







一、大模型成为发展通用人工智能的重要途径
专用模型:从就本世纪初,然后一直到 2021 年、 2022 年,就这一段时间里面,大家的更多的研究会集中在专用模型上,也就是针对特定的任务来采用一个模型解决一个方向问题。
通用大模型:最近两年,大家会越来越往通用大模型的方向去发展,也就是说一个模型来应对多种任务和多种模态,比如说像ChatGPT,它其实就把所有的这种就从文本到文本的各类的任务,其实通过一个模型就可以去解决。
 二、书生浦语大模型的开源历程
二、书生浦语大模型的开源历程
书生浦语大模型其实从去年就 6 月份第一次发布以来,一直在进行快速迭代。在 7 月份的时候就迁移参数的大模型进行了全面的升级,同来支持了 8K 语境,有 26 种语言。同时推出了就可以就全免费商用的 7B 的 KR 模型和全链条的工具体系。
那到 8 月份发布了书生万卷 1.0 这样的多模态的预训练语料库,然后续又发布了升级版的对话模型来,并且开源了智能体的框架来去支持interIM,它从语言模型到智能体的一个升级转换。那进一步的我们发布了就 123 B 的这种千亿参数的模型,然后到 9 月份又发布了就中等尺寸 10B 的开源模型,并且升级了整个的开源工具链。
那今年1月 17 号 interIM2 是正式的开源,那相比于第一代模型,interIM2 有了非常大的一个提升,也能够去解决更多的一些这种真实的一些问题和复杂的一些场景。

书生浦语2.0,它其实面向不同的使用需求,我们有不同尺寸的模糊性,以及说有不同类型的模型,那我们提供了 7B 这样的一个轻量级的模型,它其实可以为,比如说轻量级的研究和应用来去有一个就相对而言比较便宜并且性能也还过得去也还不错的模型,那同时的话我们也有了 20 B 这样的一个综合性能更强,能够去支持更加复杂的一些这种实际的场景。这样的一个中量级的模型。
那对于每一个尺寸的模型,其实我们都包含了interIM2 BASE、 interIM2 还有 interIM2 CHAT 这样的不同的三个模型,就其中 interIM2 BASE 它其实是这种高质量的、具有很强可塑性的一个模型基座,那在它的基础之上,我们在多个能力方向上去进行了强化,那可以取得非常不错的一些评测成绩和通用的语言能力,这就是我们 interIM 的模型,我们也推荐大家其实可以基于 interIM这样的一个模型去做下一步下游进一步的微调。那与此同时我们也有 interIM CHAT 这样的一个在 base 模型上的基础之上来去经过 SFT 和 RLHF 来去面向对话交互进行优化的模型,那 interIM CHAT 其实它是一个具有很好的指令遵循共情聊天和调用工具这样的一些能力的模型,所以的话我们把这所有的模型都面向社区去做了,开源用户也可以根据自己的实际场景和需求来去选用。
三、INTERIM2体系及亮点

那 INTERIM2 的话,我们到底做了一些什么事情?就 INTERIM2 其实我们最主要的一个初心其实就是回归语言建模的本质啊。我们都知道大模型它本质上其实是在做语言建模这件事情,也就是说我们能够通过给定的context,然后去预测接下来的token。那这里面的话其实最关键的就是我们要去有相就高质量的这种语料,然后让模型能够去学会就更好的这种建模能力。
那我们通过新一代的数据清洗过滤技术,那里面包括了像多维度的数据价值评估,我们基于不同的一些这种像文本质量、信息密度这样的不同的维度来去对数据价值进行了一个综合的评估和提升。那同时我们也通过高质量的语料驱动的这种数据复集的方式来从互联网上以及说语料库里面去进一步的复集更多的类似的语料。同时我们也针对性地去做了一些信数据的补齐来去加强包括模型在世界知识、数理代码等等核心能力上面的就存在的一些差异。
那下面左边这张图其实是说初代的就 interIM1 和 interIM2,它们在大规模的这种高质量验证语料上面 loss 分布我们可以看到就 interIM2的这种基座模型,它整体的这种分布其实是就往相当于是说在左移,其实这个也是说明了它确实语言建模的能力是比初代要强很多的。
那右边的话其实也有一个更直观的对比,就是说我们随着训练数据的升级,就每一代训练数据的升级,下游任务的性能其实也在不断地去进行提升。我们可以采用更少的语料就能够达到和上一代这种数据或者上一代语料相同的效果。或者是说我们随着语料提升,整体的下游任务性能是在不断增强。

