






快速发展的生成式 AI 领域专注于构建可以创建逼真内容(例如文本、图像、音频和合成数据)的神经网络。生成式 AI 正在多个行业中引发革命,通过快速创建内容、为智能知识助手提供支持、增强软件开发以编码副驾驶,以及跨多个领域自动执行复杂任务。
然而,生成式 AI 模型基于有限数据进行训练,只知道数据能告诉他们的内容。实际上,这是一个问题:确保生成内容的准确性和相关性,特别是对于模型训练数据中没有的信息。这些“知识差距”可能是时间方面的(例如,所有训练数据都在 2023 年 4 月之前),也可能是领域方面的(例如,您的任何专有数据都未用于训练模型)。
这正是检索增强生成(RAG)发挥作用的地方。RAG 利用外部信息来源增强生成式模型(例如大型语言模型(LLM)),以有效地为模型提供它不知道的“事实”。这样做将导致响应更加准确且与上下文相关,具体取决于外部信息的质量和模型的质量。
如何使用 RAG 的具体示例包括:
- 最新的聊天机器人:RAG-enabled 聊天机器人可以从公司的数据库中实时获取信息,以便准确响应客户查询。例如,模型不知道的最近停机情况。
- 上下文感知内容创建:RAG 应用可用于注入数据,以生成反映模型训练后发生的当前事件的长格式内容。
- 基于搜索的内容汇总:添加互联网搜索和文档检索功能可以将 RAG 应用转变为动态内容生成器,该生成器使用传统的搜索方法查找数据,然后将其输入典型的 RAG 工作流。
本文介绍了 RAG 应用程序的两种方法,即本地和混合方法,并展示了 NVIDIA AI Workbench 如何帮助您轻松开始使用 GitHub 中的混合 RAG 示例项目。
计算位置
RAG 的灵活性和强大功能并非免费实现的。RAG 应用程序由许多可移动的部分组成,大部分涉及某种形式的计算。例如,端到端 RAG 应用程序需要执行以下步骤:首先,将您的数据提取到向量数据库中;然后,根据您的输入从该数据库中执行信息检索;最后,将检索到的数据通过 LLM 推送以生成适当的答案。最后一步在计算方面可能特别困难,这是 GPU 可以提供显著优势的地方。
最后,结果的质量在很大程度上取决于模型的大小,以数十亿个参数进行测量。在所有条件相同的情况下,模型质量会随着模型大小的增加而增加。例如,数百亿个参数比数十亿个参数更好。这是因为参数数量与可以训练模型的数据量相关。更多的参数意味着更多的数据,从而产生更丰富、更复杂的响应。
由于更大的模型需要更大的 GPU 和更多的显存(vRAM),用户需要在其 RAG 应用程序中确定如何使用不同的 GPU。这提出了两个问题:
- 如何配置 RAG 应用程序和所需模型,以便与给定 GPU 配合使用?
- GPU 在哪里运行?
本地 RAG
运行自托管 RAG 应用程序现在很受欢迎。在这种情况下,用户或组织可以在其控制的资源上设置所有设置,包括 GPU。虽然这种方法在技术上比使用OpenAI 等服务复杂,但它可以实现自定义、隐私和成本控制,这些是第三方提供商无法实现的。
对于一些用户而言,自托管甚至意味着在 AI 工作站上运行所有内容。这意味着,在配备一个或多个 NVIDIA RTX 6000 Ada 代 GPU 的 AI 工作站上,数据、查询和计算保持完全隐私并独立存在。 虽然单独创建这样的应用程序并不现实,但有一些高质量的 RAG 应用程序可以在本地运行。例如,LM Studio、AnythingLLM 和 NVIDIA 聊天 RTX 等应用程序都是用户友好的,采用即插即用的方法。因此,用户可以使用不同的模型和向量数据库。
但是,如果您想执行某些操作,而这些操作超出了本地 GPU 的性能,该怎么办?
