






论文阅读笔记(五)——Hyena Hierarchy: Towards Larger Convolutional Language Models
目录
摘要
深度学习的最新进展很大程度上依赖于大型transformer的使用,因为它们具有大规模学习的能力。然而,transformer的核心构建块,即注意算子,在序列长度上表现出二次代价,限制了上下文可访问的数量。现有的基于低秩和稀疏逼近的次二次方法需要与密集关注层相结合来匹配transformer,这表明在能力上存在差距。在这项工作中,我们提出了Hyena,一个由隐式参数化长卷积和数据控制门控交错构建的亚二次型注意力替代算法。在数千到数十万个令牌序列的回忆和推理任务中,Hyena比依赖状态空间和其他隐式和显式方法的操作符提高了50多个点的准确性,与基于注意力的模型相匹配。我们在标准数据集(WikiText103和The Pile)的语言建模上为密集的无注意力架构设置了新的最先进的技术,在序列长度2K时,将所需的训练计算减少了20%,达到了Transformer的质量。当序列长度为8K时,Hyena operators的速度是高度优化注意力的两倍,当序列长度为64K时,速度是高度优化注意力的100倍。
简介
Hyena层次结构,这是一个由两个有效的次二次基元的递归定义的算子:长卷积和元素明智的乘法门控(见图1.1)。递归的指定深度(即步数)控制运算符的大小。对于短递归,将现有模型作为特殊情况恢复。通过将Hyena递归中的每一步映射到其相应的矩阵形式,我们揭示了Hyena算子等价地定义为数据控制矩阵的分解,即,其条目是输入的函数的矩阵。此外,我们展示了如何利用快速卷积算法在不具体化完整矩阵的情况下有效地评估Hyena算子。根据经验,Hyena算子能够在规模上显著缩小与注意力的质量差距,以更小的计算预算达到相似的困惑和下游性能(第4.2节),并且没有注意力的杂交。

链接
Preliminaries and Related Work
离散卷积是两个参数的函数:一个长度为L的输入
u
u
u信号和一个可学习的滤波器
h
h
h。(可能是无限长)可测量滤波器
h
h
h与长度为l的输入信号
u
u
u的线性(非周期)卷积定义为
y
t
=
(
h
∗
u
)
t
=
∑
n
=
0
L
−
1
h
t
−
n
u
n
y_{t}=(h * u)_{t}=\sum_{n=0}^{L-1} h_{t-n} u_{n}
yt=(h∗u)t=n=0∑L−1ht−nun
一般来说,是
u
t
∈
R
D
u_t \in R^{D}
ut∈RD,其中D是信号的宽度,或者用深度学习的术语来说,是channel的数量。在不损失一般性的情况下,我们专门分析单输入单输出(SISO)层,即D = 1。多输入多输出(MIMO)的情况,在标准卷积层中是典型的,直接遵循。
在这种情况下,输入信号可以表示为向量 u ∈ R L u \in R^{L} u∈RL,卷积可以表示为输入与滤波器h诱导的Toeplitz核矩阵 S h ∈ R L × L S_h \in R^{L \times L} Sh∈RL×L之间的矩阵向量积:
