






论文阅读笔记(九)——Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
目录
摘要
大规模序列建模引发了快速的进步,现在这些进步已经扩展到生物学和基因组学。然而,建模基因组序列提出了诸如需要建模长距离标记相互作用、基因组上游和下游区域的影响以及DNA的反向互补性(RC)等挑战。在此,我们提出了一种基于这些挑战的架构,该架构基于长距离Mamba块,并将其扩展为支持双向性的BiMamba组件,以及进一步支持RC等变性的MambaDNA块。我们使用MambaDNA作为Caduceus的基础,这是首个支持RC等变性双向长距离DNA语言模型的家族,并介绍了预训练和微调策略,生成Caduceus DNA基础模型。Caduceus在下游基准测试中表现优于之前的长距离模型;在一个具有挑战性的长距离变异效应预测任务中,Caduceus的性能超过了不利用双向性或等变性的10倍更大模型。
简介
建模DNA提出了与自然语言或蛋白质不同的挑战。
- 首先,细胞表型通常受到基因组中上游和下游碱基对的影响,这需要序列模型处理双向上下文。
- 其次,DNA由两条互补链组成,包含相同的信息;建模这一特性可以显著提高性能。
- 第三,许多基因组任务,如预测变异对基因表达的影响,可能涉及长距离相互作用,因为即使距离基因1百万碱基对的核酸也可以有显著的调控效果)。
在本文中,我们提出了受上述挑战启发的架构组件。我们的模块基于长距离Mamba块,因此可以自然地处理成千上万核苷酸的长序列,而不会产生注意力机制架构的二次计算成本。我们将Mamba扩展为BiMamba,一个支持双向性的组件,并进一步扩展为MambaDNA,支持反向互补(RC)等变性。MambaDNA块可以作为基因组分析架构中的一个直接替换组件,适用于有监督和自监督的上下文。
然后我们使用MambaDNA作为Caduceus1的基础,这是首个支持RC等变性语言建模的双向长距离DNA序列模型家族。我们进一步介绍了生成Caduceus基础模型的预训练和微调策略,用于广泛的基因组预测任务。Caduceus模型在下游性能方面始终优于之前的SSM基模型。在许多任务中,尤其是需要长距离建模的任务中,Caduceus的表现也优于10倍更大的基于Transformer的模型。
我们使用Caduceus进行变异效应预测(VEP),这一任务旨在确定遗传突变是否影响表型——在我们的案例中是基因表达。这一任务非常适合Caduceus,因为其预训练隐含地学习识别进化压力的效果(例如,保守性,共进化),这是VEP的一个关键信号来源(例如,一个突变在突变稀少的区域可能具有影响,并且在模型下具有较低的概率)。在一个基于标准数据集的变异对基因表达长距离影响的任务(Avsec et al., 2021)中,Caduceus大幅超越了现有的注意力和SSM基模型。
贡献
总结而言,我们的贡献是:
-
我们介绍了BiMamba,这是Mamba块的一个参数和硬件效率高的扩展,支持双向序列建模。
-
我们将BiMamba扩展为支持RC等变性,产生了MambaDNA块,这是基因组学深度学习架构的一个通用组件。
-
我们使用MambaDNA作为Caduceus的基础,首次实现了RC等变性DNA基础模型家族。
-
我们展示了在长距离任务中,Caduceus的表现优于不使用双向性或等变性的10倍更大的模型。
背景
序列建模中的挑战
DNA 序列的独特性引发了若干建模挑战。首先,DNA 是由两条链组成,这两条链是反向互补的(RC)。这意味着一条链上的信息在另一条链上以相反的方向重复。因此,序列模型需要处理这一双向信息,以充分理解 DNA 的功能。
