







课程视频链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
大模型的趋势是从专用模型(不同方向细分模型)转变为通用大模型(一个模型可以应对多种任务或者多种模态)。书生·浦语大模型(InternLM2)是当前优秀的开源通用大语言模型(LLM),其也提供了7B和20B的InternLM、InternLM-Chat、InternLM-Base、InternLM-Math、InternLM-XComposer供我们调用。
我个人的兴趣点在于大模型的应用,在课程中了解到从模型到应用的一般流程如下(图片来源课程视频):
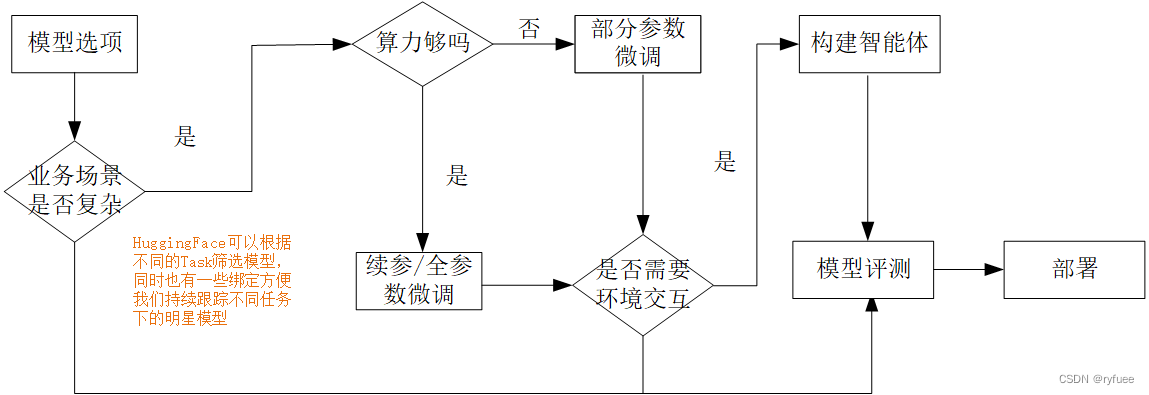
图中,我特别关注了构建智能体模块。大模型聚焦于推理,其在环境的交互能力上功能欠缺,这里的交互指的是:例如,你询问LLM今天的天气并希望LLM根据今天的气温提供出行建议,当前的LLM并不能给出实时的建议。
为了解决实时性交互的问题(即LLM通过推理结果执行Action),智能体(Agent)的概念便被提出了。Agent的核心在于Action的执行,视频中提到了Lagent轻量级智能体框架,这里也简单阅读了一下源码。
在分析Lagent源码之前,可以先看datawhalechina开源的一个仓库: tiny-universe ,其中的TinyAgent项目构建了一个迷你Agent,学习这个项目有助于理解Lagent。TinyAgent遵循React模式,通过:Thought/Action/Action Input/Observation 不断循环迭代的方式交替生成推理轨迹和执行特定任务,使得LLM能够更好的完成实时交互任务。下面给出了项目中Agent.py的源码,可以看到:
- Agent的初始化阶段主要负责加载 ReAct Prompt、加载 LLM Model、加载 tools。
- Agent的text_completion阶段涉及到两次 LLM Model 的调用。第一次是调用 LLM 获取Action需要用到的 plugin_name 以及 plugin_args,而后Agent调用Plugin的call方法得到obsercation并加入到对话中。第二次调用是 LLM 通过前面的得到的对话进一步得到 Tought 和 Final Answer。
TOOL_DESC = """{name_for_model}: Call this tool to interact with the {name_for_human} API. What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters} Format the arguments as a JSON object."""
