




一、基础能力评测
1、能力评测汇总


2、 基础能力评测三个维度
- 语言生成能力
- 知识利用能力
- 复杂推理能力
3、语言生成能力评测
- 主要问题
- 不可靠的文本评估
- 自动评估存在不全面问题
- 人工评估存在可靠性问题
- 特定专业领域生成能力偏弱
- 使用特定领域训练大模型会导致模型在其他领域性能下降
- 不可靠的文本评估
4、知识利用能力评测
- 知识利用任务类型
- 闭卷问答(基于模型自身知识)
- 开卷问答(基于自身以及外部知识)
- 知识补全
- 存在问题
- 幻象:大模型生成内容与提示内容关联度差,通过微调对齐可以一定程度上改善
- 知识时效性:通过外部知识补充是一种方式,但是无法实时更新模型内部参数,最终生成内容质量相较使用模型内部知识生成较差
5、复杂推理能力评测
- 分类
- 知识推理
- 数学推理
- 主要问题
- 推理一致性差:多次推理结果可能不一致
- 数值计算:不依赖外部计算器能力情况下,数值计算效果差
二、高级能力评测
- 人类对齐
- 环境交互
- 工具使用
1、人类对齐
- 有用性:评价模型根据人类需求完成特定任务的能力,例如知识问答、代码合成、文本
写作等 - 诚实性:从事实性、前后一致性等维度、幻象
- 无害性:是检测大语言模型所生成的文本中是否存在偏见、歧视等有害因素
2、环境交互
- 检验行动计划的可行性和准确性
- 通过实际任务的执行成功率来衡量模型与环境的交互能力
3、工具使用
- 搜索工具评测
- 模型工具评测
- 综合工具评测
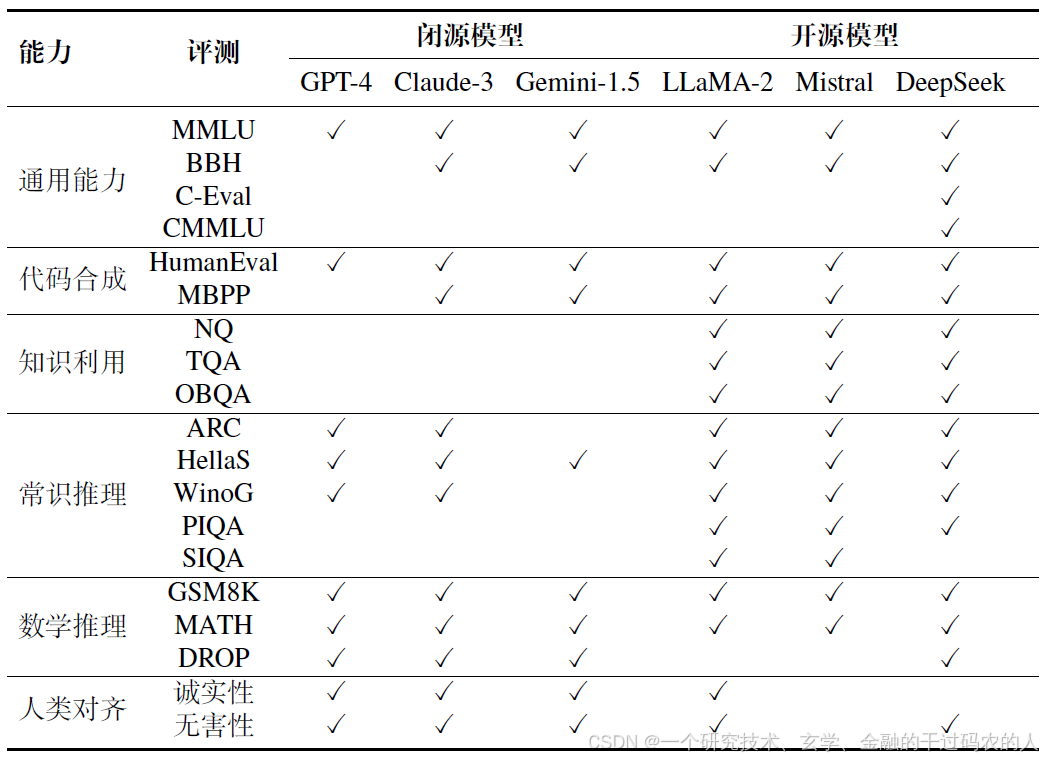
三、综合评测(主流LLM及评测数据集)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









