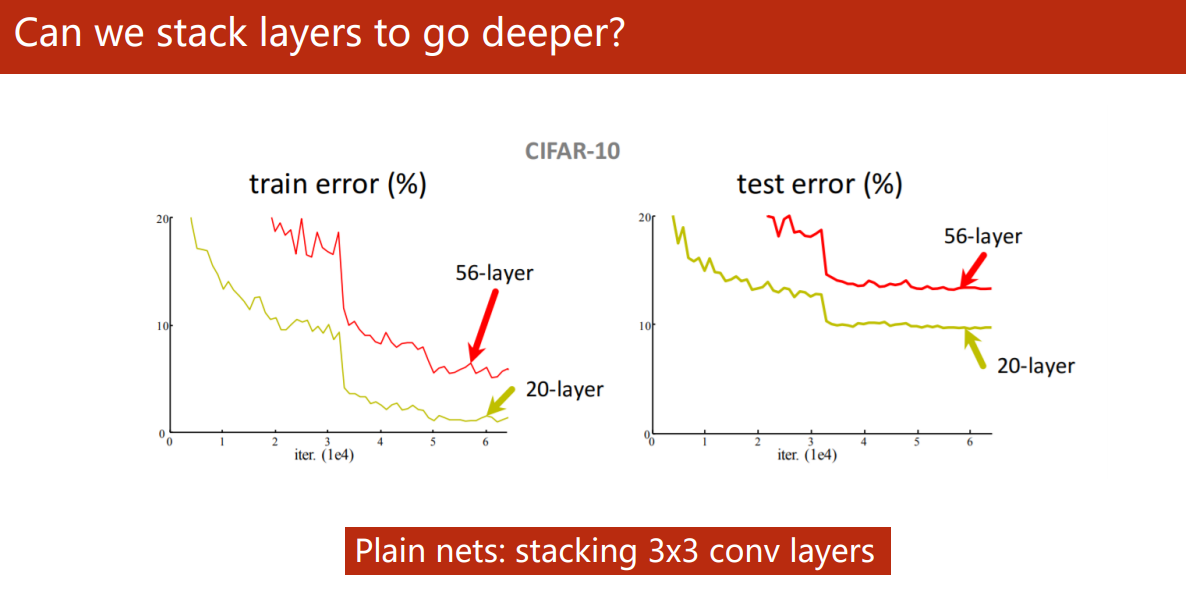
Can we stack layers to go deeper?
5 年前,何凯明大神的论文《Deep Residual Learning for Image Recognition》2 揭示了神经网络不是盲目地叠得越深就越好。
图中所示 56 层深的网络的训练以及测试的错误率都比 20 层的要高,其中一个主要的原因是越深层的网络越容易发生梯度消失,造成一部分的网络层很难在训练中更新。
-
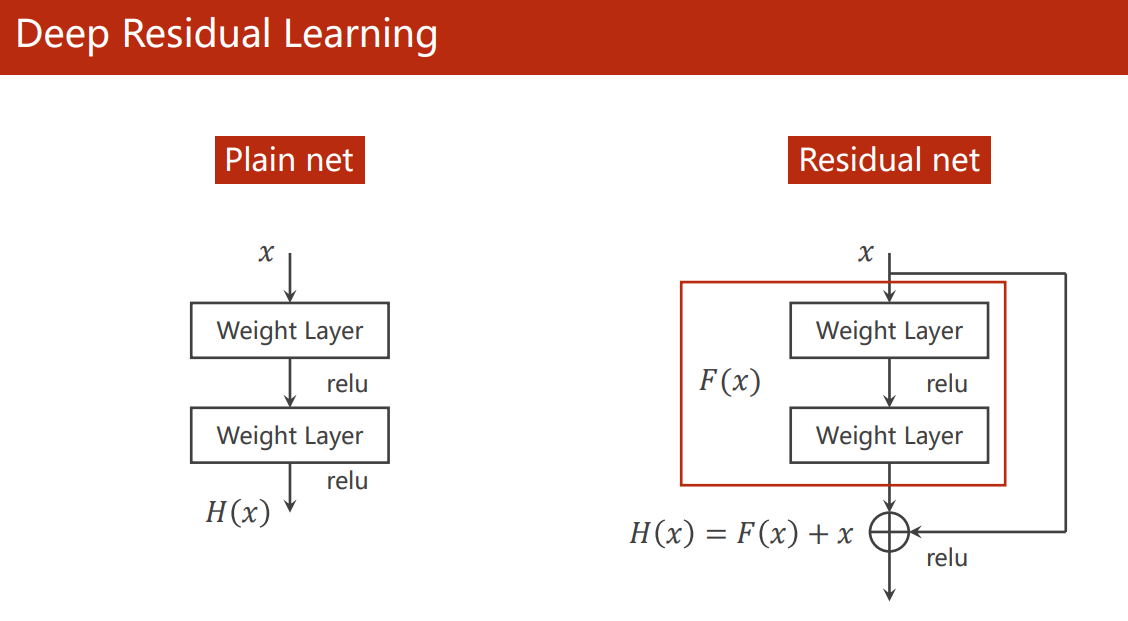
Residual Block
于是,ResNet 提出了残差连接模块,通过跳连(shortcut)的方式更容易保留上一层的梯度(图中少了 BatchNorm 层)。
所谓残差,由下图,一个 Residual block 的输出 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x 可知,红色方框的 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x, F ( x ) F(x) F(x) 是神经网络要学习的部分(卷积层的参数),这部分是最终输出的 H ( x ) H(x) H(x) 的残差,故称之为残差学习。