REACT_PROMPT = """Answer the following questions as best you can. You have access to the following tools:
{tool_descs}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
"""
class Agent:
def __init__(self, path: str = '') -> None:
self.path = path
self.tool = Tools()
self.system_prompt = self.build_system_input()
self.model = InternLM2Chat(path)
def build_system_input(self):
tool_descs, tool_names = [], []
for tool in self.tool.toolConfig:
tool_descs.append(TOOL_DESC.format(**tool))
tool_names.append(tool['name_for_model'])
tool_descs = '\n\n'.join(tool_descs)
tool_names = ','.join(tool_names)
sys_prompt = REACT_PROMPT.format(tool_descs=tool_descs, tool_names=tool_names)
return sys_prompt
def parse_latest_plugin_call(self, text):
plugin_name, plugin_args = '', ''
i = text.rfind('\nAction:')
j = text.rfind('\nAction Input:')
k = text.rfind('\nObservation:')
if 0 <= i < j: # If the text has `Action` and `Action input`,
if k < j: # but does not contain `Observation`,
text = text.rstrip() + '\nObservation:' # Add it back.
k = text.rfind('\nObservation:')
plugin_name = text[i + len('\nAction:') : j].strip()
plugin_args = text[j + len('\nAction Input:') : k].strip()
text = text[:k]
return plugin_name, plugin_args, text
def call_plugin(self, plugin_name, plugin_args):
plugin_args = json5.loads(plugin_args)
if plugin_name == 'google_search':
return '\nObservation:' + self.tool.google_search(**plugin_args)
def text_completion(self, text, history=[]):
text = "\nQuestion:" + text
response, his = self.model.chat(text, history, self.system_prompt)
print(response)
plugin_name, plugin_args, response = self.parse_latest_plugin_call(response)
if plugin_name:
response += self.call_plugin(plugin_name, plugin_args)
response, his = self.model.chat(response, history, self.system_prompt)
return response, his从上述流程可以看出,TinyAgent似乎只能进行一次工具调用,这也让我对Lagent是如何实现Thought/Action/Action Input/Observation的循环迭代产生好奇。直接打开Lagent的开源仓库,从源码目录结构可以看出代码核心是:actions、agents和llms,这里也简单对相关代码进行分析。
1. BaseModel类(llms目录下)
该框架兼容OpenAI API、Transformer、LMDeploy。因此这里先简单分析一下BaseModel类,GPTAPI、HFTransformer、LMDeployPipeline等类都继承了BaseModel,并重写或者补充了一些方法。
class BaseModel:
is_api: bool = False
def __init__(self,
path: str,
tokenizer_only: bool = False,
template_parser: 'LMTemplateParser' = LMTemplateParser,
meta_template: Optional[List[Dict]] = None,
*,
max_new_tokens: int = 512,
top_p: float = 0.8,
top_k: float = 40,
temperature: float = 0.8,
repetition_penalty: float = 1.0,
stop_words: Union[List[str], str] = None):
...
def generate(self, inputs: Union[str, List[str]], **gen_params) -> str:
...
def stream_generate(self, inputs: str, **gen_params) -> List[str]:
...
def chat(self, inputs: Union[List[dict], List[List[dict]]], **gen_params):
...
def generate_from_template(self, inputs: Union[List[dict],
List[List[dict]]],
**gen_params):
...
def stream_chat(self, inputs: List[dict], **gen_params):
...
def tokenize(self, prompts: Union[str, List[str], List[dict],
List[List[dict]]]):
...
def update_gen_params(self, **kwargs):
...2. BaseAction类(actions目录下)
BaseAction定义了所有actions的基类并给出了自定义action的方法。
class BaseAction(metaclass=AutoRegister(TOOL_REGISTRY, ToolMeta)):
"""Base class for all actions.
Args:
description (:class:`Optional[dict]`): The description of the action.
Defaults to ``None``.
parser (:class:`Type[BaseParser]`): The parser class to process the
action's inputs and outputs. Defaults to :class:`JsonParser`.
enable (:class:`bool`): Whether the action is enabled. Defaults to
``True``.
