






一点点碎碎念
这篇博客是我阅读多篇论文后写的一个总结,其中提到的相关工作和算法我没有细究其实现原理,只是大致知道它的运用,希望可以给刚入门的小伙伴做个参考。
总结写作逻辑与论文综述比较类似,语言不算特别通俗,写作结构或许可以帮助才开始看论文的小伙伴快速适应。
文章写作结构
- 概念(引入)
- 引入连续学习
- 生命智能体的角度
- 深度学习角度
- 传统连续学习的局限
- 概念比较
- 连续学习
- 在线学习
- 迁移学习
- 多任务学习
- 引入连续学习
- 介绍(对背景的扩展,对概念的详细阐述)
- 背景
- 基于深度学习
- 基于人脑神经系统
- 当前深度学习发展情况--为什么需要连续学习
- 连续学习方法为什么受到广泛关注
- 连续学习的拓展——图数据
- 传统连续学习和图连续学习
- 背景
- 连续学习研究现状
- 传统连续学习
- 重播方法
- 正则化方法
- 参数隔离方法
- 图连续学习
- 基于回放
- 基于正则化
- 基于结构
- 传统连续学习
- 问题与展望
- 问题
- 连续学习研究焦点问题
- 图连续学习研究问题
- 展望
- 连续学习的运用
- 与神经科学的结合
- 问题
正片开始
1 概念
1.1 定义
对于生命智能体(想想人的学习过程),知识技能的学习是一个终身的过程,虽然存在对以往知识的遗忘行为,但学习新知识时,对旧知识几乎不会产生灾难性遗忘。对于深度学习系统(神经网络不就是受人脑神经元的启发吗),连续学习[1]研究如何从无限数据流中学习,逐步扩展所获得的知识,并将其用于解决新的问题,也就是说模型学习效果可以自适应动态数据流,在适应新知识的同时,不会灾难性的忘记(在处理旧数据上效果非常差)以前学习的知识。连续学习是一种能长期不断获取,调整,适应和转移知识的能力,因此常常也称为终身学习和增量学习。
传统连续学习主要处理欧式数据(结构规则的数据),例如文本、音频、图像、视频等。但在非欧式数据中,例如图(不是图像,是数据结构学的图,图论里的图)和流形数据,数据结构不规则,数据动态增长的不确定性加强,不规则的结构导致传统连续学习不能直接用于连续演化的图数据上,因此出现不少针对图的连续学习研究,图连续学习也就是图数据在连续学习上的运用,本质上和连续学习解决的问题相一致,即灾难性遗忘。
1.2 概念比较
连续学习与迁移学习,多任务学习和在线学习研究重点并不相同,不能混为一谈。
| 分类 | 阐述 |
|---|---|
| 迁移学习[2] | 重点在迁移,也就是在任务一学习到的知识可以很好的运用在任务二上,更注重迁移后解决任务二的效果,对原任务一的表现并不重视。 |
| 连续学习同样重视新任务和旧任务的学习效果。 | |
| 多任务学习[3] | 即把多个相关的任务放在一起学习。例如短视频推荐系统,观看时长,点赞,评论,转发情况来综合判断该视频是否符合观看者的喜好。 多任务学习是在同一时间上获取所有任务。 |
| 连续学习过程中任务是一个一个出现的。 | |
| 在线学习[4] | 重点是在线,虽然在线学习的过程中任务也是序列进行,但具有时效性,更强调实时性。通常要求每个样本只能使用一次,且数据都是来自于同一个任务。 |
| 但连续学习是多任务的,且样本数据在内存允许的情况下保存下来,会被多次处理的,类似人脑复习的过程。 |
大多数的研究都将连续学习,终身学习和增量学习的概念等同起来,但Masana M[5]等人比较了这三个概念的不同。终身学习应当看作一个完备的系统,即构建能够在整个生命周期中学习的智能系统,连续学习是终身学习系统中的一个特征。连续学习和增量学习的界限非常模糊,他们的主要目的都是在任务逐步增长的情况下解决灾难性遗忘问题,追求稳定性和可塑性的平衡,但增量学习更多的是强调一种方法,即在训练中保留部分过去的经验,而不是每次更新都从头开始重新训练。