书生浦语2.0 它其实有这样几个主要亮点,首先第一个是具备超长的上下文的能力,在 1 月份发布的时候,我们就已经支持了 20 万 token 上面的一个长度也就200K。它可以实现比较完美的大海捞针的测试,并且它的综合性能也得到了全面提升,包括像推理、数学代码等等。它我们在 20 B 的模型在重点的评测上面是可以比肩 ChatGPT 的。那我们也有着非常优秀的对话和创作体验,像指令遵循的能力,然后结构化创作能力都是非常不错。
再像 APAC Eval 2 还上面是超过了 GPT 3.5 和 Gemini Pro,并且工具调用的能力也得到了整体的升级,可以去做可靠的支持工具的多轮调用,能够去搭建复杂的智能体,那同时的话也有很突出的数理能力和使用的数据分析的功能,我们模型是强化了它的内生计算能力,也就是说它不借助任何的外部工具或者计算器的情况下,也能够有着比较准确的一个计算的能力。
那通过加入代码解释器,我们在像 GSM 8K 和 mass 这种数学的评测集上就可以达到和 GPT 4 相仿的水平。当然这只是一个 20 B 的模型。

那这边的话是对它的一个性能有一个简单的一个阐述。我们可以看到就在各个能力维度这边,比如说像考试语言知识推理、数学代码,其实它都是有多个数据集,多个开源数据集的一个综合性的一个评测结果。那我们总共是测了四五十个这种 care 的数据集,然后根据这些维度去算的一个平均分,我们可以看到在像推理、数学代码等等方面, intermal 的提升其实是非常大的,综合的性能也达到了同量级的开源模型的领先水平。在一些重点能力评测上面,像我们 20 B 的模型其实就已经可以比肩就 GP 3.5

那这边的话会给大家一些简单的例子,比如说,嗯,就我们模型可以扮演一个就贴心可靠的这种 AI 助手,让它去规划一下,安排一下三天的行程。我们可以看到模型整体写出来的这样的一个规划都还是比较就比较丰富,并且也比较符合实际的一个情况。

那同,除了比如说去作为这种助手之外,模型其实还可以去给出这种非常充满人文关怀的对话啊。就我们可以看到很多的一些模型,其实它有着非常强的这种回复的一些风格。比如说它会就进行就列举,比如说首先,其次最后或者 123 等等,它会容易去列一些列表。那当我们的模型在遇到这种情感相关的问题的时候,它其实就我们可以看到它回复里面是充满了人文关怀。

同时它也可以去进行一些有想象力的创作,比如说我们让它去就写一个流浪地球 3 的一个剧本,我们要求它的内容是跟前两步的是相关的。那我们可以看到模型,也可以去比如说写出接下来的一些剧情的创作,那这个对于模型的一个想象力是有着比较大的挑战。

同时我们也升级了 interIM2 的工具调用能力,那这边比如说也举一个例子,像我们可以告诉模型接下来要去参加,要去参会,然后希望模型去做一些包括路线规划,然后一些这种就餐厅查询,然后并且做一些邮件发送的任务。对,我们可以看到模型它是可以通过不同的这种工具的组合调用,然后来去完成这样的一个比较复杂的任务。

