






论文阅读笔记(三)——Sequence modeling and design from molecular to genome scale with Evo
目录
摘要
基因组是一个完全编码DNA、RNA和蛋白质的序列,它们协调了整个生物体的功能。机器学习的进步与全基因组的大量数据集相结合,可以实现生物基础模型,加速复杂分子相互作用的机制理解和生成设计。我们报告Evo,一个基因组基础模型,使预测和生成任务从分子到基因组尺度。使用基于深度信号处理的先进架构,我们将Evo扩展到70亿个参数,在单核苷酸,字节分辨率下,上下文长度为131千碱基(kb)。在整个原核生物基因组的训练下,Evo可以概括分子生物学中心法则的三种基本模式,以执行零射击功能预测,与领先的领域特定语言模型竞争或优于它们。Evo在多元素生成任务中也表现出色,我们首次通过生成合成CRISPR-Cas分子复合物和整个转座系统证明了这一点。利用在整个基因组中学习到的信息,Evo还可以在核苷酸分辨率上预测基因的本质,并可以生成长达650 kb的编码丰富序列,比以前的方法长几个数量级。Evo在多模态和多尺度学习方面的进展为提高我们对多层次复杂性生物的理解和控制提供了一条有希望的途径。
简介
受到最近大型语言模型成功的启发,许多当代方法利用自回归变形器来模拟生物序列并捕获这些系统范围的相互作用。然而,现有的尝试将DNA建模为一种语言受到当前密集Transformer架构的限制,随着输入序列长度相对于模型宽度(二次缩放)的增长,计算成本很高,并且通常在单核苷酸或字节级分辨率下表现不佳(与在较粗分辨率下训练的模型相比)。扩展基于注意的模型的上下文长度的最新算法进展也有类似的分辨率限制。因此,基于transformer的DNA模型受限于短上下文长度,并使用将核苷酸聚合到语言模型的基本单位(称为令牌)的方案,从而牺牲单核苷酸分辨率。
在这里,我们提出Evo,一个70亿个参数的基因组基础模型,用于在全基因组规模上生成DNA序列。Evo使用的上下文长度为131k个令牌,基于StripedHyena架构,它混合了注意力和数据控制的卷积算子,以有效地处理和回忆长序列中的模式。Evo在包含3000亿个核苷酸的原核生物全基因组数据集上进行训练,并使用字节级单核苷酸标记器。
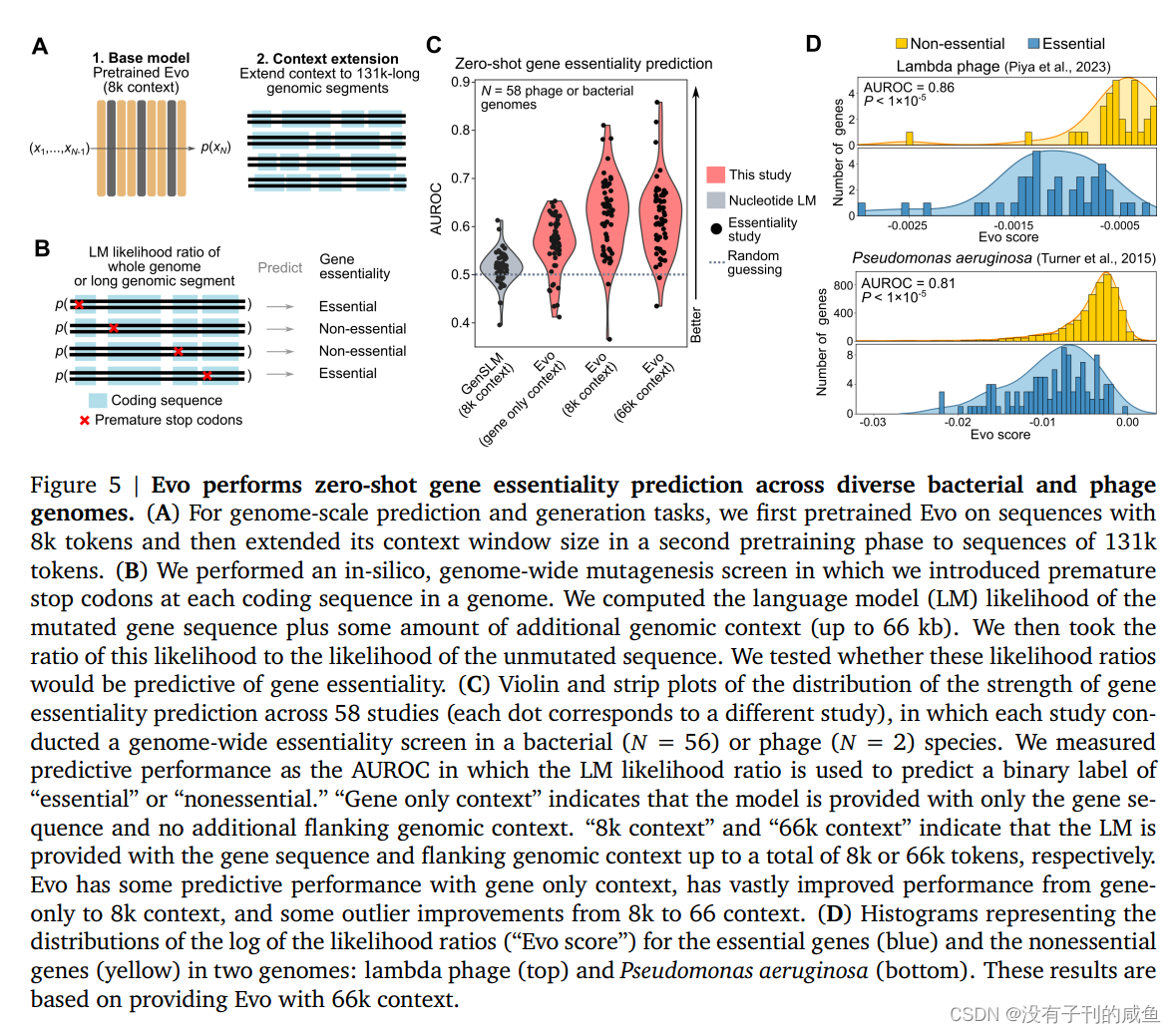
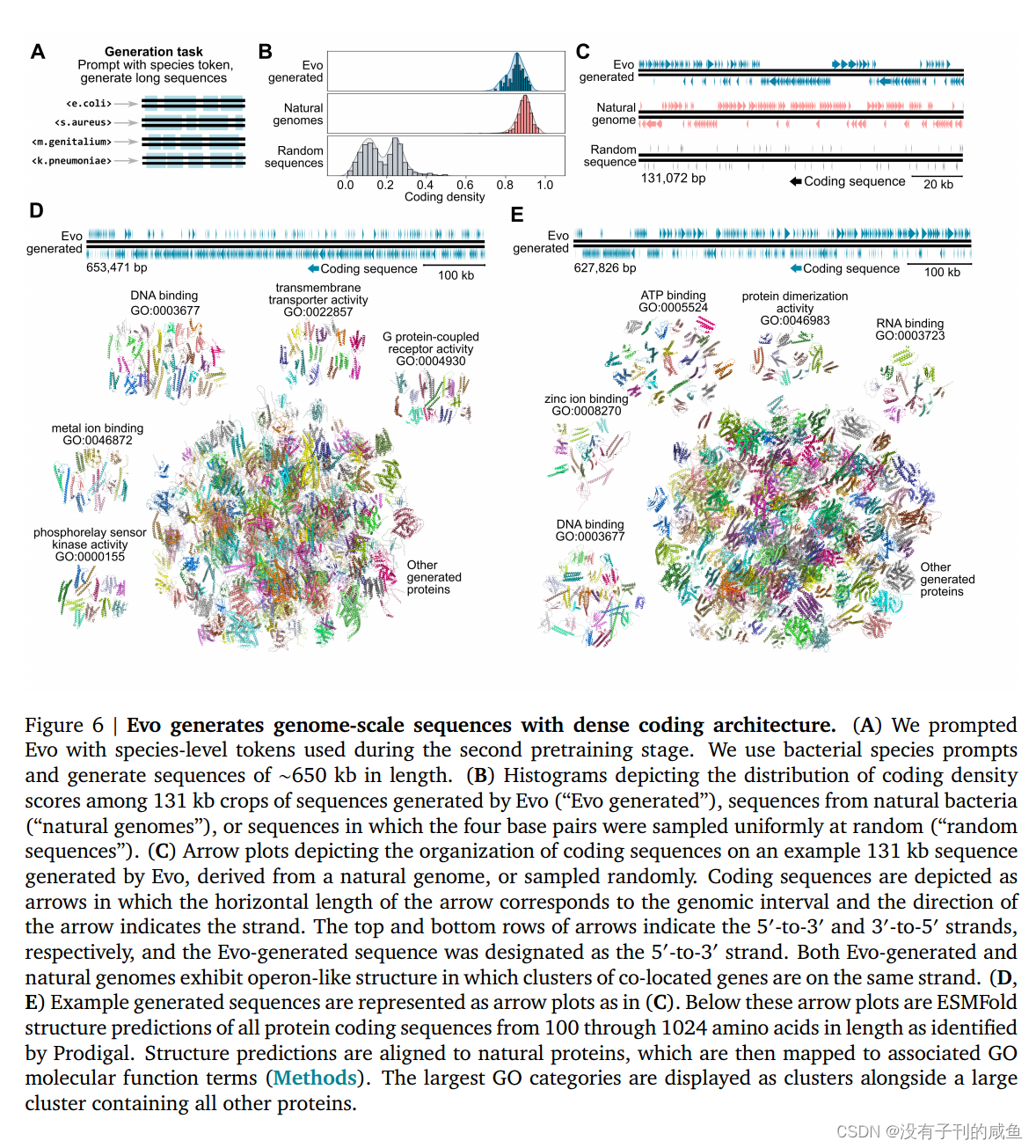