( h ∗ u ) = [ h 0 h − 1 ⋯ h − L + 1 h 1 h 0 ⋯ h − L + 2 ⋮ ⋮ ⋱ ⋮ h L − 1 h L − 2 ⋯ h 0 ] [ u 0 u 1 ⋮ u L − 1 ] (h * u)=\left[\begin{array}{cccc} h_{0} & h_{-1} & \cdots & h_{-L+1} \\ h_{1} & h_{0} & \cdots & h_{-L+2} \\ \vdots & \vdots & \ddots & \vdots \\ h_{L-1} & h_{L-2} & \cdots & h_{0} \end{array}\right]\left[\begin{array}{c} u_{0} \\ u_{1} \\ \vdots \\ u_{L-1} \end{array}\right] (h∗u)= h0h1⋮hL−1h−1h0⋮hL−2⋯⋯⋱⋯h−L+1h−L+2⋮h0 u0u1⋮uL−1
Explicit and Implicit Convolutions
隐式参数化的一种选择是选择h作为线性状态空间模型(SSM)的响应函数,由一阶差分方程描述:
x
t
+
1
=
A
x
t
+
B
u
t
state equation
y
t
=
C
x
t
+
D
u
t
output equation
\begin{array}{l} x_{t+1}=\mathrm{A} x_{t}+\mathrm{B} u_{t} \quad \text { state equation } \\ y_{t}=\mathrm{C} x_{t}+\mathrm{D} u_{t} \quad \text { output equation } \\ \end{array}
xt+1=Axt+But state equation yt=Cxt+Dut output equation
在这里,
x
0
=
0
x_0 = 0
x0=0的方便选择将输入-输出映射呈现为一个简单的卷积
y
t
=
∑
n
=
0
t
(
C
A
t
−
n
B
+
D
δ
t
−
n
)
u
n
y_{t}=\sum_{n=0}^{t}\left(\mathrm{CA}^{t-n} \mathrm{~B}+\mathrm{D} \delta_{t-n}\right) u_{n}
yt=n=0∑t(CAt−n B+Dδt−n)un
其中δt表示Kronecker delta。我们可以确定过滤器
h
h
h
t
↦
h
t
=
{
0
t
<
0
C
A
t
B
+
D
δ
t
t
≥
0
t \mapsto h_{t}=\left\{\begin{array}{ll} 0 & t<0 \\ \mathrm{CA}^{t} \mathrm{~B}+\mathrm{D} \delta_{t} & t \geq 0 \end{array}\right.
t↦ht={0CAt B+Dδtt<0t≥0
其中A的项;B;C和D是filter的学习参数。在层设计方面,ssm的自由度是矩阵的状态维度和结构维度。ssm是一个典型的例子,说明具有次线性参数计数的长卷积可以改善长序列的深度学习模型。
Self-Attention Operator
Transformers的核心是多头注意(MHA)机制。给定长度为
L
L
L的序列
u
∈
R
L
×
D
u \in R^{L\times D}
u∈RL×D,每个缩放自注意头部(Vaswani et al ., 2017)是从
R
L
×
D
R^{L\times D}
RL×D到
R
L
×
D
R^{L\times D}
RL×D的映射,它执行以下操作
A
(
u
)
=
SoftMax
(
1
D
u
M
q
M
k
⊤
u
⊤
)
y
=
SelfAttention
(
u
)
=
A
(
u
)
u
M
v
