






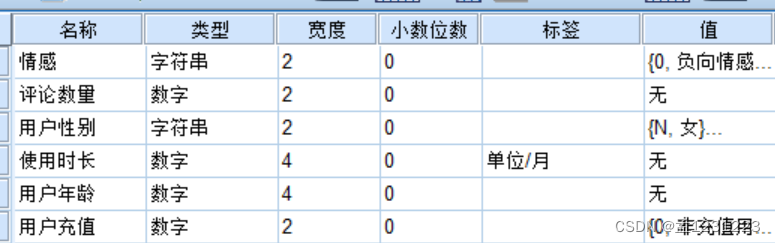
首先设置好字段和属性
然后填充表格数据(数据为随机填写,非调查、非真实来源)
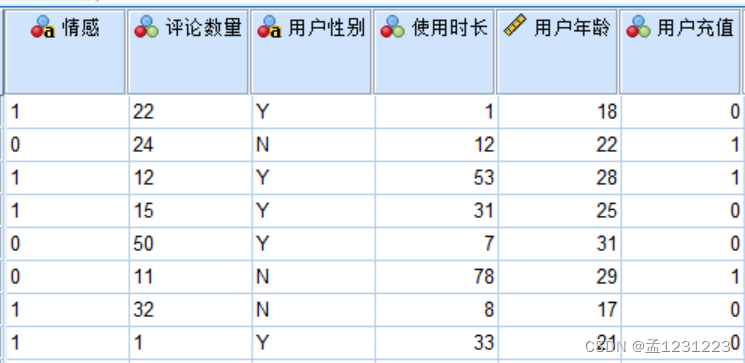
然后进行随机森林的分析,钯用户充值设为因变量,其他归为自变量,设置训练样本为70%。由于数据过少,父节点设置为4,子节点设置为2.
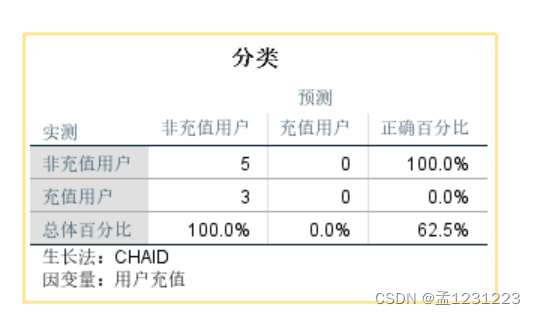
预测结果如下图:
可以看出少量数据训练出的模型还是过拟合了,非充值用户准确率66.7%,充值用户直接0正确率。
那么如果使用交叉验证,将验证数设为3(目标样本小于10)
在本数据下,使用交叉验证的方法会提高总体预测的正确百分比。
首先设置好字段和属性
然后填充表格数据(数据为随机填写,非调查、非真实来源)
然后进行随机森林的分析,钯用户充值设为因变量,其他归为自变量,设置训练样本为70%。由于数据过少,父节点设置为4,子节点设置为2.
预测结果如下图:
可以看出少量数据训练出的模型还是过拟合了,非充值用户准确率66.7%,充值用户直接0正确率。
那么如果使用交叉验证,将验证数设为3(目标样本小于10)
在本数据下,使用交叉验证的方法会提高总体预测的正确百分比。
 3244
2万+
402
2146
2万+
3244
2万+
402
2146
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