2 介绍
深度学习和人工智能的发展,本质上都是对人脑神经元结构的学习和建模。人脑拥有超强的适应能力,可以有效的获取知识技能,并在新经验的基础上完善发展,同时可以在多个领域迁移使用。虽然人脑会逐渐遗忘以前学习的知识和经验,但不会有灾难性遗忘。这是因为大脑的终身学习有一套非常丰富的神经生理学原理,神经突触可塑性(神经科学的知识啦)是大脑的一个基本特征,它会产生神经结构的物理变化,帮助我们学习,记忆和适应动态环境[6]。因此,基于对人脑的学习和模仿,人工智能需要实现类脑的终身学习的能力,可以在连续的数据流上逐步积累知识,以支持未来的学习,同时保持先前消化的信息。
近年来机器学习,深度学习模型在许多任务处理中表现良好,甚至超过人类水平,例如围棋游戏,目标检测等等,但这些研究聚焦于静态模型,无法适应数据随时间动态变化的行为[1]。例如人类活动识别任务[7],人类行为复杂多变,难以枚举所有的行为情况,同时新活动类别的识别通常是通过顺序数据( 例如视频、传感器观察 )进行的,在机器学习中训练动态增长的数据会导致新模型对旧模型的覆盖,从而导致旧数据训练效果变差而带来灾难性遗忘。连续学习为人工智能的动态连续学习提供了合适的方法。
(转念一想,解决新模型对旧模型的覆盖,也就是灾难性遗忘,最直接有效的方法,把新数据和旧数据一起重新训练嘛。)
(也不是不行,但……接着往下看)
2.1 连续学习方法的社会关注
连续学习方法越来越受到广泛的关注,主要体现在社会需求和深度学习发展要求[8]两个方面。
社会需求:
- 1. 物理内存有限,不可能保存所学的全部知识。例如机器人,默认的功能设置可以应对部分常见问题,但实际任务中将面临各种不同场景和突发小概率事件,需要不断更新默认设置和知识储备,但有限的内存决定机器人系统不可能记住每个场景的细节。
- 2. 隐私政策,即保护数据的隐私性。例如在医疗系统中,法律限制不能长期存储一个病患的数据。
- 3. 可持续发展要求,每次新任务到达则重头开始训练的耗能是极大的[5]。
对深度学习的要求:
- 1. 深度学习强烈依赖于数据:深度学习模型倾向于适应最近的数据,从而“灾难性地”遗忘旧知识信息。
- 2. 连续学习可以减少深度学习模型的训练时间。
2.2 连续学习的拓展-图数据
随着人工智能技术的发展,图像,语言,文字等各种各样的信息都应用与深度学习处理中。不同的数据形式需要不同的处理环境,例如图像数据,在训练过程中图像的大小,颜色通道是不变的。如文本数据,文本,词条的长度是可变的,但结构是规则的。然而,图数据具有不规则的结构,这导致了传统的连续学习无法运用在图数据上。
(主要不规则体现在图的邻居数是不固定的,你看图像:长方形,像素节点上下左右的连接,最多就是边缘部分只有3个邻居)
(但图的邻居不规则哇,下图举个例子,节点直接的邻居数不一样)
图结构数据在连续学习中的运用非常广泛[9]:
药物分子结构预测,生物分子之间的相互作用可以构建成图结构,节点表示生物分子,边表示相互作用关系。图网络捕捉生物分子的动态变化,对研究疾病的发病机制和药物作用机制有重大帮助。
金融风险管理:金融产品作为节点,用户对产品的评分或购买行为作为边。图网络可以捕捉金融市场的动态变化,预测风险,优化投资策略。
社会网络分析:在社交网络中,节点代表用户,边代表网络关系。图网络可以捕获网络关系变化,分析用户及其邻接节点,预测用户社交,分析用户行为,给用户推荐他感兴趣的内容。
