







变分自编码器VAE
首先,部分内容来自于LLM回答(我主要用GPT4和通义千问),如有错误、不当,希望大家指出并一起讨论学习!
VAE 是一种生成模型,它由编码器(encoder)和解码器(decoder)组成。编码器将输入数据映射到潜在空间(latent space),解码器则从潜在空间重建数据。VAE 通过引入概率模型来学习数据的分布。
主要步骤包括:
- 编码(Encoding):将输入数据编码为潜在变量的分布参数(均值和对数方差)。
- 重参数化技巧(Reparameterization Trick):从潜在变量的分布中采样。
- 解码(Decoding):将采样得到的潜在变量解码为重建数据。
建议参考博客,对应b站视频
其实际的思想与数学原理非常复杂,感觉学完了还是一知半解,只有大概的理解,所以如果数学基础比较差或者看完还无法理解的就直接去看代码吧,搞清楚网络的输入输出以及对应loss想要优化的方向就可以。
个人理解:vae与普通ae的区别就是vae要做到生成的功能就需要去修改两个点:
1.生成是生成随机的,"未知"的东西,而不是简单的比如图片像素重建这种有确切的生成label的任务。(也就是无监督)
2.能否做到条件生成或者叫控制生成,也就是现在的比如文生图、图生图,生成我们所需的结果。
因此vae希望encoder学习的是图片在潜在空间的分布,我们可以通过在这个分布里采样,然后让encoder去encode采样的结果来生成最终的结果。但实际数据在潜在空间是什么分布,是完全不知道的。既然如此,我们就假设图片在潜在空间的分布是高斯分布(或者说让encoder学习把图片的特征往潜在空间高斯分布映射),因此基本的网络构造以及优化的方向就有了。
Open-Sora Vae
为啥要用Vae
首先,需要讲一下为什么Open-Sora要使用vae,如果对stable diffusion有了解,这块可以跳过。
如果去参加这种文生图or生成视频岗位的面试,相信会有面试官问到:stable diffusion为什么能够火起来,它与diffusion模型的差异在哪?又或者diffusion模型所需的计算资源是非常巨大的,stable diffusion是如何解决这个问题,让sd可以面向个人用户私有化部署的?
以 SD为例,大概了解一下vae在SD中起到的作用:
- 图像编码和解码
VAE 模块用于将高分辨率图像编码为低维的潜在空间表示,并将潜在表示解码回图像。这对于生成模型非常重要,因为在潜在空间中进行操作(如插值、采样)更加高效。高分辨率图像通常具有大量的像素,直接在这些高维数据上进行操作会非常困难和计算量大。通过 VAE,将图像压缩到低维潜在空间表示,这样可以大大减少计算量,提高训练和推理的效率。 - 潜在空间操作
VAE 引入了概率模型,通过最大化证据下界(ELBO)来训练模型,从而使得生成的图像更加多样化和逼真。此外,VAE 可以帮助模型学习到图像的分布,使得生成的图像更加符合数据的真实分布。通过 VAE,将图像映射到潜在空间中,可以在潜在空间中进行各种操作,如插值、样本生成等。这在图像编辑、风格迁移等任务中非常有用。(我记得sd对于生图的条件控制主要是通过cross-attention来做的吧)
code code code! 还是**的code!
首先来直接看一下他们的vae.py吧,虽然不太确定这个学习顺序对不对,但是快开始看吧!
该文件主要是几个模块,我们分模块来学习。
vae.py
首先看到最下面,这里实际上就是他的主模块:
@MODELS.register_module() # vae模块也要用MODELS注册器注册
def OpenSoraVAE_V1_2( # 一些基本参数在report里也有介绍了
micro_batch_size=4, # 中间的batch-size
micro_frame_size=17, # frame长度
from_pretrained=None,
local_files_only=False,
freeze_vae_2d=False, # 是否冻结vae-2d
cal_loss=False,
force_huggingface=False,
):
# 两个字典描述两个vae的相关信息
vae_2d = dict(
type="VideoAutoencoderKL",
from_pretrained="PixArt-alpha/pixart_sigma_sdxlvae_T5_diffusers",
subfolder="vae",
micro_batch_size=micro_batch_size,
local_files_only=local_files_only,
)
vae_temporal = dict(
type="VAE_Temporal_SD",
from_pretrained=None,
)
shift = (-0.10, 0.34, 0.27, 0.98)
scale = (3.85, 2.32, 2.33, 3.06)
# 构建模型的参数字典
kwargs = dict(
vae_2d=vae_2d,
vae_temporal=vae_temporal,
freeze_vae_2d=freeze_vae_2d,
cal_loss=cal_loss,
micro_frame_size=micro_frame_size,
shift=shift,
scale=scale,
)
# 重点实际上是VideoAutoencoderPipeline
if force_huggingface or (from_pretrained is not None and not os.path.exists(from_pretrained)):
model = VideoAutoencoderPipeline.from_pretrained(from_pretrained, **kwargs)
else:
config = VideoAutoencoderPipelineConfig(**kwargs)
model = VideoAutoencoderPipeline(config)
if from_pretrained:
load_checkpoint(model, from_pretrained)
return model
看这个名称OpenSoraVAE_V1_2,应该是opensora里要用的vae模块了,但这里主要是构建过程,再深入一些看,重点应该是VideoAutoencoderPipeline。
这个VideoAutoencoderPipeline继承自PreTrainedModel,该类是从transformer导入的,我们目前先学习Pipeline用到PreTrainedModel的一些方法就好。
class VideoAutoencoderPipelineConfig(PretrainedConfig):
model_type = "VideoAutoencoderPipeline"
# 就是初始化一个PipelineConfig,后面用于Pipeline的初始化
def __init__(
self,
vae_2d=None,
vae_temporal=None,
from_pretrained=None,
freeze_vae_2d=False,
cal_loss=False,
micro_frame_size=None,
shift=0.0,
scale=1.0,
**kwargs,
):
self.vae_2d = vae_2d
self.vae_temporal = vae_temporal
self.from_pretrained = from_pretrained
self.freeze_vae_2d = freeze_vae_2d
self.cal_loss = cal_loss
self.micro_frame_size = micro_frame_size
self.shift = shift
self.scale = scale
super().__init__(**kwargs)
class VideoAutoencoderPipeline(PreTrainedModel):
# 这里就是初始化config
config_class = VideoAutoencoderPipelineConfig
def __init__(self, config: VideoAutoencoderPipelineConfig):
super().__init__(config=config)
# Pipeline需要构建两个vae的模块
self.spatial_vae = build_module(config.vae_2d, MODELS)
self.temporal_vae = build_module(config.vae_temporal, MODELS)
self.cal_loss = config.cal_loss
self.micro_frame_size = config.micro_frame_size
self.micro_z_frame_size = self.temporal_vae.get_latent_size([config.micro_frame_size, None, None])[0]
# 是否需要冻结vae_2d的参数进行训练
if config.freeze_vae_2d:
for param in self.spatial_vae.parameters():
param.requires_grad = False
self.out_channels = self.temporal_vae.out_channels
# normalization parameters
scale = torch.tensor(config.scale)
shift = torch.tensor(config.shift)
if len(scale.shape) > 0:
scale = scale[None, :, None, None, None]
if len(shift.shape) > 0:
shift = shift[None, :, None, None, None]
# 这里这个方法似乎就来自PreTrainedModel,但我查了一下该方法是pytorch提供的
# 用于注册一个持久的缓冲区(buffer),这些缓冲区不会被视为模型的参数(即不会在调用 model.parameters() 时返回),但仍然会随模型一起保存和加载。
# 我理解是让你有一块地方用来保存一些参数,并且该参数并不会随着模型参数更新迭代
self.register_buffer("scale", scale)
self.register_buffer("shift", shift)
def encode(self, x):
# 首先是那个2dvae做encode
x_z = self.spatial_vae.encode(x)
# 根据micro_frame_size参数来决定分段去做vae的encode
if self.micro_frame_size is None:
# 不分就用temporal_vae直接encode
posterior = self.temporal_vae.encode(x_z)
# z应该就是encode后分布的采样
z = posterior.sample()
else:
# 分段就根据micro_frame_size去做一段一段做encode
z_list = []
for i in range(0, x_z.shape[2], self.micro_frame_size):
x_z_bs = x_z[:, :, i : i + self.micro_frame_size]
posterior = self.temporal_vae.encode(x_z_bs)
z_list.append(posterior.sample())
# 最后把sample的结果cat起来就ok
z = torch.cat(z_list, dim=2)
# 根据计算loss来看return什么
if self.cal_loss:
# 比较奇怪的一点是如果分段做temporal_vae的encode,posterior不是只有每段序列最后一段吗?
return z, posterior, x_z
else:
return (z - self.shift) / self.scale
def decode(self, z, num_frames=None):
# 首先就是反标准化回来
if not self.cal_loss:
z = z * self.scale.to(z.dtype) + self.shift.to(z.dtype)
# 跟encode一样,看看是否需要分段decode了
if self.micro_frame_size is None:
x_z = self.temporal_vae.decode(z, num_frames=num_frames)
x = self.spatial_vae.decode(x_z)
else:
x_z_list = []
for i in range(0, z.size(2), self.micro_z_frame_size):
z_bs = z[:, :, i : i + self.micro_z_frame_size]
x_z_bs = self.temporal_vae.decode(z_bs, num_frames=min(self.micro_frame_size, num_frames))
x_z_list.append(x_z_bs)
num_frames -= self.micro_frame_size
x_z = torch.cat(x_z_list, dim=2)
x = self.spatial_vae.decode(x_z)
# 与encode类似,再往后看
if self.cal_loss:
return x, x_z
else:
return x
def forward(self, x):
# forward没什么多说的,只是这个cal_loss很让人在意
assert self.cal_loss, "This method is only available when cal_loss is True"
z, posterior, x_z = self.encode(x)
x_rec, x_z_rec = self.decode(z, num_frames=x_z.shape[2])
return x_rec, x_z_rec, z, posterior, x_z
def get_latent_size(self, input_size):
# 看方法名称是获取潜在空间的size,看实现主要是两个vae自带的方法
# 这里也是根据是否分段来计算latent size
if self.micro_frame_size is None or input_size[0] is None:
return self.temporal_vae.get_latent_size(self.spatial_vae.get_latent_size(input_size))
else:
sub_input_size = [self.micro_frame_size, input_size[1], input_size[2]]
sub_latent_size = self.temporal_vae.get_latent_size(self.spatial_vae.get_latent_size(sub_input_size))
sub_latent_size[0] = sub_latent_size[0] * (input_size[0] // self.micro_frame_size)
remain_temporal_size = [input_size[0] % self.micro_frame_size, None, None]