论文指出残差学习在实践中更容易优化。(我想还不如不直接说连了这条线之后,反向传播的梯度更容易反馈回整个网络,从而更容易优化)
由于经过卷积后的特征图要和前一层的输出相加,所以整个 ResNet 的卷积层的输出特征图大小都要保证相同,或者每一个 Residual Block 中的卷积输出要一致。
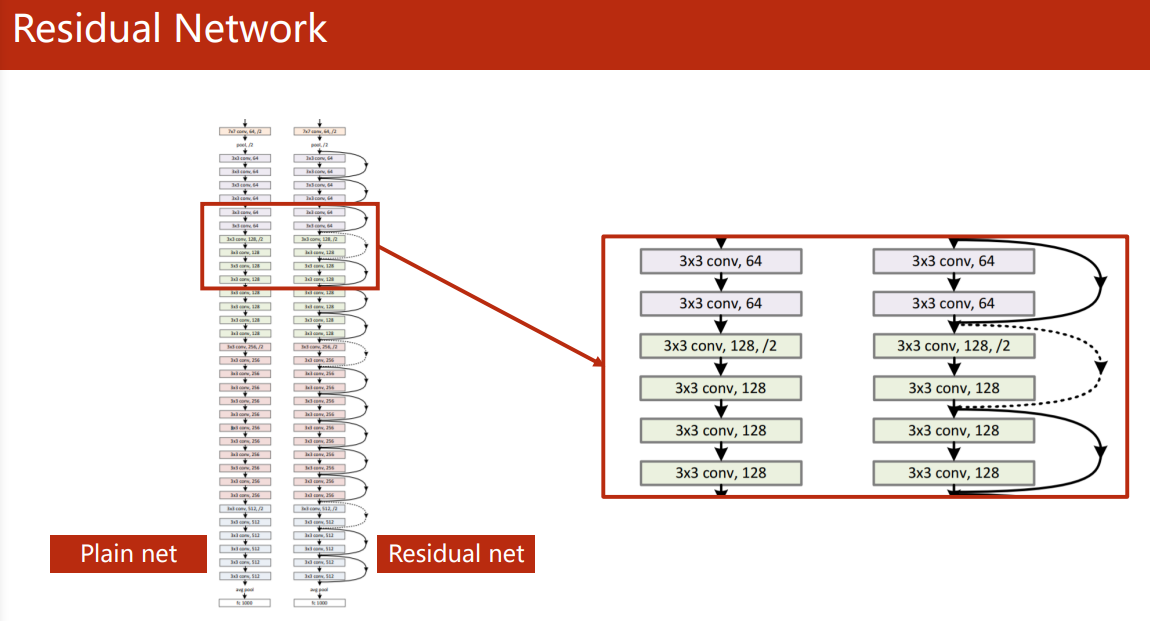
Residual Block 的实现:

论文3 有更加详细的 Residual Block 流程图: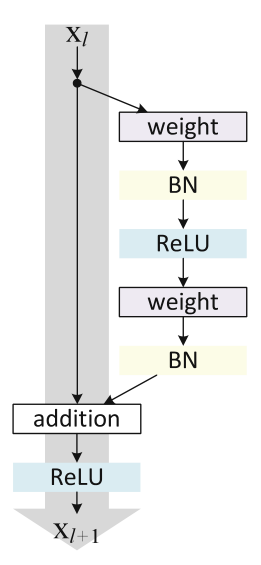
ResNet 的实现:

from torch import nn
from torch.nn import functional as F
from train_and_test import train, test, draw
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.bn = nn.BatchNorm2d(channels)
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) # 特征图大小没变
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.bn(self.conv1(x)))