我们证明Evo可以用于分子、系统和基因组尺度上的预测和生成任务。在零shot评估中,Evo在预测突变对大肠杆菌蛋白的适应度效应方面与最先进的蛋白质语言模型相竞争,在预测突变对非编码RNA的适应度效应方面优于专门的RNA语言模型,并预测原核启动子-核糖体结合位点(RBS)对的组合,从而仅从调控序列中导致活性基因表达。超越单分子和短序列,Evo学习编码和非编码序列的共同进化联系,以设计合成多组分生物系统,包括CRISPRCas系统和转座元件。在全基因组范围内,Evo可以在没有任何监督的情况下预测细菌或噬菌体中的基本基因。我们还使用Evo生成超过650千碱基(kb)的序列,具有合理的基因组编码结构,其规模比以前的方法大几个数量级。综上所述,Evo为预测性和生成性生物序列建模建立了基础范式(图1A)。Evo的进一步发展将使我们对生物学有更深入的机械理解,并加速我们设计生命的能力。
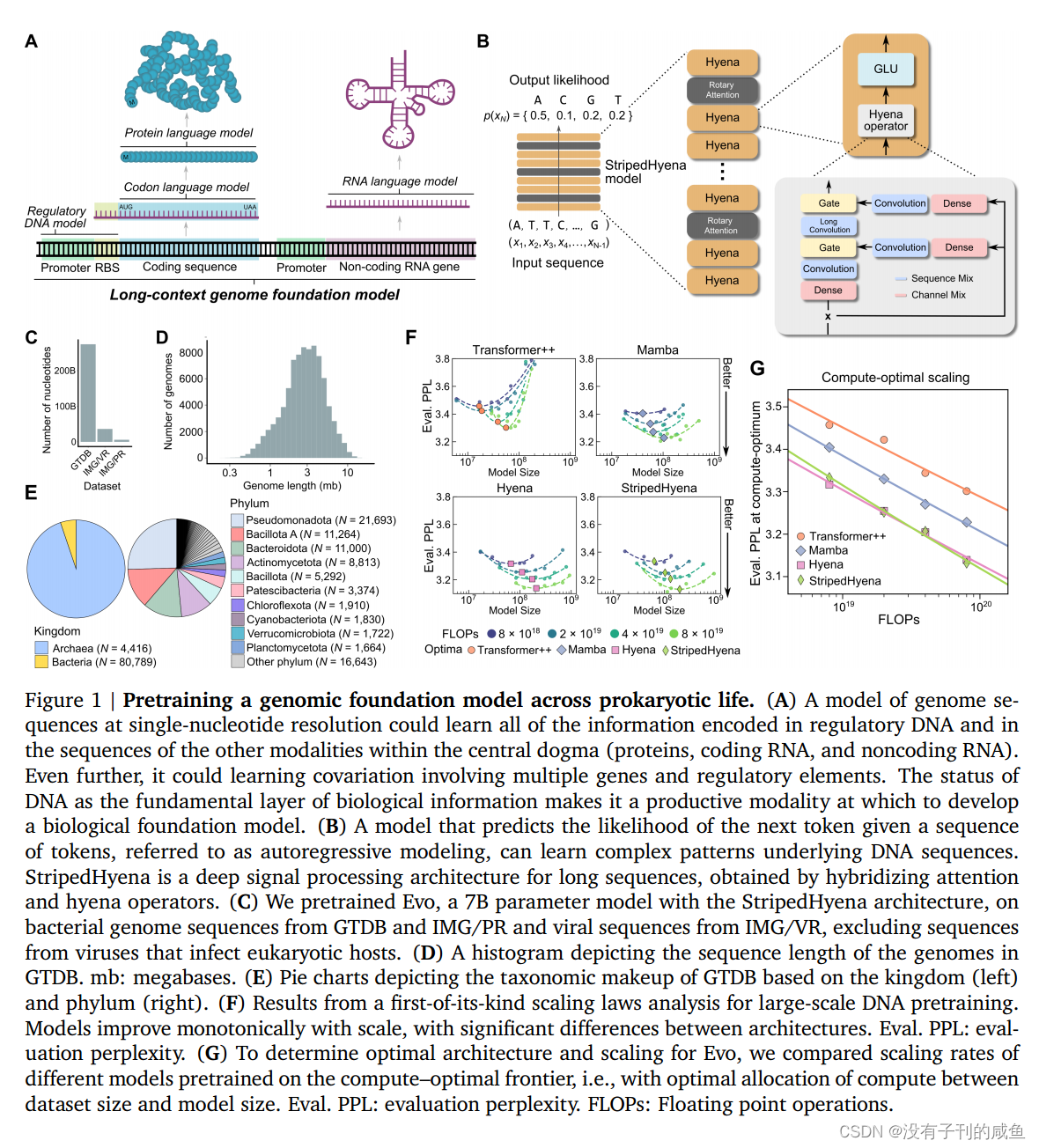
Evo是一个基因组基础模型,使用单核苷酸、字节级标记化,训练了7B个参数,上下文长度高达131k个标记。为了有效地以核苷酸分辨率对长序列进行建模,我们通过生成超过65万个标记的序列来证明这一点,我们利用了StripedHyena架构(图1B),该架构基于深度信号处理中的新兴技术。该模型是由29层数据控制的卷积算子(Hyena层)与3层(10%)配备旋转位置嵌入(RoPE)的多头注意力 (Methods)交织而成。
模型杂交,首次提出是为了解决状态空间模型的缺点最近被证明可以提高独立Hyena和Transformer架构的语言建模的扩展性能。Hyena的设计受益于其每个层类型的专门化,Hyena层实现了大部分的序列处理和注意层所需的位置,补充了从输入上下文中回忆信息的能力。
鬣狗层通过短和长卷积滤波器的组合以输入依赖的方式处理序列(图1B),使得该层在过滤DNA中可能出现的噪声模式和将单个核苷酸聚集成基序方面特别有效。与利用鬣狗架构的上一代DNA模型HyenaDNA 相比, Evo基于改进的混合设计,可扩展到1000倍大的模型尺寸和100倍多的数据。
资源与链接
预训练数据集:
- Bacterial and archaeal genomes from the Genome Taxonomy Database (GTDB) v214.1 (Parks et al, 2015).
- Curated prokaryotic viruses from the IMG/VR v4 database (Camargo et al, 2023).
- Plasmid sequences from the IMG/PR database (Camargo et al, 2024).
微调数据集:
- NCBI RefSeq (O’Leary et al, 2016).
- UHGG (Almeida et al, 2021).
- JGI IMG (Chen et al, 2021).
