






Summary of 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
- https://arxiv.org/pdf/1810.04805
1.摘要
谷歌提出的BERT模型是建立在transformer的基础上,采用双向的transformer,以此建立一个通用的NLP模型,对于特定任务只需要加一个额外的神经网络层即可,相当于把下游任务的工作转移到预训练阶段。
BERT概念简单,经验丰富。它在11项自然语言处理任务上获得了新的最先进的结果,包括将GLE标准提高到80.4 % ( 7.6 %绝对提高),将MultiNLI准确度提高到86.7 % ( 5.6 %绝对提高),将 SQuAD v1.1 ques-tion answering Test F1提高到93.2 ( 1.5 %绝对提高),超出人类表现2.0。
2.准备工作
2.1Feature-based Approaches
Feature-based指利用语言模型的中间结果也就是LM embedding, 将其作为额外的特征,引入到原任务的模型中,例如在TagLM[1]中,采用了两个单向RNN构成的语言模型,将语言模型的中间结果
h
i
L
M
=
[
h
i
L
M
→
;
h
i
L
M
←
]
h_{i}^{L M}=\left[\overrightarrow{h_{i}^{L M}} ; \overleftarrow{h_{i}^{L M}}\right]
hiLM=[hiLM;hiLM]
引入到序列标注模型中,如下图所示,其中左边部分为序列标注模型,也就是task-specific model,每个任务可能不同,右边是前向LM(Left-to-right)和后向LM(Right-To-Left), 两个LM的结果进行了合并,并将LM embedding与词向量、第一层RNN输出、第二层RNN输出进行了concat操作。
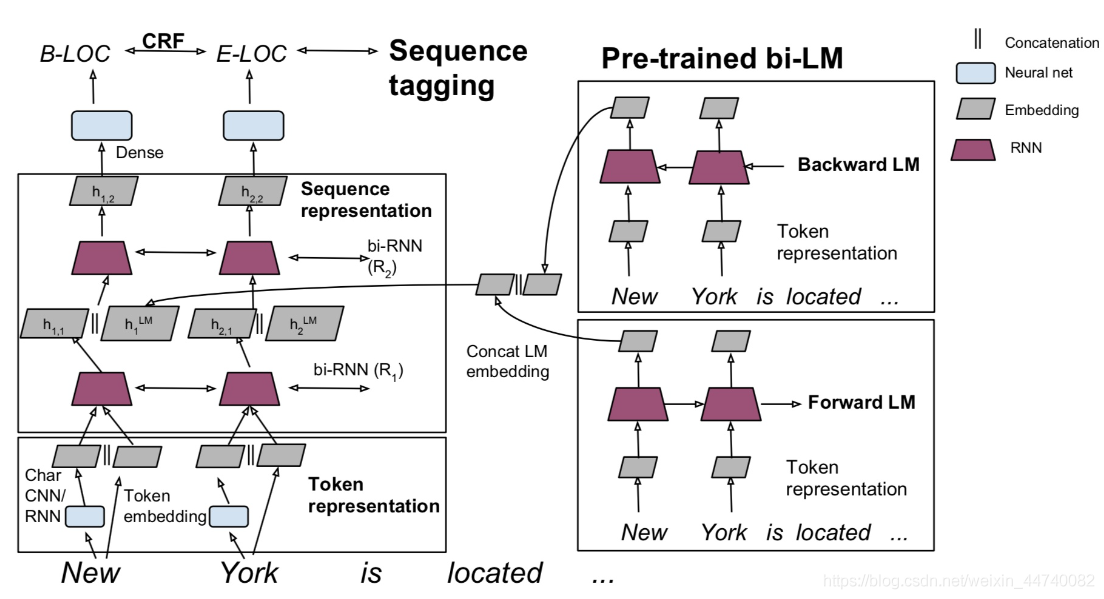
通常feature-based方法包括两步:
①在大的语料A上无监督地训练语言模型,训练完毕得到语言模型
②构造task-specific model例如序列标注模型,采用有标记的语料B来有监督地训练task-sepcific model,将语言模型的参数固定,语料B的训练数据经过语言模型得到LM embedding,作为task-specific model的额外特征
2.2Fine-tuning方法
Fine-tuning方式是指在已经训练好的语言模型的基础上,加入少量的task-specific parameters, 例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来进行fine-tune。
例如OpenAI GPT 中采用了这样的方法,模型如下所示
先语言模型采用了Transformer Decoder的方法来进行训练,采用文本预测作为语言模型训练任务,训练完毕之后,加一层Linear Project来完成分类/相似度计算等NLP任务。因此总结来说,LM + Fine-Tuning的方法工作包括两步:
①构造语言模型,采用大的语料A来训练语言模型
②在语言模型基础上增加少量神经网络层来完成specific task例如序列标注、分类等,然后采用有标记的语料B来有监督地训练模型,这个过程中语言模型的参数并不固定,依然是trainable variables.