if remain_temporal_size[0] > 0:
remain_size = self.temporal_vae.get_latent_size(remain_temporal_size)
sub_latent_size[0] += remain_size[0]
return sub_latent_size
# 获取temporal_vae.decoder.conv_out.conv的权重
def get_temporal_last_layer(self):
return self.temporal_vae.decoder.conv_out.conv.weight
# 通过@property定义device和dtype方法,使其变为class的一个属性
# 调用时相当于获取pipeline目前的device是在cuda还是cpu,以及dtype是什么
@property
def device(self):
return next(self.parameters()).device
@property
def dtype(self):
return next(self.parameters()).dtype
@property值得细学的地方也有很多,它不仅能使一个类方法变为属性,还能对该属性进一步装饰,使其可以从外部修改、删除等等。
继续套娃,可以看到pipeline看完,还是没太多东西,主要是cal_loss和micro_frame_size让人在意,那么继续看套娃的里面。在主模块中的两个vae的dict我们可以看到一个vae是VideoAutoencoderKL,另一个是VAE_Temporal_SD。VideoAutoencoderKL好像就在我们当前这个文件里,VAE_Temporal_SD不在,那我们就再看VideoAutoencoderKL。
# 对应2d-vae的dict来看该模块,看看其初始化使用了什么参数
# vae_2d = dict(
# type="VideoAutoencoderKL",
# from_pretrained="PixArt-alpha/pixart_sigma_sdxlvae_T5_diffusers",
# subfolder="vae",
# micro_batch_size=micro_batch_size,
# local_files_only=local_files_only,
# )
@MODELS.register_module()
class VideoAutoencoderKL(nn.Module):
def __init__(
self, from_pretrained=None, micro_batch_size=None, cache_dir=None, local_files_only=False, subfolder=None
):
super().__init__()
# 可以发现主模块来自于diffusers.models
# 简单看一下后面的encode,发现也使用了一些diffusers.models的AutoencoderKL自己的方法
self.module = AutoencoderKL.from_pretrained(
from_pretrained,
cache_dir=cache_dir,
local_files_only=local_files_only,
subfolder=subfolder,
)
self.out_channels = self.module.config.latent_channels
self.patch_size = (1, 8, 8)
self.micro_batch_size = micro_batch_size
又是套娃,从这里可以看到2dvae的模型来自于diffusers.models的AutoencoderKL,并且加载的是PixArt-alpha/pixart_sigma_sdxlvae_T5_diffusers权重,看来需要进一步调研看看。