其次,基因组的功能通常不仅仅依赖于局部的核苷酸序列,还依赖于更长范围内的相互作用。调控序列(如增强子)可以位于距离其目标基因数十万甚至数百万碱基对的位置。 因此,模型需要能够捕捉长距离依赖关系,以准确预测基因组功能。
最后,DNA 序列中存在大量的重复和高度保守的区域,这些区域在进化过程中受到选择压力。模型需要能够识别和利用这些模式,以提高预测准确性。
长距离序列模型
为了解决这些挑战,研究人员开发了多种长距离序列模型。这些模型包括基于注意力机制的 Transformer 模型(Vaswani et al., 2017)以及其他如 Longformer(Beltagy et al., 2020)和 Linformer(Wang et al., 2020)等变种。然而,这些模型通常具有较高的计算成本,特别是在处理非常长的序列时。
近年来,基于状态空间模型(SSM)的方法(Gu et al., 2021)显示出了在长距离序列建模中的潜力。SSM 可以有效地捕捉长距离依赖关系,同时保持较低的计算成本。Mamba 块(Gu & Dao, 2023)是最近提出的一种 SSM 变种,能够在保持计算效率的同时处理长达数十万碱基对的序列。
Mamba 块及其扩展
Mamba 块是基于状态空间模型的序列建模组件,能够高效地处理长序列。Mamba 块的核心是通过状态转移矩阵和输入矩阵来捕捉序列中的依赖关系,从而避免了注意力机制的二次计算成本。具体来说,Mamba 块通过以下状态转移方程来建模序列:
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ( t ) + D x ( t ) h'(t) = Ah(t) + Bx(t), \quad y(t) = Ch(t) + Dx(t) h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)+Dx(t)
其中, h t h_t ht 表示状态向量, A A A表示状态转移矩阵, B B B 表示输入矩阵, x t x_t xt表示输入序列。通过这种方式,Mamba 块能够高效地捕捉序列中的长距离依赖关系。
在本文中,我们将 Mamba 块扩展为支持双向性的 BiMamba 块。BiMamba 块不仅能够捕捉序列中的前向依赖关系,还能够捕捉后向依赖关系。具体来说,BiMamba 块通过以下双向状态转移方程来建模序列:
h t + 1 = A ˉ h t + B ˉ x t , y t + 1 = C h t + D x t , h_{t+1} = \bar{A} h_t + \bar{B} x_t, \quad y_{t+1} = C h_t + D x_t, ht+1=Aˉht+Bˉxt,yt+1=Cht+Dxt,
重要的是,方程 (1) 的线性时间不变性(LTI)允许我们通过展开递归来等效地将方程 (2) 表示为卷积,从而在训练过程中实现高效的并行计算。
通过某种与连续参数 ¥A, B ) 和附加时间尺度参数 (\Delta) 相关的离散化公式进行离散化。在 SSM 文献中常用的零阶保持离散化公式定义如下:
A ˉ = exp ( A Δ ) , B ˉ = A − 1 ( exp ( A Δ ) − I ) B . \bar{A} = \exp(A\Delta), \quad \bar{B} = A^{-1}(\exp(A\Delta) - I)B. Aˉ=exp(AΔ),Bˉ=A−1(exp(AΔ)−I)B.