推荐系统:用户和物品作为节点,用户和物品的关系代表边,边可以体现为用户对该物品的查阅和购买行为,图网络可以动态捕获用户的行为,以提高推荐系统的准确性。
交通预测:路口作为节点,道路代表连接的边,道路的长度,流量等信息构成边的属性,交通网络可以捕获道路流量情况,预测未来交通流量,优化交通的管理和规划。
2.3 传统连续学习和图连续学习
传统机器学习模型捕获静态数据分布(训练过程中数据不会改变,比如数据的数量,数据的种类不变)为前提,而连续学习是从动态的数据分布中学习经验知识,这必然会带来稳定性和可塑性矛盾。最直接的方法就是每当新任务来临时,都从头重新开始训练模型,但该方法面临内存容量限制,计算复杂度限制,资源消耗限制和数据安全、隐私问题限制。传统连续学习的方法主要是正则化,重播,参数隔离和循环神经网络相结合四方面,将在第三节相关研究中详细讨论。
但传统的连续学习的数据集中在欧几里得空间中,数据有顺序明确,且结构规则[9]。图数据没有唯一的结构或规范的向量表示,这使得一般的连续学习方法不能直接推广到图数据中。图表示学习作为一种规范框架,通过捕获节点、边和子图的结构并将它们转为低维向量来解决不规范的图结构问题,但该方法更多用于处理静态数据,没有考虑动态数据的增长。虽然一些调查考虑了图的动态性质,如动态图学习[10],常分为离散时间动态图( DTDG )和连续时间动态图( CTDG )、动态图表示学习,但它的重点是学习动态图在每个时间戳中的嵌入、和动态图神经网络[11],该网络通常是GNN和RNN的结合,用GNN处理网络,用RNN处理时序信息。以上方法虽然考虑了图数据的动态增长问题,但忽略了模型对之前任务的学习能力,带来了灾难性遗忘问题。
对于图数据连续学习算法的研究仍处于起步阶段,大多数研究都将图学习和传统连续学习结合起来,称为连续图学习,连续图学习的方法种类也与连续学习非常类似,主要有基于正则化,基于重播和基于结构这三种方法,将在第三节详细讨论,连续图学习和一般的连续学习方法仍有显著差异[12]。
3 连续学习研究现状
连续学习按照处理数据类型的不同分为传统连续学习和图连续学习,如图1所示,传统连续学习和图连续学习的方法具有很强的关联性。
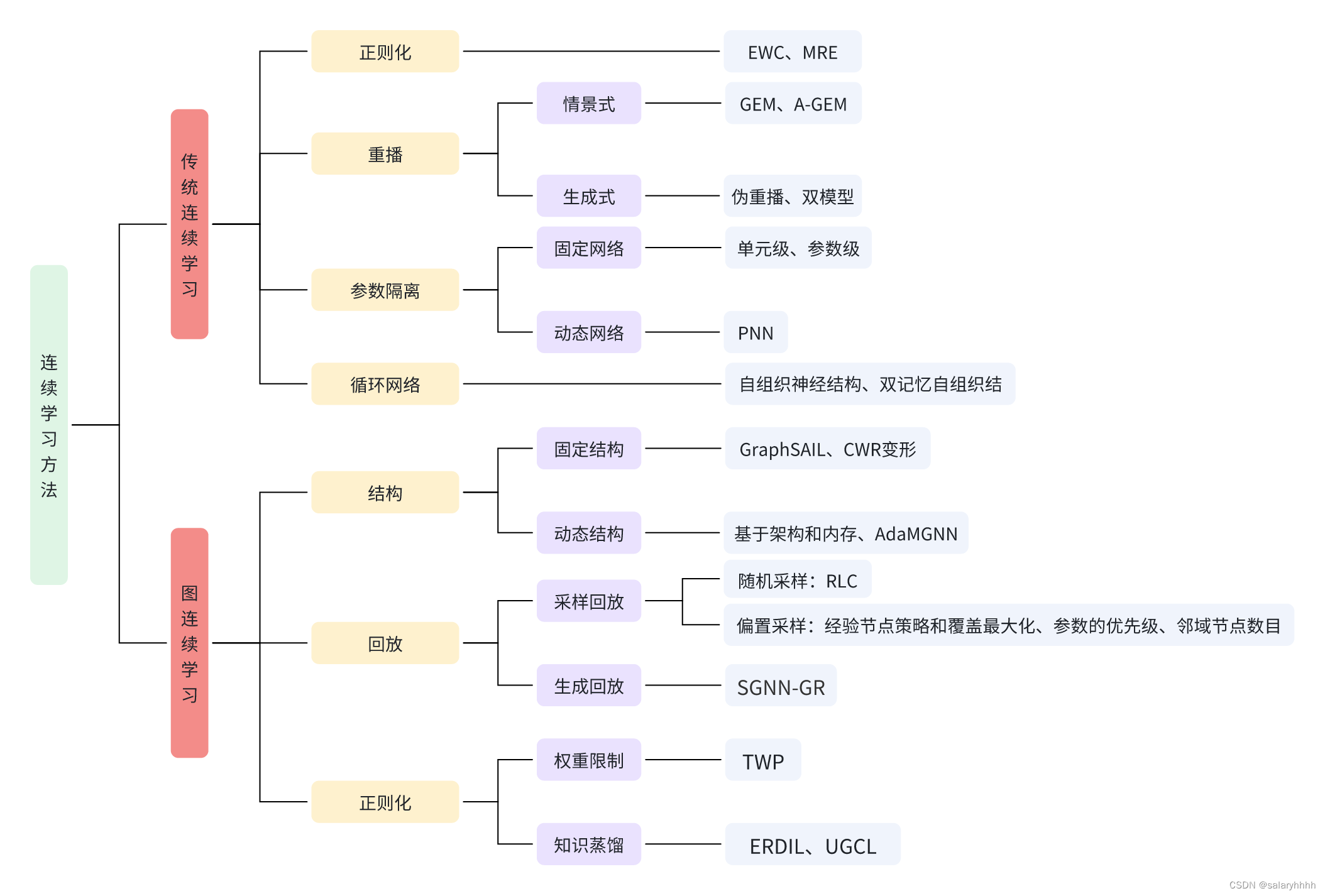
图1 树形图总结了连续学习在传统连续学习和图连续学习上常见的方法分类和一些相关研究。
3.1 传统连续学习
目前传统连续学习方法主要有正则化,重播,参数隔离,与循环神经网络相结合这四个方面[13]。
3.1.1正则化
正则化方法在更新网络参数时增加限制,它阻止了新任务对过去任务训练中得到的重要参数的影响,使得网络在学习新任务时不影响旧知识。最经典的正则化算法Kirkpatrick J等人提出一种可塑权重巩固算法( EWC )[14],EWC从新任务数据对模型的干预角度,让模型参数受限地变动,阻碍在旧任务上重要参数的变化。
正则化方法常常用在模型过拟合问题。在增量学习(重播)中,选择少量的旧任务和新任务一同训练,但我们难以保证所选择的旧任务能很好的表示旧经验信息,这导致模型在任务间转移时的不确定性积累,可能会导致会部分旧任务过拟合学习。为了防止过度适应不确定知识,Kim D[15]提出了通过最大熵正则化器( MER )对自信适应不确定知识进行惩罚。此外,为了减少类间不平衡并诱导对新类别的自我调整课程,Kim D提出了DropOut Sampling( DOS )方法,即在每个小批量中排除新类别的一些样本。
3.1.2重播
