







ABSTRACTIVE DIALOGUE SUMMARIZATION WITH SENTENCE-GATED MODELING OPTIMIZED BY DIALOGUE ACTS
论文链接:
https://arxiv.org/abs/1809.05715
思路:
会议摘要中比较早的工作,利用了dialogue act(对话行为)信息,通过添加一个dialogue act classification(对话行为分类)的任务来提升会议摘要。文章还利用门机制来显示的建模对话行为分类任务和摘要任务的关系。
数据集:
这篇文章利用AMI数据集构造了一个新的数据集,AMI数据集是一个会议数据集,包含丰富的annotation(对话行为,话题描述,姿势,表情,实体等等)。这篇文章主要利用对话行为标签。原始AMI数据集的规模太小(100多条),因此重新构造了数据集,利用滑动窗口将一个会议切分成多个对话样本,将对应的话题描述作为摘要,(如果一个对话中有多个话题,将话题描述拼接在一起),构建后的新数据集一共有7824个对话样本
模型
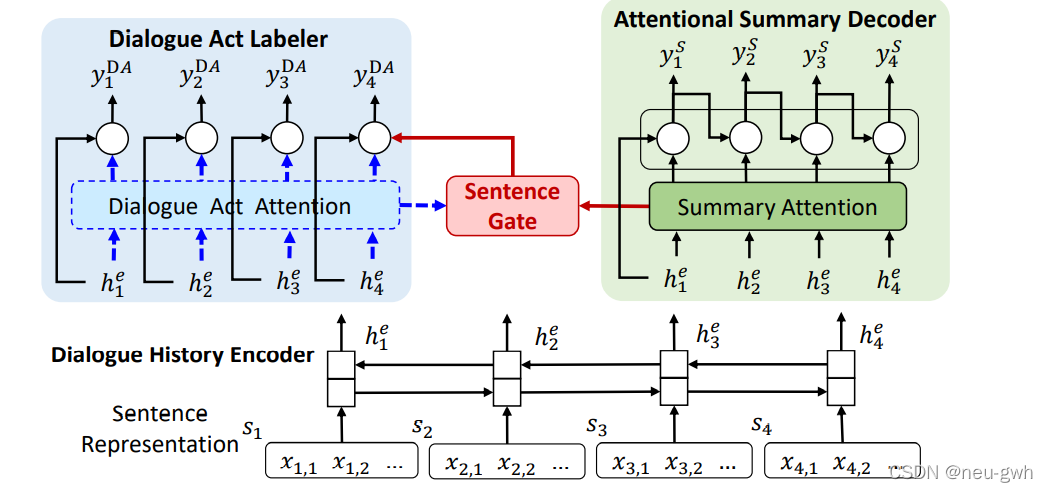
模型总体架构如上图
首先有一个解码器,是双向LSTM,每个utterance的每个word的embedding做平均得到句子表示
s
i
s_i
si,然后通过双向LSTM得到每个句子的隐藏向量表示
h
i
h_i
hi
然后有一个dialogue act labeler,完成对话动作分类任务,预测每句话的动作标签,也是用LSTM模型,这里引入了注意力,计算公式如下:
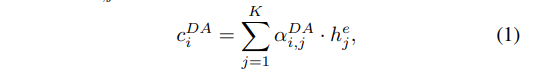
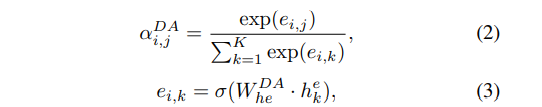
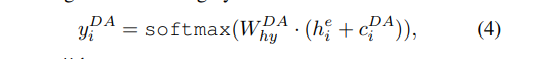
最后是一个summary decoder,用的是单向LSTM,也用到了注意力,计算公式类似:

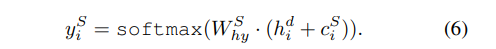
这里还引入了一个门机制,显示的建模对话动作分类和摘要的关系。这里有两种方法,第一种是full attention,同时利用对话动作分类(dialogue act attention)注意力和摘要生成注意力(summary attention)
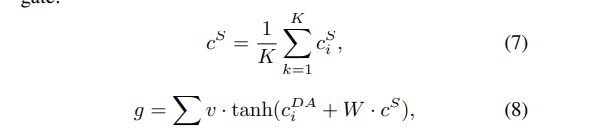
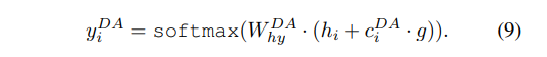
还有一种方法是summary attention,在模型架构中去掉了dialogue act attention,计算公式如下。对话动作分类和摘要生成两个任务共享注意力
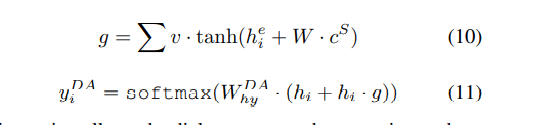
损失计算公式:
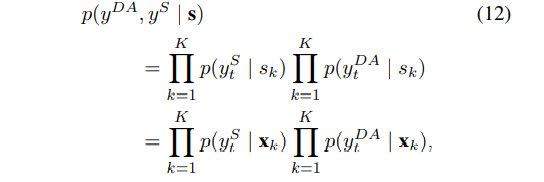