重要的是,方程 (1) 的线性时间不变性(LTI)允许我们通过展开递归来等效地将方程 (2) 表示为卷积,从而在训练过程中实现高效的并行计算。
选择机制
然而,LTI 表示的计算效率以模型无法适应/关注特定输入为代价。为了解决这种缺乏表现力的问题,Gu & Dao (2023) 提出了一种选择性 SSM,使参数 ( B, C ) 和 (\Delta) 依赖于输入 ( x(t) ),具体如下:
B
t
=
Linear
B
(
x
t
)
,
C
t
=
Linear
C
(
x
t
)
B_t = \text{Linear}_B(x_t), \quad C_t = \text{Linear}_C(x_t)
Bt=LinearB(xt),Ct=LinearC(xt)
Δ
t
=
softplus
(
Linear
Δ
(
x
t
)
)
,
\Delta_t = \text{softplus}(\text{Linear}_{\Delta}(x_t)),
Δt=softplus(LinearΔ(xt)),
其中
Linear
(
⋅
)
\text{Linear}(\cdot)
Linear(⋅) 表示线性变换,
softplus
(
x
)
=
log
(
1
+
exp
(
x
)
)
\text{softplus}(x) = \log(1 + \exp(x))
softplus(x)=log(1+exp(x))。虽然这种公式使
A
t
A_t
At 和
B
t
B_t
Bt具有时间依赖性,但可以将方程 (2) 中的线性递归重新公式化为
此外,我们将 BiMamba 块进一步扩展为支持反向互补(RC)等变性的 MambaDNA 块。MambaDNA 块能够处理 DNA 序列的双向信息和反向互补特性,使其成为基因组学分析的理想组件。

3 双向 & RC 等变 Mamba
在本节中,我们介绍扩展 Mamba 块 (Gu & Dao, 2023) 的组件。虽然这些扩展是领域无关的,但它们与 DNA 建模相关。
3.1 BiMamba
我们对标准 Mamba 模块应用的第一个扩展是将其从因果(从左到右)转换为双向。我们通过两次应用 Mamba 模块来实现这一点:一次是对原始序列,另一次是对沿长度维度反转的副本。为了合并信息,反向序列的输出沿长度维度反转并添加到前向序列。
这种方法的一个简单实现将使模块的参数数量加倍。为了避免增加的内存占用,我们改用共享投影权重来连接“前向”和“反向”Mamba。与卷积和 SSM 子模块中的参数相比,这些投影占了模型参数的绝大部分。我们将此参数高效的双向块称为 BiMamba。该模块在图 1 的中间图示中进行了说明。
3.2 MambaDNA
为了将 RC 等变归纳偏置编码到我们的模块中,我们对序列及其 RC 应用一个 Mamba(或 BiMamba)块,并在两个应用之间共享参数 (Shrikumar et al., 2017; Zhou et al., 2021)。鉴于其在基因组学中的相关性,我们将该块称为 MambaDNA。
更具体地说,表示长度为 T T T、通道数为 D D D的序列为 X 1 : T 1 : D \mathbf{X}^{1:D}_{1:T} X1:T1:D。我们的通道拆分操作定义如下:
split ( X 1 : T 1 : D ) : = [ X 1 : T 1 : ( D / 2 ) , X 1 : T ( D / 2 + 1 ) : D ] . \text{split}(\mathbf{X}^{1:D}_{1:T}) := \left[ \mathbf{X}^{1:(D/2)}_{1:T} , \mathbf{X}^{(D/2+1):D}_{1:T} \right]. split(X1:T1:D):=[X1:T1:(D/2),X1:T(D/2+1):D].
我们还定义了 RC 操作如下:
RC ( X 1 : T 1 : D ) : = X T : 1 D : 1 . \text{RC}(\mathbf{X}^{1:D}_{1:T}) := \mathbf{X}^{D:1}_{T:1}. RC(X1:T1:D):=XT:1D:1.
最后,让 concat 表示重新组合沿通道维度分裂的序列的操作,我们的 RC 等变 Mamba 模块 M RC , θ \mathbf{M}_{\text{RC}, \theta} MRC,θ表示为:
M RC , θ ( X 1 : T 1 : D ) : = concat ( [ M θ ( X 1 : T 1 : ( D / 2 ) ) , RC ( M θ ( RC ( X 1 : T ( D / 2 + 1 ) : D ) ) ) ] ) , \mathbf{M}_{\text{RC}, \theta} (\mathbf{X}^{1:D}_{1:T}) := \text{concat} \left( \left[ \mathbf{M}_\theta \left( \mathbf{X}^{1:(D/2)}_{1:T} \right) , \text{RC} \left( \mathbf{M}_\theta \left( \text{RC} \left( \mathbf{X}^{(D/2+1):D}_{1:T} \right) \right) \right) \right] \right), MRC,θ(X1:T1:D):=concat([Mθ(X1:T1:(D/2)),RC(Mθ(RC(X1:T(D/2+1):D)))]),
其中, M θ \mathbf{M}_\theta Mθ表示通过标准 Mamba 或 BiMamba 参数化的序列运算符。图 1 的右侧图示中描述了 MambaDNA 模块,其中 M θ \mathbf{M}_\theta Mθ显示为标准 Mamba。
我们声称 MambaDNA 满足我们所期望的处理 DNA 序列的 RC 等变性质:
定理 3.1
M RC , θ \mathbf{M}_{\text{RC}, \theta} MRC,θ 运算符满足以下性质:
RC ∘ M RC , θ ( X 1 : T 1 : D ) = M RC , θ ∘ RC ( X 1 : T 1 : D ) . \text{RC} \circ \mathbf{M}_{\text{RC}, \theta} (\mathbf{X}^{1:D}_{1:T}) = \mathbf{M}_{\text{RC}, \theta} \circ \text{RC} (\mathbf{X}^{1:D}_{1:T}). RC∘MRC,θ(X1:T1:D)=MRC,θ∘RC(X1:T1:D).