重播方法指的是在学习新任务时不断复习回顾旧任务。重播体现两个方面,基于情景记忆和生成式重播。
基于情景记忆(其实就是从旧数据中选择部分数据加入新数据的训练中):GEM[16]是最一种经典的情景记忆方法,它在单次传递中利用小情景记忆来限制新任务,Chaudhry A等人提出一种GEM变形方法A-GEM[17],放松问题限制,从以前的任务数据缓冲区中随机选择的样本估计的一个方向,微调损失函数,提升GEM在训练速度,同时保持类似的性能。Chaudhry A[18]考虑更小的情景记忆,这样可以忽略内存大小约束限制,获得更好的性能和更高效的学习。
生成式重播:训练中可能缺失旧数据信息,多数研究考虑一种伪重播方式生成可能的旧数据信息进行重播训练,即生成式重播。Robins A[19]等人提出将一组给定的随机输入,输入到上一个模型中,用得到的输出信息近似之前的任务样本。但对于深度网络和大的输入向量( 如全分辨率图像 ),随机输入不能覆盖输入空间,由此不能代表旧数据的关键信息[20]。
生成模型也受类脑思想的启发。根据人脑皮层中海马体与新皮层的记忆关系(就是互补学习系统理论,粗略来讲:海马体他能快速学习但迅速遗忘。新皮层他学习很慢但能长期记忆,二者功能互补学习),并行分布式处理学习和互补学习系统理论的启发,Rostami M[21]将旧数据嵌入编码成伪数据点,将从新领域中使用的一些标记数据与嵌入空间中的旧知识耦合,能够有效地扩展和推广学习的概念到新的领域。
Gido M. van de Ven[22]指出目前的生成式重放的方法训练了两个独立的模型:一个主要模型用来解决任务,一个生成模型代表以前任务的抽样样本的。考虑将重播方法进一步与蒸馏技术结合,在连续学习中表现良好,但计算成本可能非常高。进一步将生成模型合并到主模型中,通过装备反馈或反向连接,使训练具有生成能力( 例如,一个添加软层的变分自动编码器 ),这大大减少训练时间。
3.1.3参数隔离
基于参数隔离的基本思想是通过对每个任务使用不同的参数,来避免遗忘。主要分为固定网络方法和动态结构方法[12]:
固定网络方法:学习新任务时,固定网络可以在参数级[37]或单元级[38]上屏蔽网络。
动态结构方法:当模型大小不受限制时为新的任务添加新的分支,同时,固定之前的任务参数,或复制模型,以便独立的模型专用于每个单独的任务。例如渐进式神经网络( PNN )[25]为每个新的学习会话添加一个多层神经网络的现有层的副本。当一个新的学习会话开始时,现有的权重会被冻结。这个策略需要更多的超参数和更多的存储空间。
3.1.4 基于循环网络的方法
使用循环神经网络的连续学习方法是一种自适应模型,可以捕获内部隐藏状态中的输入历史。这些模型被广泛用于序列数据处理( SDP )任务[7]。
Parisi G I[23]提出一种自组织神经结构,从视频序列中增量地学习去分类人类行为。该架构包括不断增长的自组织网络,并配备了循环神经元来处理时变模式。
Parisi G I[24]提出了一种用于终身学习场景的双记忆自组织架构。该架构包括两个不断增长的循环网络,它们具有学习对象实例( 情景记忆 )和类别( 语义记忆 )的互补任务.
3.2 图连续学习
图连续学习方法主要基于三个方面:结构,回放和正则化。(和传统连续学习的方法一一对应)
3.2.1 结构
基于结构的方法(和基于参数隔离的方法类似)侧重于修改网络的特定架构,激活功能或算法层,以解决新任务的同时防止忘记旧任务。主要有固定结构和动态结构两方面。