3.BERT
3.1 Model Architecture
本论文提出两种大小的BERT结构:
B
E
R
T
B
A
S
E
:
L
=
12
,
H
=
768
,
A
=
12
,
Total Parameters
=
110
M
B
E
R
T
L
A
R
G
E
:
L
=
24
,
H
=
1024
,
A
=
16
,
Total Parameters
=
340
M
\begin{aligned} &B E R T_{B A S E:} \mathrm{L}=12, \mathrm{H}=768, \mathrm{~A}=12, \text { Total Parameters }=110 \mathrm{M} \\ &B E R T_{L A R G E:} \mathrm{L}=24, \mathrm{H}=1024, \mathrm{~A}=16, \text { Total Parameters }=340 \mathrm{M} \end{aligned}
BERTBASE:L=12,H=768, A=12, Total Parameters =110MBERTLARGE:L=24,H=1024, A=16, Total Parameters =340M
其中L表示transformer层数,H表示transformer内部维度,A表示head的数量
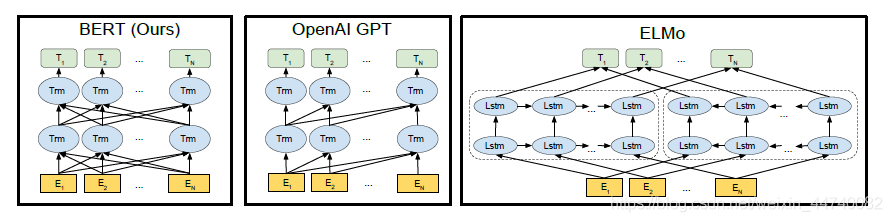
其中 B E R T B A S E B E R T_{B A S E} BERTBASE与OpenAI GPT的参数数量是相同的,模型结构如下所示,BERT是双向的transformer block连接,OpenAI GPT是单向的,只接受左侧信息的,句子中每个词只能对包括自己的前面的词进行attention。防止间接看到自己。而ELMo虽然也是‘双向’,但是它是分别由从左到右,和从右到左训练之后拼接起来的,但目标函数其实是不同的。ELMo是分别以 P ( w i ∣ w 1 , … w i − 1 ) P\left(w_{i} \mid w_{1}, \ldots w_{i-1}\right) P(wi∣w1,…wi−1)和 P ( w i ∣ w i + 1 , … w n ) P\left(w_{i} \mid w_{i+1}, \ldots w_{n}\right) P(wi∣wi+1,…wn) 作为目标函数,独立训练处两个representation然后拼接,而BERT则是以 P ( w i ∣ w 1 , … , w i − 1 , w i + 1 , … , w n ) P\left(w_{i} \mid w_{1}, \ldots, w_{i-1}, w_{i+1}, \ldots, w_{n}\right) P(wi∣w1,…,wi−1,wi+1,…,wn) 作为目标函数训练LM。
3.2 Input Representation
文章的输入可以是单个句子也可以是句子对(问题,答案)的形式,对于每一个输入的token,由三部分:token, segment and position embeddings求和表示。如下图所示:
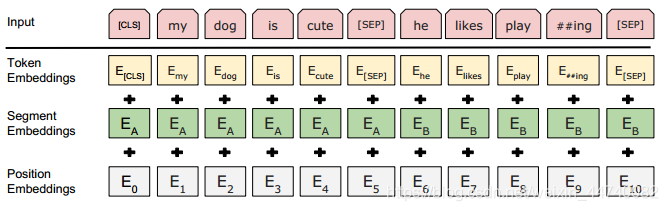
1.token是字符表示,在每一个句子的第一个token都是[CLS],对应于该token的最终隐藏状态(即,Transformer的输出)被用作分类任务的聚合序列表示。如果不是分类任务,将忽略此向量。
2.segment embedding 是当前词所在句子的索引,因为本模型可能会处理句子对的形式(eg.问答任务),用A,B分别表示第一个句子和第二个句子,如果是单个句子任务,那么segment embedding均为A。
3.position embedding 是当前词在整个输入中的位置索引。
3.3 Pre-training Tasks
3.3.1 Task #1: Masked LM
双向模型会导致预测的下一词已经在给定序列中出现了的问题,为了解决这种现象,本文提出了一种masking方法,随机mask一定比例的token,然后仅仅预测这部分被masking的token,本文将这种方法叫做“masked LM”(MLM),就像做完形填空一样,根据上下文信息判断空格处的单词,根据这个时候的hidden 向量,通过softmax判断这个masked token应该是什么。该论文将mask每一个句子中15%的token。
3.3.2 Task #2: Next Sentence Prediction
许多下游任务,比如问答,自然语言推理等,需要基于对两个句子之间的关系的理解,而这种关系不能直接通过语言建模来获取到。为了训练一个可以理解句子间关系的模型,作者为一个二分类的下一个句子预测任务进行了预训练,这些句子对可以从任何单语言的语料中获取到。特别是,当为每个预测样例选择一个句子对A和B,50%的时间B是A后面的下一个句子(标记为IsNext), 50%的时间B是语料库中的一个随机句子(标记为NotNext)。图1中,C用来预测下一个句子(NSP)。尽管简单,但是该方法QA和NLI任务都非常有帮助。5.1节对此有展示。
NSP任务和 Jernite et al. (2017) and Logeswaran and Lee (2018)中的表示学习的目标密切相关。任务,先前的工作中,只将句子嵌入转移到了下游任务中,而BERT转移了所有参数来初始化终端任务模型的参数。
4 Experiments
在这部分,该论文在11个NLP任务上进行了实验,并取得了当时最好的结果















 3673
3673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