PixArt-alpha
PixArt-alpha是华为的团队出品的自动作画模型,可以学习、了解的链接也不少,我这里就不详细介绍了,就贴张图吧。
论文地址
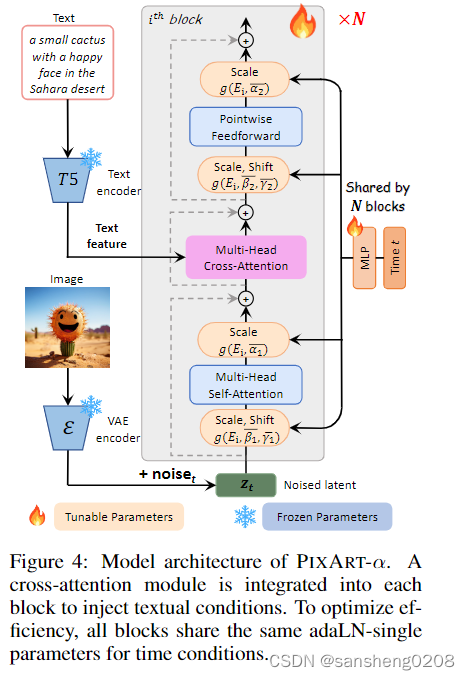
那么不看太多,直接去找他们的vae代码,我猜测也是直接用的diffusers.models的AutoencoderKL搭的,这里是他们的git地址
看了一下,发现他们的vae实际上在这里,仍然是直接用的from diffusers.models import AutoencoderKL,只不过换了model name加载,所以还是应该直接看一下diffusers.models
diffusers.models
首先是贴出github的diffusers.models地址
内容很多,来找一下,首先看init.py,因为都是可以from diffusers.models import AutoencoderKL的嘛。
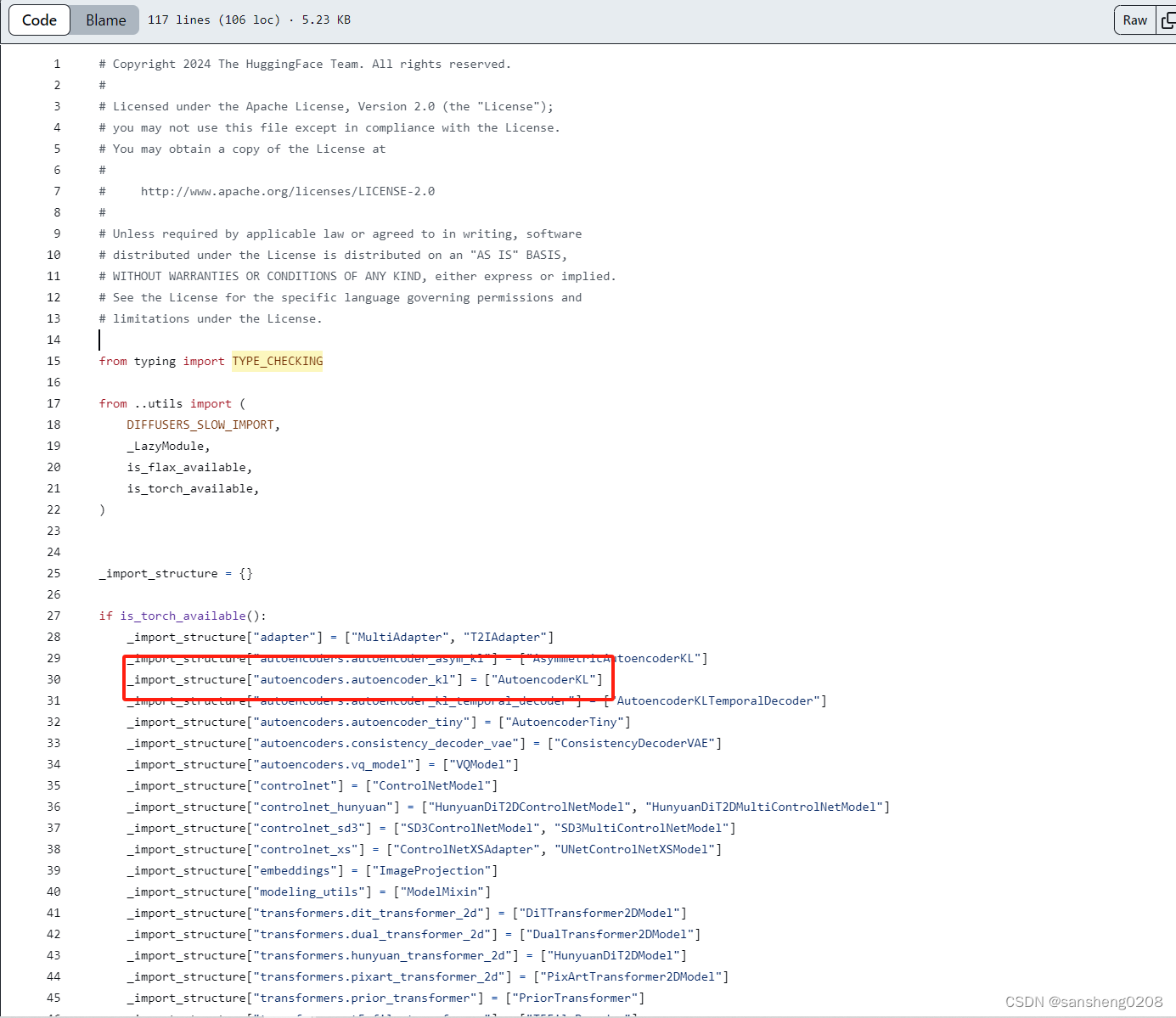
对应模块的路径继续去看
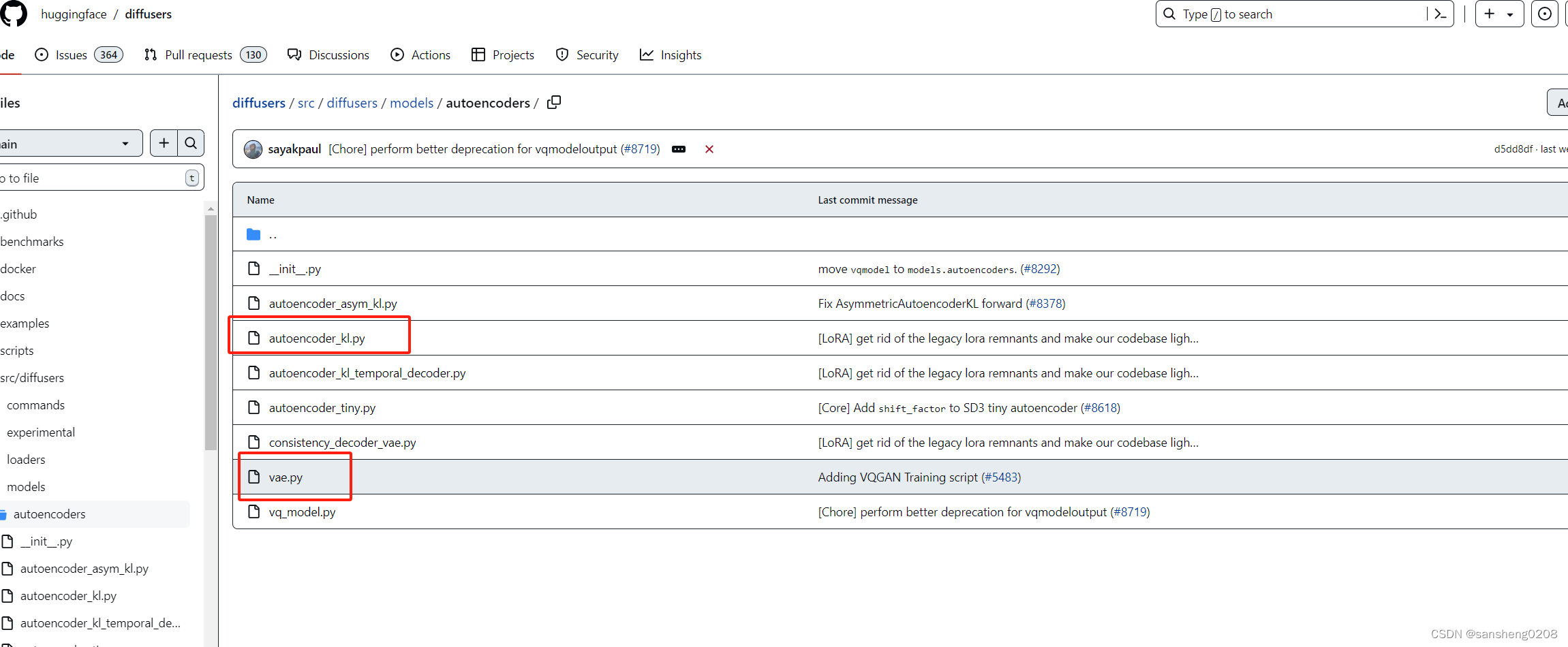
OK,如果估计的没有错,真正的vae结构搭建在这里了,那么实际上最底层的学习内容就要在这里了。在此,再说一句题外话,如果不想扒的这么深的,其实就看到open-sora如何构造、加载的vae model就可以了,并且在学习的过程中,发现了另一位大佬的学习记录,大佬看的也很细,包括将model打印出来,大家也可以跟着大佬一起看一看。
直接先在github线上过一下vae的代码,在对应地址栏那里加上1s
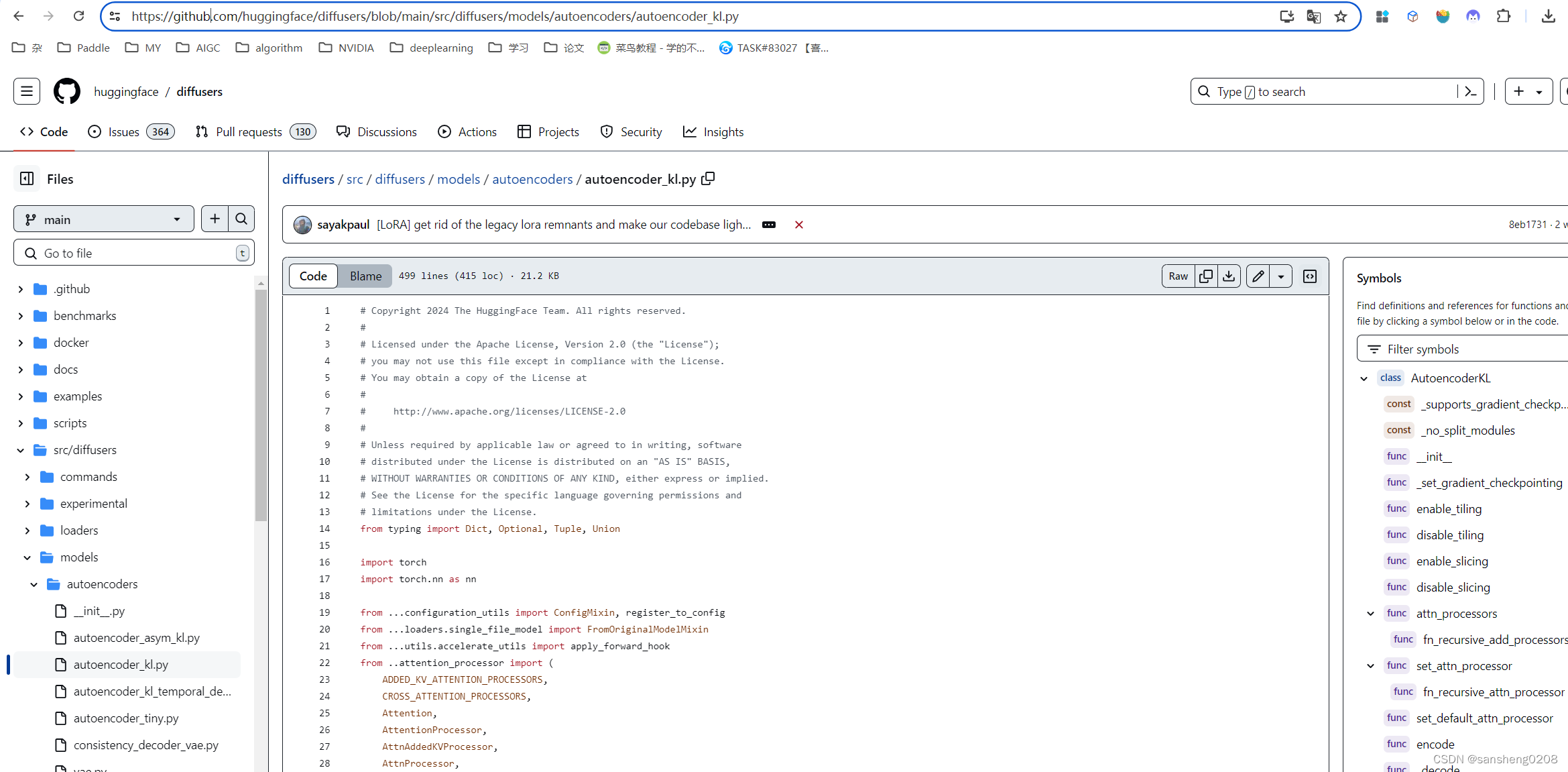
回车!这样就可以看到在线的vscode界面,方便我们跟踪代码。