y = self.bn(self.conv1(y))
return F.relu(x + y) # 不是拼接,所以返回通道数还是 channel
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.rblock1 = ResidualBlock(channels=16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.rblock2 = ResidualBlock(channels=32)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(512, 10)
def forward(self, x):
batch_size = x.size(0)
x = self.mp(F.relu(self.conv1(x))) # N,16,12,12
x = self.rblock1(x) # N,16,12,12
x = self.mp(F.relu(self.conv2(x))) # N,32,4,4
x = self.rblock2(x) # N,32,4,4
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = ResNet()
读论文,复现 ResNet v2
复现何凯明大神的 ResNet v2:《Identity Mappings in Deep Residual Networks》3
其实,这篇论文主要讨论了 ResNet 的 Residual Block 可能的各种魔改方式:
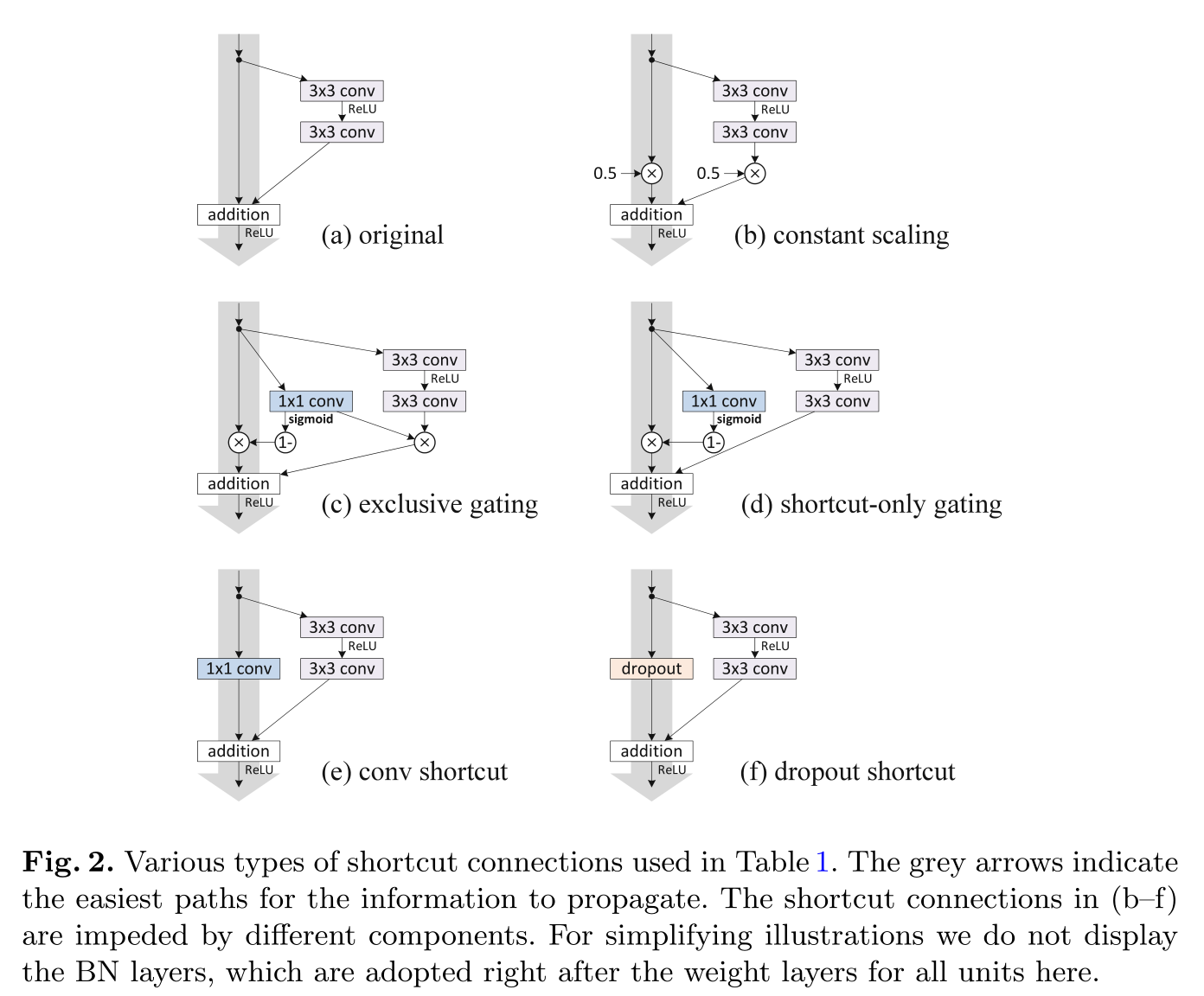
- shortcut(灰色箭头线、快捷链接)上加入其它操作或者像 Inception Module 一样搞多个分支:
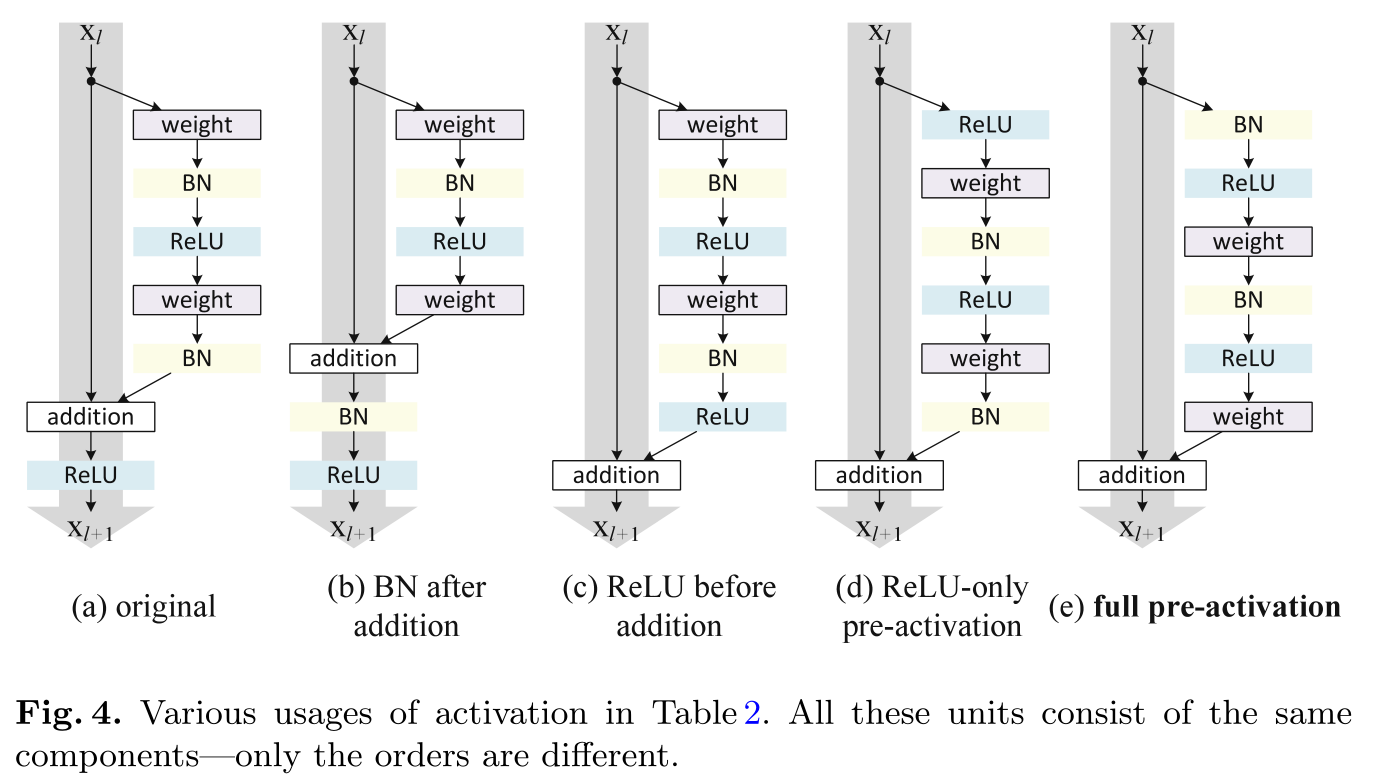
- 归一化层(BatchNorm)和激活层(ReLU)的不同顺序:
最终的结论是 shortcut(灰色箭头线、快捷链接)最好不做其它操作,尽量保持干净,以便信息的传播。消融实验(控制变量法)也表明,original shortcut2 (Fig.2. (a) original)已经是最好的了。
对于归一化层(BatchNorm)和激活层(ReLU)顺序的魔改问题。最终的消融实验(控制变量法)表明,BN+ReLU 层在卷积层前面先对输入进行计算是更好的(Fig.4. (e) full pre-activation),比2 还好。
所以代码只需要改一下 ResidualBlock 的 BN+ReLU 的顺序:
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.bn = nn.BatchNorm2d(channels)