Examples:
* simple tool
.. code-block:: python
class Bold(BaseAction):
'''Make text bold'''
def run(self, text: str):
'''
Args:
text (str): input text
Returns:
str: bold text
'''
return '**' + text + '**'
action = Bold()
* toolkit with multiple APIs
.. code-block:: python
class Calculator(BaseAction):
'''Calculator'''
@tool_api
def add(self, a, b):
'''Add operation
Args:
a (int): augend
b (int): addend
Returns:
int: sum
'''
return a + b
@tool_api
def sub(self, a, b):
'''Subtraction operation
Args:
a (int): minuend
b (int): subtrahend
Returns:
int: difference
'''
return a - b
action = Calculator()
"""
...3. react.py(agents目录下)
ReAct继承自BaseAgent,其流程其实和TinyAgent差不多。为了实现可以不断调用工具并在适当调用次数下得到Final Answer,这里的做法是:
- 做法一:设置一个 max_turn,一旦到达最大次数就输出Final Answer
- 做法二:在Prompt中提到LLM一旦认为可以结束tools调用了就会输出{thought}和{finish}。LLM通过自主判断是否输出"final answer",一旦出现“final answer”,ReActProtocol中的Parse函数便会返回设定 action_return.type == self._action_executor.finish_action.name,于是函数调用停止。
If you already know the answer, or you do not need to use tools,
please using the following format to reply:
```
{thought}the thought process to get the final answer
{finish}final answer
```
CALL_PROTOCOL_EN = """You are a assistant who can utilize external tools.
{tool_description}
To use a tool, please use the following format:
```
{thought}Think what you need to solve, do you need to use tools?
{action}the tool name, should be one of [{action_names}]
{action_input}the input to the action
```
The response after utilizing tools should using the following format:
```
{response}the results after call the tool.
```
If you already know the answer, or you do not need to use tools,
please using the following format to reply:
```
{thought}the thought process to get the final answer
{finish}final answer
```
Begin!"""class ReAct(BaseAgent):
"""An implementation of ReAct (https://arxiv.org/abs/2210.03629)
Args:
llm (BaseModel or BaseAPIModel): a LLM service which can chat
and act as backend.
action_executor (ActionExecutor): an action executor to manage
all actions and their response.
protocol (ReActProtocol): a wrapper to generate prompt and
parse the response from LLM / actions.
max_turn (int): the maximum number of trails for LLM to generate
plans that can be successfully parsed by ReAct protocol.
Defaults to 4.
"""
def __init__(self,
llm: Union[BaseModel, BaseAPIModel],
action_executor: ActionExecutor,
protocol: ReActProtocol = ReActProtocol(),
max_turn: int = 4) -> None:
self.max_turn = max_turn
super().__init__(
llm=llm, action_executor=action_executor, protocol=protocol)
def chat(self, message: Union[str, dict, List[dict]],
**kwargs) -> AgentReturn:
if isinstance(message, str):
inner_history = [dict(role='user', content=message)]
elif isinstance(message, dict):
inner_history = [message]
elif isinstance(message, list):
inner_history = message[:]
else:
raise TypeError(f'unsupported type: {type(message)}')
offset = len(inner_history)
agent_return = AgentReturn()
default_response = 'Sorry that I cannot answer your question.'
for turn in range(self.max_turn):
prompt = self._protocol.format(
chat_history=[],
inner_step=inner_history,
action_executor=self._action_executor,
force_stop=(turn == self.max_turn - 1))
response = self._llm.chat(prompt, **kwargs)
inner_history.append(dict(role='assistant', content=response))
thought, action, action_input = self._protocol.parse(
response, self._action_executor)
action_return: ActionReturn = self._action_executor(
action, action_input)
action_return.thought = thought
agent_return.actions.append(action_return)
if action_return.type == self._action_executor.finish_action.name:
agent_return.response = action_return.format_result()
break
inner_history.append(self._protocol.format_response(action_return))
else:
agent_return.response = default_response
agent_return.inner_steps = inner_history[offset:]
return agent_return总结:第一节课我主要关注了从模型到应用的流程,重点了解了智能体的构建。从tinyAgent开源项目入手,结合Lagent源码简单知悉了ReAct模式下模型调用工具的流程。















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









