







今天在网上看到这篇文章The Impact of Imbalanced Training Data for Convolutional Neural Networks,里面做了一系列实验讨论训练样本对CNN的影响。
作者前面先是介绍了CNN和深度学习的相关知识,然后介绍了几个流行的数据集,ImageNet、mnist、CIFAR-10 and CIFAR-100。
然后利用较小的CIFAR-10来做验证。所谓的样本不平衡指的是各个类别的样本数量差别很大。一般的机器学习算法在这样的数据下表现都不好,那么对CNN有什么影响呢。
CIFAR-10是一个简单的图像分类数据集。共有10类(airplane,automobile,bird,cat,deer,dog, frog,horse,ship,truck),每一类含有5000张训练图片,1000张测试图片。网络使用的是CIFAR-10的结构。

第一个实验:
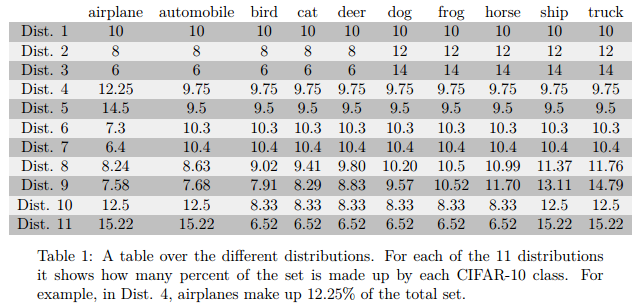
上图中,每一行是一组数据,共十种类别,其中的数字是指每类占总数的比例。可以看到dist.1是完全平衡的,后面的不平衡性越来越大。
Dist. 1:类别平衡,每一类都占用10%的数据。
Dist. 2、Dist. 3:一部分类别的数据比另一部分多。
Dist. 4、Dist 5:只有一类数据比较多。
Dist. 6、Dist 7:只有一类数据比较少。
Dist. 8: 数据个数呈线性分布。
Dist. 9:数据个数呈指数级分布。
Dist. 10、Dist. 11:交通工具对应的类别中的样本数都比动物的多
对每一份训练数据都进行训练,测试时用的测试集还是每类1000个的原始测试集,保持不变。
下面我们来看看训练结果:
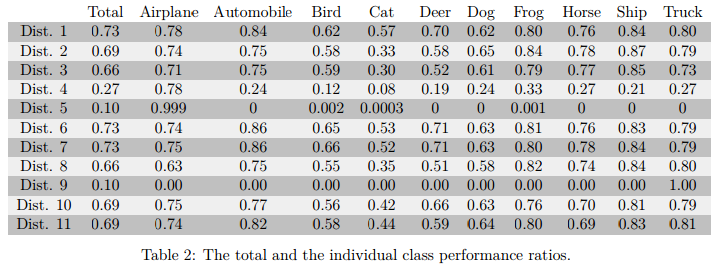
上表的每一列代表这种类别在十一次实验中的准确率,最左边的一列是总的准确率。可以看出总的准确率表现不错的几组1,2,6,7,10,11都是大部分类别平衡,一两类差别较大;而表现很差的,像5,9可以说是训练失败了,他们的不平衡性也比前面的要强。
下面是经过过采样的样本训练的结果:
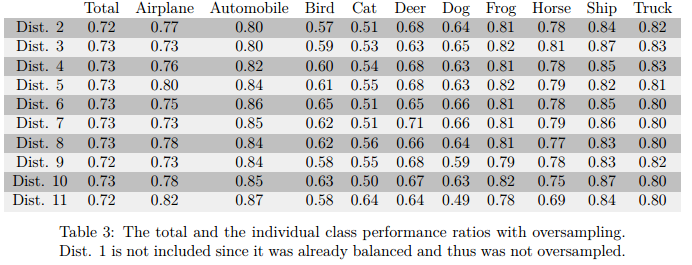
可以看到经过过采样将类别数量平衡以后,总的表现基本相当。
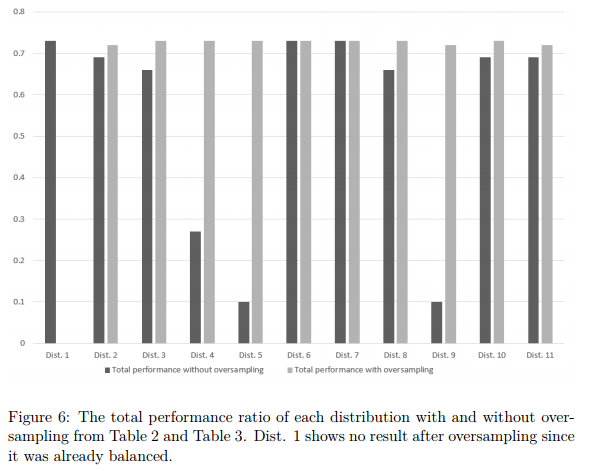
上图是过采样前后的训练结果对比,深色是未经过过采样的,浅色的经过过采样的。所以得到的结论是在训练之前需要将数据库平衡化,可以采取过采样的方式。
这个结论也是实验得出的,在实际应用中是个经验公式。















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









