







撰写时间:2017.08.31
撰写内容:使用tensorflow实现batch normalization
写在开头:batch normalization不是很难的内容,但是如果不自己通过一些低级的API实现总会觉得有些细节很难触碰到,所以下面的内容就是如何使用tensorflow实现batch normalization。
文章分为两部分:
1.实现过程中使用的API,务必在实现之前了解这些api的使用
2.实现batch normalization,代码来自于stackoverflow上面的一个回答。
代码是否可用,并没有测试。我也是今天早上做项目的时候需要使用bn,所以花了一天时间,边学习,边记录才有了这篇博文。对于文中API解释不清楚的,可以搜一搜tensorflow的官方问答,或者其他博文。最后所有的测试代码,可以从我的github地址上下载(还没上传。。)
2017.9.4更新:
代码可以使用,而且效果很好,训练速度有明显的提成,我的项目的代码地址,
tensorflow API
assign
返回值是op,而不是tensor
1.tf.assign()
2.tf.assign_sub()
3.tf.assign_add()
dependency
1.tf.control_dependency()
人为的在两个操作之间添加关联关系
with tf.control_dependency([op1,...])
op2即op2是依赖于op1的,在运行op2时需要调用op1
2.tf.identity()
Return a new tensor with the same shape and contents as the input tensor or value.
import tensorflow as tf
x = tf.Variable(0.0)
x_plus_1 = tf.assign_add(x, 1)
with tf.control_dependencies([x_plus_1]):
y = tf.identity(x)
#y = x
init = tf.global_variables_initializer()
with tf.Session() as session:
init.run()
for i in xrange(5):
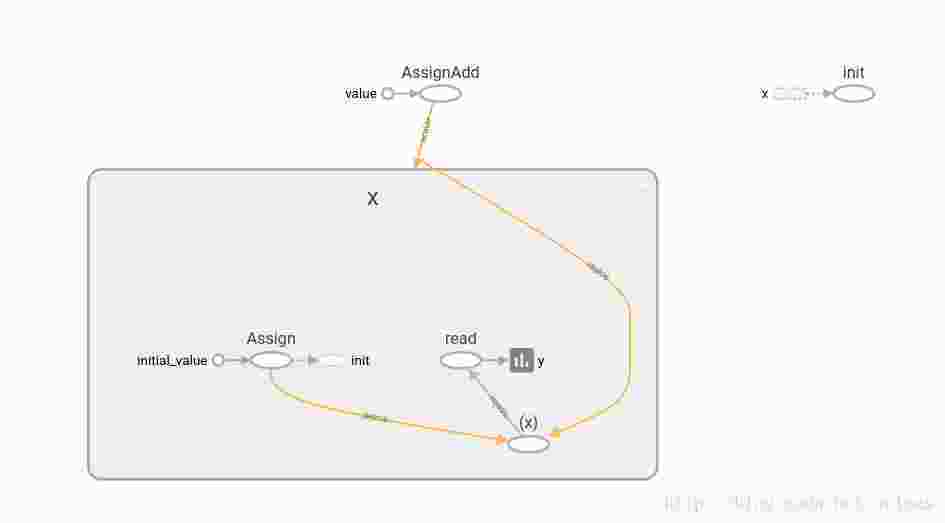
print(y.eval())with “y=x”,并不会创建变量,而且不是op,所以tf.control_dependencies并不会生效。
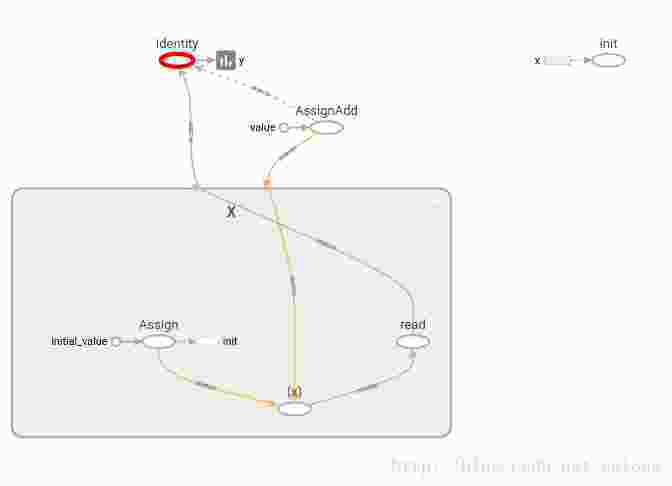
with “y=tf.identity(x)”,每次取y的值,x都会自动加1
ExponentialMovingAverage
1.apply()
1.adds shadow copies of trained variables
2.add ops that maintain a moving average of the trained variables
调用形式
with tf.control_dependencies([op1]):
ema_op = ema.apply([var1])注:op1是更新变量var1的,然后先储存var1修改前的变量值,shadow variables。然后执行op1,取出修改后变量为variable。最后创建一个更新shadow variables的op,
shadow_variable = decay * shadow_variable + (1 - decay) * variable
2.average()
Returns the Variable holding the average of var.
取出apply中计算的值
import tensorflow as tf
w = tf.Variable(1.0)
b = tf.Variable(1.0)
ema = tf.train.ExponentialMovingAverage(0.9)
#使add操作的返回值为op,而不是数值
#如果是数值,那么control_dependency就不能依赖了
update_w = tf.assign_add(w, 1.0)
update_b = tf.assign_sub(b,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









