









从上一篇文章 多场景建模: STAR(Star Topology Adaptive Recommender) 开始,我们便开启了一个关于多场景建模的系列篇。
今天继续带来一篇同样是CIKM’ 2021的论文:
SAR-Net: A Scenario-Aware Ranking Network for Personalized Fair Recommendation in Hundreds of Travel Scenarios
https://arxiv.org/pdf/2110.06475
多场景建模问题
(这里的概述其实与上一篇文章是大同小异的,看过上一篇的小伙伴可以选择跳过本小节)
由于不同场景有着独立的主题和数据规模,不同场景之间的数据分布是显著不同,这导致训练一个统一的模型去服务所有场景是困难的,论文称之为“多场景建模问题”。针对这个问题,一般存在以下三种解决方案:

1、所有场景共享一个模型:
不同场景行为数据分布不同,会导致各个场景互相产生负向影响。
2、每一种场景单独建模:
- 这种方案的人力和硬件成本的都比较高,需要同时维护和部署多个模型
- 样本量较少的场景,建模效果较差
- 无法利用所有场景的数据
3、所有场景联合建模:
- 既有每一个场景的独立参数,又有共同的共享参数
- 既可以减少维护成本,同时也能用样本量大的场景去带动小场景。
因此,第3种方法是一种比较合理的方案,相关的实践包括多任务学习和多场景建模。但是,它们其实是有着明显区别,虽然两者也存在很多相同的思想,比如即有共享也有特定任务/场景的学习参数。
- 多任务学习通常是聚焦于单独一个domain(场景、领域)内的不同任务的处理,即不同任务的label空间是不同的;
- 而多场景建模则是关注于多个domain的同一个任务的建模,比如CTR,即不同场景的label空间是一样的,但数据分布是不同的。

论文认为,多任务学习采用一种“早共享”(early-sharing)的策略取学习不同任务之间的特征embedding,然后把它们喂进独立的任务特定的子网络,但这种建模方式忽略了用户在场景之间的兴趣迁移,因此无法精准地预测用户的兴趣。
除此之外,输入信息在不同场景的重要性是必然不同的,多任务学习没有显式去捕获这种差异。