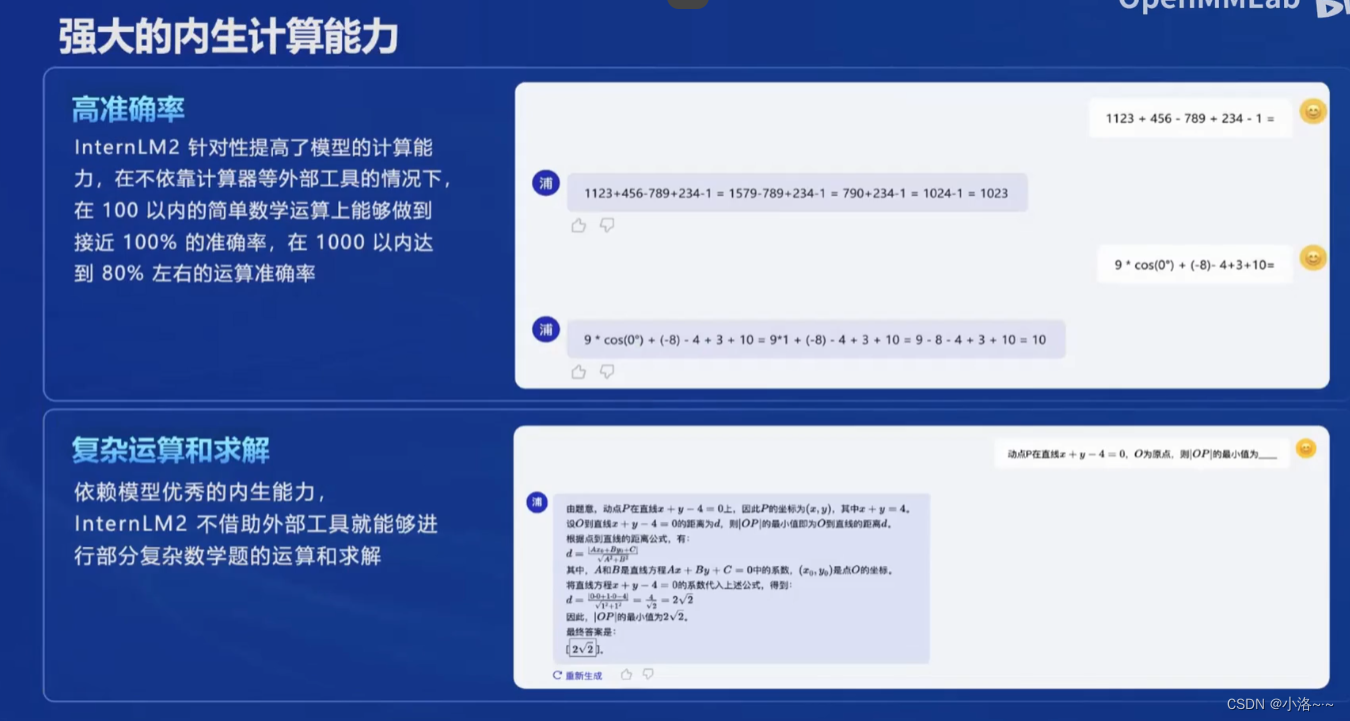
interIM2,它其实在这种计算能力上也有着很大的一个增强。比如说这边我们去就问了一些四则运算,或者说一些简单数学计算的这样的一个例子,并且它可能都是这种多步的一个计算,我们可以看到模型对于这样的一个一些计算都能够答得回答得比较准确,比如说 100 以内的这种数学运算,基本上是能够做到 100% 的准确率,然后 1 000 以内的也可以达到 80% 左右的一个运算准确率,并且它也可以去做一些比较复杂这种数学题的运算和求解。比如说这边它可能有一些这种像高中的一些题目,以及说,以及是说像一些就大学的,比如说像微积分之类的一些题目,其实我们在测试过程中发现它也能够做对不少。
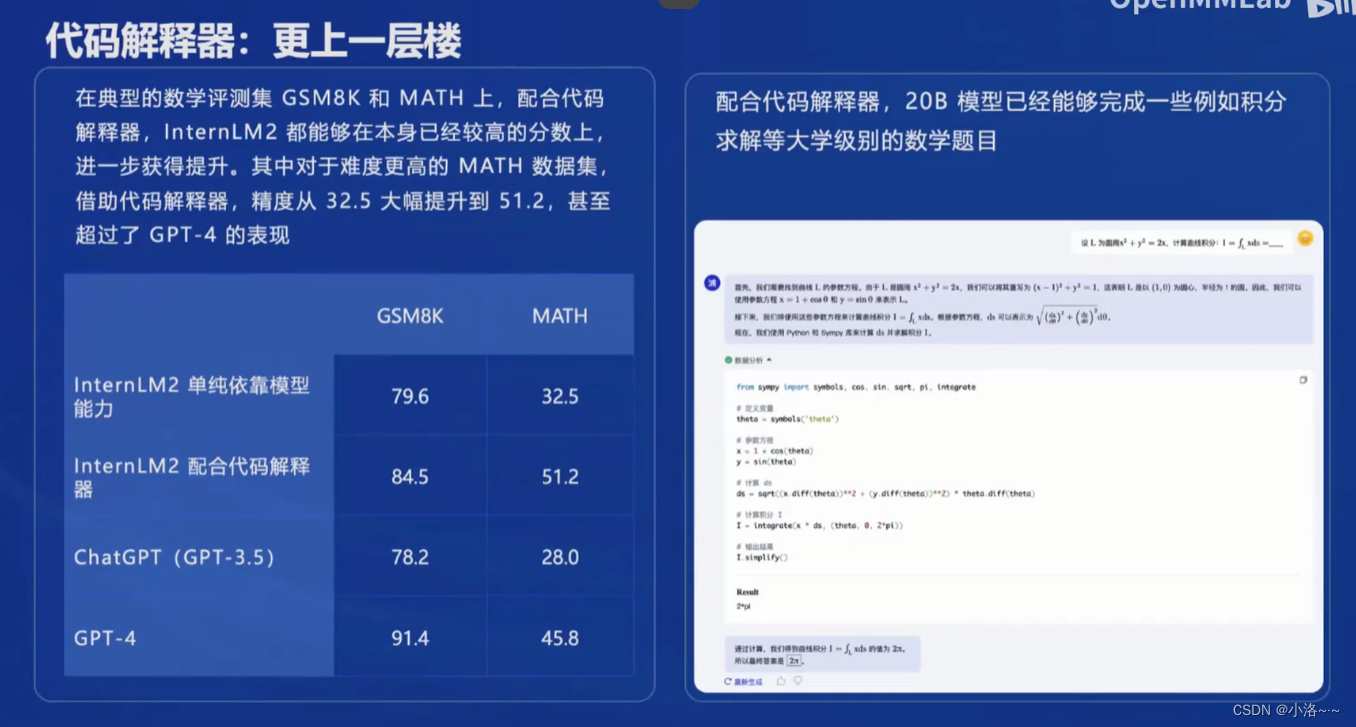
那刚才其实都是模型内生的这种计算能力,或者说数学能力,那我们也知道大模型它的计算能力在有的时候可能不太可靠。那借助这种比如说代码解释器,我们就可以在就进一步的来去提升它的数学的一个成绩。比如说JS、 N8K 和 mass 都是目前比较就使用比较广泛的两个数学的测试集,我们可以看到 INTERIM2 单纯依靠模型的能力,它就已经能够获得很高的分数,当它配合代码解释器之后,其实就能够有进一步的这种大幅的提高,比如说像mass,它从 32.5 提升到了51.2,甚至是说能够超过 GPT4 的表现。
那比如说像右边我们给了一道这种微积分的例子,那我们来去问模型,然后模型首先会进行一些分析,然后接下来可能就通过这种撰写代码,然后去执行代码,得到最终的一个结果。
同时的话模型也有一些比较实用的这种数据分析的功能,比如说我们可以去上传一张表格,然后让模型去帮忙。嗯,就看一下表格文件,那模型可能通过一些这种代码的撰写,然后去把这种表格就读进来,然后去做一个简单的一个就概述。那接下来的话可能我们会要求模型去结合表格里面数据来去画一些,比如说行业的发展趋势图。我们可以看到模型就可以通过这种,比如说去写代码,使用 mathplotlib,然后去画出这样的一些折线图。那进一步的我们还可以要求,比如说模型去使用一些机器学习的算法。

