







一、在Eclipse中查看Java类库的源代码
首先要找到JDK安装目录,然后该目录下会有个src.zip文件,我们把它加载到Eclipse中就行了,然后在Eclipse中想查看某个方法或者某个类的源代码,直接选中按F3



下面那个Path就是你所安装JDK目录下的src.zip的路径

使用:
可以在 Java 源代码编辑器或代码片段编辑测试窗中选择类型、方法或字段的名称,然后对元素的定义打开编辑器。
在 Java 编辑器中,选择类型、方法或字段的名称。您也可以仅仅在名称中单击一次。
执行下列其中一项操作:
1.从菜单栏中,选择浏览 > 打开声明
2.从编辑器的弹出菜单中,选择打开声明
3.按 F3 键
或者
1.按下 Ctrl 键。
2.在 Java 编辑器中,将鼠标移到类型、方法或字段的名称上,直到名称变为带有下划线为止。
3.单击一次超链接。
如果具有多个同名的定义,则会显示一个对话框,您可以选择想要打开的一个定义。一个编辑器打开,它包含所选择的元素。
原文地址:http://ajava.org/course/tool/14485.html

二、Java进阶之----LinkedList源码分析
今天在看LinkedList的源代码的时候,遇到了一个坑。我研究源码时,发现LinkedList是一个直线型的链表结构,但是我在baidu搜索资料的时候,关于这部分的源码解析,全部都说LinkedList是一个环形链表结构。。我纠结了好长时间,还以为我理解错了,最后还是在Google搜到了结果:因为我看的源码是1.7的而baidu出来的几乎全部都是1.6的。而且也没有对应的说明。在1.7之后,Oracle将LinkedList做了一些优化,将1.6中的环形结构优化为了直线型了链表结构。这里要提示一下朋友们,看源码的时候,一定要看版本,有的情况是属于小改动,有的地方可能有大改动,这样只会越看越迷糊。
好,言归正传。我们来分析一下Java中LinkedList的部分源码。(本文针对的是1.7的源码)
LinkedList的基本结构