数据公平问题
在淘宝的许多交易场景中,在促销期间为了确保某些重要的商品的交易的确定性,在重排阶段往往会加入人工干预取调整排序结果,这会让那些真正曝光的加入人工干预的商品是有偏的。因此,使用这种有偏的日志取训练,排序模型会更多地学习到那些干预之后过度曝光的商品的信息,导致预期之外的对排序结果的自我强化,比如弱势商品的系统性歧视(systematic discrimination of disadvantaged items),论文称之为数据公平问题(Data Fairness Issue)。
之前的研究都是专注于曝光偏差[引用1、引用2、引用3]和选择偏差[引用4、引用5],而没有对这种干预偏差的研究。解决这种偏差的最直接方法便是对干预的商品进行下采样,但这需要大量的工程技巧和人工调整数据集,对于频繁改变的干预规则,特别是促销期间,下采样便不适用了。并且过度的下采样会导致可用数据的浪费。
SAR-Net
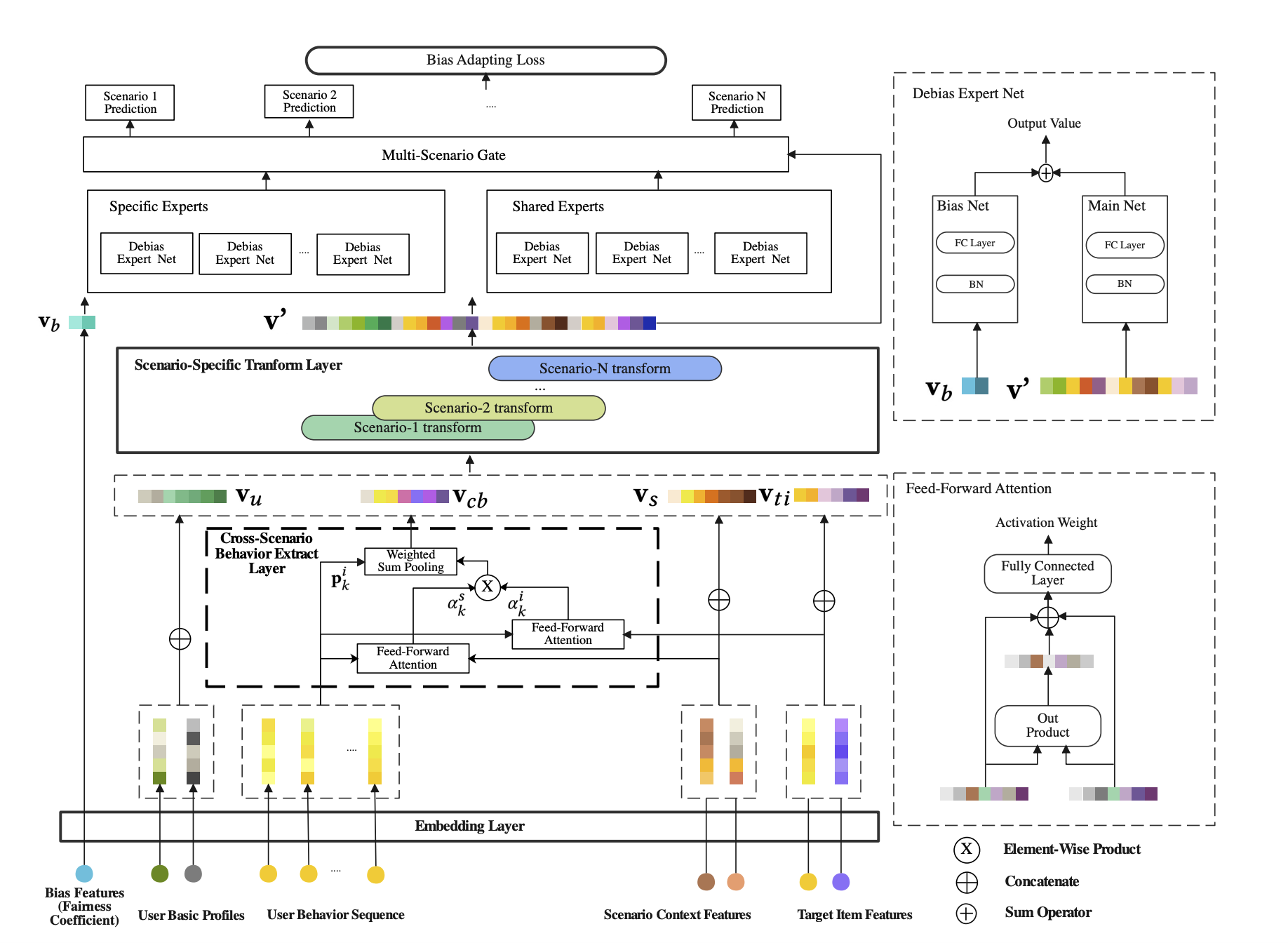
为了解决上述的多场景建模问题和数据公平性问题,论文提出了新型网络,称为Scenario-Aware Ranking Network (SAR-Net),包括以下组件:
- SAR-Net结构是基于多专家网络
- 两个注意力模块分别加入场景特征和target item特征,用于提取用户的跨场景(cross-scenario)兴趣
- 一个场景线性转换(scenario-wise linear transformation)来加强每一个独立场景的重要信息,更好地利用场景之间的差异和共性
- 为了克服人工干预造成的数据公平性问题,提出一种公平系数(Fairness Coefficient)的计算来作为样本的权重,应用到损失函数和bias-expert网路层里面
整体的网络结构如下图所示:
公平系数
干预偏差导致数据分布偏向于那些加权的items,用这样的不均衡数据去训练,推荐模型会趋向于学习那些占据过多的items,导致其他弱势items的系统性歧视。针对这个问题,论文提出一种公平系数Fairness Coefficient (FC)的概念,来衡量每个独立样本的重要性和干预程度。