固定结构:为每个任务分配特定的参数和神经元,在学习新任务时,冻结属于旧任务的参数或神经元。Lukas Galke[39]等人系统地分析了隐式存储模型参数和显式存储模型数据对图连续学习增量训练方法的影响,实验基于固定结构的图神经网络。GraphSAIL[40]实现图结构保存策略,显示地保存每个节点的局部信息、全局信息和自身信息。Daruna A[26]等人将恢复初始化复制权值原理( CWR )运用在知识图谱的学习上。他们引入合并嵌入和临时嵌入方式,基于每个会话的实体和关系的数量,调整并重新初始化实体和关系的临时嵌入。会话结束后,通过新复制或与现有的嵌入做平均运算,将临时嵌入移动到合并嵌入。
动态架构:Rakaraddi A[27]提出了一种结合了基于架构和基于内存的图连续学习策略,包括一个基于强化学习的控制器网络( RLC )和一个基础可训练网络被称为子网络( CN )。观察到新任务时,确定从基础网络中添加/修剪的最优节点数量。多模态结构演化持续图学习MSCGL将多模态与连续学习相结合,Cai J[28]构建了一个自适应多模态图神经网络AdaMGNN可以自适应地从流式任务中学习,也就是根据流式的任务数据动态地调整其网络结构和参数。这意味着,对于每一个新的任务,AdaMGNN都可以改变其复杂度,甚至在训练过程中改变其架构,从而实现对新任务的快速适应。
3.2.2 回放
基于回放的方法是在学习新任务时,利用以前学习的旧知识和当前数据进行联合训练,以避免灾难性遗忘。
基于回放的方法主要有两种,采样方法和生成方法[12]。
采样方法:从旧任务中选取样本,并将它们存放于缓冲区中,但缓冲区大小有限,我们需要考虑如何抽样才能有效的利用旧任务的信息。采样方法分为随机采样和偏置抽样。随机采样即随机的抽取旧样本,RLC[27]采用水塘抽样策略,以等概率随机选择节点。随机抽样没有考虑节点重要性关系,不能有效的保存旧数据的知识。偏置抽样即按照一定标准有选择的进行采样。ER-GNN[29]通过经验节点策略如特征均值和覆盖最大化影响最大化等方式来选择存储在经验缓冲区中的经验节点。Perini M[30]提出了一种基于参数的优先级节点采样策略,选择损失较高的样本。SAER[31]采用邻域节点数目来衡量节点的重要性。
生成方法:通过生成模型生成旧任务的伪数据,以保存旧知识。流式图神经网络SGNN-GR[32]提出了一个基于GAN框架的生成模型来生成节点邻域。
3.2.3正则化
正则化方法通过考虑图的拓扑结构和给损失函数添加相应正则化术语来规范梯度方向,由此限制新任务学习时导致的参数剧烈变化对之前重要参数的影响。
正则化方法主要有两个方面,权重的限制和知识蒸馏。
权重限制:其关键是选择哪些权重进行限制。TWP[29]考虑梯度来定义权重重要性,因为参数的更新是由梯度方向决定的,TWP将注意系数相对于一个特定参数的梯度特征定义重要性。
知识蒸馏:知识蒸馏主要是为了提高模型性能,对模型的函数空间进行正则化,而不是为了进行模型压缩,将复杂模型的知识萃取出来,浓缩到一个小的学生模型中。ERDIL[33]认为范例关系图中的角度关系是一种重要的知识,并利用蒸馏法来传递结构信息来进行连续学习。通用图持续学习UGCL[34]将重播和正则化结合,把每次学习到的任务数据更新保存到重放缓冲区中,从中采样出旧经验,经过图神经网络,使用局部结构蒸馏和全局结构蒸馏过程从之前的任务模型中获得结构化知识。
4 问题与展望
4.1 问题