代码链接:
https://github.com/MiuLab/DialSum
A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining
论文链接
https://arxiv.org/abs/2004.02016
动机与主要想法
作者提出会议摘要主要有三个挑战,一是会议对话很长,正常的Transformer无法处理,而是会议对话中有多个说话人,三是会议对话的数据集规模往往很小。这篇文章提出了HMNET,针对第一个挑战,这篇文章设计了一个 层次化的Transformer网络,针对第二个挑战,引入说话人角色向量,针对第三个挑战,引入预训练,用新闻领域的数据集预训练模型。
模型和方法
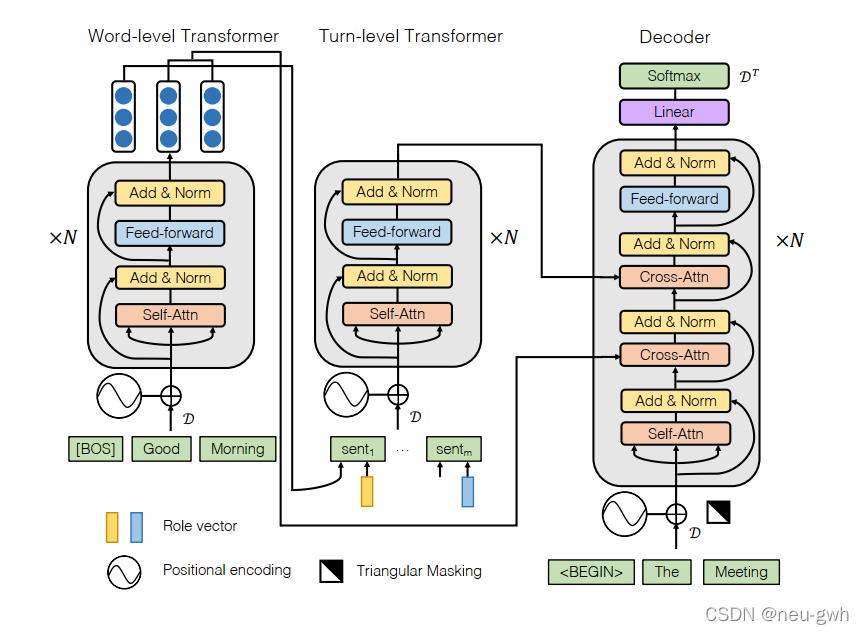
模型总体架构如上图所示
编码器是层次化的Transformer,包括word-level和utterance-level的Transformer
对于word-level,这篇文章有一个特别之处,它同时引入了词性和实体信息,每个token表示为
x
i
,
j
=
[
g
i
,
j
;
P
O
S
i
,
j
;
E
N
T
i
,
j
]
x_{i, j}=\left[g_{i, j} ; P O S_{i, j} ; E N T_{i, j}\right]
xi,j=[gi,j;POSi,j;ENTi,j]这里在每个输入序列前还添加了一个特殊符号
w
i
,
0
=
[
B
O
S
]
w_{i, 0}=[\mathrm{BOS}]
wi,0=[BOS],最后用Transformer对每个utterance的token编码。得到token级别的输出向量表示
对于utterance-level,用之前word-level得到的输出向量表示中的BOS位置的向量代表这个utterance,这里还添加了一个角色向量(role vector),为每个对话参与者训练一个向量,拼接在一起
[
x
1
,
0
W
;
p
1
]
,
…
,
[
x
m
,
0
W
;
p
m
]
\left[x_{1,0}^{\mathcal{W}} ; p_{1}\right], \ldots,\left[x_{m, 0}^{\mathcal{W}} ; p_{m}\right]
[x1,0W;p1],…,[xm,0W;pm]送入Transformer得到了句子级别的向量表示
解码器的注意力先append word-level的输出向量,再append句子级别的输出向量,后面都跟个layer-norm
训练和解码和正常生成任务一样,训练时使用交叉熵损失和teacher-forcing,解码用beam-search
为解决数据不足问题,利用新闻摘要数据预训练,这里把新闻处理成会议的格式,把m个新闻拼接起来,就看成一个m个参与人的会议,第几个新闻,就相当于第几个参与者,每个句子看成对话中的一个turn.