- D , d i , s , N s \mathbb{D},d_{i,s},N_s D,di,s,Ns 分别表示所有场景的全部数据、场景s的第i个item、场景s的items的数量,当然 d i , s ∈ D d_{i,s} \in \mathbb{D} di,s∈D
- P V ( i , s ) PV(i,s) PV(i,s) 是从 d i , s d_{i,s} di,s 采样的数量, F ( i , s ) F(i,s) F(i,s) 是所有 d i , s d_{i,s} di,s采样中由SAR-Net预测的数量
- 白话一点, P V ( i , s ) PV(i,s) PV(i,s) 是指一个item的全部曝光,包括模型预测而曝光的和由于人工规则干预而曝光,而 F ( i , s ) F(i,s) F(i,s) 便单纯是指由模型预测而曝光的
最后,不同items在不同场景下的公平系数如下式:

分子是一个与items是否被干预无关的常熟,而分母则会受干预影响。可以看出,随着干预而增加曝光,FC便会变小,这便达到了样本重要性调节的作用。
Embedding Layer
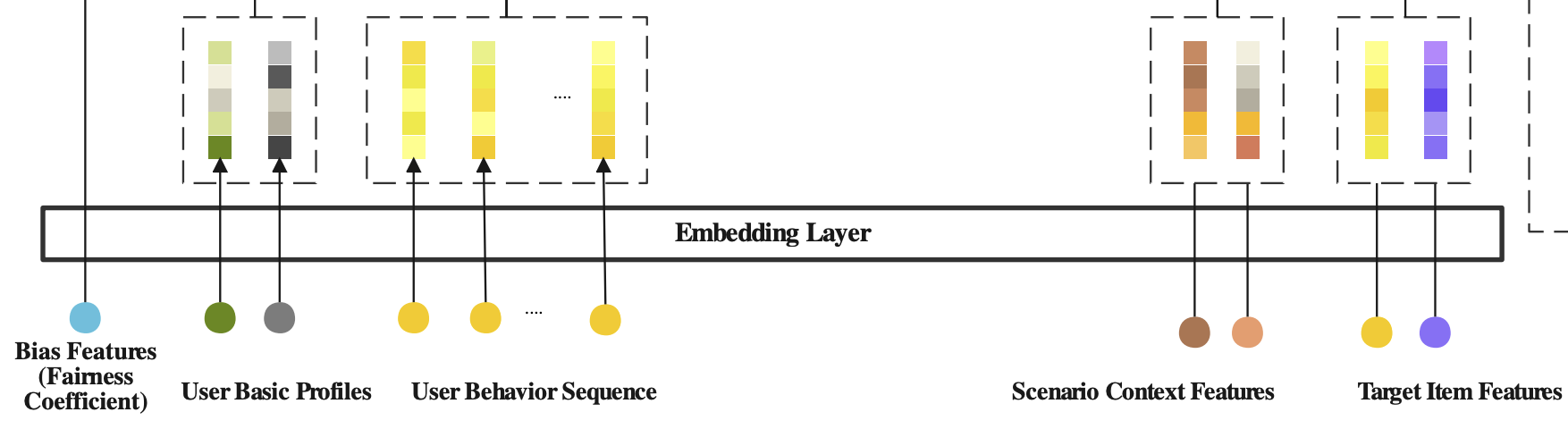
如上图所示,论文使用到五组特征:
- 用户画像特征:用户ID、国家等
- target item特征:品类ID、离线统计分数等
- 场景相关特征:时间、当前场景ID、当前场景类型
- 用户跨场景行为:所有场景下用户交互的items列表,比如点击、加购、下单等,每一个item除了有与target item一样的特征域,还有发生行为时的场景相关特征
- 干预偏差:每一个样本的公平系数,需要在第二天才能计算出来

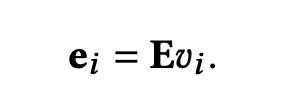
这里没什么特殊,仍然是将特征进行one-hot编码 v i ∈ R N v_i \in \mathbb{R}^N vi∈RN,然后映射到向量。从高维的one-hot编码映射到低维的密集向量 E ∈ R D × N , e i ∈ R D E \in \mathbb{R}^{D \times N},e_i \in \mathbb{R}^D E∈RD×N,ei∈RD。