\begin{aligned} \mathrm{A}(u) & =\operatorname{SoftMax}\left(\frac{1}{\sqrt{D}} u \mathrm{M}_{q} \mathrm{M}_{k}^{\top} u^{\top}\right) \\ y & =\operatorname{SelfAttention}(u) \\ & =\mathrm{A}(u) u \mathrm{M}_{v} \end{aligned}
A(u)y=SoftMax(D1uMqMk⊤u⊤)=SelfAttention(u)=A(u)uMv
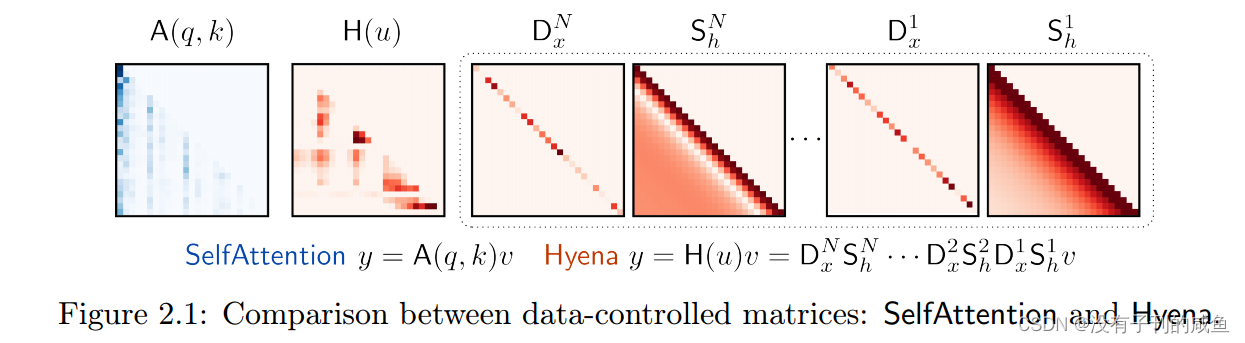
Hyena: Definition and Properties
Hyena Recurrences
在高层次上,Hyena包括以下步骤(设置D = 1以清晰):
- 计算一组输入的N +1个线性投影,类似于注意力。投影数 ( v t , x t 1 , . . . . , x t N ) \left ( v_t,x^1_t,....,x^N_t \right ) (vt,xt1,....,xtN)不一定是3。一个投影作为值的角色,使得一个线性输入输出函数可以定义为 y = H ( u ) v y = H(u)v y=H(u)v对于某个H(u)。
- 矩阵H(u)是通过将隐式长卷积和每次与一个 x i x_i xi投影的逐元素乘法交错来定义的,直到所有投影都耗尽为止。H(u)v的计算是有效的,不需要具体化H(u)。通过这样做,我们隐式地将数据控制算子定义为矩阵的因式分解。形成H(u)的长卷积隐式参数化,以保持序列长度的次线性参数缩放

输入输出映射可以重写为
y
=
x
N
⋅
(
h
N
∗
(
x
N
−
1
⋅
(
h
N
−
1
∗
(
⋯
)
)
)
)
y=x^{N} \cdot\left(h^{N} *\left(x^{N-1} \cdot\left(h^{N-1} *(\cdots)\right)\right)\right)
y=xN⋅(hN∗(xN−1⋅(hN−1∗(⋯))))
Hyena Matrices
Hyena operators基于开发的H3机制。为了清楚地说明,我们再次考虑SISO情况(D = 1)。设Dq和Dk为l × l对角矩阵,其各自的主对角项分别是q和k的相应项。H3实现了一个具有数据控制的、参数化分解的代理注意力矩阵,分为四项:
A
(
q
,
k
)
=
D
q
S
ψ
D
k
S
φ
H
3
(
q
,
k
,
v
)
=
A
(
q
,
k
)
v
\begin{aligned} \mathrm{A}(q, k) & =\mathrm{D}_{q} \mathrm{~S}_{\psi} \mathrm{D}_{k} \mathrm{~S}_{\varphi} \\ \mathrm{H} 3(q, k, v) & =\mathrm{A}(q, k) v \end{aligned}
A(q,k)H3(q,k,v)=Dq SψDk Sφ=A(q,k)v
其中$\mathrm{~S}{\psi} \mathrm{~S}{\varphi} 为可学习因果滤波器的 T o e p l i t z 矩阵 为可学习因果滤波器的Toeplitz矩阵 为可学习因果滤波器的Toeplitz矩阵\psi,\varphi$通过ssm参数化
与qkv投影一起,滤波器构成了层设计中的自由度。这种分解允许在O(llog2l)时间内(两个FFT卷积和两个元素积)计算(8),即。
z
t
=
k
t
(
φ
∗
v
)
t
y
t
=
q
t
(
ψ
∗
z
)
t
\begin{aligned} z_{t} & =k_{t}(\varphi * v)_{t} \\ y_{t} & =q_{t}(\psi * z)_{t} \end{aligned}