代码链接
https://github.com/xcfcode/DDAMS
Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization
论文链接:
https://arxiv.org/abs/2012.03502
动机与想法
这篇文章将dialogue discourse(语篇关系,如QA,Contrast,Continuation等)引入到会议摘要中,构造了一个 meeting discourse graph,建模对话之间的关系,同时还利用QA语篇关系来构造伪摘要数据,缓解会议摘要数据不足的问题
模型与方法
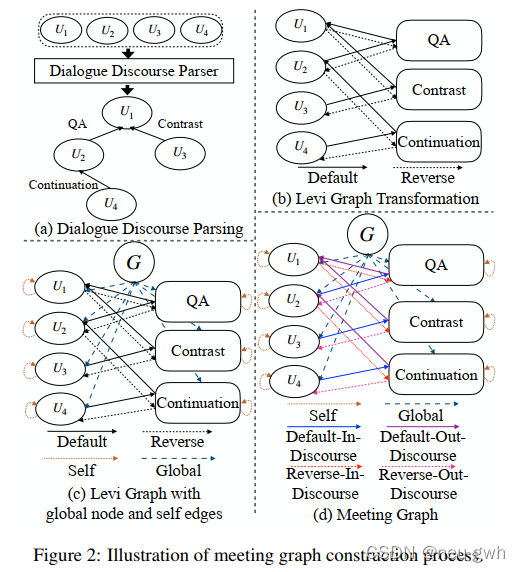
这篇文章构造了一个meeting discourse graph,如上图所示,首先用一个语篇解析模型标注出对话之间的语篇关系。然后用Levi 转换将标注出的关系(带标签的边)转化为额外的节点,这样就可以同时建模语句节点和语篇关系。Levi转换后的边有两种,default和reverse,这里还添加了一个额外的全局节点,捕获全局的信息,还添加了自环,捕获自己的信息。这里明确指出关系边的类型,一共有六种类型的边,default-in,default-out,reverse-in,reverse-out
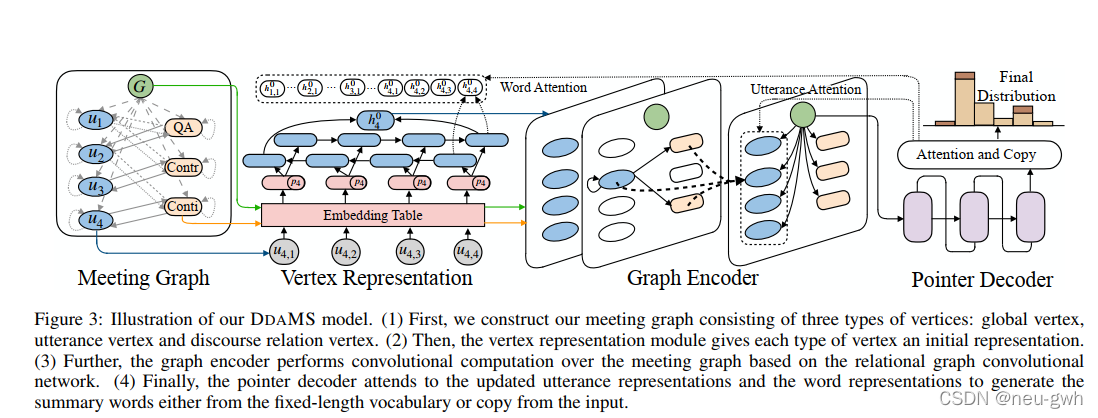
模型架构如上图所示,首先按上面说的构造会议语篇关系图,这里有三种节点,关系节点,语句节点,全局节点。
然后对节点进行表示,得到三种节点的初始向量表示。全局节点和关系节点,通过embedding table表示,语句节点用双向LSTM表示,这里还用一个onehot向量编码说话人,与语句向量表示拼接在一起,从而引入说话人信息
将得到的向量表示送入图编码器(graph encoder),这里用的是relational graph convolutional networks,得到隐藏向量表示。这里还引入了门机制,控制信息传递的过程。主要公式如下
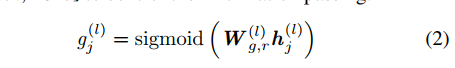
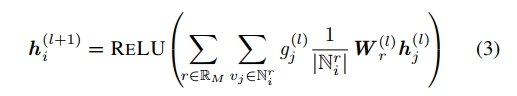
最后用pointer decoder来进行解码,这里引入了注意力机制,复制机制,注意力包括word-level的,还有utterance-level的,分别得到一个上下文向量,将word-level的上下文和utterance-level的上下文拼接在一起,来指导摘要的生成。
为解决会议摘要数据缺少的问题,这里构造了伪摘要数据集。问题后面往往跟着一些讨论,问题包含了讨论的重要信息。这里利用QA语篇关系,将问题作为伪摘要,将问题后面跟着的若干讨论作为伪会议。先在伪摘要数据集上进行预训练。

















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