- The Gut Phage Database (Camarillo-Guerrero et al, 2021).
- The Human Gastrointestinal Bacteria Genome Collection (Forster et al, 2019).
- MGnify (Mitchell et al, 2020).
- Youngblut et al (2020) animal gut metagenomes.
- MGRAST (Meyer et al, 2008).
- Tara Oceans samples (Sunagawa et al, 2015).
第一阶段用64个Nvidia H100 gpu训练Evo,在第二阶段用128个Nvidia A100 gpu训练Evo。Evo总共在大约340B个令牌上进行了训练,使用了大约2×1022个FLOPS。
Method
Evo基于StripedHyena,这是一种用于序列建模的最先进的混合模型架构。Evo包含32个块,模型宽度为4096维。每个块包含一个序列混合层,负责沿序列维度处理信息,以及一个通道混合层,侧重于沿模型宽度维度处理信息。
在序列混合层中,Evo采用了29个hyena layers,以相同的间隔与3个旋转自关注层交错。我们使用中描述的模态规范形式对hyena算子中的卷积进行参数化。对于通道混合层,Evo采用门控线性单元。Evo使用均方根层归一化进一步规范化每一层的输入(Zhang和Sennrich, 2019)。
Hyena layers: Hyena是一种序列混频器,通过短卷积、长卷积和门控的组合实现输入依赖(数据控制)算子(图1B)。鬣狗属于深度信号处理原语,专为大规模序列模型中高效、依赖输入的计算而设计。输入依赖性使由深度信号处理层构建的架构能够根据输入调整计算,从而实现上下文学习。这些层依赖于与快速乘法算法兼容的结构化算子,因此可以在次二次时间内使用例如卷积的快速傅里叶变换进行评估。操作符是隐式参数化的,例如,从位置嵌入或输入学习到操作符参数的映射。隐式参数化的典型选择是线性投影、超网络或模态或伴生形式的线性状态空间模型。Hyena的forward pass的蓝图总结如下。

Self-attention Layers: Transformer模型的核心序列混合算子。自注意将输出序列构建为输入元素的加权组合,其中权重本身依赖于输入。给定一个输入序列,(未归一化)自注意层的前向传递为:
(
q
,
k
,
v
)
↦
A
(
q
,
k
)
v
,
A
(
q
,
k
)
=
softmax
(
q
k
T
)
(q, k, v) \mapsto A(q, k) v, \quad A(q, k)=\operatorname{softmax}\left(q k^{T}\right)
