







对struck SVM的理解,很关键的一点是对支持向量的选择过程的理解,最终模型的效果好不好,也取决于选择的sv是否具有代表性。这里,可以先把对第一幅图学习后得到的sv的情况打出来,从而从数据入手,一边提问题,一边解决问题,这其实就是理解作者思路的过程。
根据第一幅图得到10个sv:
| SV序号 SV结构 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| sv.b | 4.6352 | -0.53 | -0.2418 | -2.588 | -0.5559 | -0.5452 | -0.0756 | -0.0463 | -0.0321 | -0.0203 |
| sv.spIndex | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| sv.y | 1 | 31 | 32 | 41 | 36 | 40 | 20 | 29 | 23 | 37 |
| sv.g | -1.0638 | -1.0638 | -1.0638 | -1.0638 | -1.0638 | -1.0638 | -1.0638 | -1.0638 | -1.0638 | -1.0638 |
这些sv之间的Kernel(衡量了sv之间特征向量的相似度)构成的gKernelMatrix是这样的:
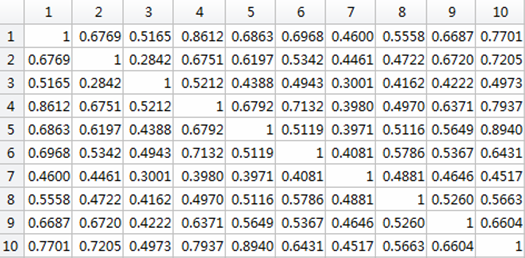
于是,从这两幅数据中,我们可以提出一些疑问:
①只有第1个sv是正sv,它的系数b>0。为啥?
②有没有发现后面9个负sv与正sv的相似度都比较大(都>0.45),为啥要从一堆sample中选出与正sv相似度比较高的作为负sv呢??
③第4个sv与第1个sv(也是唯一一个正sv)的相似度很大,高达0.8612,而且第4个sv的权重也比较大(b的绝对值)。说明第4个sv对于决策起到很重要的作用。但有个问题,第10个sv和正sv的相似度也很大,但第10个sv的系数b却很小,这是因为什么呢??(第4个sv是第41个sample,第10个sv是第37个sample,与真实目标重叠率都为0,而且眼肉看的话,其实特征情况相差也不大,但为什么第10个sv那么小呢??)
④结构中的g到底是什么含义呢?
为了方便之后的观察,我们也打出这10个sv的图像内容以及与真实boundingbox的位置关系:

(其中,上图显示了当前sv与真实boundingbox的位置关系;下图表示了真实bounding box内的图像内容以及当前sv(左上角标出的是sample的序号)中的图像内容)
下面,我们开始解决这些疑问。
Struck:Structured Output Tracking with Kernels对应的matlab代码中有个很重要的变量g(指的是sample对应的特征向量的梯度),对应论文的这个公式:

Tip 1:为什么要找到g最小的sample作为负sv呢???
来看一下g的含义:

因为要找到g最小,理想情况是-learner_loss和-learner_evaluate都小,分开详细来看这两部分:
①-learner_loss小 当前sample与真实目标boundingbox的重叠率小
②在分析-learner_evaluate的大小与什么有关之前,先看一下learner_evaluate是怎么得到的,对应代码如下:

找到-learner_evaluate小的,也就是找到learner_evaluate即score大的。为了比较什么情况下learner_evaluate的值大,什么情况下learner_evaluate的值小,我们假设有两个sample:
(这里需要注意:正sv的系数b>0,负sv的系数b<0。)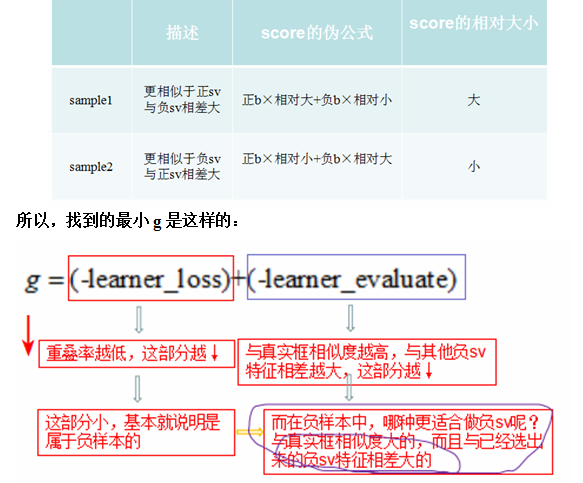
Tip 2:由Tip1变为了为什么要找到与真实框重叠率低,且与真实框相似度高,与已经选出来的负sv特征相差大的作为负sv??
也许下面这幅图可以帮助我们更直观的理解:
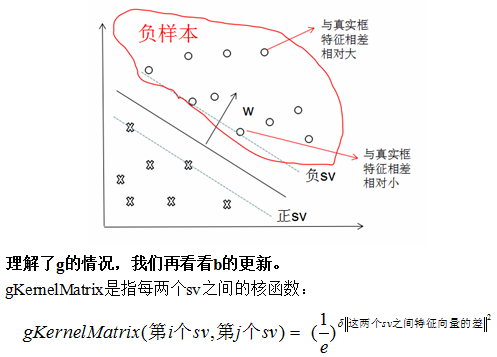
即:两个sv之间相似度越大,它们之间的Kernel就越大。也就是Kernel值的大小代表了sv之间相似度。
对应的代码是:

这个smo算法和梯度g联系很密切,关乎到sv系数b的变化。
这里我们会考虑到,执行smo算法是在哪个过程中?论文中提到了三种不同的更新步骤:PROCESS NEW、PROCESSOLD、OPTIMIZE PROCESSES,在执行这几个更新过程选出正负sv的最后,都要通过smo算法来调整参数,它们的执行过程分别描述如下:

对这部分的理解:
添加正sv:真实目标框
添加负sv:当前g最小的sample
为了方便理解,我们始终把g看成两部分来分析,一部分和重叠率有关,一部分和与当前sv的相似度有关。通过之前对g的含义的分析,我们把对g的比较看做是重叠率以及相似度的比较。因为看了很长时间,要说g到底代表什么物理意义,好像并没有一个很合理的说法。
之前已经提到,g是这样的:

所以,选出的作为负sv的sample是与真实框重叠少,但与真实框的特征相似,与负sv的特征相差大的。

对这部分的理解:
选出“正”sv:当前g最小的sv
(注意上面的一句话: 这意味着这个最大化仅仅是从引用这个支持模式的支持向量中选择。 这里是“选出”,也就是说从之前已经选中作为 sv 的并且引用这个支持模式中的 sample 中选出一个作为当前的“正 sv ”,并没有添加新的 sample 作为正 sv 。但是,选中的这个正 sv 并不一定是那个真正的正 sv ,也可能出现把负 sv 选出来作为当前的“正” sv 的情况,这个可以通过后面的输出观察到,这就相当于在改变之前某个 sv 的系数,更新方式见 smo 算法,涉及到系数 b 增加和减小,增加和减小的程度,为啥要这样更新呢??这个问题在最后的准则总结中,会详细回答 ...... )




第13步有个对g的更新过程,之前执著于研究g什么时候增大,什么时候减小。而且还想,为啥要把不是正sv的选出来“正sv”和负sv作为一对,进行更新呢?固定住每次都选出真实的正sv作为正sv不行吗?于是,我让每次进入smo算法时的ip都固定为当前支持模式中的真实目标框所在的sv,打出来这种方式下,第一幅得到的sv的情况如下:
| SV序号 SV结构 | 1 | 2 | 3 | 4 | 5 | 6 |
| sv.b | 5.1160 | -1.5473 | -0.8786 | -2.3833 | -0.2224 | -0.0845 |
| sv.spIndex | 1 | 1 | 1 | 1 | 1 | 1 |
| sv.y | 1 | 31 | 32 | 41 | 40 | 36 |
| sv.g | -1.3496 | -0.8856 | -0.9250 | -1.3040 | -1.3387 | -1.3496 |

出现错误了:
在红色框圈出的那一步,第一个sv的g竟然成了最小的,后来想到不应该让每次进入smo算法时的ip都固定为当前支持模式中的真实目标框所在的sv,这样第一个sv的g还是在更新的。
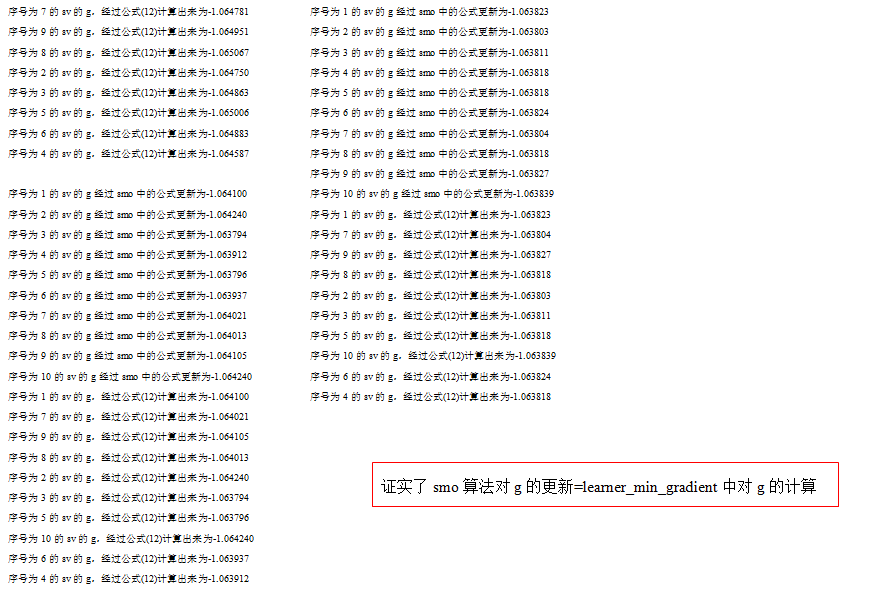
后来想到,在smo中,应该不让第一个sv的g还更新,这样才能保证第一个sv的g始终是最大的。后来发现也错了,通过min_gradient计算出来的第一个sv的g已经不等于0了。也就是g一定要变,不能不变。我把焦点放在了那两个g的公式上,惊奇地发现,第13步那个对g的更新方式其实和前面讲到的的对g的计算的公式是一样的。
我把这两个计算公式的结果打出来,结果一看,果然是相同的,利用min_gradient计算出来的g与每次PROCESS之后进行的smo中对g的更新一致。


哈哈,按现在问题就聚焦在b上啦~b的变化又是由lambdaU的大小决定着。而lambdaU,它的大小是这样的:

从一堆sample中选出一些作为sv的准则:可以戳前一篇博客















 3625
3625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