四、书生浦语的模型:从模型到应用
那刚才已经介绍了,就 INTERIM2 整体的一个就情况,以及说相比于商业带有模型的一些提升,那从模型到应用,比如说从我们有书生浦语的模型,那我们希望去就去构建,像比如说智能客服或者说个人助手,以及说各种各样行业应用。那这个过程其实它也不是那么直接,或者说它其实需要经历过很多的经历很多的一些这种环节。

那具体这里面存在什么样的一些gap我们可以做一个简单的分析,那从模型到最终的一个应用,它可能有一个,比如说这边列了一个比较典型的流程
那首先第一个我们可能就需要去做模型的一个选型。那模型选型的过程可能是一个就模型评测的过程,我们可能去看一下就现在社区的各个不同的开源模型,它们在一些经典的评测集上,或者说在一些这种大规模的榜单上整体的一个效果,然后我们可能去选其中一个,或者说选其中几个来去在业务场景里面去考虑.
那选初步选好模型之后,我们就会去考虑业务场景是否复杂,如果业务场景比如说是比较复杂业务场景,我们就可能去需要去对模型进行微调。
那模型微调的话我们需要进一步去考虑我们目前的算力它是否足够,如果是,比如说有充足的算力,我们就可以去进行模型的这种训或者全参数的微调,如果算力非常有限,可能只能去进行部分参数的微调,比如说像 Lora。
那微调出来模型之后,那可能它就具备一些业务场景的相关的一些知识,我们可能需要去评估模型是否需要和环境去做交互,也就是说在我们业务系统里面或者说实际应用里面是否有这种外部的一些,就 API 或者说外部的一些工具需要模型去做交互。
如果需要的话,我们需要去进一步构建智能体。如果不需要,那就可以就直接去考虑测试模型性能,那接下来肯定在上线之前,我们就会去进行模型评测,在实际的场景里面,或者说我们实际的这种就预期的一些领域里面,然后对它做进一步的评测。
如果能够通过评测,那接下来就是模型的一个部署和上线,那我们可以看到就从模型然后到应用,它需要经过很多的一些步骤,那这里面可能每一步又会需要,比如说一些这种大量的这种代码的开发,或者是说去选择各种不同的工具,然后去完成里面每个环节的事情。

五、书生浦语全链条开源开放体系
开发了书生浦语的这种就全链条的工具体系,并且把它都面向社区做了开源。
分成包括从数据、预训练、微调、部署、评测到应用,其实多个环节基本上都完成了一个全覆盖
- 数据:书生万卷,开源的数据集
- 预训练:interLM-train
- 微微调:xTuner
- 部署: LM deploy
- 评测:openCompass
- 智能体的应用:legent、 agentLego ,包括智能体的框架和智能体的工具箱

开源工具体系介绍:数据方面
那接下来对于我们的一些开源工具体系做一个简单的介绍,那首先是数据方面,首先是去年已经发布了书生万卷 1.0 这样的一个多模态的数据集,它总数据量其实达到了两个TB,并且它都是符合主流的中国价值宏观的一些中文语料,里面包括有文本式数据、有图像文本的数据,有视频数据。他们其实经过了非常精细化的处理,就依赖实验室这边在整个大模型研发过程当中积累的关于数据的一些理解和经验。
那在前不久又发布了书生万卷CC,就这样的一个就开源的数据集,它其实包括了从 2013 年到 2023 年的互联网的公开内容。它其实是基于 CC 这样的一个数据集做了非常精细的一些清洗,那同时的话它也来源是非常丰富多样的,并且在一些这种安全信息,就像一些就安全上面也做了比较多的一些处理,那通过这样的一些数据集其实是支持了整个 interm 的迭代工作,那么我们也将其中的就很多的一些,就一些数据的成果来开源出来,大家都可以在open datalab 这样的实验室的数据平台上来去获取到。包括这边开源的数据集,以及说还有很多其他的一些社区的开源数据集。

开源工具体系介绍:预训练方面
那在预训练的层面我们也开,就相当于开发了 interevil 这样的一个预训练的框架,其实它具备这种高可扩展性,其支持了从 8 卡到千卡级的一个训练,并且在铅卡的级别上面加速效率达到了92%,是远远超过了。比如说一些竞品,就竞品的框架,同时的话通过实验室这边的一些优化技术来能够去实现性能的一个技术优化来达到 50% 的加速,同时也能够去兼容主流的一些技术生态,比如说像 hugging face 的模型和各种轻量化的技术,并且也能够开箱即用,也支持了多种不同规格的语言模型,只需要修改配置就可以去进行模型的预训练。

开源工具体系介绍:微调方面
在微调方面的话,我们其实就开发了xTuner这样的一个微调的框架。
增量预训和有监督的微调是经常会用到两种方式,增量预训。其实就我们通过以这种类似预训练的方式来去让模型学到一些新的知识,比如某个垂类领域的知识。那这边的训练数据可能是,比如说像书籍、文章代码等等,那有监督的微调主要是让模型学会理解各种指令来去进行对话。或者我们也可以通过有 Generator 方式去注入少量的领域知识,那这边的训练数据通常来讲是高质量的这种对话或者问答的数据。
那有监督微调里面,其实它又会分为就这种全量参数的微调,也就是说我们所模型所有的参数都是放开训练的,也有这种部分参数的微调,比如说这边是一张 Lora 的图,就 Lora 的一个示意图,我们会去就相当于固定模型的就绝大部分参数,然后通过放开或者引入少量的参数,然后这样能够去降低整体的一个微调的成本。

