









写在前面
- 看到好多人都在讨论,简单认识一下
- 博文内容涉及 DeepSeek AI 大模型 V3、R1、Janus、VL2 简单介绍以及本地部署
- 理解不足小伙伴帮忙指正 😃,生活加油
“以开源精神和长期主义追求普惠 AGI” 是 DeepSeek 一直以来的坚定信念
持续分享技术干货,感兴趣小伙伴可以关注下 _
关于 DeepSeek 是什么不多讲了,我们直接看模型吧 _
项目地址:
https://github.com/deepseek-ai/
公开的模型地址:
https://huggingface.co/deepseek-ai
DeepSeek-V3 系列
DeepSeek-V3 是 DeepSeek-V2 之后有一个新的版本,一个超大规模的 “混合专家”模型(MoE),671B 参数,激活 37B,在 14.8T token 上进行了预训练。它专为高效训练和推理设计,既能生成高质量文本,又能节省计算资源。用更低的成本(时间和算力)实现顶级性能,对标甚至超越闭源模型(如 GPT-4)。通俗的话讲专注文本任务,规模更大、效率更高,节省资源
项目地址 https://github.com/deepseek-ai/DeepSeek-V3
发布公告: https://api-docs.deepseek.com/zh-cn/news/news1226
用一句话讲 DeepSeek-V3 系列大模型 专注于 文本生成和理解,比如对话、问答、写作、翻译等任务。
在线体验
https://chat.deepseek.com/sign_in
需要注册一个账号,直接问问题就可以

本地部署算力要求
这个需要算力环境,我当前的机器部署不了, 项目的 readme 文件里面也没有写算力要求,而且模型特别大
可以通过 ollama 来部署, 671b 参数 400 多G
PS C:\Users\Administrator> ollama run deepseek-v3
pulling manifest
pulling d83c18fb2a2c... 0% ▕ ▏ 814 MB/404 GB 25 MB/s 4h27m
sglang 的部署 readme 里面有个硬件推荐 8 个 NVIDIA H200 GPU
https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
主要是显存,同时需要考虑模型精度,我在这个 issues 下面看到的算力讨论, DeepSeek-V3 采用 FP8 训练,并开源了原生 FP8 权重。,SGLang 和 LMDeploy 第一时间支持了 V3 模型的原生 FP8 推理,同时 TensorRT-LLM 和 MindIE 则实现了 BF16 推理。同时提供了从 FP8 到 BF16 的转换脚本。
https://github.com/InternLM/lmdeploy/issues/2960
DeepSeekV3 有 671B 个参数,显存要求为:
对于 FP8:~671GB (671B × 1GB/B) ~ 83-84 * 8 = 672
对于 BF16:~1,342GB(671B × 2GB/B)
DeepSeek-V2 版本有个算力要求可以参考,236B 参数,要使用BF16格式的DeepSeek-V2进行推理,需要80GB*8 GPU。
https://github.com/deepseek-ai/DeepSeek-V2?tab=readme-ov-file#8-how-to-run-locally
DeepSeek-R1 系列