在连续学习领域,大部分的研究都集中在灾难性遗忘问题,但连续学习的最终目标应该是在无限的学习中不断增强模型的表现能力[12],使模型能够更好的解决各种问题(应该更注重模型的性能,不要太局限在灾难性遗忘了)。而关于灾难性遗忘的研究中,许多研究者更关注内存问题,比如内存容量,信息隐私安全等,时常忽略了计算消耗[8],例如重放方法中存储旧任务的缓冲区,在正则化方法中保存旧参数,旧模型的内存位置。在实际研究中已经充分证明了不需要保存过多旧经验就能很好的实现可塑性与稳定性(可塑性及学习新知识的能力,稳定性及保持旧知识的识别能力)的平衡,而复杂数据带来的高能耗运算问题例如GPT,更应当受到广泛的关注。
图连续学习因为其特殊的数据结构,相比于传统连续学习,还有一些未解决问题[35]。
不确定的邻域:邻域信息可以很好的反应节点的重要程度,和节点与邻接节点的关系问题,可以帮助我们更好的学习图数据特征,虽然图表示学习已经能够很好的解决图领域关系的表示问题,但在连续的图嵌入过程中,对于不确定邻居的动态图嵌入过程仍需要一个优化策略,图终身学习需要考虑新数据嵌入的合适时间和节点关系以维护算法的稳定性和有效性。
图数据的极端变化:节点之间的关系是复杂多变的,在极端情况下图结构可能会随时间迅速改变,大多数旧结构消失,或者出现非常不平衡的节点关系图。在旧数据的保存和重播时要慎重选择。
数据流之间的关系:数据流之间是一个个的图,学习图数据中的全局上下文或全局依赖关系对于理解节点之间的整个关系非常重要。在图连续学习中,学习图的全局上下文关系仍然具有挑战,特别是大规模图中
各种方法之间的比较基准:由于图数据的多样性,图连续学习的应用场景也很丰富,针对节点分类、边分类或图分类等等。不同图连续学习模型效能的比较也受数据集,任务配置等因素的影响。CGLB[36]连续图学习基准提供了一组标准化的数据集、评估指标和实验设置,以便研究人员公平的比较算法。但不同模型针对的问题不同,对数据集可能有一些特殊要求,很难运用一个真正的标准化基准。
4.2 展望
连续学习的运用越来越多元化,除了各种视觉分类的场景外,还扩展到更多计算机视觉运用中。在其他领域,如强化学习,自然语言处理和伦理考虑方面也有广泛的运用。在交叉学科如机器人,图形学习,生物成像等运用场景也有无限的潜力[13]。
在类脑方面,神经科学在连续学习的发展中起着非常重要的引导作用,神经突触可塑性在调节多个脑区域的稳定性和可塑性平衡的机制,还有大脑的互补学习系统都为连续学习的研究带来了重要的生物启发。学科交叉融合发展的趋势是必然的,连续学习的研究是探索人脑学习机制的重要一步,目前连续学习主流上都是处理同模态的数据,而人脑是处理多模态复杂信息的智能生物系统,目前也出现例如MSCGL这样的多模态连续图学习模型,未来连续学习的发展必然会拓宽到更多领域,与生物,物理,化学等方向交叉融合发展,往多模态的道路上不断前进。
参考文献
(按道理标号应该是[1]这种形式,但博客编辑器里面列表好像没有这种)
- De Lange M, Aljundi R, Masana M, et al. A continual learning survey: Defying forgetting in classification tasks[J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 44(7): 3366-3385.
- Pan S J , Yang Q .A Survey on Transfer Learning[J].IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10):1345-1359.