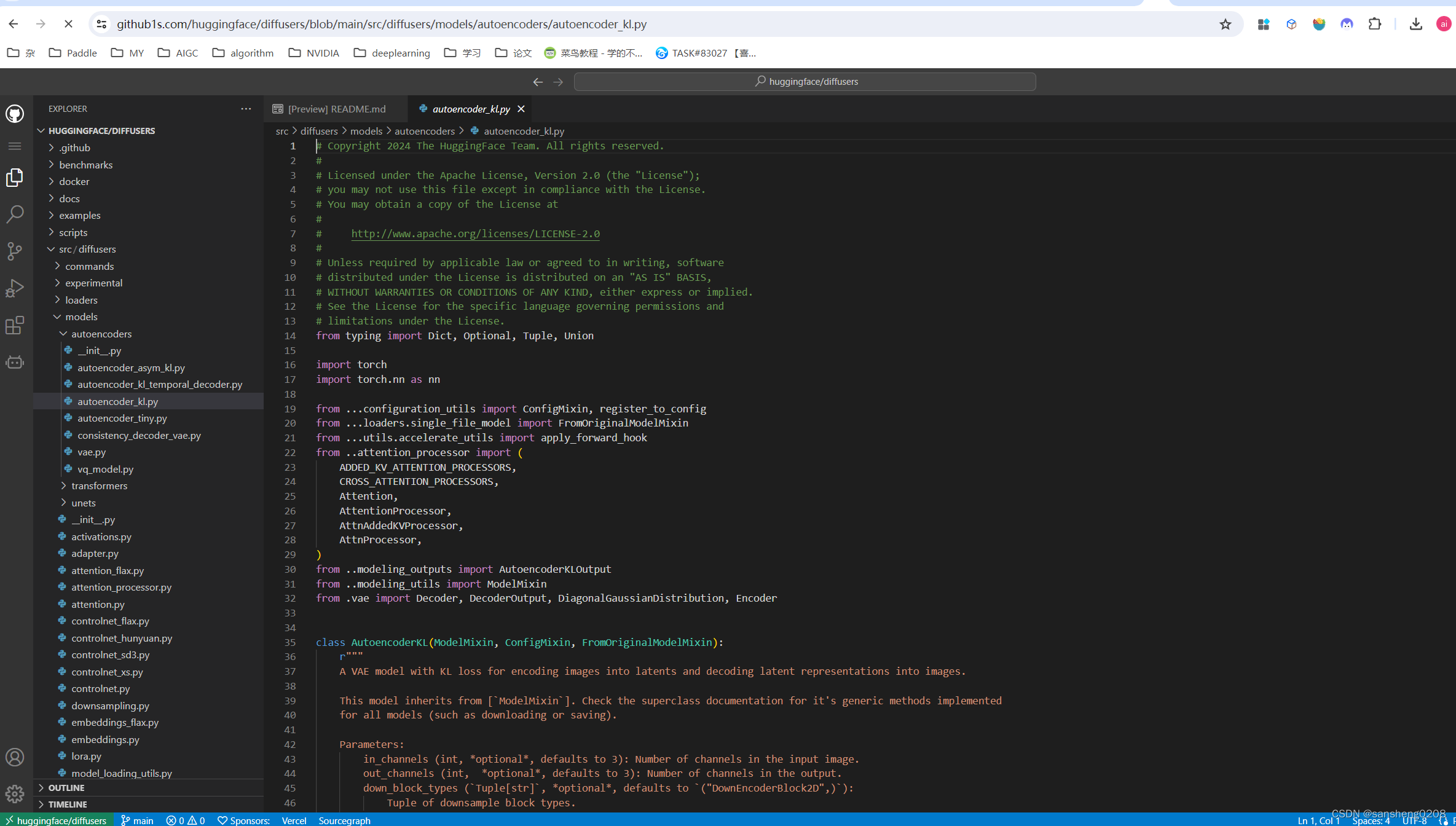
扫一眼AutoencoderKL的参数(要注意它的定义还有多类继承),发现它encoder和decoder模块的搭建继续套娃
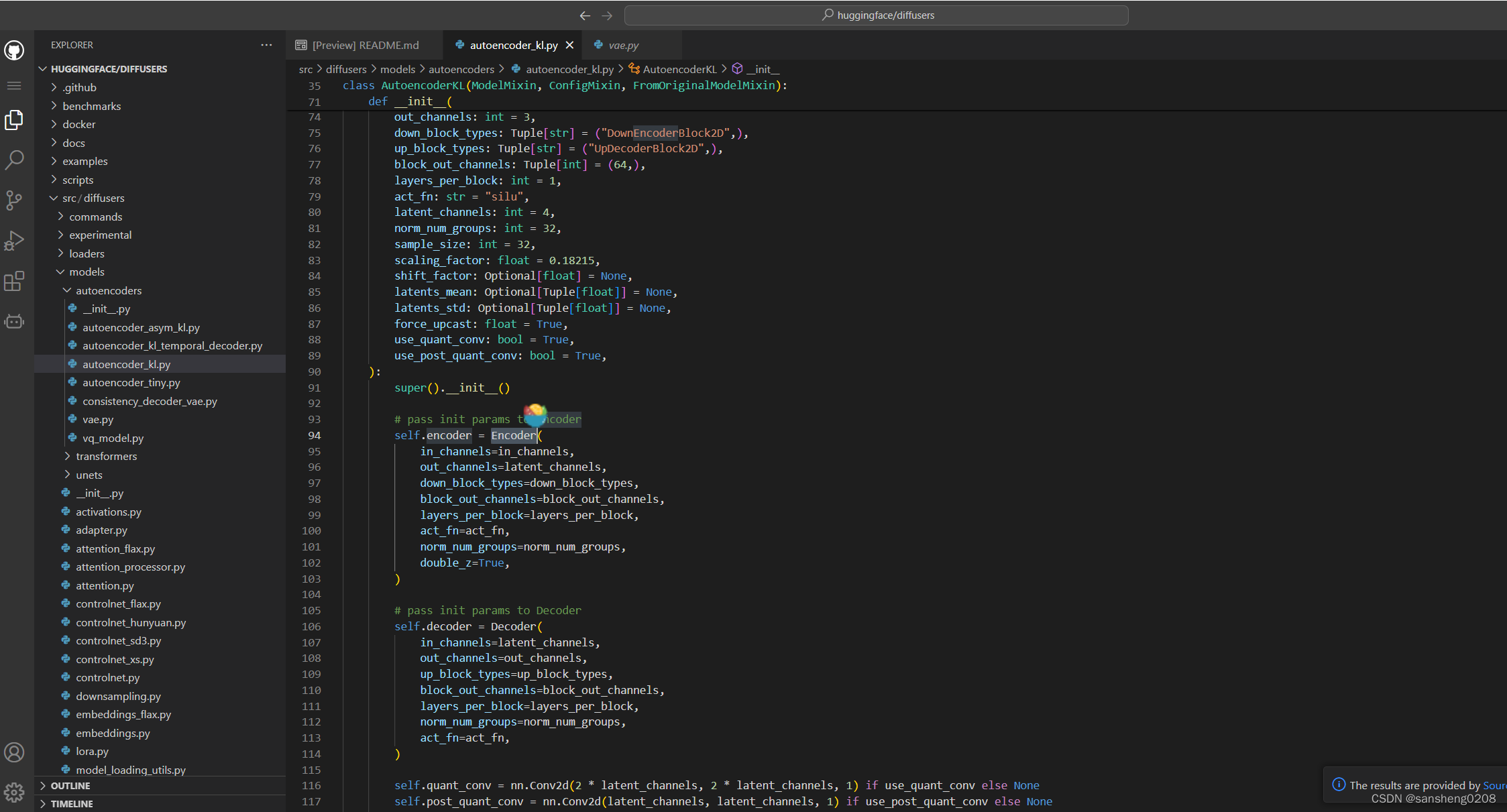
进入的是vae.py,这里开始堆叠block了,又发现block定义的源码在…unets.unet_2d_blocks,继续进入。
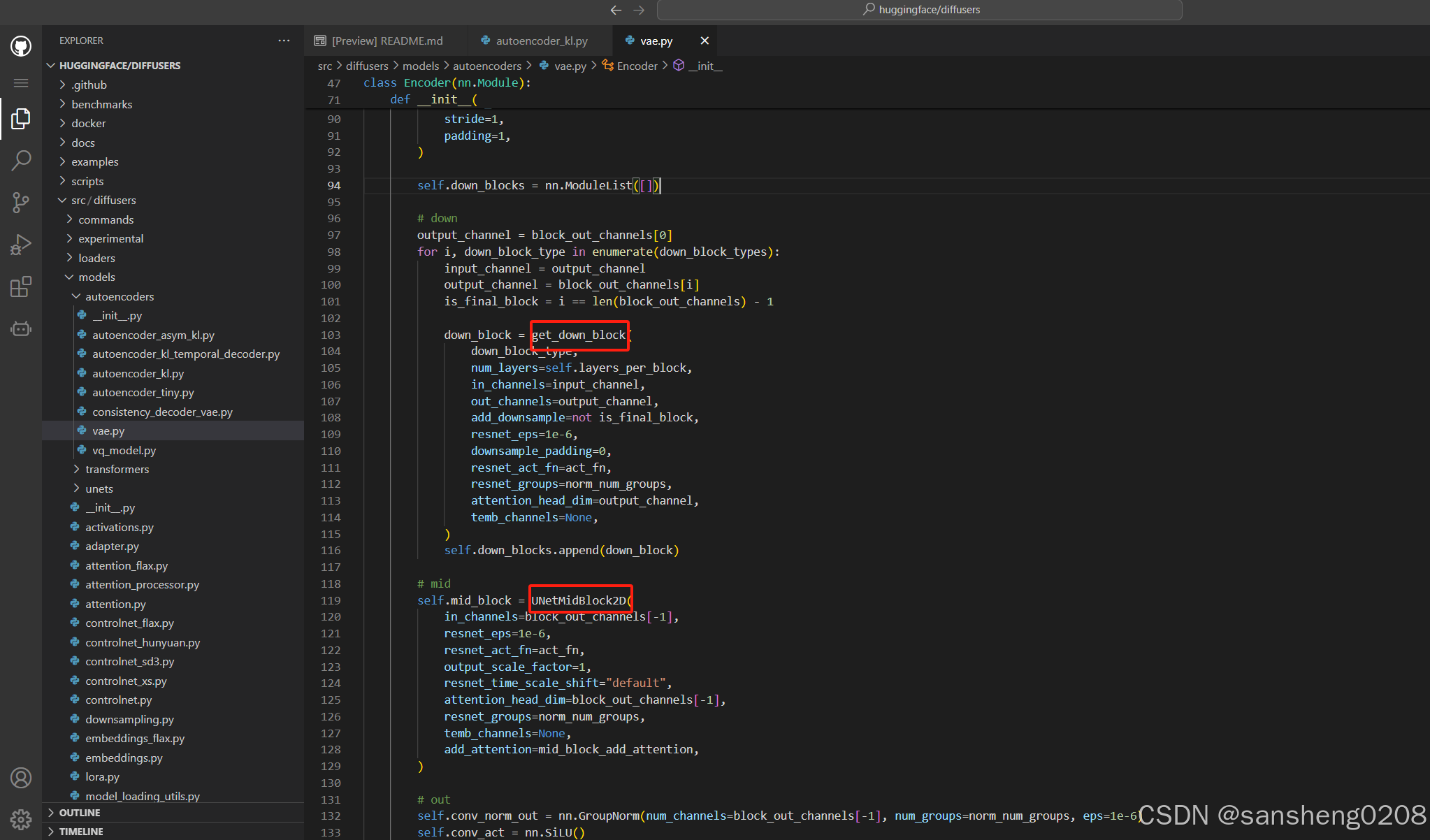
我们找到对应的encoder模块。
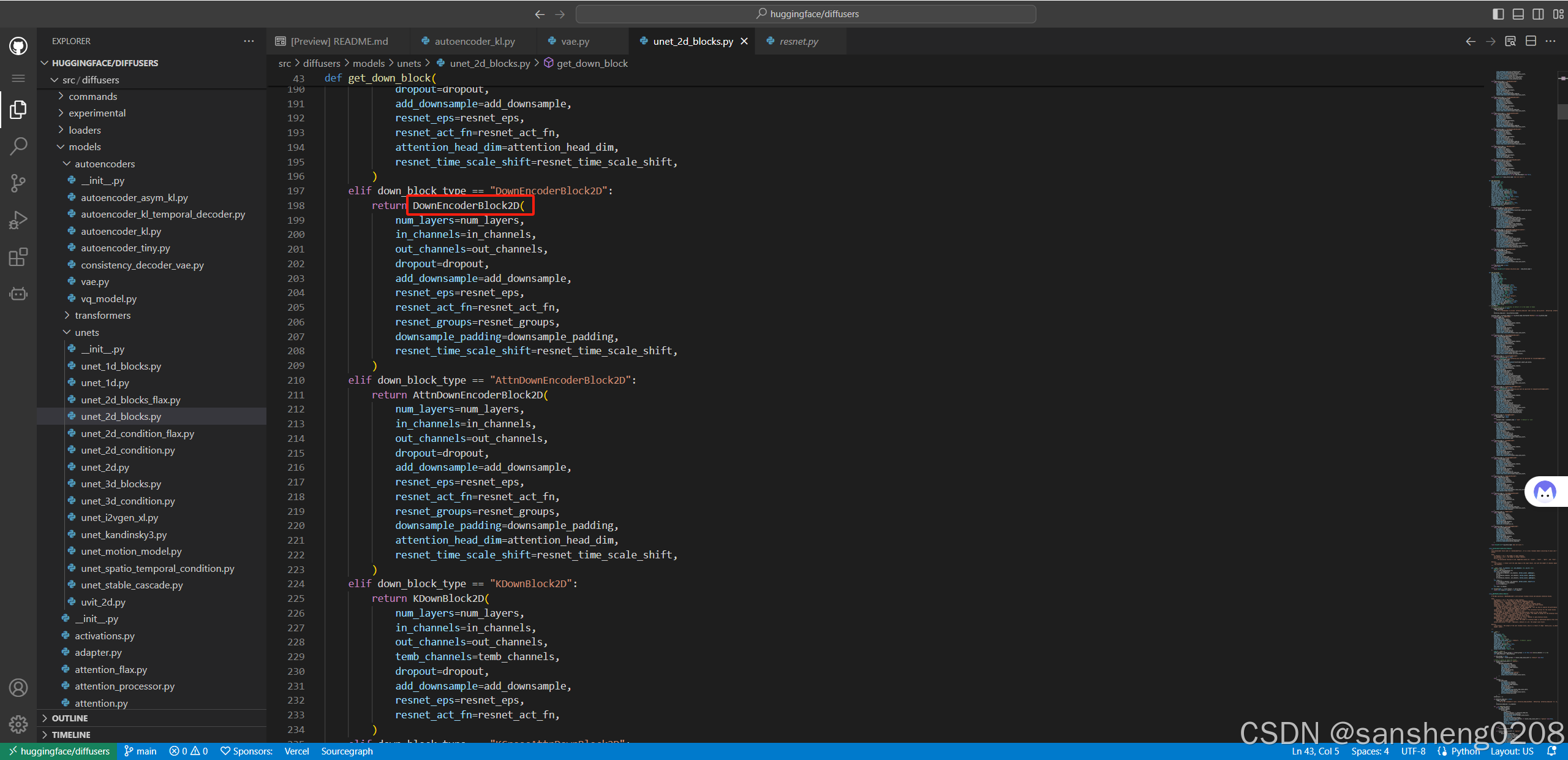
原来是resnet的block,再继续
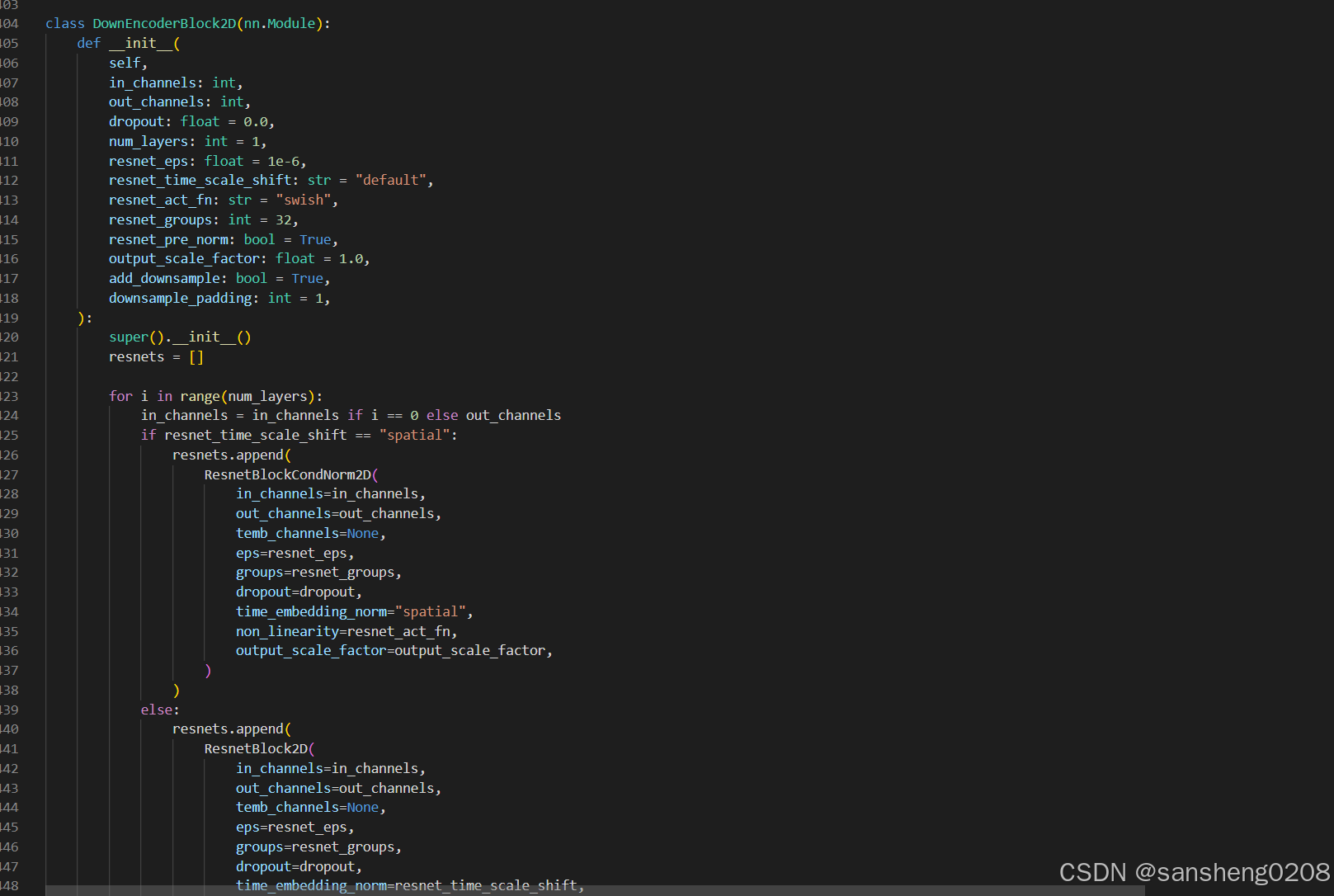
看了一眼之前init的时候resnet_time_scale_shift根本没有给,所以应该用的是默认值,那么这里的resnets用的是ResnetBlock2D,继续进入。
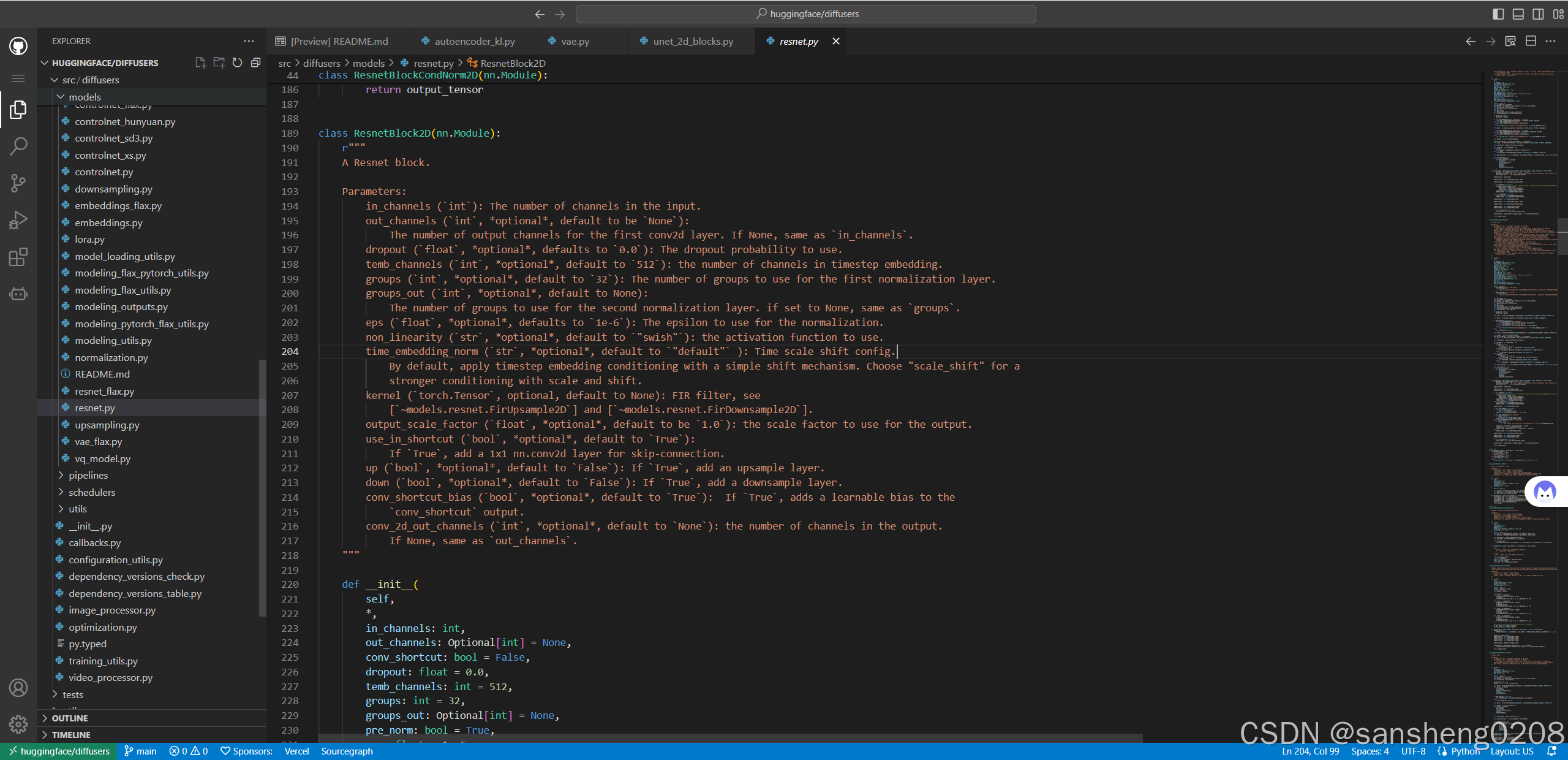
okok,这里终于不套娃了,来简单看看它这里的代码吧。前面这个过程大概捋了一下整个模型init到底在init什么,套了这么多层实在是有点晕,那就本地运行、调试一下来理解代码。先安装一下(顺便看一眼库都装在哪了,方便一会去改源码):
pip install --upgrade diffusers[torch]
我是在容器里安装的,安装完了直接进入容器里面打开库的目录。
进入之后,就不用在网页端看了。
大概过一下他的ResnetBlock2D整个结构、参数。(forward我就以f2(f1(x))的方式来注释整个forward流程)
class ResnetBlock2D(nn.Module):
r"""
A Resnet block.