DeepSeek-R1 是一个基于强化学习(RL)训练的大型语言模型(LLM), 旨在提高其推理能力 。它通过两个RL阶段和两个监督微调(SFT)阶段进行训练,以发现更好的推理模式并与人类偏好保持一致。此外,DeepSeek-R1还展示了将大型模型的推理模式蒸馏到较小模型的能力,从而获得更好的性能。该项目还开源了DeepSeek-R1-Zero、DeepSeek-R1以及基于Llama和Qwen的6个密集型模型,为研究社区提供支持。
包含以下核心模型:
DeepSeek-R1-Zero:通过纯强化学习(RL)训练的基础模型,无监督微调(SFT)阶段,探索性强但存在输出不稳定问题。DeepSeek-R1:在R1-Zero基础上引入冷启动数据(少量 SFT)优化后的版本,解决输出问题并提升推理能力。DeepSeek-R1-Distill:从R1蒸馏到小型开源模型(如 Qwen、Llama)的轻量级推理模型,性能接近原版但更易部署。
DeepSeek-R1-Zero 和 DeepSeek-R1 基于 DeepSeek-V3-Base 进行训练,DeepSeek-R1-Distill 模型基于开源模型使用 DeepSeek-R1 生成的样本进行微调
项目地址: https://github.com/deepseek-ai/DeepSeek-R1
发布公告: https://api-docs.deepseek.com/zh-cn/news/news250120
用一句话讲 DeepSeek-R1 系列是专注于 复杂推理任务(如数学、代码、逻辑推理)的模型家族
在线体验
https://chat.deepseek.com/sign_in
需要注册一个账号,然后选择 深度思考 R1

本地部署
我当前的机器可以本地部署 DeepSeek-R1-Distill 系列的小模型
DeepSeek-R1-Distill-Qwen-1.5BDeepSeek-R1-Distill-Qwen-7BDeepSeek-R1-Distill-Llama-8BDeepSeek-R1-Distill-Qwen-14BDeepSeek-R1-Distill-Qwen-32BDeepSeek-R1-Distill-Llama-70B
下载 ollama:之后直接安装就可以
安装成功会自动配置环境变量
PS C:\Users\Administrator> ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
PS C:\Users\Administrator>
通过下面的地址选择对应的参数的模型即可:
https://ollama.com/library/deepseek-r1
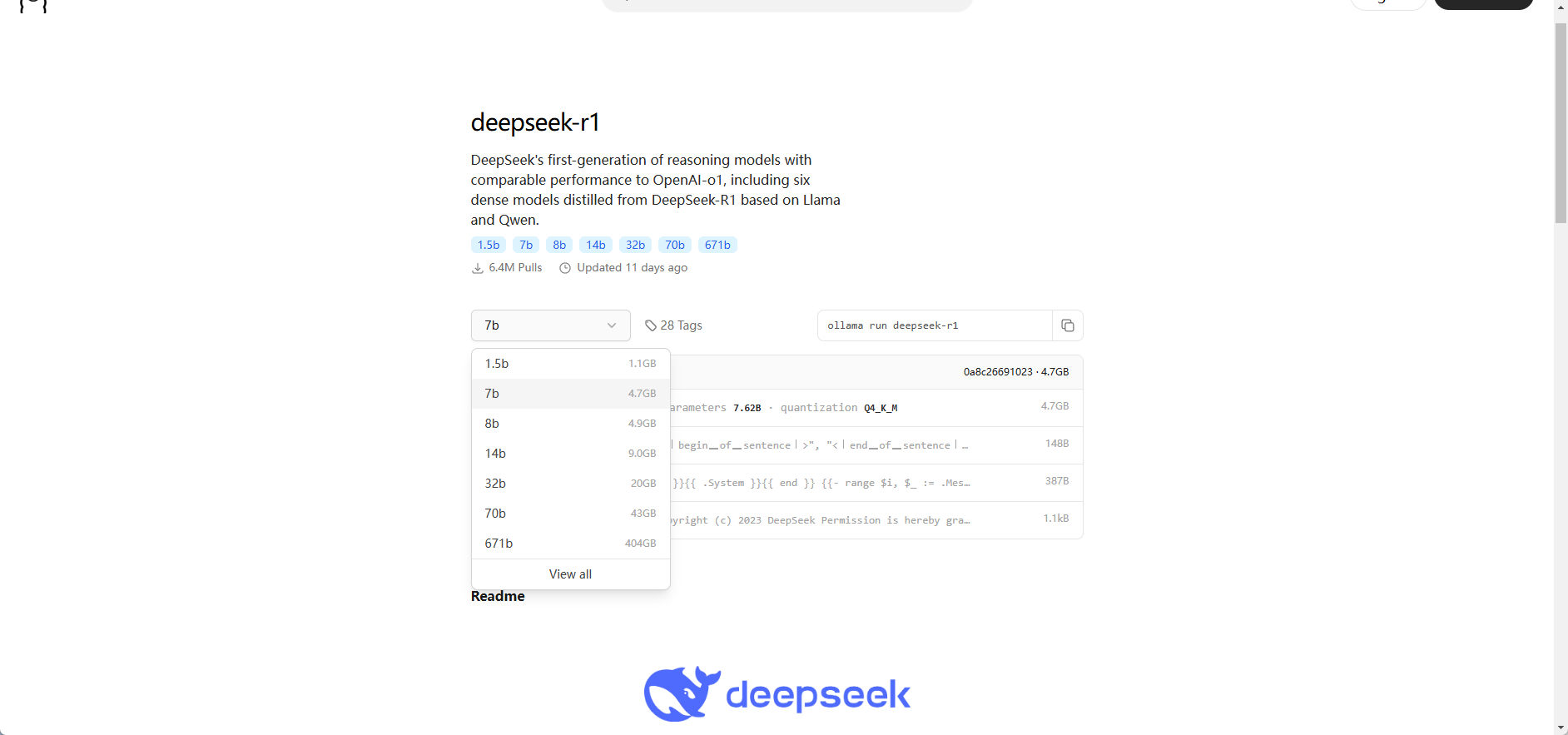
模型下载成功就可以用了,默认会自动下载 DeepSeek-R1-Distill-Qwen-7B 模型
PS C:\Users\Administrator> ollama run deepseek-r1
pulling manifest
pulling 96c415656d37... 100% ▕████████████████████████████████████████████████████████▏ 4.7 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
pulling 40fb844194b2... 100% ▕████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
直接命令行就可以交互了,算一道数学题
PS C:\Users\Administrator> ollama run deepseek-r1
>>> 1+2+3+4+54654+213=?