- Vandenhende S , Georgoulis S , Proesmans M ,et al.Revisiting Multi-Task Learning in the Deep Learning Era[J]. 2020.
- Hoi S C H , Sahoo D , Lu J ,et al.Online Learning: A Comprehensive Survey[J]. 2018.
- Masana M, Liu X, Twardowski B, et al. Class-incremental learning: survey and performance evaluation on image classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(5): 5513-5533.
- Parisi G I, Kemker R, Part J L, et al. Continual lifelong learning with neural networks: A review[J]. Neural networks, 2019, 113: 54-71.
- Cossu A, Carta A, Lomonaco V, et al. Continual learning for recurrent neural networks: an empirical evaluation[J]. Neural Networks, 2021, 143: 607-627.
- Verwimp E, Ben-David S, Bethge M, et al. Continual learning: Applications and the road forward[J]. arxiv preprint arxiv:2311.11908, 2023.
- Yuan Q, Guan S U, Ni P, et al. Continual Graph Learning: A Survey[J]. arxiv preprint arxiv:2301.12230, 2023.
- Zhu Y , Lyu F , Hu C ,et al.Encoder-Decoder Architecture for Supervised Dynamic Graph Learning: A Survey[J]. 2022.
- Xue G, Zhong M, Li J, et al. Dynamic network embedding survey[J]. Neurocomputing, 2022, 472: 212-223.
- Tian Z, Zhang D, Dai H N. Continual Learning on Graphs: A Survey[J]. arxiv preprint arxiv:2402.06330, 2024.
- Wang L, Zhang X, Su H, et al. A comprehensive survey of continual learning: Theory, method and application[J]. arxiv preprint arxiv:2302.00487, 2023.
- Kirkpatrick J, Pascanu R, Rabinowitz N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the national academy of sciences, 2017, 114(13): 3521-3526.
