









GAN介绍 - 介绍 https://blog.csdn.net/sean2100/article/details/83662975
GAN介绍 - 为什么学习生成式模型? https://blog.csdn.net/sean2100/article/details/83681043
GAN介绍 - 生成式模型是如何工作的? GAN与其他模型有什么区别?https://blog.csdn.net/sean2100/article/details/83907062
GAN介绍 - 提示与技巧 https://blog.csdn.net/sean2100/article/details/83964523
GAN介绍 - 相关研究课题 https://blog.csdn.net/sean2100/article/details/84010202
GAN介绍 - 即插即用生成网络(PPGN) https://blog.csdn.net/sean2100/article/details/84032930
GAN介绍 - 练习题 https://blog.csdn.net/sean2100/article/details/84037752
GAN介绍 - 练习题答案 https://blog.csdn.net/sean2100/article/details/84037768
GAN介绍 - 总结 https://blog.csdn.net/sean2100/article/details/84010467
May 9, 2017
有一些技巧可以提高GAN的表现, 但是比较困难去解释这些技巧有多么的有效。 有些技巧看起来对有些情况有效,但是对另一些情况起到反作用。 这些技巧只能作为值得去尝试的技术,而不是通用的最优的方法。
NIPS2016有一个对抗学习的专题讨论会, 其中Soumith Chintala将做一个关于如何训练GAN的邀请演讲。 这个演讲或多或少的与此部分的内容有相同的目标。 想了解更多的不包含在此介绍中的技巧,请参考Soumith的演讲内容(https://github.com/soumith/ganhacks)。
4.1 使用标签(Label)训练
不管以任何形式使用标签, 模型生成的样本的质量,无论是在形状或者构成上主观上判断几乎总会有很大的提高。 Denton et al. (2015)首先观察到了这种现象, 通过使用class-conditional GAN生成的样本比GAN生成的样本要好很多, 并且可以生成任何类的样本。 后来, Salimans et al. (2016)发现甚至当生成器不是显式的包含类信息时样本质量也可以提高, 此工作说明了通过学习判别器来识别真实样本的特定的类也是很有效的提高生成样本质量的方法。
现在还不是很清楚,为什么这个技巧很有效。 可能是因为合并使用类信息给训练过程提供了有用的线索, 对优化过程有帮助。 也可能是此方法客观上没有提高样本质量, 而只是让样本发生改变而呈现出对人类视觉友好的属性。 如果是后者, 那么这个技巧不会导致产生一个在真实数据生成分布上的更好的模型, 但是它仍然可以帮助创建供人类观众享受的媒介, 并且可以帮助RL(增强学习)程序来处理那些与人类相关的知识以及环境的任务。
很重要的一点是,在进行比较时, 我们需要比较那些都使用此技巧的不同的方法。 比如说, 使用标签训练的模型与其他的使用标签训练的模型做比较, class-conditional模型只与其他的class-conditional模型比较。 一个使用标签训练的模型与一个没有使用标签训练的模型做比较是不公平的,也是一个无趣的基准。 这就类似于在图像任务上,卷积网络通常会比非卷积网络表现的好是一样的道理。
4.2 单侧标签平滑(One-sided label smoothing)
GAN是通过估计判别器对两个密度的比率来工作的, 但是深度神经网络倾向于产生高置信的输出来识别正确的类, 并且通常会有很极端的概率值。 当深度网络的输入是对抗的组成时, 此问题特别的突出。 分类器倾向于线性推断, 并且产生极高置信值的预测 (Goodfellow et al., 2014a)。
为了鼓励判别器来估计一个柔性的概率,而不是预测极端置信的分类, 我们使用一个被称为单侧标签平滑的技术 (Salimans et al., 2016)。
通常情况下,我们使用公式8来训练判别器。 使用TensorFlow(Abadi et al., 2015)的代码来表达如下:

单侧标签平滑技术的思想是调整目标为真实的样本的值(原来是1)为一个比1略小的值, 比如0.9:

这种做法可以避免判别器的极端预测行为: 如果判别器通过学习来预测一个极端大的逻辑值,也就是对某些输入的输出概率接近于1时, 它将被惩罚并被鼓励回到一个较小的逻辑值上去。
不对伪样本的标签进行平滑处理是很重要的。 假设我们使用一个目标值1−α1−α为真样本, 并且使用目标值0+β0+β为伪样本。 那么最优的判别器函数将变为:
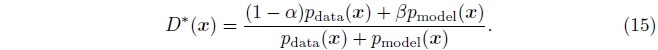
当ββ是零时, 那么通过αα的平滑将仅仅是按比例缩小判别器的最优值。 当ββ非零时, 最优判别器的函数形状会发生变化。 特别是, 在pdata(x)pdata(x)很小且pmodel(x)pmodel(x)很大的区域, D∗(x)D∗(x)将会在pmodel(x)pmodel(x)的伪造的mode中出现一个峰值。 判别器将鼓励生成器的不正确的行为: 从而导致生成器或者产生与数据类似的样本,或者产生与已经产生过的样本类似的样本。
单侧标签平滑是对很多以前的标签平滑技术的一个简单的修改, 标签平滑技术最早可以追溯到至少1980年代。 Szegedy et al. (2015)展示了标签平滑在识别任务的卷积网络中是一个极好的正则器。 标签平滑作为正则器如此有效的原因是它在训练集上不是鼓励模型选择非正确类别,而是仅仅降低正确类的置信值。 其他的正则器比如说权值衰减(Weight decay), 当正则器的系数被设置的足够大时,其经常鼓励一些错误分类。 Warde-Farley and Goodfellow (2016) 展示了标签平滑可以帮助降低针对对抗样本的脆弱性, 这可以理解为标签平滑应该可以帮助判别器更有效的学习如何抵抗生成器的攻击。
4.3 Virtual batch normalization(虚拟批量标准化)
由于DCGAN的介绍,当前多数的GAN架构都使用了某种形式的batch normalization。 Batch normalizaiton的主要目的是通过对模型进行重新参数化来提高模型的优化, 此方法是: 一个特征的平均和方差通过使用一个对应此特征的简单的平均参数和一个简单的方差参数来决定, 而不是使用一个用来提取特征的所有层和参数的复杂的相互关系来决定的。 重新参数化通过对minibatch的数据的特征减去平均值,并除以标准方差来完成的。 标准化操作设计为模型的一部分是很重要的, 从而使反向传播总是对被标准化的特征计算梯度。 当标准化不是被定义为模型的一部分时, 也就是说,当特征在训练完成后进行标准化时, 这个方法将不会很有效。
Batch normalization很有用, 但是对GAN来说有几个不幸的侧面的影响。 在每一步的训练过程中,使用不同的minibatch数据来计算标准化的统计特性,会导致这些标准化参数常量引起波动。 当minibatch比较小的时候, 这个波动将会变得足够大, 以至于对GAN生成图像的影响比zz都大。 请参考图21的例子。

图21: 两个minibatch, 每一个有16个样本, 由使用了batch normalization的生成式网络产生。 这些minibatch展示了当使用batch normalization时偶尔会发生的问题: minibatch中特征值的平均值和标准方差的波动可能比独立的zz对minibatch中独立的图像有更大的影响。 这里列举的是,其中一个minibatch包含全是橘黄色的彩色样本,另一个包含全是绿色的彩色样本。 minibatch中的样本应该是彼此相互独立的, 但是在这种情况下, batch normalization导致他们变得互相的有联系。
Salimans et al. (2016)介绍了一些技术来缓和此问题。 Reference batch normalization(参考批量标准化)包含运行网络两次: 第一次是对一个minibatch的参考样本, 这里的参考样本是在训练开始以前被采样并且是保持不变的; 另一个是对当前的minibatch的样本进行训练。 特征的平均值和标准差使用参考样本的batch进行计算。 然后,使用这些统计的信息对两个batch的特征进行标准化处理。 此方法的一个缺点是模型容易对参考batch的样本过拟合。 为了稍微缓解此问题, 可以使用虚拟batch normalization, 对一个样本标准化时使用的统计信息是通过此样本与参考batch的联合来进行计算的。 不管是Reference batch normalization还是虚拟的batch normalizaiton都有一个特性,也就是,在训练过程的minibatch的所有样本(真实的样本,以及所有的由生成器产生的样本(除了那些定义参考batch的样本))都是被相互独立的处理, 并样本满足独立且同分布(i.i.d: Independent and identically distributed)。
4.4 可以平衡G和D吗?
很多人凭直觉认为, 需要去平衡两个玩家以防止一个战胜另外一个, 即便是这个平衡是可以接受并且可行的。 但是,我们还没有看到有任何令人印象深刻的方法使用它。
作者现在认为,GAN通过评估数据和模型的密度的比值来起作用。 当判别器是最优时, 这个比例可以被正确的估计, 因此判别器战胜生成器是好的情况。
当判别器的置信值太高时, 生成器的梯度会消失。 解决此问题的正确方法不是限制判别器的能力,而是在梯度没有消失的地方,对游戏进行参数化处理。(参考3.2.3章)
有时, 如果判别器的置信值太高, 生成器的梯度会变得很大。 解决此问题较好的方法是使用单侧标签平衡技术,而不是降低判别器的准确率。(参考4.2章)
为了最好的估计比值, 判别器应该总是最优的, 所以建议每一次训练,训练判别器k(k>1)k(k>1)步, 训练生成器一步。 在实际应用中, 这种做法并不能总是带来明显的提高。
可以尝试通过选择模型的大小来平衡生成器和判别器。 在实际应用中, 判别器通常是较深的, 与生成器相比, 判别器在每个隐含层有更多的过滤器(filter, 这里指的是CNN网络)。 这可能是因为,让判别器来正确的估计数据和生成器密度的比值是很重要的, 但是他也可能人为的造成mode collapse问题–因为使用当前的训练方法, 生成器不倾向于使用它的所有的能力。 研究者们大概没有看到通过提高生成器的能力会带来太多的好处。 如果mode collapse问题可以被克服, 生成器的大小应该会被提高, 但是并不清楚是否判别器也需要相应的提高尺寸。
[最终修改于: 2017年6月10日]
来源:https://sinpycn.github.io/2017/05/09/GAN-Tutorial-Tips-and-Tricks.html















 6679
6679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