<think>
To solve the equation \(1 + 2 + 3 + 4 + 54654 + 213\), I will follow these steps:
First, add the numbers from 1 to 4.
Next, add the result to 54654.
Finally, add this sum to 213 to get the final answer.
</think>
To solve the equation \(1 + 2 + 3 + 4 + 54654 + 213\), follow these steps:
1. **Add the numbers from 1 to 4:**
\[
1 + 2 + 3 + 4 = 10
\]
2. **Add this sum to 54654:**
\[
10 + 54654 = 54664
\]
3. **Finally, add the result to 213:**
\[
54664 + 213 = 54877
\]
**Final Answer:**
\boxed{54877}
>>> Send a message
需要面板工具的可以接 Chatbox 或者 open-webui,下面为 open-webui 的项目地址,时间关系,小伙伴可以自行尝试。
https://github.com/open-webui/open-webui
Janus 系列
项目地址: https://github.com/deepseek-ai/Janus
Janus 系列模型都支持文本和图像的多模态任务,既能理解图文内容,也能生成图文内容。它们都采用了一种统一的框架,将多模态理解和生成任务整合到一个模型中,避免了传统方法中需要多个专用模型的复杂性。DeepSeek 将这些模型开源,支持学术界和工业界的研究和应用。
用一句话讲, Janus 系列模型用于,通过图片分析内容生成文字,以及通过文字描述生成图片。
模型简单介绍:
Janus基础版多模态模型,专注于统一多模态理解和生成。通过解耦视觉编码,解决了传统模型中视觉编码器在理解和生成任务中的冲突。简单、灵活且高效,性能优于之前的统一模型,甚至媲美专用模型。适用场景:适合需要同时处理图文理解和生成的任务,比如图像描述生成、视觉问答等。Janus-Pro:Janus 的升级版,性能更强,功能更全面。优化了训练策略。使用了更多的训练数据。模型规模更大(如 Janus-Pro-7B)。在多模态理解和文本到图像的指令跟随能力上有显著提升。生成图像的质量和稳定性更好。适用场景:适合对图文理解和生成要求更高的任务,比如高质量的文本到图像生成、复杂的多模态推理等。JanusFlow: 结合了自回归模型和Rectified Flow(一种先进的生成建模方法)的新模型。使用极简架构,无需复杂的修改即可在大型语言模型框架中训练 Rectified Flow。在生成任务中表现优异,媲美甚至超越专用模型。适用场景:适合需要高质量图像生成和多模态理解的任务,比如艺术创作、设计辅助等。
下面为 最新的模型 Janus-Pro 的在线体验和本地部署Demo
在线体验
https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B

本地部署问题解决
https://github.com/deepseek-ai/Janus?tab=readme-ov-file#janus-pro
直接按照readme文档操作就行,克隆项目,创建虚拟环境,install 依赖,如果需要UI 交互,选择 gradio 版本,然后就会自己下模型
PS C:\Users\Administrator\Documents\GitHub\Janus> pip install -e .[gradio]
Obtaining file:///C:/Users/Administrator/Documents/GitHub/Janus
Installing build dependencies ... done
Checking if build backend supports build_editable ... done
Getting requirements to build editable ... done
Preparing editable metadata (pyproject.toml) ... done
........................
Building wheels for collected packages: janus
Building editable for janus (pyproject.toml) ... done
Created wheel for janus: filename=janus-1.0.0-0.editable-py3-none-any.whl size=16002 sha256=00f8a57fbcefb148efcfd23b83693d260c751b746d7baa5ffa8d17981c908f7c
Stored in directory: D:\Temp\pip-ephem-wheel-cache-k1hkfs8g\wheels\dd\84\9f\ec544ec10f9f6d18b0043de3566fbc47b75c06c5ec8eb88bc1
Successfully built janus
Installing collected packages: janus
Attempting uninstall: janus
Found existing installation: janus 1.0.0
Uninstalling janus-1.0.0:
Successfully uninstalled janus-1.0.0
Successfully installed janus-1.0.0
运行Demo
PS C:\Users\Administrator\Documents\GitHub\Janus> python demo/app_januspro.py
Python version is above 3.10, patching the collections module.