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) # 特征图大小没变
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = self.conv1(F.relu(self.bn(x)))
y = self.conv2(F.relu(self.bn(y)))
return x + y # 不需要再激活
读论文,复现 DenseNet
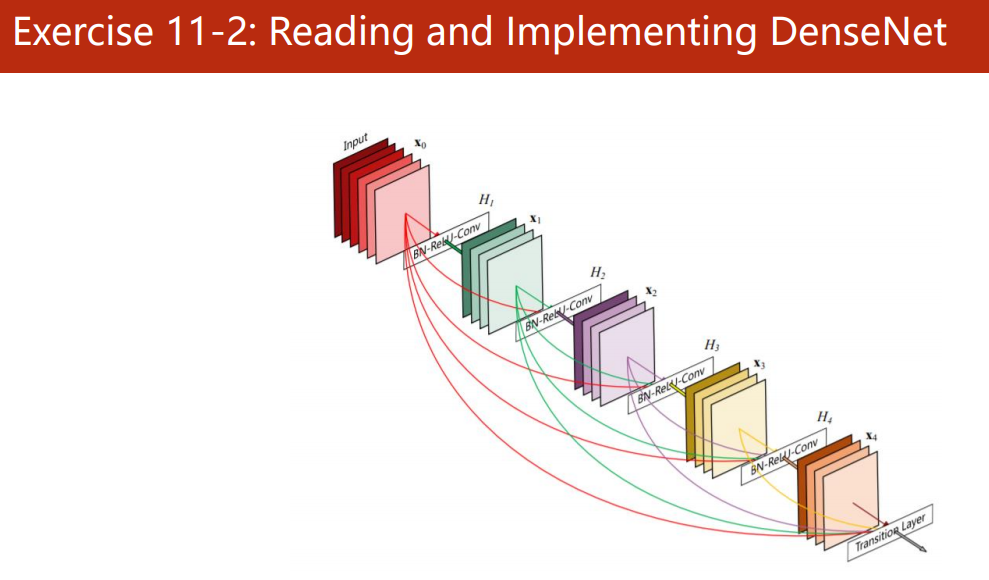
参见:《卷积神经网络进阶(DenseNet)》
Lin, Min et al. “Network In Network.” CoRR abs/1312.4400 (2014): n. pag. ↩︎
He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:770-778. ↩︎ ↩︎ ↩︎
He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks[C]. ↩︎ ↩︎















 1827
1827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











