







多场景建模: STAR(Star Topology Adaptive Recommender)
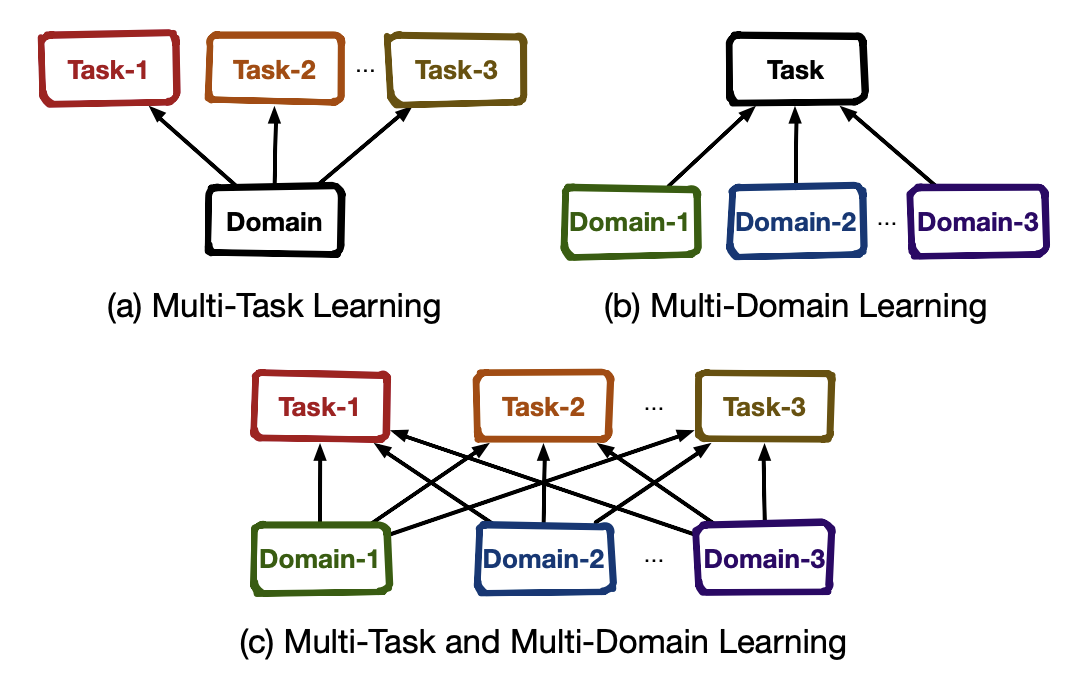
在前面的相关文章中,已经多次提及了多任务学习、多场景建模以及多场景多任务建模三者的联系和区别,便不再赘述,用下面这张图可以清晰明了地体现三者的关系:
1. 概述
PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information
KDD‘2023:https://arxiv.org/pdf/2302.01115
1.1 建模难点
老生常谈,不同的场景是存在着重叠的用户和items,因此不同场景之间是存在共性的;不同任务是功能相关的,因此不同任务之间是存在依赖的。基于这些特性:
- 为每一个场景的每一个任务训练单独的模型,除了部署成本和迭代效率问题之外,还存在无法利用全部数据而忽略数据之间的共性,导致不理想的效果。
- 而直接混合全部数据训练一个统一的模型,则会忽略不同场景和任务的差异性
也正是如此,多场景多任务建模容易出现以下问题:
- 无法有效地对齐和混合特征的语义和重要性会导致场景跷跷板,因为在不同场景下,用户的行为和候选items是分布是不同;
- 无法有效地平衡多个目标之间的相互依赖,则会导致任务跷跷板,因为不同任务是存在独特的稀疏性,并且互相影响彼此的。
- 而多场景多任务中则更为复杂,因为这两个问题是同时存在的,论文称之为不完全的双跷跷板现象(imperfectly double seesaw phenomenon)
2.2 个性化建模
个性化建模是推荐系统的核心,增强模型的个性化可以帮助捕获用户在不同场景下对items的偏好程度,这正好符合多场景多任务的属性,因此精确的个性化预估可以缓解双跷跷板问题。
但,常规的将个性化先验信息作为模型的底层输入,这样一步一步往上传递,会导致其影响变得很弱,因此如何正确地以哪种方式将个性化先验信息注入到模型的哪个位置便是关键。
2. PEPNet