C:\Users\Administrator\Documents\GitHub\Janus\.venv\lib\site-packages\torchvision\datapoints\__init__.py:12: UserWarning: The torchvision.datapoints and torchvision.transforms.v2 namespaces are still Beta. While we do not expect major breaking changes, some APIs may still change according to user feedback. Please submit any feedback you may have in this issue: https://github.com/pytorch/vision/issues/6753, and you can also check out https://github.com/pytorch/vision/issues/7319 to learn more about the APIs that we suspect might involve future changes. You can silence this warning by calling torchvision.disable_beta_transforms_warning().
warnings.warn(_BETA_TRANSFORMS_WARNING)
C:\Users\Administrator\Documents\GitHub\Janus\.venv\lib\site-packages\torchvision\transforms\v2\__init__.py:54: UserWarning: The torchvision.datapoints and torchvision.transforms.v2 namespaces are still Beta. While we do not expect major breaking changes, some APIs may still change according to user feedback. Please submit any feedback you may have in this issue: https://github.com/pytorch/vision/issues/6753, and you can also check out https://github.com/pytorch/vision/issues/7319 to learn more about the APIs that we suspect might involve future changes. You can silence this warning by calling torchvision.disable_beta_transforms_warning().
warnings.warn(_BETA_TRANSFORMS_WARNING)
C:\Users\Administrator\Documents\GitHub\Janus\.venv\lib\site-packages\transformers\models\auto\image_processing_auto.py:590: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.28k/1.28k [00:00<?, ?B/s]
pytorch_model.bin.index.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 89.0k/89.0k [00:00<00:00, 252kB/s]
model.safetensors.index.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 92.8k/92.8k [00:00<00:00, 243kB/s]
pytorch_model-00001-of-00002.bin: 0%| | 10.5M/9.99G [00:02<33:41, 4.94MB/s]
pytorch_model-00001-of-00002.bin: 2%|█▋ | 157M/9.99G [00:13<11:13, 14.6MB/s]
。。。。。。。。。。。。。。。。。。
tokenizer_config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 285/285 [00:00<00:00, 272kB/s]
tokenizer.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.72M/4.72M [00:00<00:00, 7.59MB/s]
special_tokens_map.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 344/344 [00:00<?, ?B/s]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
processor_config.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 210/210 [00:00<?, ?B/s]
Some kwargs in processor config are unused and will not have any effect: ignore_id, add_special_token, num_image_tokens, mask_prompt, image_tag, sft_format.
Running on local URL: http://127.0.0.1:7860
IMPORTANT: You are using gradio version 3.48.0, however version 4.44.1 is available, please upgrade.
--------
Running on public URL: https://8f307516dd497d1b07.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
install 过程需要 VPN ,没有VPN 报下来类似的报错
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like deepseek-ai/Janus-Pro-7B is not the path to a directory containing a file named preprocessor_config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
上传图片识别报错

File "C:\Users\Administrator\Documents\GitHub\Janus\demo\app_januspro.py", line 58, in multimodal_understanding
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
File "C:\Users\Administrator\Documents\GitHub\Janus\janus\models\modeling_vlm.py", line 246, in prepare_inputs_embeds
images_embeds = self.aligner(self.vision_model(images))
。。。。。。。。。。。。。。。。。。。。。。。。。
RuntimeError: "slow_conv2d_cpu" not implemented for 'Half'
这个 issues 下面有解决办法
https://github.com/deepseek-ai/Janus/issues/121
确认下使用的CPU 还是GPU
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("使用了那个: ",cuda_device)
GPU 修改
如果用 GPU 跑,需要重新install GPU 的 torch。需要注意低版本不支持 float16
PS C:\Users\Administrator\Documents\GitHub\Janus> pip uninstall torch
WARNING: Skipping torch as it is not installed.
