







C-预处理
- #define
- #define定义的宏可以出现在代码的任何地方
- define从本行开始,之后的代码都可以使用这个宏常量
- 我们应避免在宏定义中定义表达式
宏表达式与汗水的对比
- 宏表达式在预编译时期被处理,编译器不知道宏表达式的存在
- 宏表达式用“实参”完全替代形参,不进行任何运算
- 宏表达式没有任何调用开销
- 宏表达式中不能出现递归定义
- C语言没有办法在函数中定义一个函数,但是却可以在函数中定义一个宏
一些你应该知道的强大的内置宏
- FILE 被编译的文件名
- LINE 当前行号
- DATE 编译时的日期
- TIME 编译时的时间
- STDC 编译是是否遵循C规范
-> 例如: #define LOG(s) printf(“%s : %d %s “, FILE, LINE, s);
条件编译
- 条件编译的行为类似C语言的 if-else
- 条件编译是预编译器指令,用于控制是否编译某代码段
- #if #ifdef #ifndef #elif #else #endif
inclde
- #include的本质是将已经存在的文件内容 嵌入到当前文件中
- #inclde的间接包含可能产生嵌入相同文件内容的动作。
-> 如何避免嵌入相同的文件呢? 范例:
#ifndef _GLOBAL_H
#define _GLOBAL_H
int global = 0;
#endif相信上面的代码, 你已经见过了, 是不是可以理解呢?
- #error与#warning、#line
- #error用于生成一个编译错误消息,并停止编译 -> 即程序的预处理都不会完成
- #error用于定义预处理不正确的错误
- #warning用于生成编译器警告,但不会停止编译
- #line用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
- #line的本质是重定义FILE和LINE
-> 范例:
LOG("demo");
#ifndef COMMAND
#warning complication will be stop
#error No defined constant symbol COMMAND
#endif
#line 20 "hello.c"
LOG("#line 起作用了吗?"); 可以看出, #error message : message并不需要加双引号。
pragma pack
- 内存对齐
在看这个指令之前,先来看一下,什么是内存对齐?
不同类型的数据在内存中按照一定规则排列; 而不是顺序的一个接一个排放,这就是内存对齐。- 为什么需要内存对齐呢?
- CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是1,2, 4, 8, 16
- 当读取操作的数据为对齐时,则需要两次总线周期来访问内存,因此性能会大打折扣
- 并且某些硬件平台规定只能从规定的地址处获取某些特定类型的数据,否则会抛出硬件异常
struct test1{
char c1;
short s;
char c2;
int i;
};
struct test2{
char c1;
char c2;
short s;
int i;
};
printf("test1's size is %d:", sizeof(struct test1)); //12
printf("test2's size is %d:", sizeof(struct test2)); //8
结果为什么是这样呢? 来看一下内存对齐的规则:
- 1,对于结构体的各成员,第一个成员位于偏移0的位置,以后每个数据的偏移量必须是 min(#pragma pack()指定的数, 这个数据成员的自身长度)的倍数。
- 2,在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构体(或联合)最大数据成员长度中, 比较小的呢个进行
- 3, #pragma pack 的默认值为4
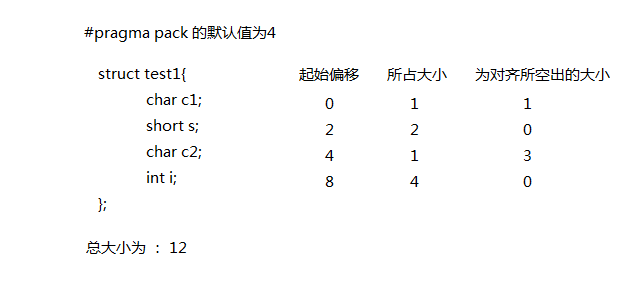
-> 我们可的:
- 在对齐过程中起始偏移 : 必须是 min(#pragma pack()指定的数, 这个数据成员的自身长度)的倍数
- 最后整个结构体的大小必须是 : #pragma pack指定的数值和结构体(或联合)最大数据成员长度中, 比较小的呢个的倍数















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