(q,k,v)↦A(q,k)v,A(q,k)=softmax(qkT)
其中查询𝑞∈算子𝐿×𝐷,键𝑘∈算子𝐿×𝐷,值𝑣∈算子𝐿×𝐷是通过输入的线性变换得到的,例如𝑣=𝑢𝑊𝑣。将softmax应用于“变量”的行。查询、键、值术语借用自数据库,其中键用于索引存储的值。从概念上讲,关注矩阵的值(𝑞,𝑘)衡量查询和键之间的相似度,类似于将查询与数据库中的键进行匹配。
Positional embeddings: 就其本身而言,自注意算子对输入序列中输入嵌入的不同位置没有任何概念。出于这个原因,它通常会辅以位置编码机制。StripedHyena的注意层利用旋转位置嵌入机制(RoPE)来模拟相对位置信息。位置信息是通过旋转注意算子的查询和键标记向量来编码的。具体来说,RoPE实现了查询和键的旋转,旋转幅度定义为它们在序列中的相对位置的函数。
为了在第二个预训练阶段将上下文窗口长度从8k扩展到131k,我们应用线性位置插值来扩展在第一个预训练阶段应用的旋转位置嵌入,其序列长度为8k。当应用于比最初训练时更长的序列时,插值使模型能够继续利用其学习到的表示。我们还测试了其他位置插值方法,但发现它们在数据上的表现略差于线性插值。
Tokenization: 在语言建模中,标记描述了模型用来处理语言的语义信息的最小单位。例如,记号可以表示词汇表中的单个单词,甚至可以表示较低级别的语义信息,如单个字符。标记化描述了将这些语义语言单元(如单词或字符)映射到唯一整数值的过程,每个整数值表示查找表中的一个条目。这些整数值通过嵌入层映射到向量,然后由模型以端到端方式处理。Evo使用Python中实现的UTF-8编码,以单核苷酸分辨率对DNA序列进行标记。在预训练期间,Evo使用了四个标记的有效词汇表,每个碱基一个,总词汇表为512个字符。我们使用额外的字符来启用在使用微调模型生成过程中使用特殊令牌的提示。
Code
model.py
import pkgutil
from transformers import AutoConfig, AutoModelForCausalLM
import yaml
from stripedhyena.utils import dotdict
from stripedhyena.model import StripedHyena
from stripedhyena.tokenizer import CharLevelTokenizer
MODEL_NAMES = ['evo-1-8k-base', 'evo-1-131k-base']
class Evo:
def __init__(self, model_name: str = MODEL_NAMES[1], device: str = None):