Parameters:
in_channels (`int`): The number of channels in the input.
out_channels (`int`, *optional*, default to be `None`):
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
groups_out (`int`, *optional*, default to None):
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift" for a
stronger conditioning with scale and shift.
kernel (`torch.Tensor`, optional, default to None): FIR filter, see
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
use_in_shortcut (`bool`, *optional*, default to `True`):
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
`conv_shortcut` output.
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
If None, same as `out_channels`.
"""
def __init__(
self,
*,
in_channels: int,
out_channels: Optional[int] = None,
conv_shortcut: bool = False,
dropout: float = 0.0,
temb_channels: int = 512,
groups: int = 32,
groups_out: Optional[int] = None,
pre_norm: bool = True,
eps: float = 1e-6,
non_linearity: str = "swish",
skip_time_act: bool = False,
time_embedding_norm: str = "default", # default, scale_shift,
kernel: Optional[torch.Tensor] = None,
output_scale_factor: float = 1.0,
use_in_shortcut: Optional[bool] = None,
up: bool = False,
down: bool = False,
conv_shortcut_bias: bool = True,
conv_2d_out_channels: Optional[int] = None,
):
super().__init__()
# time_embedding_norm在这个block是不能用的
if time_embedding_norm == "ada_group":
raise ValueError(
"This class cannot be used with `time_embedding_norm==ada_group`, please use `ResnetBlockCondNorm2D` instead",
)
if time_embedding_norm == "spatial":
raise ValueError(
"This class cannot be used with `time_embedding_norm==spatial`, please use `ResnetBlockCondNorm2D` instead",
)
self.pre_norm = True
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.up = up
self.down = down
self.output_scale_factor = output_scale_factor
self.time_embedding_norm = time_embedding_norm
self.skip_time_act = skip_time_act
## 第一个部分,先固定初始化两个3*3conv2d与两个groupnorm+激活函数和dropout
if groups_out is None:
groups_out = groups
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
if temb_channels is not None:
if self.time_embedding_norm == "default":
self.time_emb_proj = nn.Linear(temb_channels, out_channels)
elif self.time_embedding_norm == "scale_shift":
self.time_emb_proj = nn.Linear(temb_channels, 2 * out_channels)
else:
raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
else:
self.time_emb_proj = None
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
self.dropout = torch.nn.Dropout(dropout)
conv_2d_out_channels = conv_2d_out_channels or out_channels
self.conv2 = nn.Conv2d(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
self.nonlinearity = get_activation(non_linearity)
# 看是否需要上采样or下采样,里面又有一些套娃
self.upsample = self.downsample = None
if self.up:
if kernel == "fir":
fir_kernel = (1, 3, 3, 1)
# 看起来是反卷积来上采样?
self.upsample = lambda x: upsample_2d(x, kernel=fir_kernel)
elif kernel == "sde_vp":
# 最邻近插值
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
else:
# 不用卷积上采样
self.upsample = Upsample2D(in_channels, use_conv=False)
elif self.down:
if kernel == "fir":
fir_kernel = (1, 3, 3, 1)
self.downsample = lambda x: downsample_2d(x, kernel=fir_kernel)
elif kernel == "sde_vp":
# 2*2平均池化做下采样
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
else:
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
# 如果要走shortcut,就init的一个1*1conv2d
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
self.conv_shortcut = None
if self.use_in_shortcut:
self.conv_shortcut = nn.Conv2d(
in_channels,
conv_2d_out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=conv_shortcut_bias,
)
def forward(self, input_tensor: torch.Tensor, temb: torch.Tensor, *args, **kwargs) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
hidden_states = input_tensor
# swish(groupnorm(x))
hidden_states = self.norm1(hidden_states)
hidden_states = self.nonlinearity(hidden_states)
# sample(swish(groupnorm(x)))
if self.upsample is not None:
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
if hidden_states.shape[0] >= 64:
input_tensor = input_tensor.contiguous()
hidden_states = hidden_states.contiguous()
input_tensor = self.upsample(input_tensor)
hidden_states = self.upsample(hidden_states)
elif self.downsample is not None:
input_tensor = self.downsample(input_tensor)
hidden_states = self.downsample(hidden_states)
# 3*3_conv2d(sample(swish(groupnorm(x))))
hidden_states = self.conv1(hidden_states)
# 如果有time特征要做emb
if self.time_emb_proj is not None:
if not self.skip_time_act:
temb = self.nonlinearity(temb)
temb = self.time_emb_proj(temb)[:, :, None, None]
# time_emb和中间hidden信息加起来--scale_shift暂时不知道干嘛的
if self.time_embedding_norm == "default":
if temb is not None:
hidden_states = hidden_states + temb
hidden_states = self.norm2(hidden_states)
elif self.time_embedding_norm == "scale_shift":
if temb is None:
raise ValueError(
f" `temb` should not be None when `time_embedding_norm` is {self.time_embedding_norm}"
)
time_scale, time_shift = torch.chunk(temb, 2, dim=1)
hidden_states = self.norm2(hidden_states)
hidden_states = hidden_states * (1 + time_scale) + time_shift
else:
hidden_states = self.norm2(hidden_states)
# swish(groupnorm(3*3_conv2d(sample(swish(groupnorm(x+timeinfo))))))
hidden_states = self.nonlinearity(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.conv2(hidden_states)
# 1*1_conv2d(3*3_conv2d(dropout(swish(groupnorm(3*3_conv2d(sample(swish(groupnorm(x+timeinfo)))))))))
if self.conv_shortcut is not None:
input_tensor = self.conv_shortcut(input_tensor)
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
return output_tensor
顺带去瞅一眼downsample怎么写的,像Downsample2D都比较简单,就是conv或者avgpooling,所以就不再展示套娃注释了。
这样看下来,整个基本的block也不是很复杂,现在回归到vae的encoder。
我们来调用get_down_block初始化一个模块并打印一下(downsample为True,会多一个卷积进行下采样)。
from diffusers.models.unets.unet_2d_blocks import (
AutoencoderTinyBlock,
UNetMidBlock2D,
get_down_block,
get_up_block,
)
if __name__ == "__main__":
in_channels: int = 3
out_channels: int = 3
down_block_types: tuple[str, ...] = ("DownEncoderBlock2D",)
block_out_channels: tuple[int, ...] = (64,)
layers_per_block: int = 2
norm_num_groups: int = 3
act_fn: str = "silu"
down_block = get_down_block(
down_block_type = "DownEncoderBlock2D",
num_layers=layers_per_block,
in_channels=in_channels,
out_channels=out_channels,
add_downsample=False,
resnet_eps=1e-6,
downsample_padding=0,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
attention_head_dim=out_channels,
temb_channels=None,
)
print(down_block)
DownEncoderBlock2D(
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(3, 3, eps=1e-06, affine=True)
(conv1): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(norm2): GroupNorm(3, 3, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
那么包括它的midblock,encoder,都可以去浅浅打印一下,简单看一下。
这样就知道了diffusers库搭建模块的逻辑,再回到opensora(下一篇)。
由于目前在换工作,工作交接比平时正常工作还忙,所以更新速度会比较慢,下一篇正在草稿箱,写完就发。

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