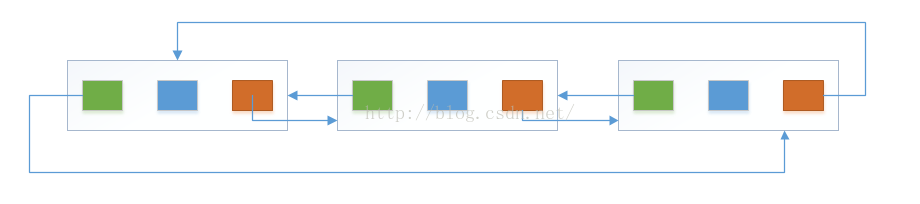
LinkedList的构造方法
这段代码还是很好理解的。我们可以配合图片来深入理解。
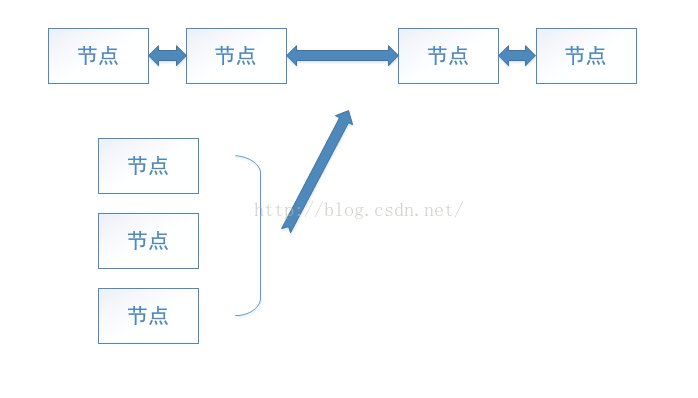
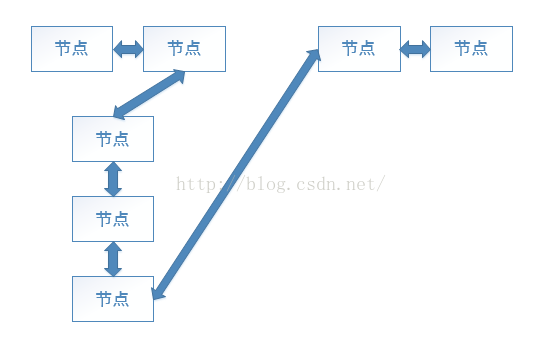
LinkedList部分方法分析
addFirst/addLast分析
addLast方法在实现上是个addFirst是一致的,这里就不在赘述了。有兴趣的朋友可以看看源代码。
getFirst/getLast方法分析
get方法分析
三、完整实例
【转自:https://github.com/onlyliuxin/coding2017/blob/master/group20/1107837739/1107837739Learning/src/org/korben/list/KLinkedList.java】
(1)KList.java
package org.korben.list;
/**
* Korben's List
*
* Created by Korben on 18/02/2017.
*/
public interface KList<T> {
int size();
boolean isEmpty();
boolean contains(Object o);
Object[] toArray();
boolean add(T o);
boolean remove(T o);
void clear();
T get(int index);
T set(int index, T element);
void add(int index, T element);
T remove(int index);
int indexOf(T o);
KIterator<T> iterator();
}(2)KLinkedList.java——存在点bug;不过大体思路给出来了
package org.korben.list;
import java.util.Objects;
/**
* Korben's LinkedList
*
* Created by Korben on 18/02/2017.
*/
public class KLinkedList<T> implements KList<T> {
private int size;
private Node<T> head;
private Node<T> last;
public KLinkedList() {
this.head = new Node<>(null);
}
@Override
public int size() {
return this.size;
}
@Override
public boolean isEmpty() {
return this.size == 0;
}
@Override
public boolean contains(Object o) {
Node node = this.head;
while (node.next != null) {
node = node.next;
if (Objects.equals(node.data, o)) {
return true;
}
}
return false;
}
@Override
public Object[] toArray() {
return new Object[0];
}
@Override
public boolean add(T o) {
if (this.last == null) {
this.last = new Node<>(o);
this.last.pre = this.head;
this.head.next = this.last;
} else {
Node<T> oldLast = this.last;
this.last = new Node<>(o);
this.last.pre = oldLast;
oldLast.next = this.last;
}
this.size++;
return true;
}
@Override
public boolean remove(T o) {
Node node = this.head;
while (node.next != null) {
node = node.next;
if (Objects.equals(node.data, o)) {
node.pre.next = node.next;
if (node.next != null) {
node.next.pre = node.pre;
}
this.size--;
return true;
}
}
return false;
}
@Override
public void clear() {
this.head.next = null;
this.last = null;
this.size = 0;
}
@Override
public T get(int index) {
return getNode(index).data;
}
@Override
public T set(int index, T element) {
Node<T> node = getNode(index);
node.data = element;
return element;
}
@Override
public void add(int index, T element) {
Node<T> node = this.head;
for (int i = 0; i <= index; i++) {
node = node.next;
}
Node<T> pre = node.pre;
Node<T> newNode = new Node<>(element);
pre.next = newNode;
newNode.pre = pre;
newNode.next = node;
node.pre = newNode;
this.size++;
}
@Override
public T remove(int index) {
Node<T> node = getNode(index);
Node<T> pre = node.pre;
Node<T> next = node.next;
pre.next = next;
if (next != null) {
next.pre = pre;
}
this.size--;
return node.data;
}
@Override
public int indexOf(T o) {
Node node = this.head;
int index = 0;
while (node.next != null) {
node = node.next;
if (Objects.equals(node.data, o)) {
return index;
}
index++;
}
return -1;
}
@Override
public KIterator<T> iterator() {
throw new IllegalStateException("方法未实现");
}
private Node<T> getNode(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
Node<T> node = this.head;
for (int i = 0; i <= index; i++) {
node = node.next;
}
return node;
}
private static class Node<T> {
T data;
Node<T> pre;
Node<T> next;
Node(T data) {
this.data = data;
}
}
}















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