"""
Loads an Evo model checkpoint given a model name.
If the checkpoint does not exist, we automatically download it from HuggingFace.
"""
self.device = device
# Check model name.
if model_name not in MODEL_NAMES:
raise ValueError(
f'Invalid model name {model_name}. Should be one of: '
f'{", ".join(MODEL_NAMES)}.'
)
# Assign config path.
if model_name == 'evo-1-8k-base':
config_path = 'configs/evo-1-8k-base_inference.yml'
elif model_name == 'evo-1-131k-base':
config_path = 'configs/evo-1-131k-base_inference.yml'
else:
raise ValueError(
f'Invalid model name {model_name}. Should be one of: '
f'{", ".join(MODEL_NAMES)}.'
)
# Load model.
self.model = load_checkpoint(
model_name=model_name,
config_path=config_path,
device=self.device
)
# Load tokenizer.
self.tokenizer = CharLevelTokenizer(512)
HF_MODEL_NAME_MAP = {
'evo-1-8k-base': 'togethercomputer/evo-1-8k-base',
'evo-1-131k-base': 'togethercomputer/evo-1-131k-base',
}
def load_checkpoint(
model_name: str = MODEL_NAMES[1],
config_path: str = 'evo/configs/evo-1-131k-base_inference.yml',
device: str = None,
*args, **kwargs
):
"""
Load checkpoint from HuggingFace and place it into SH model.