N是unique特征值的数量,D是向量的维度,远小于N。
跨场景行为提取层
多任务建模没有考虑用户在不同场景的兴趣转移,但事实上,大部分用户是存在于多个场景之下的,并且有着各自不同的偏好。比如,用户可能在周边游主题场景下更喜欢景点门票,但同时在亲子游主题场景下喜欢居住质量高的或者更适合儿童玩的地方,并且情侣游、浪漫景点和旅游经验会是用户的主要考虑。
因此,为了能够映射出用户在不同场景下的重要旅游意图和描绘用户的兴趣迁移,对用户的跨场景行为建模则成了关键。
出于这个考虑,论文提出了对用户的跨场景行为聚合为一个统一的表征,这个聚合策略如下式:
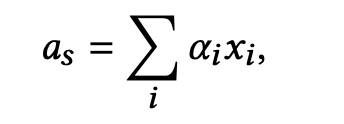
- α i \alpha_i αi 是分配给 x i x_i xi 的权重,代表它在聚合时的重要性。
但问题是如何计算权重?最简单粗暴的方法便是每一个点击的items有着相同的重要性: α i = 1 / ∣ x i ∣ \alpha_i=1/|x_i| αi=1/∣xi∣,但这显然不聪明,并不是每一个items都是对target item有指示作用的。
DIN 采用了注意力机制从用户的行为中提取相关的兴趣,考虑了历史行为items与target item的相关性,这是一种实用的方法。但在多场景下,行为发生时的场景上下文是非常重要的信息。比如,用户在周边游、亲子游和西北旅游三个主题场景的历史行为,对于正在查看的情侣游主题场景下,其中亲子游的相关性是比较低。
简单来说,用户在不同场景的历史行为对当前的场景影响是不同,因此需要考虑强相关的场景下的历史行为来进行推荐。具体地,论文使用了两个注意力模块来提取用户的跨场景兴趣,分别利用场景特征和items特征来分别调节历史行为。
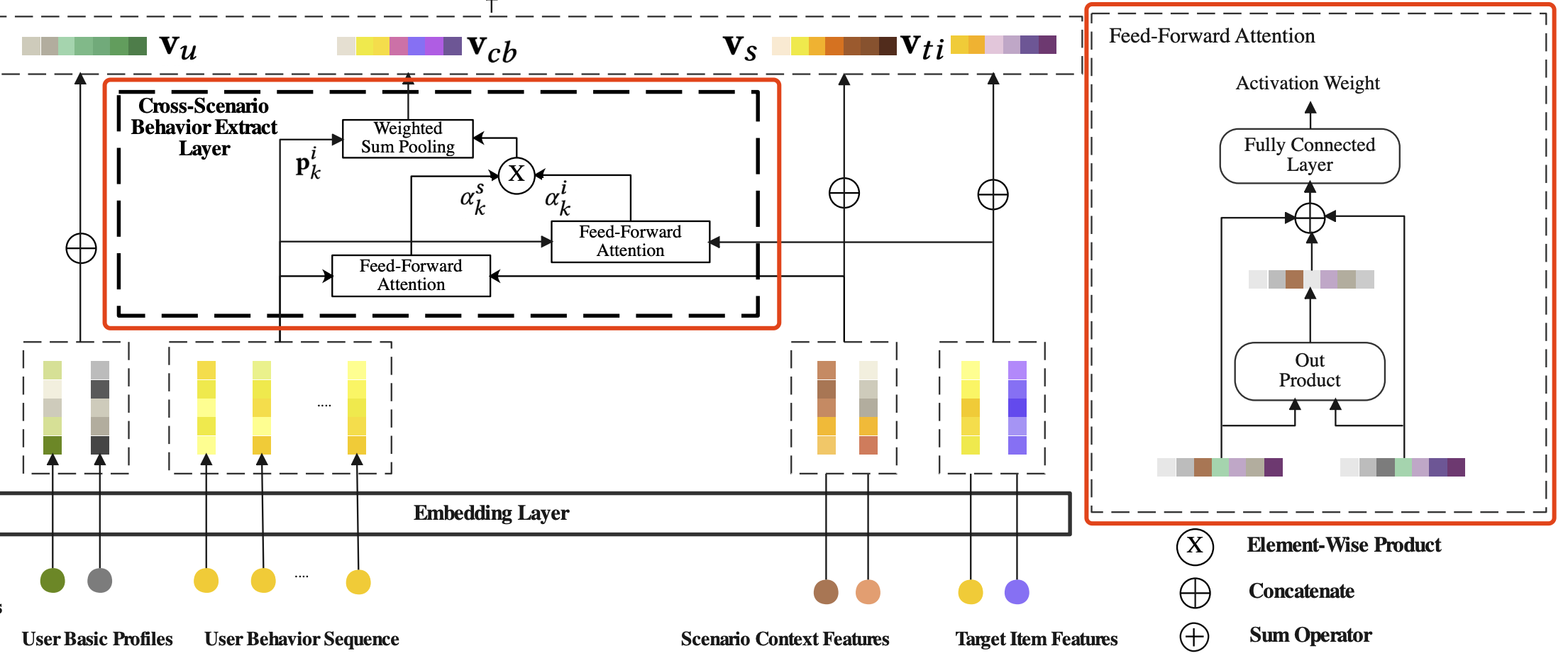
上一小节也提到,用户跨场景的历史行为包括items特征和场景相关特征,因此可以将历史行为分为两部分:
- p ( B i ) = { p 1 i , p 2 i , . . . , p ∣ p ( B i ) ∣ i } p(B^i)=\{p^i_1,p^i_2,...,p^i_{|p(B^i)|}\} p(Bi)={p1i,p2i,...,p∣p(Bi)∣i},具体地,第k个item的特征embeddings拼接,比如item id、品类等,可以表示为: p k i = [ e i t e m i d ∣ ∣ e d e s t i n a t i o n ∣ ∣ e c a t e g o r y ] p^i_k=[e_{itemid}||e_{destination}||e_{category}] pki=[eitemid∣∣edestination∣∣ecategory]
- p ( B s ) = { p 1 s , p 2 s , . . . , p ∣ p ( B s ) ∣ s } p(B^s)=\{p^s_1,p^s_2,...,p^s_{|p(B^s)|}\} p(Bs)={p1s,p2s,...,p∣p(Bs)∣s},具体地,第k个场景的上下文特征拼接,比如场景id、场景类型等,可以表示为: p k s = [ e s c e n a r i o I d ∣ ∣ e s c e n a r i o T y p e ∣ ∣ e b e h a v i o r T i m e ] p^s_k=[e_{scenarioId}||e_{scenarioType}||e_{behaviorTime}] pks=[escenarioId∣∣escenarioType∣∣ebehaviorTime]
那么,定义计算两个权重 α k i \alpha^i_k αki 和 α k s \alpha^s_k αks ,分别表示第i个行为item与target item或者target 场景的相关性,如下式:

- p t i , p t s p^i_t,p^s_t pti,pts 分别表示target item和target场景的embeddings
- Ψ ( x , y ) \Psi(x,y) Ψ(x,y) 是x和y两个向量作为输入,输出一个权重值,具体计算逻辑如上图[Cross-Scenario Behavior Extract Layer]中的feed-forward注意力操作
最后,同时考虑两个权重 α k i \alpha^i_k αki 和 α k s \alpha^s_k αks 进行聚合得到用户的跨场景兴趣迁移 v c b v_{cb} vcb,如下式:
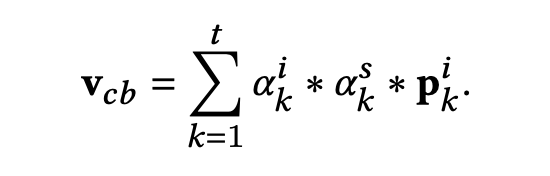
场景特定转换层
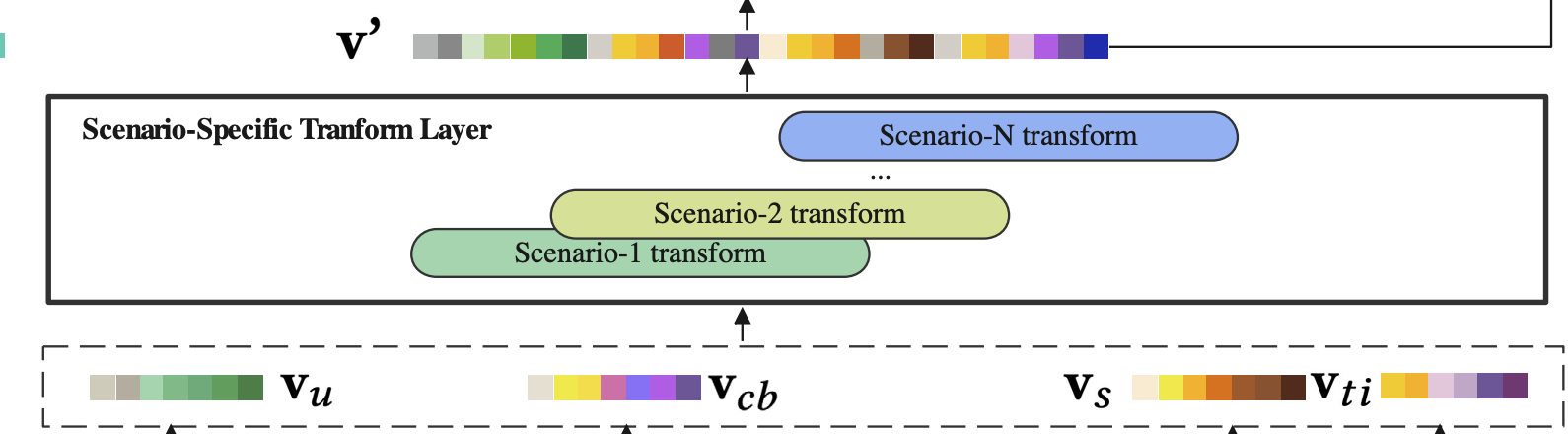
再上一步得到用户的兴趣转移向量 v c b v_{cb} vcb,场景特定转换层会将 v c b v_{cb} vcb和其他特征进行拼接,包括用户基础画像向量 v u v_u vu,target item特征向量 v t i v_{ti} vti,场景上下文特征向量 v s v_s vs: v = [ v c b ∣ ∣ v u ∣ ∣ v t i ∣ ∣ v s ] v=[v_{cb}||v_u||v_{ti}||v_s] v=[vcb∣∣vu∣∣vti∣∣vs]
接着,转换层使用场景特定的element-wise product操作来对v进行转换映射:
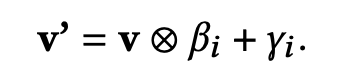
- β i , γ i \beta_i,\gamma_i βi,γi 是对应第i个场景的私有参数向量,维度与v相同
- ⊗ \otimes ⊗ 对应element-wise product操作
Debias混合专家
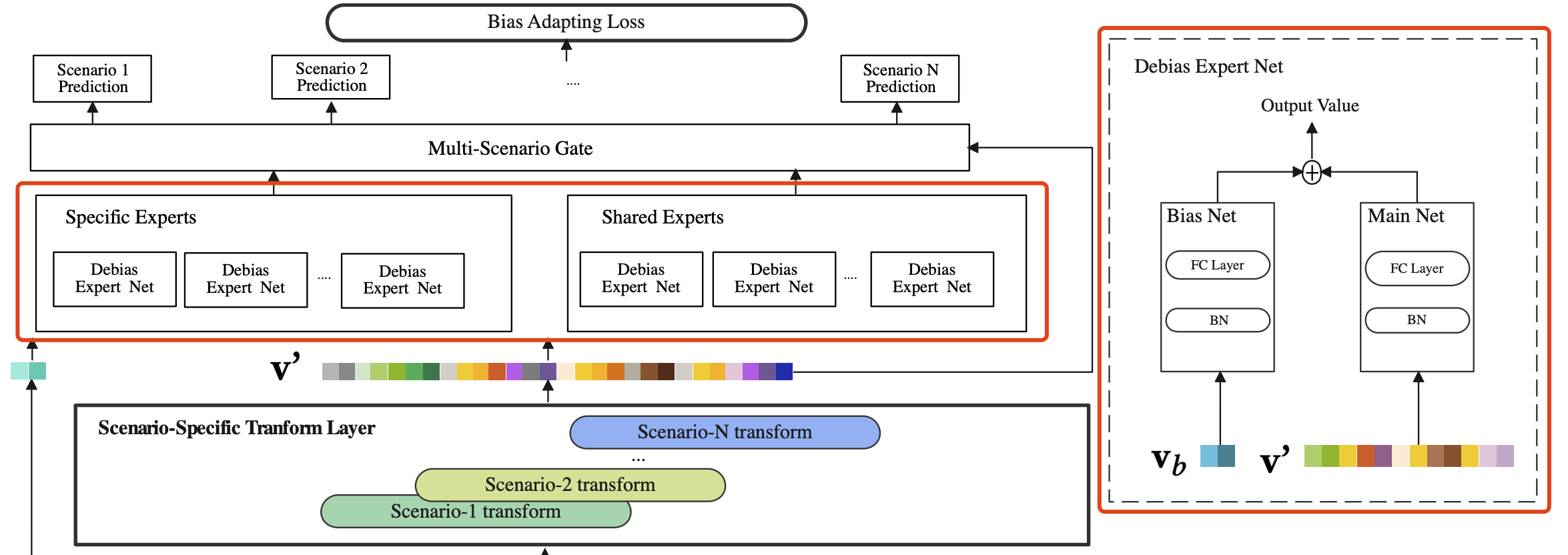
因为不同任务共享参数是难以描绘不同任务的异质性,并且可能产生负向迁移的潜在问题,论文设计了一种多专家网络作为特征提取部分的核心网络结构,类似于多任务学习中的PLE,如上图左边红框所示,每一个场景有着自己私有的场景特定专家,而所有场景又共享着一些专家,以此来更深入地建模同类任务的差异,并以此来缓解跷跷板问题。
为了缓解干预偏差对模型预测的影响,论文将每个专家网络分为两个部分(如上图右边红框所示,这两部分的网络结构是相同的,都是一个batch normalization和一个全连接层):
- Main Net:输入是用户兴趣转移向量 v c b ′ v^{'}_{cb} vcb′、用户基础画像向量 v u ′ v^{'}_u vu′、target item特征向量 v t i ′ v^{'}_{ti} vti′ 和场景上下文特征向量 v s ′ v^{'}_s vs′,目标是预测用户对target item的点击率