证明见附录 A。

类似于 BiMamba 模块,MambaDNA 块不需要显著的额外内存占用,因为处理前向和 RC 序列的包裹序列运算符完全共享。
Caduceus

Caduceus
下面我们描述 Caduceus,这是一种新型双向 DNA 语言模型架构,强调 RC 等变性。我们介绍了该模型的两个版本,每个版本都通过不同的方式保持等变性:(1)通过参数共享 (Shrikumar et al., 2017),即 Caduceus-PS,或(2)通过在下游任务中使用的一种技术,称为后处理合并 (post-hoc conjoining) (Zhou et al., 2021),即 Caduceus-Ph。
Caduceus-PS
架构 对于 Caduceus-PS,我们利用了第 3 节中介绍的架构创新。即,我们将一个 BiMamba 模块封装在一个 MambaDNA 块内。此外,在 Mamba 块之前,架构中还包含一个 RC 等变标记嵌入模块。记 Embg 为将一个热向量 X 1 : T 1 : D \mathbf{X}^{1:D}_{1:T} X1:T1:D映射到 R D / 2 \mathbb{R}^{D/2} RD/2的线性投影,RC 等变版本的嵌入定义为:
Emb RC , θ ( X 1 : T 1 : D ) : = concat ( [ Embg ( X 1 : T 1 : ( D / 2 ) ) , RC ∘ Embg ( RC ( X 1 : T ( D / 2 + 1 ) : D ) ) ] ) \text{Emb}_{\text{RC}, \theta} (\mathbf{X}^{1:D}_{1:T}) := \text{concat} \left( \left[ \text{Embg} \left( \mathbf{X}^{1:(D/2)}_{1:T} \right) , \text{RC} \circ \text{Embg} \left( \text{RC} \left( \mathbf{X}^{(D/2+1):D}_{1:T} \right) \right) \right] \right) EmbRC,θ(X1:T1:D):=concat([Embg(X1:T1:(D/2)),RC∘Embg(RC(X1:T(D/2+1):D))])
此外,Caduceus 模型的 logits 通过其最终的 MambaDNA 块传递,通过一个 RC 等变语言模型头进行计算。我们认为,Caduceus-PS 是第一个将 RC 等变性纳入 LM 预训练范式的模型。通过定义通道翻转操作 flip_chan X 1 : T 1 : D : = ( X T : 1 D : 1 ) \mathbf{X}^{1:D}_{1:T} := \left( \mathbf{X}^{D:1}_{T:1} \right) X1:T1:D:=(XT:1D:1),然后让 LMLg 为从具有 D/2 通道的序列到 R 4 \mathbb{R}^4 R4向量的线性投影,定义语言模型头的等变版本为:
LM RC , θ ( X 1 : T 1 : D ) : = LMg ( X 1 : T 1 : ( D / 2 ) ) + flip chan ∘ LMg ( X 1 : T ( D / 2 + 1 ) : D ) \text{LM}_{\text{RC}, \theta} (\mathbf{X}^{1:D}_{1:T}) := \text{LMg}( \mathbf{X}^{1:(D/2)}_{1:T} ) + \text{flip chan} \circ \text{LMg}( \mathbf{X}^{(D/2+1):D}_{1:T}) LMRC,θ(X1:T1:D):=LMg(X1:T1:(D/2))+flip chan∘LMg(X1:T(D/2+1):D)
如图 2 中的黑色路径所示,Caduceus-PS 使 RC 等变语言模型预训练成为可能:它对给定序列的 RC 的预测等效于沿长度维度反转原始序列的预测,并补充互补碱基:A-T 和 C-G。我们在下面的声明中形式化了这一说法:
定理
组合 LM RC , θ ∘ M RC , θ ( n ) ∘ Emb RC , θ \text{LM}_{\text{RC}, \theta} \circ \mathbf{M}_{\text{RC}, \theta}^{(n)} \circ \text{Emb}_{\text{RC}, \theta} LMRC,θ∘MRC,θ(n)∘EmbRC,θ,其中 M RC , θ ( n ) \mathbf{M}_{\text{RC}, \theta}^{(n)} MRC,θ(n)表示不同 Mamba RC 等变模块的 n 次组合,得到一个 RC 等变的序列运算符。
证明见附录 B。

预训练 鉴于该模型的双向性,我们使用掩码语言建模(MLM)目标训练 Caduceus-PS,使用 BERT (Devlin et al., 2018) 提出的标准掩码配方。Caduceus-PS 的 RC 等变语言建模意味着我们不需要在预训练时进行 RC 数据增强,因为预测本质上是关于这个问题的对称的。
下游使用 对于下游任务,由于所测序列的任一链将携带相同标签,我们希望强调 RC 不变性。Caduceus-PS 中的标记嵌入参数共享意味着其中间和最终隐藏状态是两个(通道)维度的平均值。为了在下游训练和推理中保持 RC 不变性,中间和最终隐藏状态被分割,两部分分别被平均。
Caduceus-Ph
架构 Caduceus-Ph 模型在图 2 中用蓝色路径表示。模型的核心是 BiMamba 块的堆栈。
预训练 与 Caduceus-PS 一样,该模型使用相同的 MLM 目标进行预训练。然而,由于该模型不是 RC 等变 LM,我们必须依赖预训练期间的数据增强。
下游使用 为了使下游任务的表示 RC 不变性,我们采用了一种称为后处理合并 (post-hoc conjoining) 的技术 (Zhou et al., 2021)。具体来说,对于下游任务,保持骨干模型不变,但我们在推理时应用 RC 数据增强。然而,对于下游任务推理,我们对原始序列和一次翻转的序列应用模型两次,然后对输出求平均,有效地执行一次 RC 合并 (Mallet & Vert, 2021)。
结果
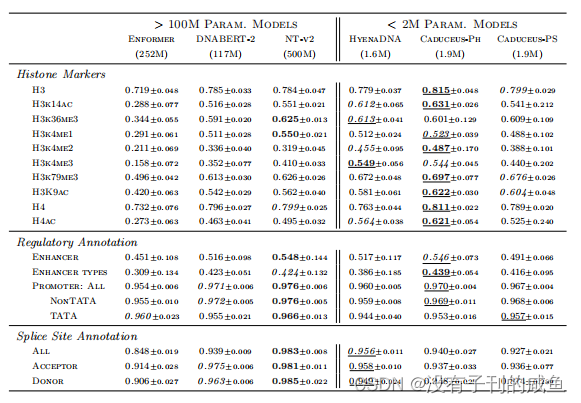
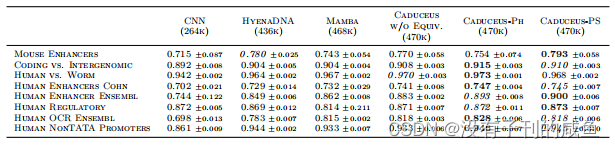















 2875
2875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