那这边我们有高效微调框架Extruner,它能够去适配不同的各种各样生态,比如说不同的一些微调策略和算法,能够去覆盖各类的 SFD 的场景,同时的话它也能够去适配不同的一些开源生态,比如说加载 hugging face 的模型, Model Scope 的一些模型,或者说数据集。同时里面也会去做自动的优化加速,让开发者可以不用去关注这些复杂的一些浅存优化和计算加速的细节,可以把更多的一些精力来去投入到比如说数据的一些准备和优化上面。
同时的话 external 也能够去适配不同的硬件能够覆盖,比如说像 Nvidia 20 系列以上的所有显卡,也就是说它可以在很多的一些消费卡上能够去跑起来。那通过这种一些量化的方式,它最低其实只需要 8G 的显存就可以去微调 7B 的模型。

开源工具体系介绍:评测方面
那接下来还是评测的这样的一个环节,评测其实也是实验室持续在投入力量来去做的事情啊。从去年的整体 5 月份开始,其实就陆陆续续都有这种评测框架的一个开发和开源,那在今年的 1 月份也正式发布了 open Compass 2.0 思南大模型评测体系,那这也是 open Compass 就整体的评测体系的一个就重大的升级。

它里面包括有三个部分。
首先第一个是 Compass rank,我们会提供一个这种中立全面的性能榜单,就包括就大语言模型的这种榜单,包括多模态模型评测的榜单,那基本上就主流的模型大家应该都可以在这个榜单上面来看到,我们也会定期地去发布相关的一些更新,

以及说还有 Compass Kit 就大模型的评测的全栈的工具链,我们会把就评测所依赖的各种相关的工具其实都在 Opencompass 这样的一个 GitHub organization 里面去做一个开源。
那里面会包括就除了各个数据集的兼容,目前里面应该已经支持了超过 100 个数据集的评测。对,那它包括也有很丰富的这种模型推理的接入,然后也包括像数据污染检查的一些功能,长文本能力评测以及是说中英文双语的一些主观评测,能够去覆盖就多个维度、多种需求的这种评测。
 同时的话我们也建立了 Compass Hub 这样的一个高质量评测基准的一个社区,我们是希望以开源、开放、共建、共享的方式来去构建大模型的评测基准,或者说评测集的社区,来去让更多的一些研究者和开发者参与到大模型的评测中,来来去把各种优秀的这种评测集能够在社区去进行汇聚,同时也提供而更好的一些这种支撑的服务。
同时的话我们也建立了 Compass Hub 这样的一个高质量评测基准的一个社区,我们是希望以开源、开放、共建、共享的方式来去构建大模型的评测基准,或者说评测集的社区,来去让更多的一些研究者和开发者参与到大模型的评测中,来来去把各种优秀的这种评测集能够在社区去进行汇聚,同时也提供而更好的一些这种支撑的服务。

那 open Compass 的话,其实它现在已经有非常广泛的应用,很多的一些大模型的这种头部的企业或者说研究机构,他们在发布大模模型的时候都会用 open Compass 来去进行评测。那同时的话它也是获得 Meta 官方推荐的唯一的一个国产大模型的评测体系,目前也是社区支持最完善的评测体系之一,应该已经适配了超过 100 个评测集, 50 多万道题目,并且就整个的一套评测工具和评,包括评测的一些 prompt 其实都是开源的。

那我们从就整体的 open Compass 2.0,我们自己构建的一些评测集里面也可以发现一些趋势,我们对主流的一些模型都做了一些评测的分析,当然的话我们不用不太需要去关注具体这边每一个模型它的一个性能,因为我们更多的是希望去给社区提供一些这种关于模型整体的发展的一些趋势的了解啊。