- Bias Net:输入是上述与场景和item相关的公平系数 w w w 经过embedding layer映射后的向量 v b v_b vb,目标是预测干预的程度,来作为Main Net的预测分数的权重。
Bias Net只在训练阶段使用,线上推理阶段应该去掉,这也很好理解,因为在训练阶段Main Net拟合的是去掉干预的点击率。
多门控网络预测
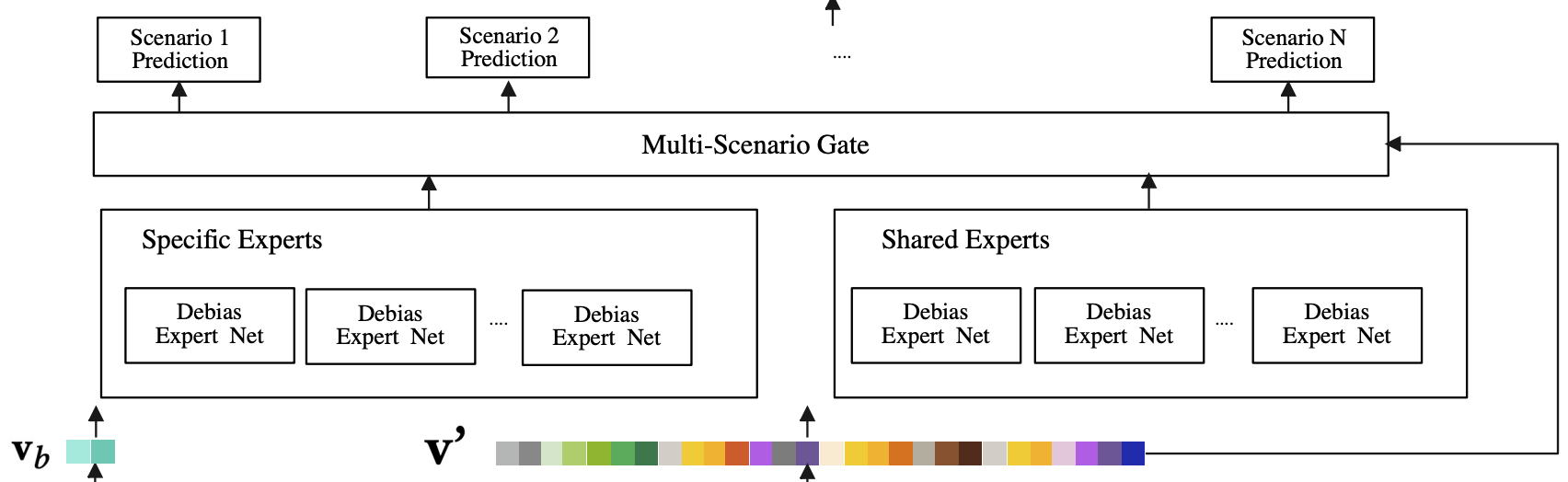
在经过Debias混合专家之后,我们会得到来自场景特定专家和场景共享专家的预估分数。
记x为输入表征, m k m_k mk 是场景k的场景特定专家的数量, m s m_s ms 是场景共享专家的数量,则预估分数为:
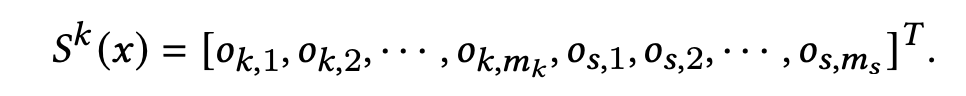
多门控网络的结果其实就是一个SoftMax激活函数的单层全连接,它相当于一个选择器,为每一个专家预估分数分配权重,然后进行加权求和:
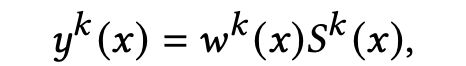
- y k ( x ) y^k(x) yk(x) 是第k个场景最终的预估分数了
- 多门控网络这里的输入x其实也是Debias混合专家的输入,即场景特定转换层的输出,如上结构图所示
偏差适应损失
为了减轻干预偏差问题,论文提出了公平系数的概念来衡量每个样本的重要性,并且希望模型能够从高公平系数的样本中获取更多的信息,因为这些样本是更少被干预的。
因此,论文在二元交叉熵(binary cross entropy )的基础上加入了公平系数的考虑:

- l o s s k , l , i loss_{k,l,i} lossk,l,i 是场景k和item i的第l个样本的loss, w f a i r n e s s i , k w^{i,k}_{fairness} wfairnessi,k 是场景k和item i的公平系数
l o s s k , l , i loss_{k,l,i} lossk,l,i 则是常规的binary cross entropy 计算,如下:
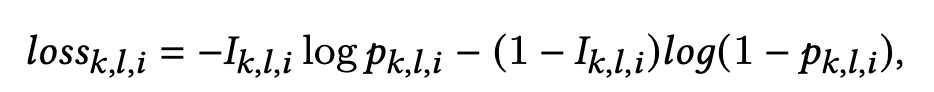
- p k , l , i p_{k,l,i} pk,l,i 是SAR-Net的输出
- I k , l , i I_{k,l,i} Ik,l,i 是场景k和item i的第l个样本的label,等于1则表示当前用户点击了item
实验结果
参数配置
- 使用Adam作为优化器,学习率为0.001,batch size为2048
- 用户行为序列截断长度为50
- SAR-Net每个场景使用2个场景特定专家,8个共享专家
评估指标
论文使用了常规的AUC(Area Under the ROC Curve)作为评估指标,并计算基于基础模型的提升,但并没有像 STAR 那样进一步使用用户分组
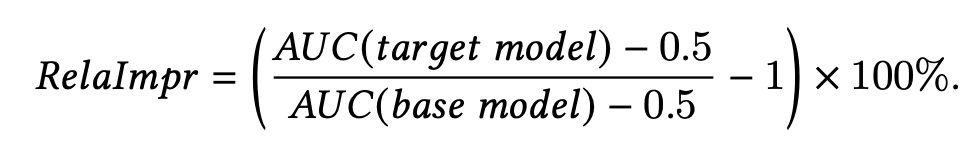
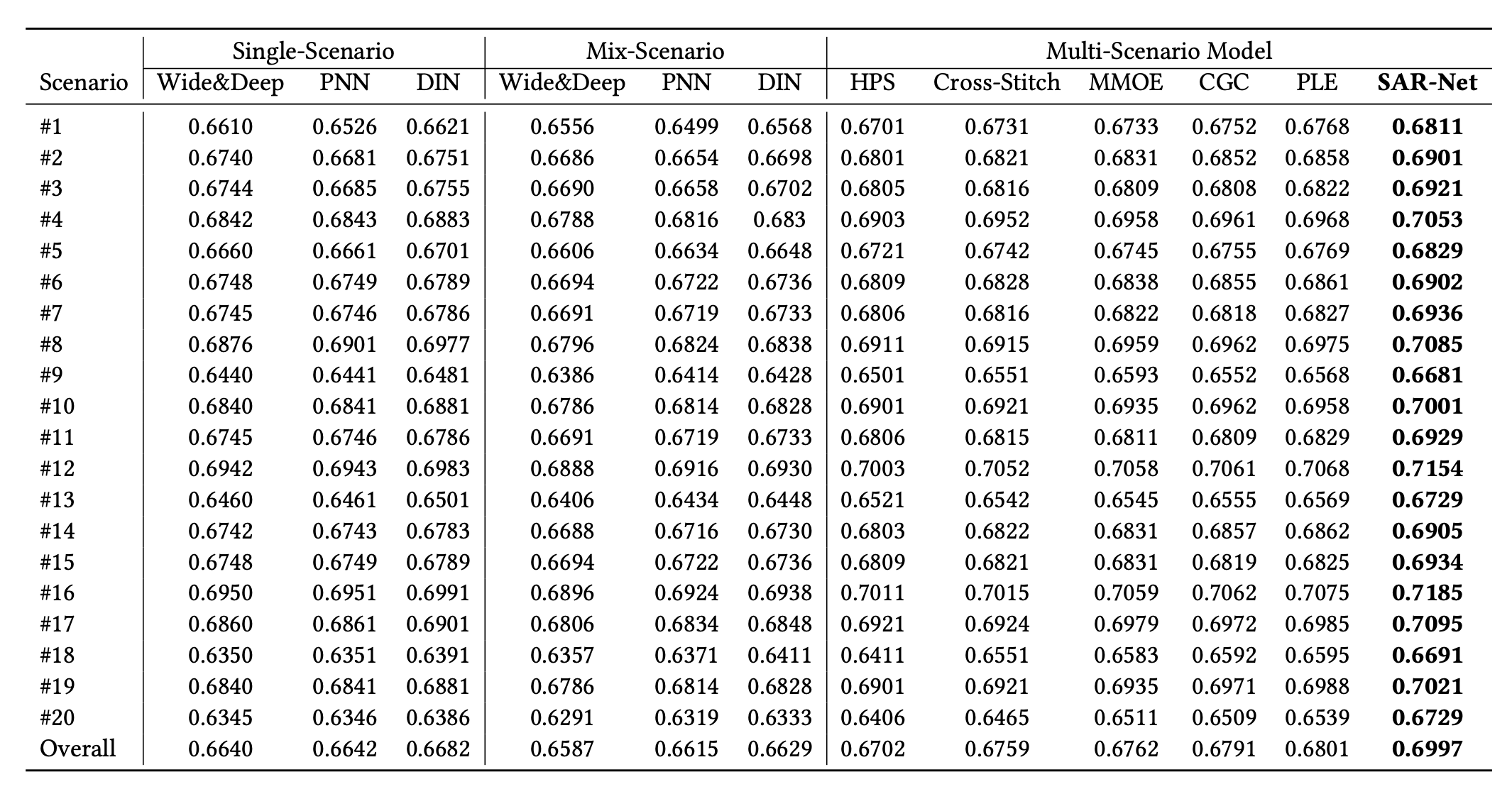
效果对比
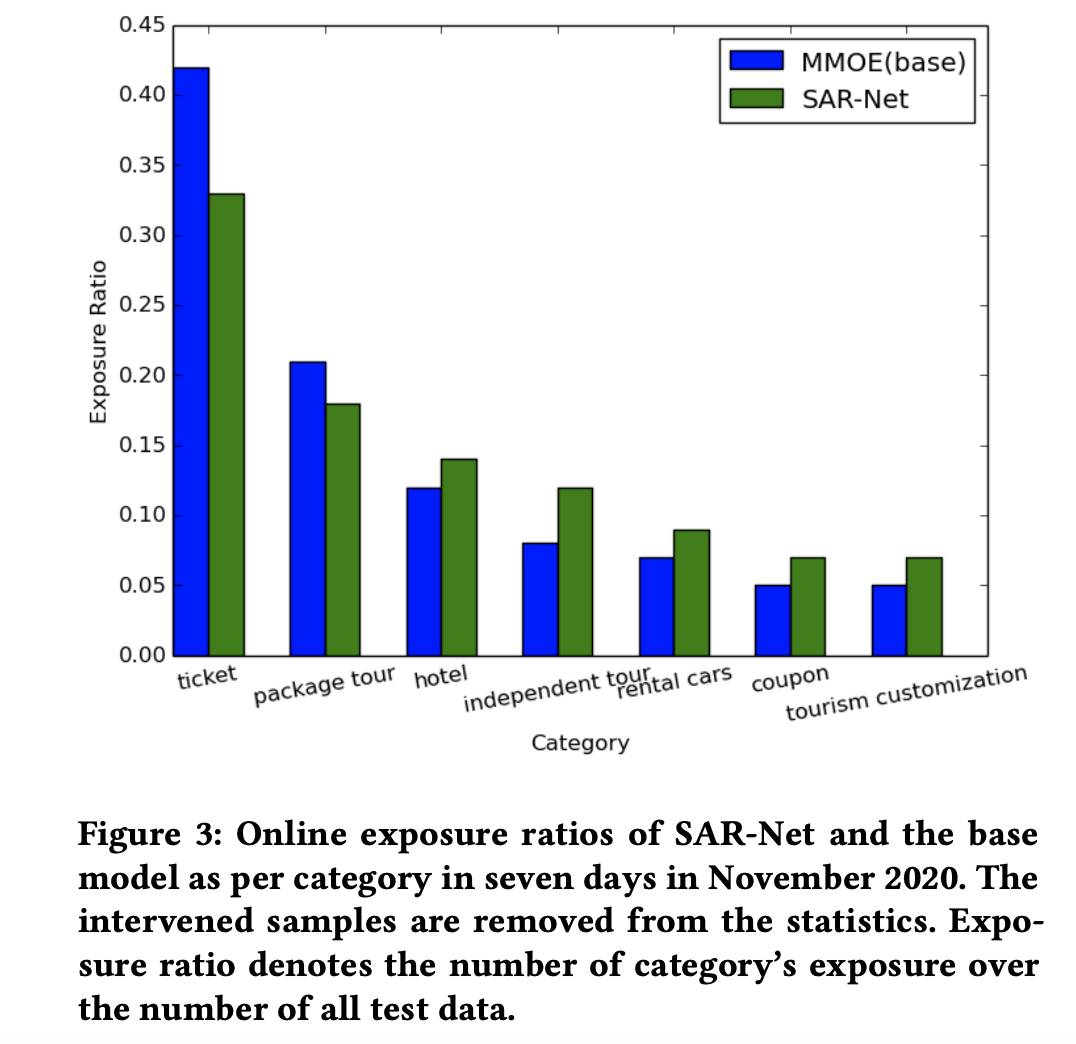
消融实验
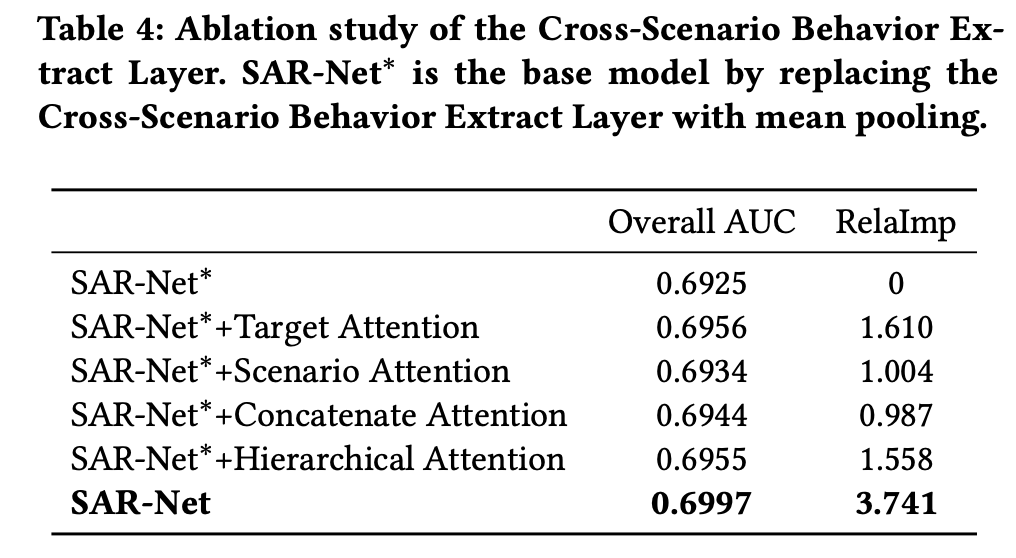
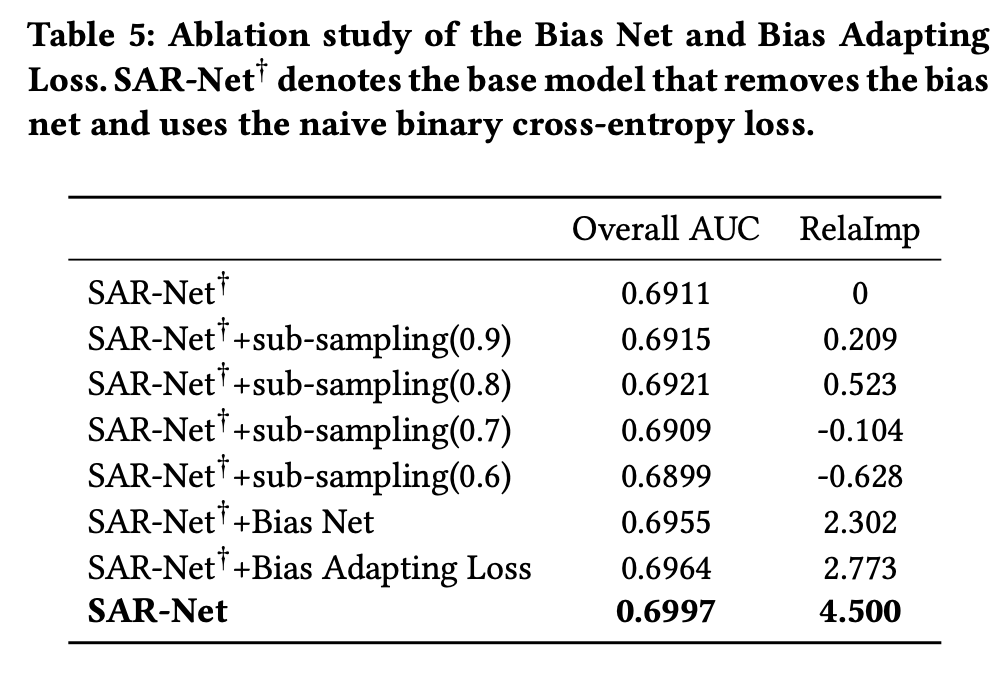
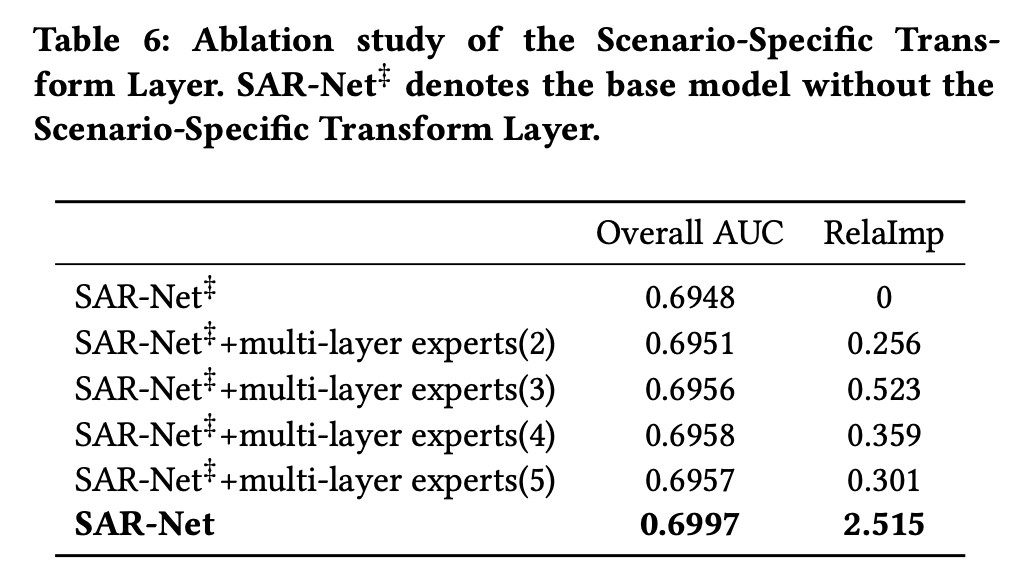
总结
其实,多场景建模与多任务学习存在相似的思想,比如本文的SAR-Net的最顶层便是与PLE非常相似,由场景特定专家与共享专家加权组合。
- 相较于STAR(Star Topology Adaptive Recommender),一个批次样本需要是同一个场景的,SAR-Net则显得更加灵活了,除了专家层之外,同样有着许多场景特定的参数
- 并且SAR-Net还加入了干预偏差的矫正训练,适用了电商类的促销场景
- SAR-Net在用户历史行为序列与target item的注意力模块之外,还创新地增加了一个场景上下文的注意力模块,更多地利用历史行为序列中的场景上下文信息。















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