"""
# Map model name to HuggingFace model name.
hf_model_name = HF_MODEL_NAME_MAP[model_name]
# Load model config.
model_config = AutoConfig.from_pretrained(hf_model_name, trust_remote_code=True)
model_config.use_cache = True
# Load model.
model = AutoModelForCausalLM.from_pretrained(
hf_model_name,
config=model_config,
trust_remote_code=True,
)
# Load model state dict & cleanup.
state_dict = model.backbone.state_dict()
del model
del model_config
# Load SH config.
config = yaml.safe_load(pkgutil.get_data(__name__, config_path))
global_config = dotdict(config, Loader=yaml.FullLoader)
# Load SH Model.
model = StripedHyena(global_config)
model.load_state_dict(state_dict, strict=True)
model.to_bfloat16_except_poles_residues()
if device is not None:
model = model.to(device)
return model
config.yml
vocab_size: 512
hidden_size: 4096
num_filters: 4096
max_sequence_len: 8192
attn_layer_idxs: [8, 16, 24]
hyena_layer_idxs: [0, 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31]
num_layers: 32
short_filter_length: 3
num_attention_heads: 32
short_filter_bias: True
mlp_init_method: torch.nn.init.zeros_
mlp_output_init_method: torch.nn.init.zeros_
eps: 1.0e-6
state_size: 8
inner_size_multiple_of: 16 # force GLU inner_size to be a multiple of
smeared_gqa: False
make_vocab_size_divisible_by: 8
log_intermediate_values: False
proj_groups: 1 # GQA