一个答案是混合 RAG。
混合 RAG
Hybrid RAG 是一种方法,它使用在不同位置运行的计算资源来提供必要的计算能力。它被称为 hybrid,因为它结合了不同但互补的资源。通常情况下,这意味着在本地 AI 工作站或 PC 上运行嵌入和检索步骤,而远程 GPU 资源则用于 LLM 推理计算。无论您是处理小型项目还是处理大量数据,这种组合都有助于产生最佳性能。
虽然这种方法听起来很有吸引力,但自行构建混合 RAG 应用并非易事。您需要了解 LangChain 的基础知识,以及数据存储和管理、信息检索、文本生成和构建用户界面的基础知识。然后,您需要做出技术决策,例如将模型大小、精度和令牌限制与目标硬件相匹配。最后,您需要了解如何连接所有内容,以便选择在何处运行特定的计算组件。
NVIDIA AI Workbench 的用武之地有很多。这就是 NVIDIA AI Workbench 的用武之地。NVIDIA AI Workbench 是一款免费的解决方案,使您能够在所选系统(PC、工作站、数据中心或云)上开发、测试和原型设计生成式 AI 应用程序。AI Workbench 既支持开发又支持训练,您可以跨人员和系统创建和共享开发环境NVIDIA AI Workbench。
在本地或远程工作站或 PC 上,只需几分钟即可安装 AI Workbench 并开始使用。它支持 Windows 11、Ubuntu 22.04 和 24.04 以及 macOS。安装后,您可以启动新项目或从 AI Workbench 示例 on GitHub 中克隆一个项目。您可以通过选择 GitHub 或 GitLab 进行一切工作,因此您可以像往常一样工作,但仍然轻松分享您的工作。详细了解 AI Workbench 入门。
采用 AI 的混合 RAG 工作台