PS C:\Users\Administrator\Documents\GitHub\Janus> pip install torch==2.2.2+cu118 --index-url https://download.pytorch.org/whl/cu118
Looking in indexes: https://download.pytorch.org/whl/cu118
Collecting torch==2.2.2+cu118
Downloading https://download.pytorch.org/whl/cu118/torch-2.2.2%2Bcu118-cp310-cp310-win_amd64.whl (2704.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.7/2.7 GB 10.1 MB/s eta 0:00:00
GPU 我的机器需要 30 秒左右


CPU 修改
如果没有显卡,只用 CPU 跑,需要修改这两个地方
if torch.cuda.is_available():
#vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
vl_gpt = vl_gpt.to(torch.bfloat32).cuda()
else:
#vl_gpt = vl_gpt.to(torch.float16)
vl_gpt = vl_gpt.to(torch.float32)
pil_images = [Image.fromarray(image)]
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
#).to(cuda_device, dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float16)
).to(cuda_device, dtype=torch.bfloat32 if torch.cuda.is_available() else torch.float32)
CPU 超级慢,下面的分析用了 200 多秒,但是内容更多,应该和精度有关系

DeepSeek-VL2 系列
DeepSeek-VL2 是一个大型混合专家(MoE)视觉语言模型系列,显著改进了其前身DeepSeek-VL。DeepSeek-VL2在各种任务中表现出色,包括但不限于视觉问答、光学字符识别、文档/表格/图表理解和视觉定位。
项目地址:
https://github.com/deepseek-ai/DeepSeek-VL2
用一句话讲,DeepSeek-VL2 用于处理视觉问答、光学字符识别和文档理解等任务
该模型系列包括三个变体:
DeepSeek-VL2-Tiny: 10亿 个激活参数DeepSeek-VL2-Small: 28亿个激活参数DeepSeek-VL2,45亿个激活参数
需要80GB GPU内存才能使用 deepseek-vl2-small 运行,对于 deepseek-vl2,可能需要更大的内存。与现有的开源密集型和基于MoE的模型相比,DeepSeek-VL2在性能上具有竞争力或达到最先进水平,同时使用的激活参数更少或相当。
DeepSeek-VL2 没有找到对应的在线体验版本
本地部署
这里尝试着部署 DeepSeek-VL2-Tiny, 直接按照readme文档操作就行,克隆项目,创建虚拟环境,install 依赖,如果需要UI 交互,选择 gradio 版本,然后就会自己下模型
目前只支持 GPU 部署
PS C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2> pip install -e .[gradio]
然后根据 显存大小选择合适的命令
# vl2-tiny, 3.37B-MoE in total, activated 1B, can be run on a single GPU < 40GB
CUDA_VISIBLE_DEVICES=2 python web_demo.py \
--model_name "deepseek-ai/deepseek-vl2-tiny" \
--port 37914
# vl2-small, 16.1B-MoE in total, activated 2.4B
# If run on A100 40GB GPU, you need to set the `--chunk_size 512` for incremental prefilling for saving memory and it might be slow.
# If run on > 40GB GPU, you can ignore the `--chunk_size 512` for faster response.
CUDA_VISIBLE_DEVICES=2 python web_demo.py \
--model_name "deepseek-ai/deepseek-vl2-small" \
--port 37914 \
--chunk_size 512
# # vl27.5-MoE in total, activated 4.2B
CUDA_VISIBLE_DEVICES=2 python web_demo.py \
--model_name "deepseek-ai/deepseek-vl2" \
--port 37914
第一次执行
PS C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2> python web_demo.py --model_name "deepseek-ai/deepseek-vl2-tiny" --port 37914
Python version is above 3.10, patching the collections module.
C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torchvision\io\image.py:13: UserWarning: Failed to load image Python extension: '[WinError 127] 找不到指定的程序。'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for:
PyTorch 2.6.0+cu124 with CUDA 1204 (you have 2.6.0+cpu)
Python 3.10.11 (you have 3.10.11)
Please reinstall xformers (see https://github.com/facebookresearch/xformers#installing-xformers)
Memory-efficient attention, SwiGLU, sparse and more won't be available.
Set XFORMERS_MORE_DETAILS=1 for more details
deepseek-ai/deepseek-vl2-tiny is loading...