那首先第一个这边是我们有一个综合性的客观评测,也就是说在我们自己构造的客观样的评测集上来去进行就结果的评测,这边会从语言知识推理、数学代码、智能体这多个方面来去进行评测,就左边最高的是 GPT 4,那我们也可以看到其实整体能力大家是有比较大的提升空间的,因为在 open Compass 2.0 里面,我们采用了更加准确的这种循环评测的策略,之前的很多评测集其实是采用这种选择题的模式,比如说ABCD。然后让模型去选择,那这样的话模型其实有一些这种猜测的因素,或者说一些随机,就随机的因素在那在 open Compass 2.0 里面我们采用了循环品评测的策略,也就是说我们会把选项去进行一个这种轮换啊。也模型只有在能够打对所有这种轮换的方式的时候,我们才认为模型这道题是对的,那这样的话其实就能够获得更加准确的一个性能。那我们发现就哪怕是 GPT 4在这样的一个百分制的评测基准里面也只是达到了 61.8 分的一个大概及格的水平,所以大模型的整体能力还是有比较大提升空间。
那我们也可以看到复杂推理其实现在仍然是短板,国内的很多的模型综合能力其实在接近 GPT 4,因为我们考察的维度是多种多样的哦。我们也没有是说把所有都是很难的题目,那会考虑到一些平均的分布,所以就这样综合性看下来的话,有些模型其实是在接近 GPT 4 Turbo 的水平,但是在一些比较复杂的推理上仍然存在比较大的差距,并且和模型的尺寸也存在比较强的相关性,也就是说我们拿这种相对比较平均的这种考题来去区分模型,可能它们的分差并不大。但如果是一些比较复杂的推理场景,那有可能差距就显现得非常大。
同时我们也发现就这种偏理科能力的一些分数和模型的尺寸也有比较强的一个关联性,比如说像语言和知识这样的一类文,偏文科的维度上中轻量级的模型和这种重量级或者说闭源的商业模型差距比较小。但是在比如说像数学推理代码这样的一些偏理科的维度上,性能和尺寸就呈现比较强的相关性。
同时的话我们也通过这种主客观的评测,其实也发现有些模型可能在主观和客观的性能上存在比较大偏差,所以社区不仅是需要去夯实这种客观评测的能力基础,也需要在一些对话体验上来去下功夫。

那这边的话其实就是主观评测的一个胜率,我们是让,就对,比如说每个不同的模型和 GPT 4 的一个这种综合的一个胜率,那 GP 4 的胜率就有50%,那我们也可以看到 GP 4 在主观评测里面仍然现在是占据着第一的位置啊。那我们也可以看到,就国内近期发布的部分的大模型,其实表现也是非常优异的,多个维度上缩小了和 GPT stop 的一些差距。并且国内的模型在中文场景下是具有性能优势。再比如说像中文的语言理解、中文知识,还有中文的创作上,国内的商业模型相比于 GPT 4 Turbo 其实是具有很强的竞争能力的,甚至有些少数模型它在单个维度上甚至能够去完成对 GPT 4 Turbo 的超越。
那我们也可以看到开源社区其实也是有非常好的一个发展趋势。比如说像 E34B Chat,然后 internLM2 chat 20B,它们其实都是这种中轻量级的尺寸,那在这整个评测里面就已经展现出非常优秀的综合性能,能够去接近这种商业 BI 模型的性能,所以我们能够从这样的一些评测榜单里面可以去发现在整体的一些发展趋势,以及说对我们未来,比如说开源模型的一些选型能够去进行一些指导。

开源工具体系介绍:部署方面
那另外的话,我们还有就在整个全链条开源开放体系里面还有一个部署环节,那这边的话我们其实开发了LMdeploy 这样的一个大模型的全流程的部署的解决方案,那也包括像模型的轻量化推理和服务等等。模型部署通常来讲是模型上线应用里面的最后一环,那怎么样去把模型能够去就在 GPU 上更快地跑起来,然后去得到更极致的性能、显存等等的一些优化。
那这里面 LMdeploy 其实做了非常多的一些工作。那它里面支持了包括模型的轻量化,比如说 4 比特权重的量化,然后 8 比特 KV cache 的量化,然后也知我们也开发了不同的推理引擎,比如说像 top one mind,或者说基于 Pytorch 的推理引擎啊。同时的话我们也就开发了这样的一些服务的模块,比如说能够去兼容 OpenAI 的这种 Server 的接口。
然后也有 Gradio 的一些这种这个 word Demo 就各种各样的一些,比如说它需要去部署上线所依赖的一些这种功能或者feature,很多在LMdeploy 里面都可以找到。那同时我们也提供了不同的一些访问接口,比如说像直接的 Python 接口,或者说像这种 restful 的接口和 GRPC 的接口,那这里面的话我们其实就在进行了一些高效的推理引擎的优化,比如说有这种持续批处理的一些技巧,然后也有一些深度优化这种低比特计算的一些Carnal。
那还有就是说关于模型并行的一些优化和这种 KV cache 的一些管理的机制,那就 LMdeploy 它其实也是一个就比较完备的一个工具链,它能够去完成从量化到推理到服务这样的一个全流程,也可以无缝地对接 open Compass 来去评测推理的精度。那实验室内部现在也是会使用 LMdeploy 和 open a Paas 去做这种评测的一个加速啊。我们也可以去这边也有多维度的评测的工具。
同时的话LMdeploy 也支持这种交互式的推理。比如说类似于我们就跟类似于 UI 上面我们可能问一句答一句这种,那也支持,比如说这种非交互式的,我们把整个对话历史都发给模型。