为了解决上述的问题,论文提出了一种针对多场景多任务建模的方法:Parameter and Embedding Personalized Network (PEPNet),它可以通过增强个性化来充分地利用任务之间的关联和消除了场景偏差。
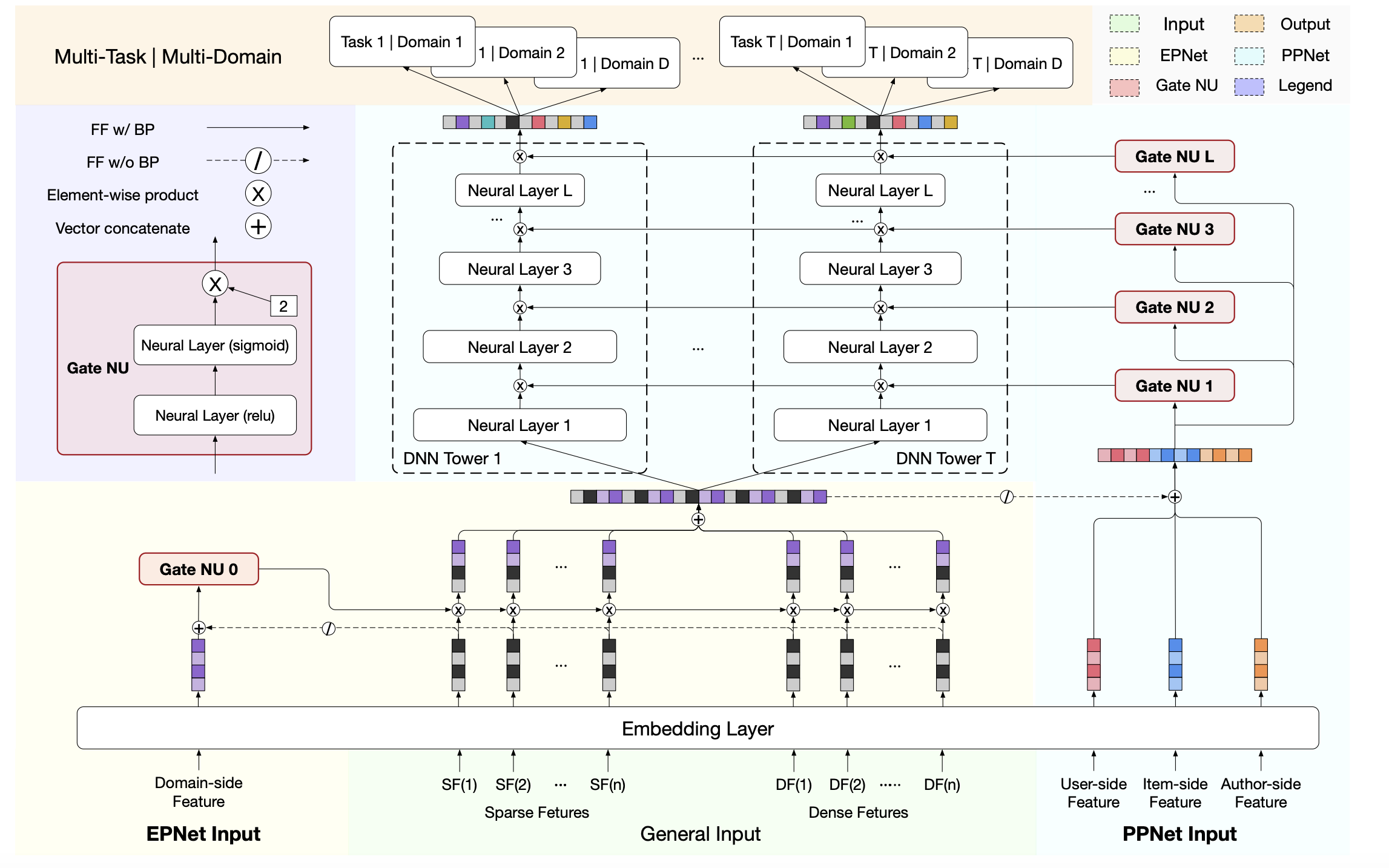
PEPNet将带有个性化先验信息的特征作为输入,通过门控机制,来动态地缩放底层网络-embedding layer和顶层网络-DNN隐藏层单元,分别称之为场景特定的EPNet和任务特定的PPNet:
- Embedding Personalized Network (EPNet) 为底层网络添加场景特定的个性化信息来生成个性化embedding门控,用于执行来自多个场景的原始embedding选择,以生成个性化的embedding
- Parameter Personalized Network (PPNet) 将用户和items的个性化信息与每一个task tower的DNN的输入进行拼接来获得个性化的门控分数,然后采用element-wise product应用到DNN的隐藏层单元上,来个性化优化DNN的参数。
通过将先验的个性化映射为0-2缩放的权重,EPNet为不同用户在多个场景下融合不同重要性的特征,而PPNet则为不同用户在多个任务下优化DNN的参数,来平衡目标的不同稀疏性。
PEPNet的整体结构如下图所示,可以看到,核心的组件便是这三个:Gate NU(门控网络单元)、Embedding Personalized Network (EPNet)、Parameter Personalized Network (PPNet)
2.1 问题定义
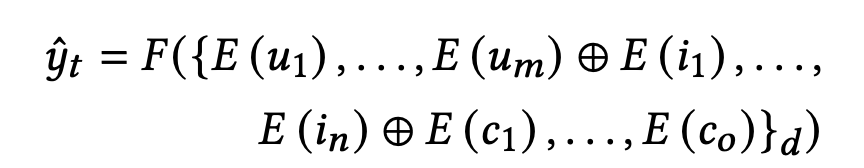
- 首先来看,模型的目标 y ^ t \hat{y}_t y^t 是用户u对于item t在场景d下的第t个任务的预估分数, { } d \{\}_d {}d 表示样本是来自场景d的
