







 本文深入探讨文本表示的三种核心方法:one-hot表示、词袋模型和TF-IDF,解析每种方法的工作原理、优缺点及应用场景,为自然语言处理提供理论基础。
本文深入探讨文本表示的三种核心方法:one-hot表示、词袋模型和TF-IDF,解析每种方法的工作原理、优缺点及应用场景,为自然语言处理提供理论基础。
目录
1.词向量的one-hot表示
拿英文举例,英语中大约有1300万个词组(token),不过他们是完全独立的吗?显然不是。例如,有一些词组,Feline猫科动物和Cat猫,Hotel宾馆和Motel汽车旅馆,其实有一定的关联或相似性存在。因此,我们希望用词向量编码词组,把词组表示为N维空间中的一个点(而点与点之间有距离的远近等关系,可以体现深层一点的信息,如含义的关联或相似性),每一个词向量的维度都可能会表征一些意义(物理含义),这些意义我们用"声明speech"来定义。例如,语义维度可以用来表明时态(过去,现在与未来),计数(单数与复数)和性别(男女)。
最简单的词向量编码方式是one-hot,这是一种离散表示方法:假设我们的词典总共有n个词,那我们开一个1*n的高维向量,而每个词都会在某个索引index下取到1,其余位置全部都取值为0(稀疏向量).词向量在这种类型的编码中如下图所示:
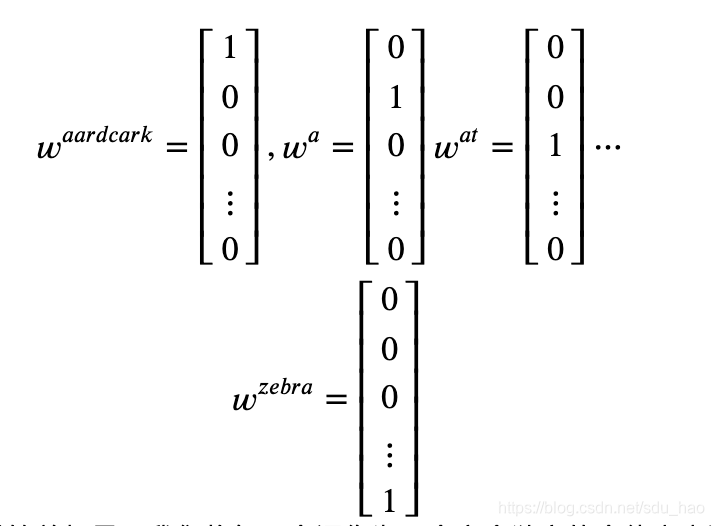
在one-hot表示方法下,每个词的词向量维度与词典大小相同,如a是词典中的第2个单词,那么在向量的第2个位置取1,其余位置全为0.
这种词向量编码方式简单粗暴,我们将每一个词作为一个完全独立的个体来表达。遗憾的是,这种方式下,我们的词向量没办法给我们任何形式的词组相似性权衡。例如
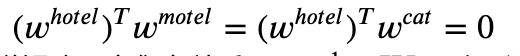
我们通常使用余弦相似度来衡量两个单词/词组的相似度,其中一个重要的操作就是对两个词向量做内积。我们期望如果两个词如果相似的话,那么他们对应词向量的余弦相似度应该接近于1。但是在one-hot的表示方法下,并不能体现这种关系,hotel和motel具有相似性,但他们的one-hot表示向量的内积却为0.
究其根本你会发现,是你开了一个极高维度的空间,然后每个词语都会占据一个维度,因此没有办法在空间中关联起来。因此我们可以把词向量的维度降低一些,在这样一个子空间中,可能原本没有关联的词就关联起来了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3748
3748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