C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\huggingface_hub\file_download.py:795: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 165k/165k [00:00<00:00, 412kB/s]
tokenizer.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6.27M/6.27M [00:01<00:00, 6.26MB/s]
special_tokens_map.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 801/801 [00:00<?, ?B/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
processor_config.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.23k/1.23k [00:00<?, ?B/s]
Add pad token = ['<|▁pad▁|>'] to the tokenizer
<|▁pad▁|>:2
Add image token = ['<image>'] to the tokenizer
<image>:128815
Add grounding-related tokens = ['<|ref|>', '<|/ref|>', '<|det|>', '<|/det|>', '<|grounding|>'] to the tokenizer with input_ids
<|ref|>:128816
<|/ref|>:128817
<|det|>:128818
<|/det|>:128819
<|grounding|>:128820
Add chat tokens = ['<|User|>', '<|Assistant|>'] to the tokenizer with input_ids
<|User|>:128821
<|Assistant|>:128822
config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.29k/2.29k [00:00<00:00, 2.29MB/s]
model.safetensors.index.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 247k/247k [00:00<00:00, 5.26MB/s]
Downloading shards: 0%| | 0/1 [00:00<?, ?it/s]
model-00001-of-000001.safetensors: 11%|█████████████████████
如果报 cuda 相关的错,类似下面这边,需要下载对应的版本的 torch
Traceback (most recent call last):
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\web_demo.py", line 662, in <module>
demo = build_demo(args)
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\web_demo.py", line 471, in build_demo
fetch_model(args.model_name)
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\web_demo.py", line 143, in fetch_model
DEPLOY_MODELS[model_name] = load_model(model_path, dtype=dtype)
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\deepseek_vl2\serve\inference.py", line 44, in load_model
vl_gpt = vl_gpt.cuda().eval()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\modeling_utils.py", line 2528, in cuda
return super().cuda(*args, **kwargs)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1053, in cuda
return self._apply(lambda t: t.cuda(device))
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 903, in _apply
module._apply(fn)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 903, in _apply
module._apply(fn)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 903, in _apply
module._apply(fn)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 930, in _apply
param_applied = fn(param)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1053, in <lambda>
return self._apply(lambda t: t.cuda(device))
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\cuda\__init__.py", line 310, in _lazy_init
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
PS C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2>
安照提示下载对应的版本
先卸载,在安装
PS C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2> pip uninstall torch torchvision torchaudio
>> pip install torch==2.6.0+cu124 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
再次运行,会报文件不存在的报错。
PS C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2> python web_demo.py --model_name "deepseek-ai/deepseek-vl2-tiny" --port 37914
Python version is above 3.10, patching the collections module.
A matching Triton is not available, some optimizations will not be enabled
。。。。。。。。。。。。。。。。。。。。。。
Load deepseek-ai/deepseek-vl2-tiny successfully...
IMPORTANT: You are using gradio version 3.48.0, however version 4.44.1 is available, please upgrade.
--------
Traceback (most recent call last):
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\web_demo.py", line 662, in <module>
demo = build_demo(args)
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\web_demo.py", line 582, in build_demo
examples=format_examples(examples_list),
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\web_demo.py", line 577, in format_examples
examples.append([images, display_example(images), texts])
File "C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2\deepseek_vl2\serve\app_modules\utils.py", line 319, in display_example
image = Image.open(img_path)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\PIL\Image.py", line 3431, in open
fp = builtins.open(filename, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\Administrator\\Documents\\GitHub\\DeepSeek-VL2\\images\\mi_2.jpeg'
找到对应的 Demo 文件,发现路径不对,需要修改一下
# multi-images
[
[
"images/multi_image_1.jpeg",
"images/mi_2.jpeg",
"images/mi_3.jpeg"
],
"能帮我用这几个食材做一道菜吗?",
]
更正为:
# multi-images
[
[
"images/multi_image_1.jpeg",
"images/multi_image_2.jpeg",
"images/multi_image_3.jpeg"
],
"能帮我用这几个食材做一道菜吗?",
]
重新运行,面板启动了
PS C:\Users\Administrator\Documents\GitHub\DeepSeek-VL2> python web_demo.py --model_name "deepseek-ai/deepseek-vl2-tiny" --port 37914
.............................
Load deepseek-ai/deepseek-vl2-tiny successfully...
IMPORTANT: You are using gradio version 3.48.0, however version 4.44.1 is available, please upgrade.
--------
Reloading javascript...
Running on local URL: http://0.0.0.0:37914
Running on public URL: https://55c3f30e0730a00cc1.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
浏览器访问

用一个 Demo 试一下,上传一张图片,找出后面的长颈鹿

相对来说时间蛮快的,关于 deepseek 的大模型基本认知分析到这里,我的机器配置,Windows 11 + RTX 3060 12G + i7-12700 + 64G
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 😃
https://github.com/deepseek-ai/
© 2018-至今 liruilonger@gmail.com, 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)



















 1821
1821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