- u 1 , . . . , u m u_1,...,u_m u1,...,um 是用户特征,包括历史行为、用户画像、用户ID等, i 1 , . . . , i n i_1,...,i_n i1,...,in 是item特征,包括分类、item ID、作者ID, c 1 , . . . , c o c_1,...,c_o c1,...,co 是其他上下文特征
- E ( ∗ ) E(*) E(∗) 对应embedding layer,将离散/连续性特征分桶之后映射到可学习embedding, ⊕ \oplus ⊕ 则表示拼接操作
现实场景中,item的候选池和部分用户在多个场景下是共享的,然而由于不同的消费目标,用户对于同一个item,在不同场景下的行为趋势是会改变的。为了更好地捕获用户的多种行为趋势和多个场景间的联系,论文采用了多个task和多个场景共同联合训练,即模型的目标为:
x d → y ^ t x_d \rightarrow \hat{y}_t xd→y^t
- x d x_d xd 是来自每一个场景的样本特征, d ∈ D d \in D d∈D,
- y ^ t \hat{y}_t y^t 则是每一个task的预估分数, t ∈ T t \in T t∈T
2.2 Gate NU
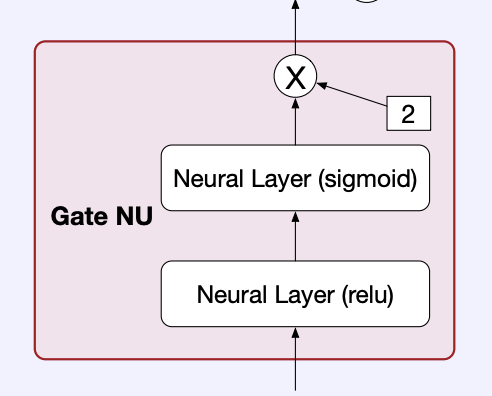
Gate NU(Gate Neural Unit)是EPNet和PPNet的基础单元,它是一种门控结构,可以将处理更多的带有个性化语义的先验知识,将其映射到模型里。
Gate NU是论文借鉴了 LHUC 的做法,LHUC是聚焦于speaker特定的隐藏层分布的学习,它通过引入个性化分布来缩放模型的隐藏层,提升了不同speaker的语音识别准确率。但LHUC在本质上可以认为是仅仅使用用户ID来作为个性化标识,忽略了其他相关的先验知识,比如用户的性别、年龄和其他画像。
另外,在推荐系统的场景,items侧同样也很关键,比如item ID、分类和作者等。有一些研究已经表明用户对于不同的items会表现出不同的偏好模式。
Gate NU的表达式如下:

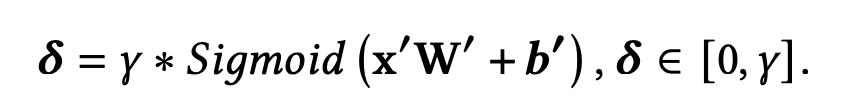
- x 是Gate NU的输入
- 第一层网络用于多方面的先验知识的特征交叉
- 接着第二层用于门控分数的生成。最后通过Sigmoid和超参数 γ \gamma γ可以让分数向量的取值范围控制在 [ 0 , γ ] [0,\gamma] [0,γ],其中 γ \gamma γ设为2
2.3 EPNet
在推荐系统中,embeddings table是非常巨大的,特别是ID类特征,因此,为了节省内存和计算开销,底层embedding一般是共享:
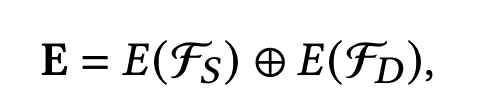
- F S , F D \mathcal{F}_S,\mathcal{F}_D FS,FD 分别是离散型特征和连续性特征, E ( ∗ ) E(*) E(∗) 通过embedding layer将这些特征输入映射到可学习的embedding E
但是共享的embedding layer,对于多场景而言,过于强调共性而忽略了场景之间的差异。
EPNet在此基础上,注入了场景特定的先验知识到embedding,并且是以极少开销的代价(少量的参数)和快速的收敛,如下式:
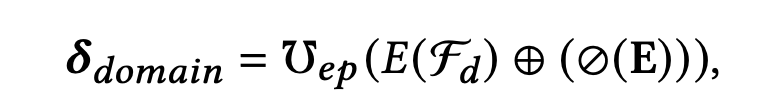
- 使用了场景侧的特征 E ( F d ) ∈ R k E(\mathcal{F}_d) \in \mathbb{R}^k E(Fd)∈Rk 作为EPNet的输入,包括场景ID、特定场景下的个性化统计,如用户行为的统计、items的曝光量等
- E ( F d ) E(\mathcal{F}_d) E(Fd) 拼接上常规的输入特征embedding, ⊘ ( ∗ ) \oslash(*) ⊘(∗) 表示取消梯度反向传播操作
- ℧ e p \mho_{ep} ℧ep 则为上一小节的Gate NU
EPNet在不改变原始embedding layer结构的前提下,使用Gate NU来对Embedding E进行个性化转换,对齐不同用户的多个场景下的特征重要性:

- ⊗ \otimes ⊗ 表示点乘操作(element-wise product)
2.4 PPNet
目前推荐系统下的多任务学习的做法都是使用复杂的模块去建模多个task的表征,也就是DNN towers,即堆积的神经网络层。但,由于DNN towers的参数是所有用户共享的,这其实是缺乏个性化的参数,那由于不同用户的行为偏好的不统一,会导致建模难以平衡多个task,最终出现跷跷板的问题。
为了解决这个问题,论文使用了PPNet来优化多任务学习中的DNN参数,构建一个能够定制每个用户兴趣的DNN模型,其计算公式如下:
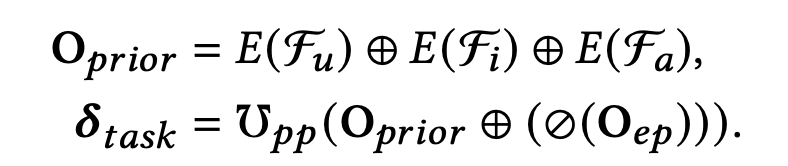
- 论文拼接了用户侧、item侧、作者侧三个维度的特征来作为PPNet的先验个性化,用户侧特征如用户ID、年龄、性别,item侧特征如item ID、分类、流行度,作者侧如作者ID等
- 接着再这些先验个性化特征 O p r i o r O_{prior} Oprior 再与上一小节的EPNet的输出 O e p O_{ep} Oep拼接,输入到Gate NU ℧ p p \mho_{pp} ℧pp 中
- 并且为了影响EPNet的embedding的更新,这里同样需要对 O e p O_{ep} Oep取消梯度反向传播
与EPNet一样,Gate NU ℧ p p \mho_{pp} ℧pp 的输出会与隐藏层H进行点积操作(element-wise product)来放大或缩小隐藏层H的贡献:
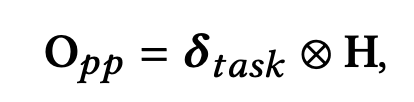
- H = [ H 1 , . . . , H T ] , H t ∈ R h H=[H_1,...,H_T],H_t \in \mathbb{R}^h H=[H1,...,HT],Ht∈Rh 表示第t个task的隐藏层单元
- δ t a s k ∈ R h ∗ T \delta_{task} \in \mathbb{R}^{h*T} δtask∈Rh∗T 拆分为T个维度为h的向量之后,应用到T个task的隐藏层单元。同样地, O p p O_{pp} Opp 会拆分为T个task的h维度的PPNet输出