hyena_filter_groups: 1
split_k0: True
model_parallel_size: 1
pile_parallel_size: 1
tie_embeddings: True
inner_mlp_size: null # set to None, so it auto-fills
mha_out_proj_bias: True
qkv_proj_bias: True
final_norm: True
rng_fork: False
use_flash_attn: True
use_flash_rmsnorm: False
use_flash_depthwise: False
use_flashfft: False
column_split: True # only affects outputs when proj_groups > 1
inference_mode: True
tokenizer_type: CharLevelTokenizer
prefill_style: fft
mlp_activation: gelu
结果
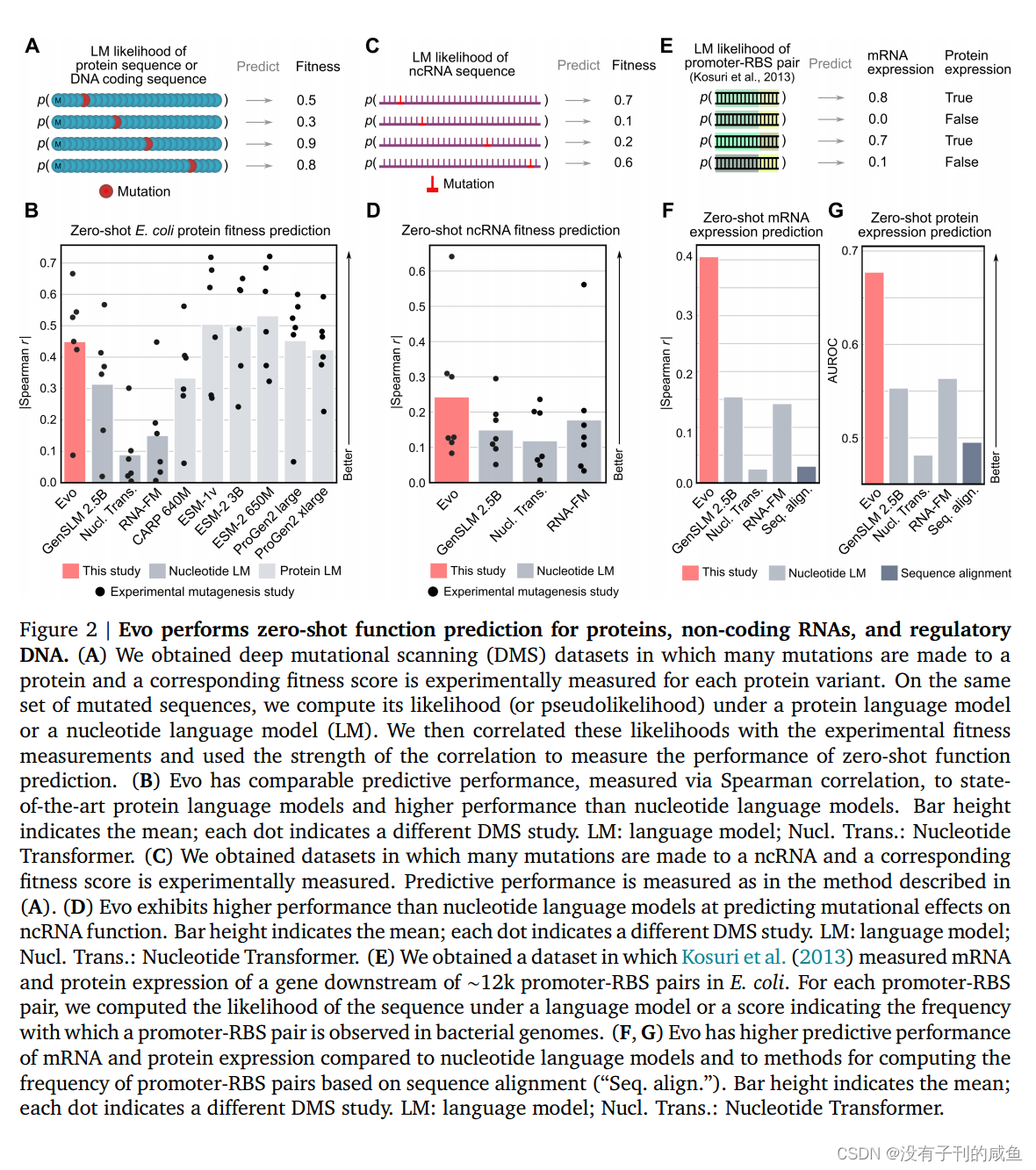
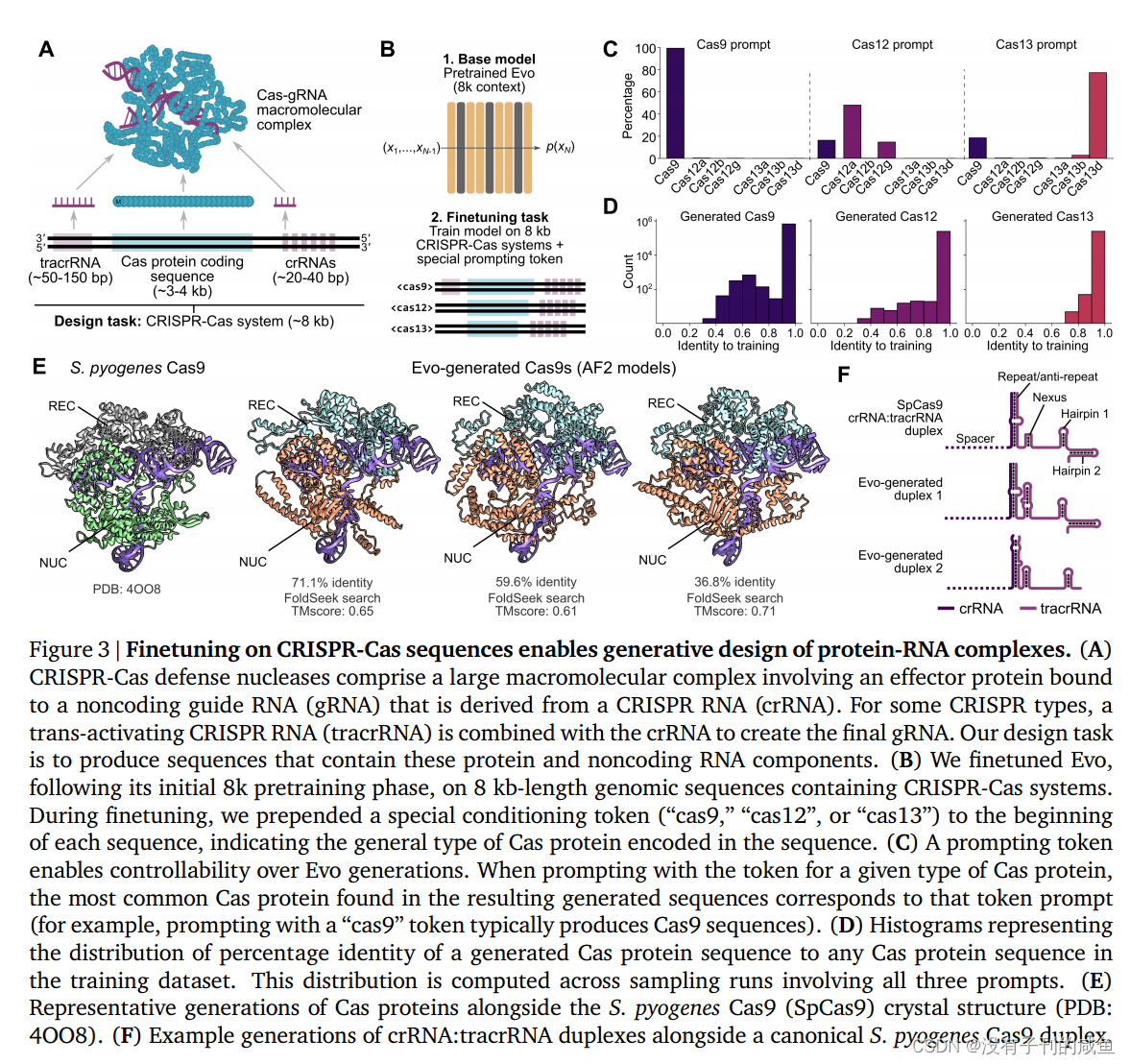
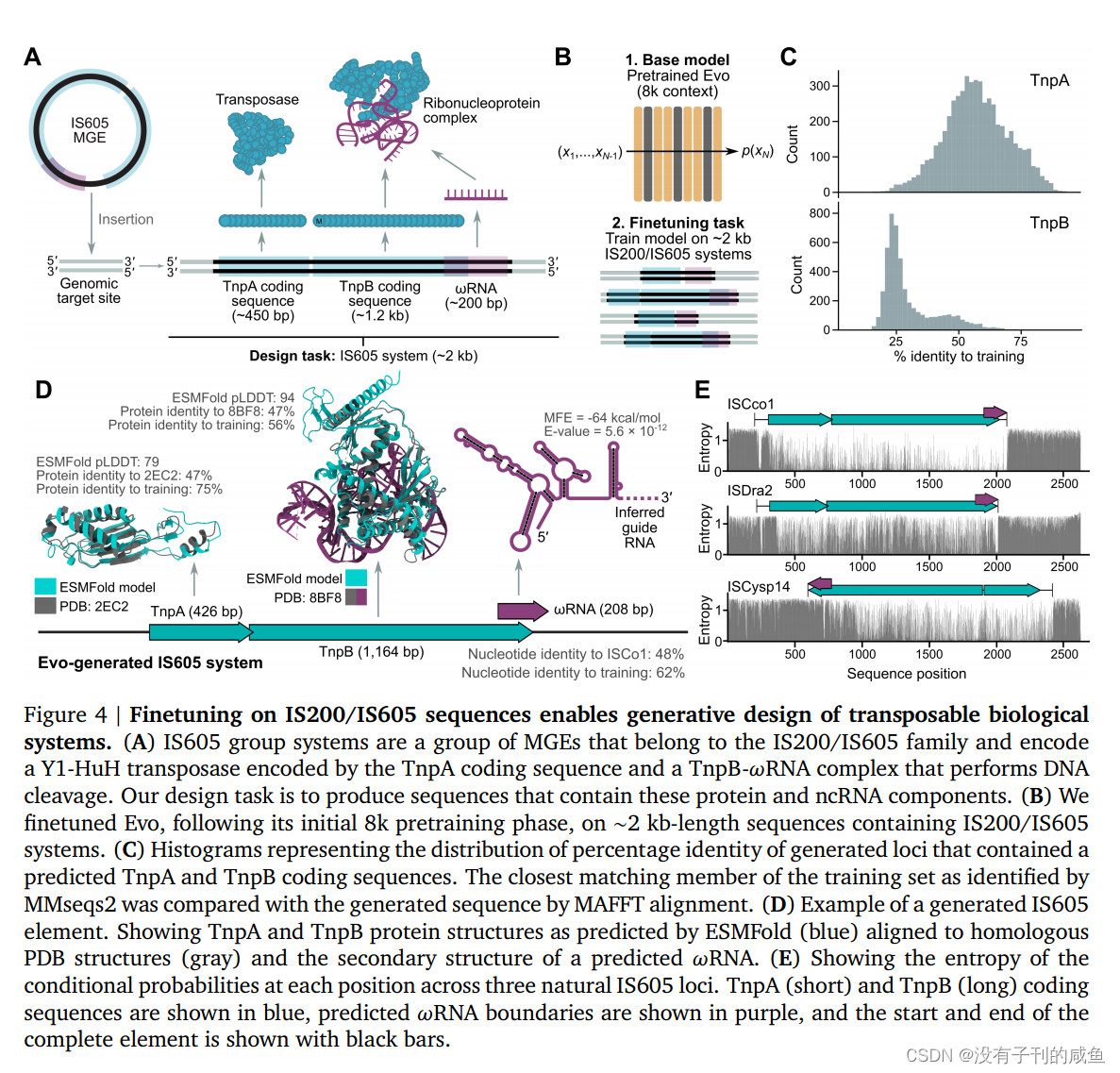

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