那这里的话是 LMdeploy 和 VIM 这样的一个社区非常流行的推理框架,它的一个性能的对比我们可以看到在 A100 上 LMdeploy 它的一个推理效率是要在不同的模型尺寸上其实都是优于 VIM 的,那这个这样的话其实也能够为我们的线上服务留,就相当于预留更多的一个容量,然后也能够让我们的一些这种推荐的响应能够更快啊。

开源工具体系介绍:智能体方面
那最后也介绍一下我们智能体的框架,比如说这边我们开发了一个轻量级的智能体框架lagent,那它支能够去支持多种的智能体的能力啊。比如说像 react 的一些,还有remove,还有 autoGPT 这样的,不同的一些这种智能体的一些pipeline,比如说我们从输入,然后接下来怎么去选择和执行工具,以及说是否有计划拆分等等。
那这样不同的一些智能体的流程,其实都是在里面可以去一键支持,以及说可以去开发新的流程,并且也可以去灵活地支持各种大语言模型,包括一些这种大模型的API,像 GPT 3.5 和 GPT 4。那也支持,比如说一些 care 模型,像 hugging face 里面的模型,还有interIM的模型,它也能够有很多的一些内置的工具可以去直接使用。

举两个例子,就一个是通过 lagent这样的一个框架,我们就可以让模型去实现,比如说代码,刚才提到的代码简数学题的能力。
以及是说这边还有一个多模态 AI 工具的使用,我们可以做到零样本的一个泛化,那这样的话其实这个 Demo 也是基于legent,我们可以去搭建那智能体的框架,其实就给我们如何去使用和进一步地去开发大模型,就留下了很多的一些这种可能性。

那刚才其实 legent是这种智能体的整体的一个框架,那除此之外我们还开发了多模体、多模态智能体的一个工具箱,其实它主要是一个比较丰富的工具集合,尤其是它提供了大量的这种跟视觉多模态相关的领域的一些前沿的算法功能,比如说就 openlab 是目前计算机视觉领域应该是最大或者说最全的一个模型库,那我们其实也把 Openlab 里面的很多的典型的算法。或者说高性能的算法其实在这里面去做了封装。那我们除了除此之外,还包括像 stable diffusion,然后像一些语音的模型,包括像这种 Sam 这一类分割的模型,在 agent level 里面其实都做了支持。
所以的话当我们想要去把就语言模型去拓展到一个这种多模态职能体的时候,我们可以借助 agent ECO 这样的一个就工具箱来去完成整体的一个这种智能体的一个就工具集,然后大家就可以 focus 在智能体本身的一些开发上。那 agent Lego 的话,它其实能够去兼容agent,也可以去兼容,比如说像 long chain 和 Transformer agents,就其他的一些这种 agent 框架啊。所以的话我们其实是把智,就智能体的工具箱和智能体本身,框架就框架本身是也是做了一定的解耦。

最后回顾一下,就是说书生浦语的全链条开源开放体系,包括了从数据到预训练到微调到部署到评测到应用这样的不同的一些环节,就整体大家从需要去基于大模型,然后去做这样的各种各样的一些应用开发和一些微调实现,基本上都可以在 internLM 开源的工具链里面去找到相应的工具。
 希望以这种高质量的开源来去赋能整体的一个创新。
希望以这种高质量的开源来去赋能整体的一个创新。
















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