ztyt=kt(φ∗v)t=qt(ψ∗z)t
对于任意数量的投影(不限于三个),Hyena表示(8)的泛化,并且对于卷积具有隐式的自由形式长过滤器。得到的递归式(4)也可以用矩阵形式
y
=
H
(
u
)
v
y = H(u)v
y=H(u)v表示。设
D
x
n
=
d
i
a
g
(
x
n
)
∈
R
L
×
L
D^n_x = diag(x^n) \in R^{L×L}
Dxn=diag(xn)∈RL×L,设shnh为滤波器h n对应的Toeplitz矩阵。得到的Hyena递归式在v上是线性的,可以用矩阵形式重写:
y
=
H
(
u
)
v
=
D
x
N
S
h
N
⋯
D
x
2
S
h
2
D
x
1
S
h
1
v
y=\mathrm{H}(u) v=\mathrm{D}_{x}^{N} \mathrm{~S}_{h}^{N} \cdots \mathrm{D}_{x}^{2} \mathrm{~S}_{h}^{2} \mathrm{D}_{x}^{1} \mathrm{~S}_{h}^{1} v
y=H(u)v=DxN ShN⋯Dx2 Sh2Dx1 Sh1v
Hyena Filters
这里我们提供了卷积参数化的细节。我们将每个Hyena算子的过滤器表示为从时间(或空间)域t到值ht的映射,并使用浅前馈神经网络(FFN)进行学习:
h
t
=
Window
(
t
)
⋅
(
FFN
∘
PositionalEncoding
)
(
t
)
h_{t}=\operatorname{Window}(t) \cdot(\text { FFN } \circ \text { PositionalEncoding })(t)
ht=Window(t)⋅( FFN ∘ PositionalEncoding )(t)

Hyena Algorithm

Code
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
import random
import string
# Check for GPU availability
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
class TextDataset(Dataset):
def __init__(self, text, seq_len):
self.text = text
self.seq_len = seq_len
def __len__(self):
return len(self.text) - self.seq_len
def __getitem__(self, index):
return torch.tensor(self.text[index:index+self.seq_len]), torch.tensor(self.text[index+self.seq_len])
class Hyena(nn.Module):
def __init__(self, input_dim, output_dim, filter_size, depth, positional_dim):
super(Hyena, self).__init__()
self.depth = depth
self.output_dim = output_dim
self.input_dim = input_dim
self.positional_dim = positional_dim
self.filter_size = filter_size