- Kim D, Bae J, Jo Y, et al. Incremental learning with maximum entropy regularization: Rethinking forgetting and intransigence[J]. arxiv preprint arxiv:1902.00829, 2019.
- Lopez-Paz D, Ranzato M A. Gradient episodic memory for continual learning[J]. Advances in neural information processing systems, 2017, 30.
- Chaudhry A , Ranzato M , Rohrbach M ,et al.Efficient Lifelong Learning with A-GEM[J]. 2018.
- Chaudhry A , Rohrbach M , Elhoseiny M ,et al.Continual Learning with Tiny Episodic Memories[J]. 2019.
- Robins A. Catastrophic forgetting, rehearsal and pseudorehearsal[J]. Connection Science, 1995, 7(2): 123-146.
- Atkinson C, McCane B, Szymanski L, et al. Pseudo-recursal: Solving the catastrophic forgetting problem in deep neural networks[J]. arxiv preprint arxiv:1802.03875, 2018.
- Rostami M , Kolouri S , Mcclelland J ,et al.Generative Continual Concept Learning.2019[2024-02-26].
- Van d V G M , Tolias A S .Generative replay with feedback connections as a general strategy for continual learning[J]. 2018.
- Parisi G I, Tani J, Weber C, et al. Lifelong learning of human actions with deep neural network self-organization[J]. Neural Networks, 2017, 96: 137-149.
- Parisi G I , Tani J , Weber C ,et al.Lifelong Learning of Spatiotemporal Representations with Dual-Memory Recurrent Self-Organization[J].Frontiers in Neurorobotics, 2018, 12.
- Rusu A A, Rabinowitz N C, Desjardins G, et al. Progressive neural networks[J]. arxiv preprint arxiv:1606.04671, 2016.
- Daruna A , Gupta M , Sridharan M ,et al.Continual Learning of Knowledge Graph Embeddings[J].IEEE Robotics and Automation Letters, 2021, PP(99):1-1.
- Rakaraddi A, Siew Kei L, Pratama M, et al. Reinforced continual learning for graphs[C]//Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022: 1666-1674.
- Cai J, Wang X, Guan C, et al. Multimodal continual graph learning with neural architecture search[C]//Proceedings of the ACM Web Conference 2022. 2022: 1292-1300.
- Zhou F , Cao C .Overcoming Catastrophic Forgetting in Graph Neural Networks with Experience Replay[J]. 2020.
- Perini M, Ramponi G, Carbone P, et al. Learning on streaming graphs with experience replay[C]//Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing. 2022: 470-478.
- Ahrabian K, Xu Y, Zhang Y, et al. Structure aware experience replay for incremental learning in graph-based recommender systems[C]//Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021: 2832-2836.
- Wang J , Song G , Wu Y ,et al.Streaming Graph Neural Networks via Continual Learning[J].ACM, 2020.
- Dong S, Hong X, Tao X, et al. Few-shot class-incremental learning via relation knowledge distillation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(2): 1255-1263.
- Hoang T D, Tung D V, Nguyen D H, et al. Universal graph continual learning[J]. arxiv preprint arxiv:2308.13982, 2023.
- Febrinanto F G , Xia F , Moore K ,et al.Graph Lifelong Learning: A Survey[J].IEEE computational intelligence magazine, 2023.
- Zhang X, Song D, Tao D. CGLB: Benchmark Tasks for Continual Graph Learning[J]. Advances in Neural Information Processing Systems, 2022, 35: 13006-13021.
- Fernando C, Banarse D, Blundell C, et al. Pathnet: Evolution channels gradient descent in super neural networks[J]. arxiv preprint arxiv:1701.08734, 2017.
- Serra J, Suris D, Miron M, et al. Overcoming catastrophic forgetting with hard attention to the task[C]//International conference on machine learning. PMLR, 2018: 4548-4557.
- Galke L , Franke B , Zielke T ,et al.Lifelong Learning of Graph Neural Networks for Open-World Node Classification.2020[2024-03-06].
- Xu Y, Zhang Y, Guo W, et al. Graphsail: Graph structure aware incremental learning for recommender systems[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2861-2868.















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









