




 本文介绍了一种在推荐系统中用于压缩embedding表的高效算法——基于二进制码的HashEmbedding,通过特征哈希、二进制化、代码块策略和十进制化步骤,减少存储需求并保持模型效果。
本文介绍了一种在推荐系统中用于压缩embedding表的高效算法——基于二进制码的HashEmbedding,通过特征哈希、二进制化、代码块策略和十进制化步骤,减少存储需求并保持模型效果。
推荐系统中,ID类特征的表示学习(embedding learning)是深度学习模型成功的关键,因为这些embedding参数占据模型的大部分体积。这些模型标准的做法是为每一个ID特征分配一个unique embedding vectors,但这也导致存储embedding table需要消耗巨大的内存。
在上一篇文章中 Embedding压缩之hash embedding,介绍了几种常见的hash embedding方法来对embedding进行压缩,实现模型的瘦身。今天继续介绍一种阿里在CIKM 2021的论文中提出的方法:基于二进制码的hash embedding,该方法兼具了调整embedding存储的大小的灵活性和尽可能保留模型的效果。
算法流程
Binary code based Hash Embedding的算法流程如下图,主要分为了3步:特征hash、embedding索引生成、embedding向量生成。
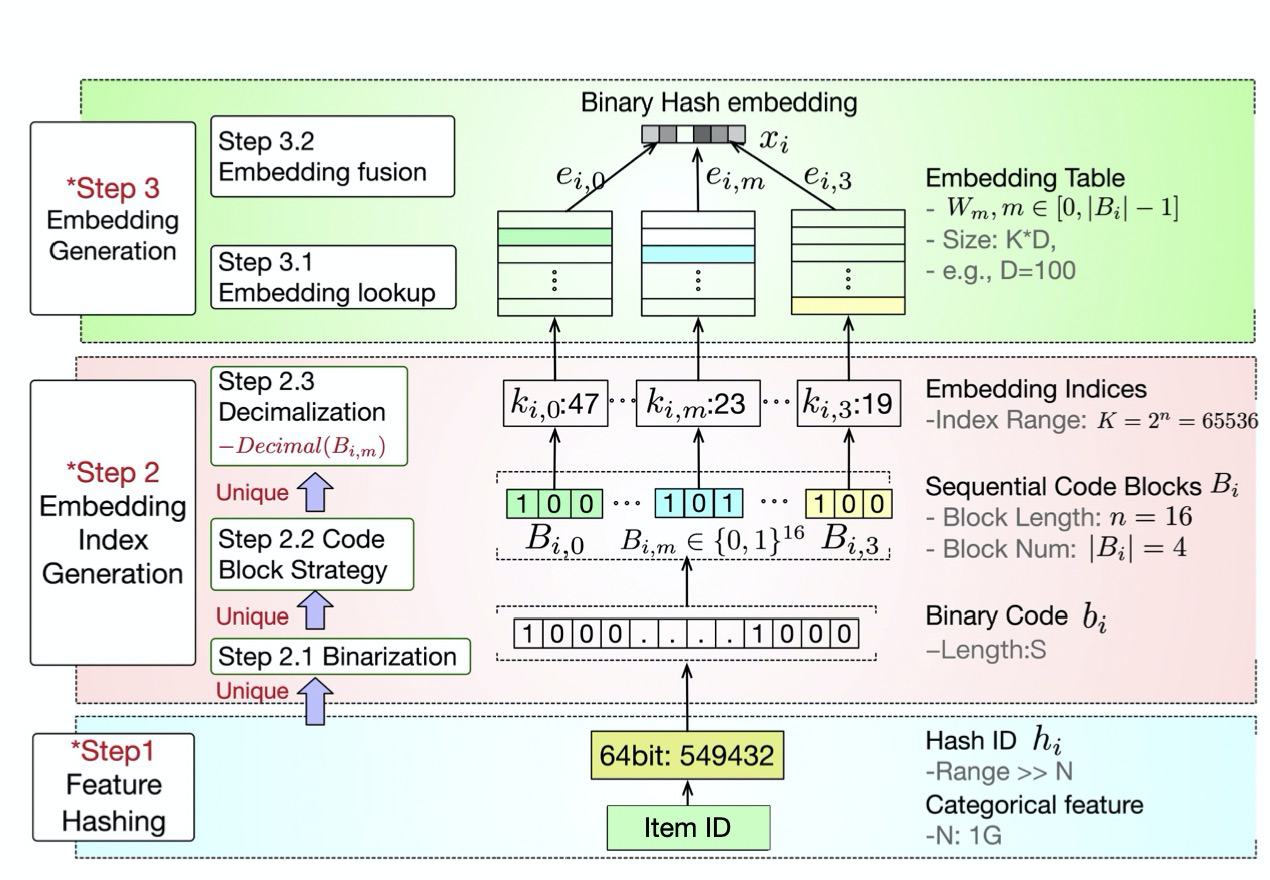
特征Hash
ID类特征的来源是多种类型,比如字符串或者整型,实际中的做法分为两种:
- 提前创建映射表,即将不同的特征值映射到对应的unique id,这种做法的缺点是不灵活,难以应对特征值的动态扩展,并且需要保存映射表;
- 另一种做法则是使用特征Hash,可以直接将原始特征值映射到Integer,如上图[Binary Hash Embedding-Step1],称为Hash ID:
h i = H ( f i ) h_i=\mathcal{H}(f_i) hi=H(fi)
其中, H \mathcal{H} H为hash函数(如Murmur Hash), h i h_i hi为特征值 f i f_i fi的Hash ID。为了尽量降低 h i h_i hi之间的冲突, H \mathcal{H} H的输出通常是一个比较大的数值,比如64位的Integer。
embedding索引生成
如上图[Binary Hash Embedding-Step2],Embedding索引生成分为3步:Binarization、Code Block Strategy和Decimalization。
Binarization
在特征Hash之后,每一个特征值可以认为是拥有一个对应的唯一(没有冲突)的Hash ID。
在这一步,会将Hash ID转化为一个二进制码 b i ∈ { 0 , 1 } S b_i \in \{0,1\}^S bi∈{ 0,1}S,S为二进制码的长度,如上图[Binary Hash Embedding-Step2.1],比如13的二进制码是 110 1 2 1101_2 11012。
因为10进制转2进制这个过程是不包含任何参数,并且计算逻辑是固定的,因此二进制码 b i b_i bi是可以与特征值 f i f_i f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