要查看示例应用程序,以便在本地或远程系统上运行基于文本的自定义 RAG Web 应用程序和您自己的文档,请查看 NVIDIA Hybrid RAG 项目。该项目是一个 Workbench 项目 ,在主机上运行具有 Gradio 聊天 UI 前端的容器化 RAG 服务器。此外,它还提供了 JupyterLab 开发环境,以及与 Visual Studio Code 集成的选项。您可以使用各种 模型,并选择要运行推理的位置。
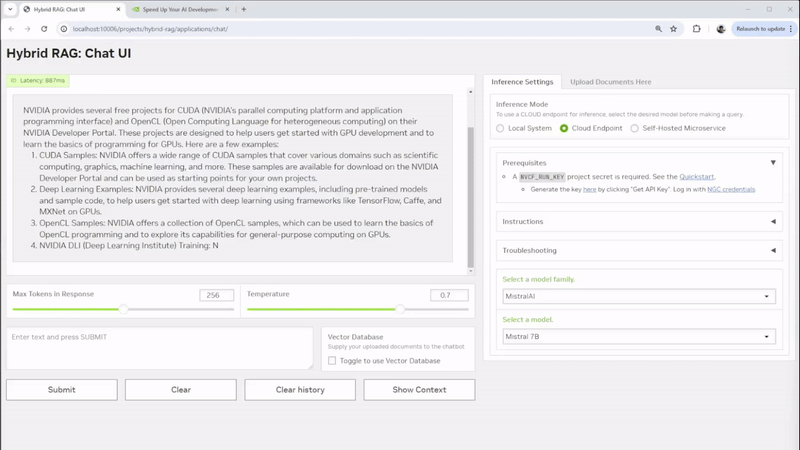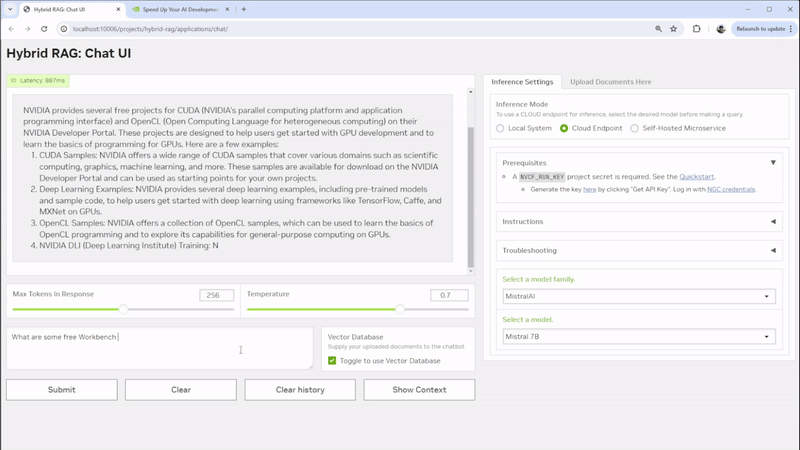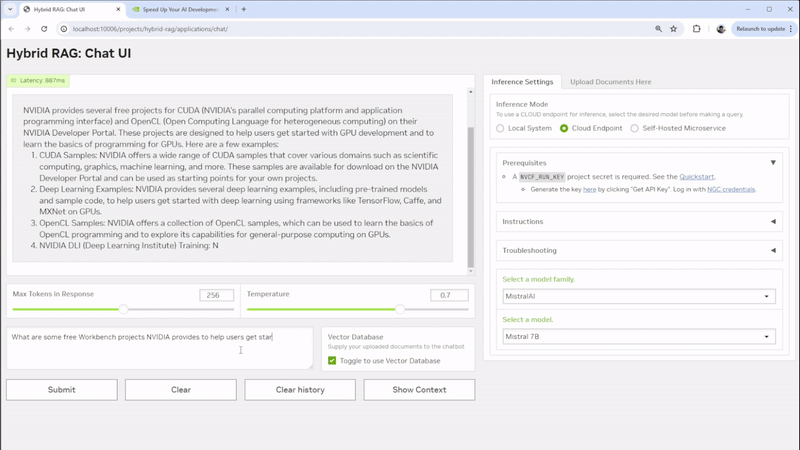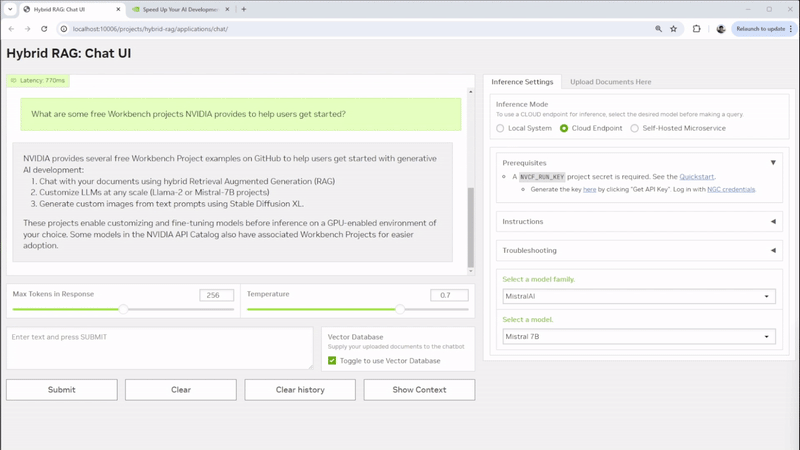
图 1. 使用可定制的 Gradio 聊天 UI 开发混合 RAG 项目
Hybrid RAG 项目相当简单,因为它也是一个开发环境,您可以打开它并详细了解 Hybrid RAG 的工作原理。它完全可修改,提供了一个合适的环境,以便开始学习如何设置混合应用程序。您可以使用它来学习,也可以将其分支并将其调整到您自己的应用程序中。
此项目与 NVIDIA API 目录无缝集成,使开发者能够利用基于云的推理端点进行快速原型设计和开发。另外,您可以下载 NVIDIA NIMs 到本地工作站或服务器,以进行本地部署和自定义。 NVIDIA 开发者计划 为您提供免费的 NIM 实验访问权限。
重要的是,这些相同的 NIM 借助 NVIDIA AI Enterprise 许可证可以过渡到生产环境,从而确保从开发到部署的顺畅路径。凭借这种灵活性,您可以根据自己的需求选择最适合的推理方法,无论是基于云、本地还是混合方法。在不同环境中,您也可以保持一致。















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