self.linear1 = nn.Linear(input_dim, (output_dim + 1) * depth)
self.conv1d = nn.Conv1d(depth, depth, filter_size, padding=filter_size // 2)
self.linear2 = nn.Linear(depth * positional_dim, output_dim)
def forward(self, x):
x = x.float() # Convert input tensor to float
x = self.linear1(x)
x = x.view(x.size(0), -1, self.depth).transpose(1, 2)
x = self.conv1d(x)
x = x.transpose(1, 2).contiguous().view(-1, self.depth * self.positional_dim)
x = self.linear2(x)
return x
def train_hyena_model(text_file, input_dim, filter_size, depth, positional_dim, lr, num_epochs, batch_size=128):
text = open(text_file, 'r').read()
text = text.lower()
chars = list(set(text))
char_to_idx = {ch: i for i, ch in enumerate(chars)}
dataset = TextDataset([char_to_idx[ch] for ch in text], input_dim)
dataloader = DataLoader(dataset, batch_size=batch_size, pin_memory=True)
# Move model to GPU if available
model = Hyena(input_dim, len(chars), filter_size, depth, positional_dim).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(1, num_epochs + 1):
for seqs, targets in dataloader:
# Move tensors to GPU if available
seqs, targets = seqs.to(device), targets.to(device)
model.zero_grad()
outputs = model(seqs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch [{epoch}/{num_epochs}], Loss: {loss.item():.4f}')
print('Training completed.')
return model, chars, char_to_idx
def generate_text(model, seed_text, length, char_to_idx, idx_to_char, vocab, input_dim):
model.eval()
with torch.no_grad():
seed_indices = torch.LongTensor([
char_to_idx.get(c, random.randint(0, vocab - 1)) for c in seed_text.lower()