论文在所有DNN层中都使用了PPNet来尽可能个性化DNN参数,来为不同用户平衡不同稀疏性的多个目标,如下式:
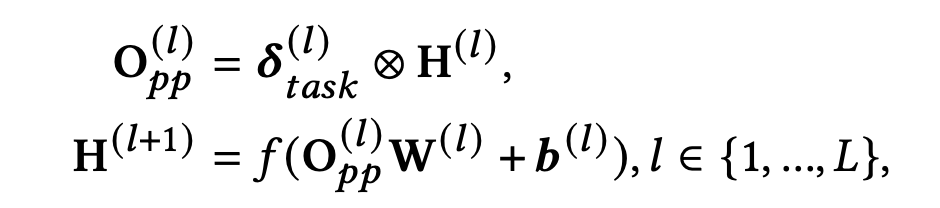
L是DNN的层数,f是激活函数,前L-1层使用Relu,最后一层使用Sigmoid,最后一层输出的便是多个场景下多个task的预测分数。
3. 策略&实验
3.1 训练策略
在推荐系统中,embeddings的更新会比DNN的参数更加频繁,特别是ID类特征,因此,为了更好地捕获底层embedding的变化和更稳定地更新顶层的DNN参数,论文会对它们使用不同的训练策略,embedding layer使用AdaGrad优化器,学习率为0.05,DNN参数使用Adam优化器,学习率为5e-06。
其他超参数:batch size为1024,embedding size为40,Xavier initialization作为参数初始化,使用[100, 64]的2层DNN
3.2 实验
评估指标使用AUC和按照用户分组统计的GAUC:

- n是用户的数量, # i m p r e s s i o n i \#impression_i #impressioni和 A U C i AUC_i AUCi是第i个用户的曝光量和AUC。
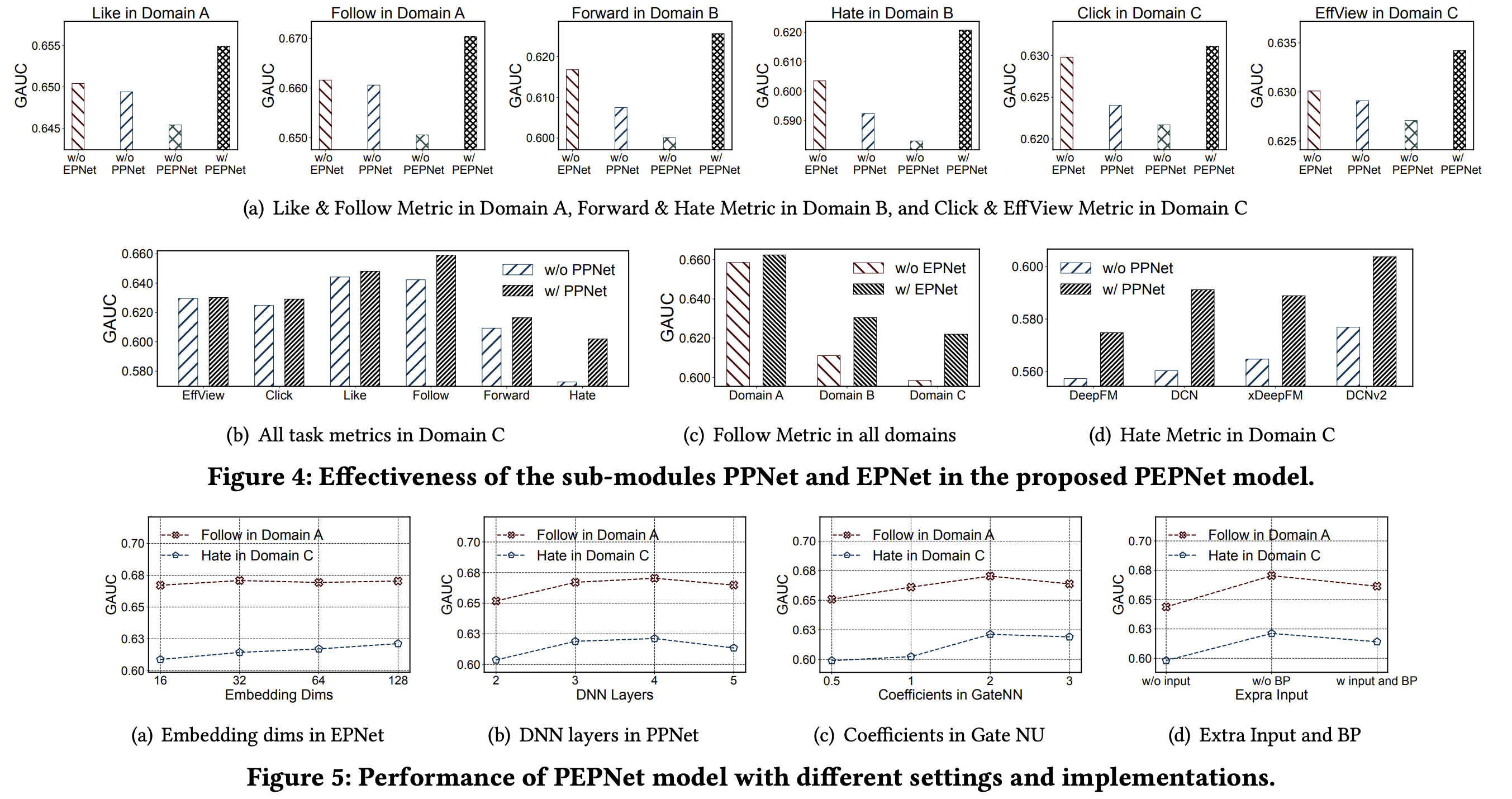
PEPNet效果比主流的模型效果都要好,因此,下面主要看下消融实验,可以作为设置超参数的参考:
代码实现
tensorflow 2.x:recsys/multidomain/pepnet.py
tensorflow 1.x:recommendation/multidomain/pepnet.py

















 3619
3619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









