









简称 MMT
跨域无监督reid的典型代表之作,由CUHK的葛艺潇大佬出品,详细解读可以上某乎大佬的个人解读。
收录于ICLR2020
论文地址:https://openreview.net/pdf?id=rJlnOhVYPS
动机
1、解决聚类算法出现的噪声问题。
方法
1、MMT:离线修正难例标签和在线修正软标签。2、采用softmax-triplet loss。

一、聚类的一般方法
第一,输入通过网络得到特征,对特征进行聚类,得到的结果作为gt。(聚类会引入噪声)
第二,将这些特征经过分类器得到预测结果。
第三,在特征上做三元损失,在分类结果做softmax。
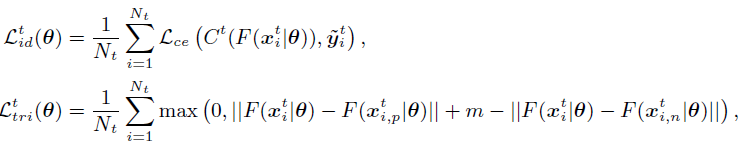
二、MMT的思想
1、对于源域数据,应用上述聚类思路和损失,不过gt用的就是输入本身的gt。
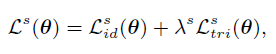
2、在线软伪标签修正

流程:
1、输入原图和随机擦除、裁剪和翻转后的图分别到net1和net2,并用聚类一般思路得到聚类结果,这里得到的是 hard pseudo labels。
2、用两个分类器得到它们的预测值。
3、用时间平均模型(mean net)产生软伪标签,公式如下:即将权值进行一个平均加权。解释为什么要用软标签——正常思路应该是直接用硬标签对互相产生的预测值进行损失约束,==个人理解:==两个net产生的label应该一致,同时又应该和它们各自聚类的gt保持一致。但作者认为这样会放大噪声,因此用mean net产生可靠的伪标签。
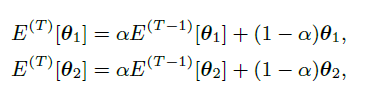
此外,作者认为用不同的过去net集成的mean net产生的标签(net 1的集成mean net 1是产生label给net 2)能让两个网络的预测软标签更加不想关,即提升鲁棒性降低错误率。
软标签产生公式如下:(交叉熵损失,log左边的是对另一个mean net进行分类的预测值作为gt,log右边是当前预测值)
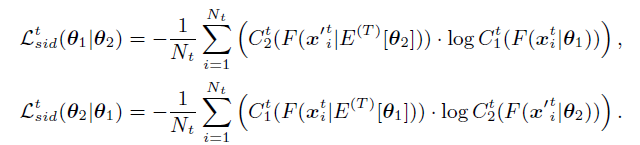
注意:MMT是用两个网络的平均模型产生软标签,然后作为不同的网络的gt。(即,mean net 1产生的软标签作为 net 2 的gt进行约束,同理对mean net2。)
3、softmax-triplet Loss 本文亮点之二(并不是本文原创公式,但是首次用于产生软标签)
因为原始的三元损失都是优化硬标签的,即anchor,positive和negative都是embedding feature,对于postive可以当作“1”,negative为“0”,本质上就是hard label。
作者提出了针对软标签的三元损失公式:
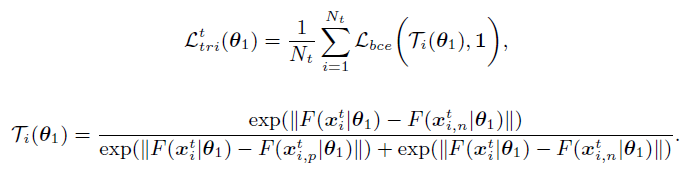
公式理解:bce是二元交叉熵损失,1是为了让positive和anchor更靠近,而anchor与negative更远,即分母中左边那项要越小越好。显然,这个形式和softmax函数很像了!!!
如下是最终的三元损失:同样对两个网络也是互相做Loss
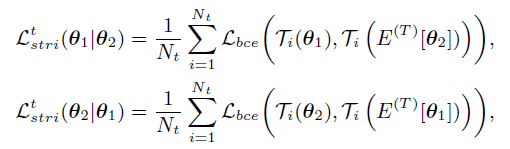
4、整体算法和损失
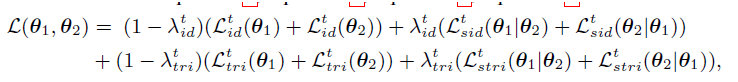
整体流程:

对于一个epoch,首先用聚类算法得到目标域的每个样本的伪标签;然后对于一个batch,通过时间平均模型产生软伪标签Ti和分类的hard标签;通过Loss更新标签;然后以平均加权方式更新 mean net。
实验

1、通过聚类设置为500,实际id不止这么多,但也达到了很好的效果。
2、和co-teaching方法比较:证明本文方法去噪的有效性(该方法和本文用的同一种聚类方法)

3、消融实验:验证不同模块的作用
一、验证软标签的作用——即,只用聚类得到的hard label,结果如table 2
二、验证提出的 softmax-triplet loss的有效性
三、验证MMT的有效性
本文是用了两个时序平均模型,并将它们的预测结果作为另一个student网络的软标签。作者也做了对比实验——1、只用一个temporal teacher的效果,然后生成软标签和本身的student网路做Loss,如table 2中的 w/o θ2。(即MEBnet的单模型思路)
2、只用两个student net以及它们互相的结果作为软标签然后训练。
四、验证hard 伪标签的必要性
tabel 2中的去掉Lid,t和只用Lsid,t+Lstri,t,效果变差。分析原因——初始的聚类标签很重要,因为网络初始通常对每个id都是统一的概率输出,即相当于一开始就是“软标签”,因此无法对目标域进行有效的区分,所以需要用到one-hot形式的hard label。
而作者认为,**hard的三元损失在本文中非必须,**作者认为提出的softmax-triplet 损失在训练初期酒能学习到预测更好的效果。(注意DFL的也是没有用三元损失,用了三元损失,效果变差)
附录部分的超参数实验

1、绿色线是没有时序集合网络的迭代效果,红色是加入了的。
2、对总体的Loss的超参数的实验:
总的loss中主要是两个超参数,固定一个实验另一个。















 2846
2846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