])
if len(seed_indices) < input_dim:
seed_indices = torch.cat((seed_indices, torch.zeros(input_dim - len(seed_indices), dtype=torch.long))).to(device)
out = []
for i in range(length):
seed_input = seed_indices.float().unsqueeze(0).to(device)
outputs = model(seed_input)
probs = nn.functional.softmax(outputs[-1], dim=0)
probs = probs.cpu().numpy()
next_idx = np.random.choice(len(probs), p=probs)
out.append(idx_to_char[next_idx])
seed_indices[:-1] = seed_indices[1:].clone()
seed_indices[-1] = next_idx
return out
def main():
random_text = ''.join(
random.choice(string.ascii_lowercase + string.digits + string.punctuation + ' ')
for _ in range(1337)
)
with open('random_text.txt', 'w') as f:
f.write(random_text)
input_dim = 70
output_dim = 64
filter_size = 3
depth = 3
positional_dim = (input_dim - filter_size + 2 * (filter_size // 2)) // 1 + 1
lr = 0.001
num_epochs = 1000
model, vocab, char_to_idx = train_hyena_model(
'random_text.txt', input_dim, output_dim, filter_size, depth, positional_dim, lr, num_epochs
)
idx_to_char = {idx: char for char, idx in char_to_idx.items()}
seed_text = 'The quick brown fox'
num_chars = 70
generated_text = generate_text(model, seed_text, num_chars, char_to_idx, idx_to_char, len(vocab), input_dim)
print('Generated text: ' + ''.join(generated_text))
if __name__ == '__main__':
main()
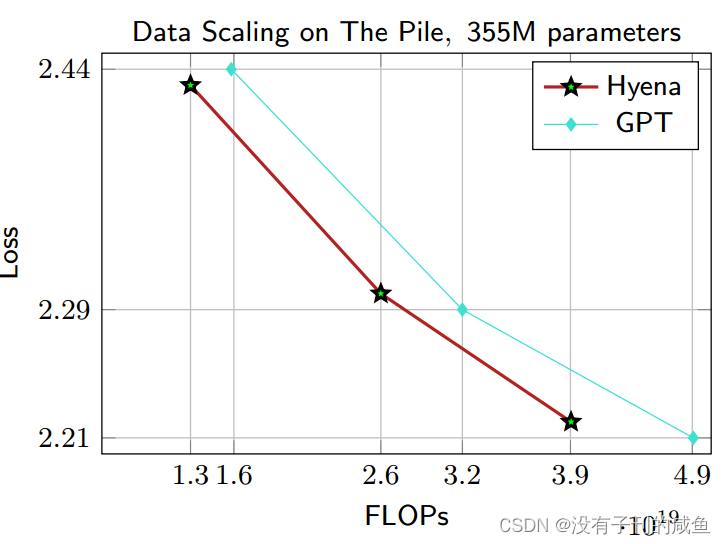
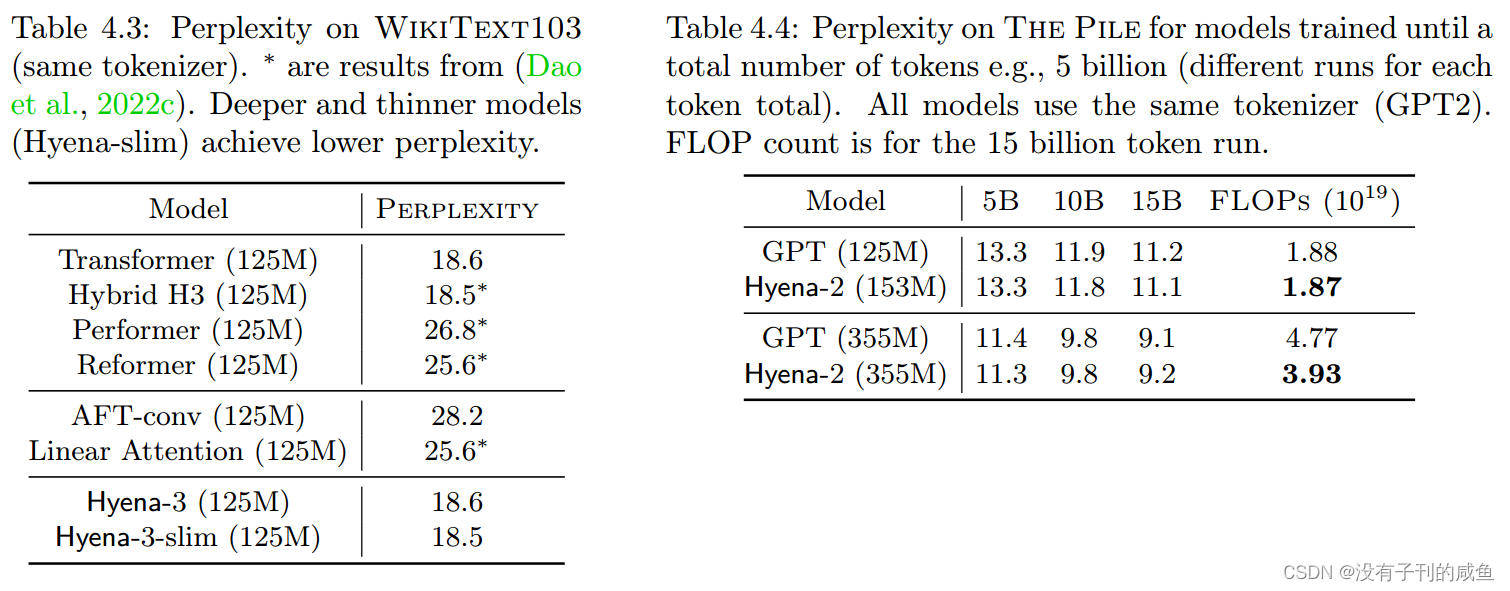
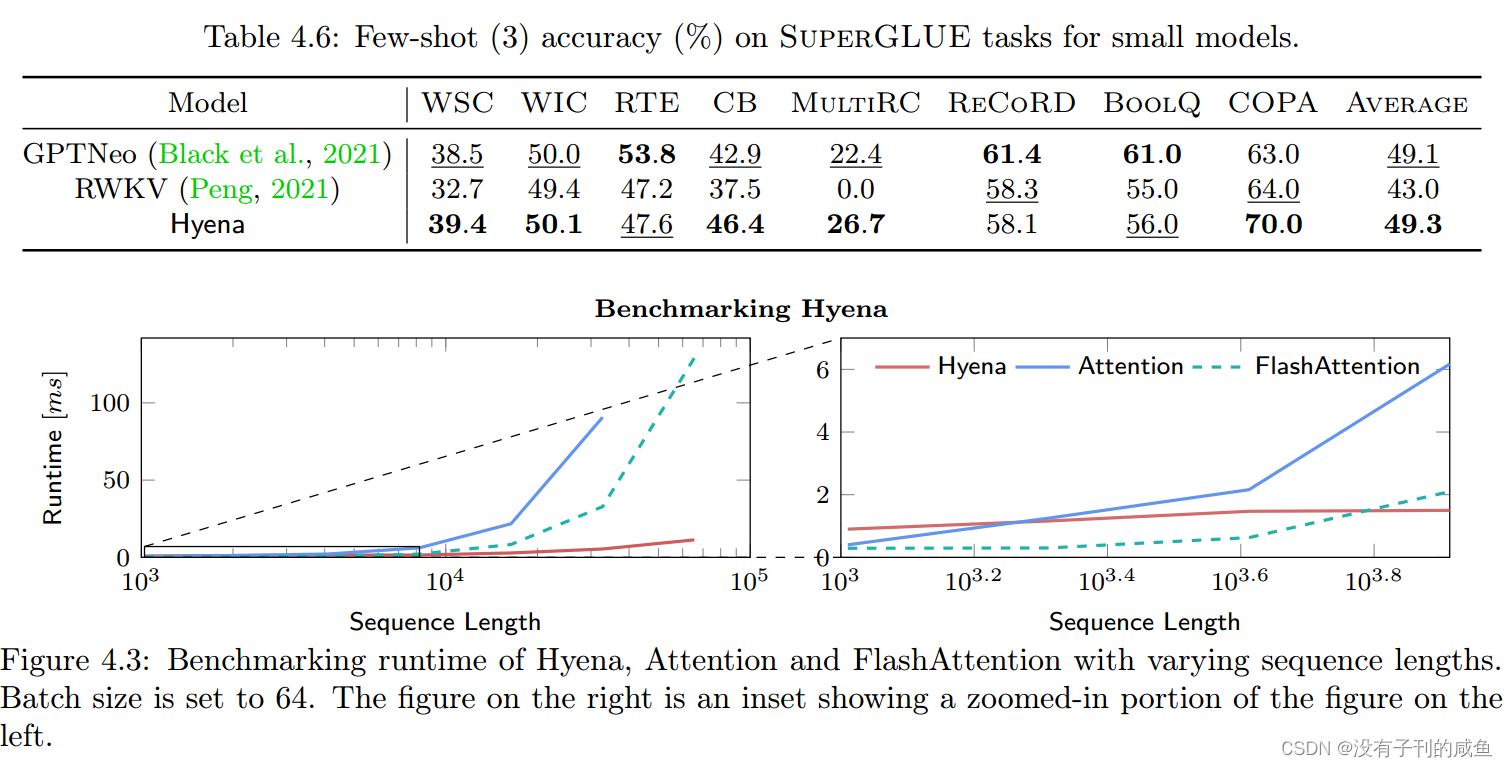
结果




















 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









