






项目地址:Score Jacobian Chaining (ttic.edu)
背景
(有Dreamfusion,DreamFields等相关基础可跳过这部分)
传统的三维模型制作工序繁杂,通常需要借助Maya、ZBrush等专业建模软件,进行几何体塑形雕刻、UV排布、贴图绘制,才能得到游戏、影视中看到的逼真立体模型。而近年来,GAN、Diffusion等模型在二维生成领域取得的成绩,也让我们联想到——是否能将三维建模这种繁琐的工作交给神经网络完成。(由于三维模型和深度学习模型两个“模型”概念容易混淆,下面统一称为三维物体)

参照图像生成的方法,容易想到,只需要将原先图像生成模型中的二维卷积层替换为三维卷积,再使用三维物体数据集进行训练即可完成目标。但是想法很美好,现实很骨感,目前最大的三维数据集Objaverse仅有80万的三维物体,相比Stable Diffusion训练所使用的Laion5B数据集50亿图文对少了几个数量级(参考自 一作详解ProlificDreamer:如何生成高质量的3D内容 )。缺乏数据的情况下当然也可以做生成,但是模型的泛化性能肯定就比较差了。
于是只能另辟蹊径。我们知道,三维物体要呈现到二维的屏幕上,需要经过渲染的过程(如光栅化、光线追踪),最终渲染出的是二维的图像。如果我们对渲染出的图像进行监督,不就可以使用二维数据集进行训练了?但是这样做有一个前置条件,就是渲染三维物体的渲染器必须是可微分的,那么对渲染图像所求得的梯度,才可以回传到三维物体上(比如网格体,每个顶点坐标为,通过可微分渲染器,对渲染图像求得的梯度可以反传到每一个
上)。如果这样的三维物体是用另外一个模型生成的(比如3D-GAN),那么梯度也可以传回到生成器中。这样的方法同样存在问题,我们需要一个体量巨大的生成器才能完成形态各异的三维物体的记忆和生成,同时三维模型的分辨率(精度)难以调节(每提升一点精度,模型指数倍增大)。
出于这些缺点,上面使用生成器进行三维物体生成的方法也是不明智的。但是我们发现,要完成上述的训练过程得到一个三维物体(注意是一个),其实并不需要有一个生成器的存在。例如Mesh,我们只需要训练其每一个顶点的 坐标,就可以得到一个模型。比如我们想要生成狗这种三维物体,我们只需要将数据集图像全部换成狗的图片,最终训练得到的Mesh应该就是狗。但是准确的来说,这是三维重建而非生成。要实现像Stable Diffusion那样输入文字生成图像一样的功能,我们有一个简单的想法,不直接使用数据集图像进行监督,而使用一个预训练的、可接受文字输入的监督器(Discriminator)进行监督就可以了,它可以辨别出渲染的图片像猫还是狗,还是啥都不像。实际上DreamFields就是这样做的,它使用对比学习的方式,使用CLIP进行监督。这样其实仍是从渲染的图像出发进行优化,具有一致性较差等缺点。而我们想要做的是直接从三维物体的参数出发进行优化,渲染的图像只是一座“桥梁”。
总结上述的想法,我们只需要有一个含参数的三维物体(比如Mesh,参数就是每一点坐标),一个可微分渲染器和一个能指导三维物体优化的监督器就可以完成三维生成了(相当于三维物体是学生,监督器是老师,这样的过程和蒸馏有些类似)。由于Mesh也具有分辨率难调节的缺点,我们想要使用一个能无限缩放分辨率的三维表达形式来表示三维物体。自然而然可以想到,隐式场三维表达正好满足这样的条件,并且对于较为热门的NeRF等隐式场,其渲染器也是可微分的。而监督器,除了CNN、CLIP之外,如果阅读过宋飏 Score-based Generative Modeling Through Stochastic Differential Equations 等文章,可以联想到在图像生成领域取得巨大成功的Diffusion模型,也可以为渲染图像指导梯度方向。这样我们的想法就齐全了,使用隐式场三维表达+Diffusion的方式,可以完成三维生成。
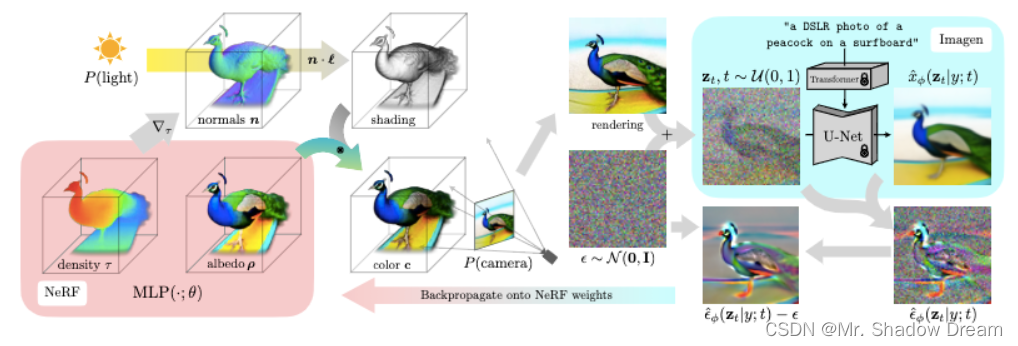
前置
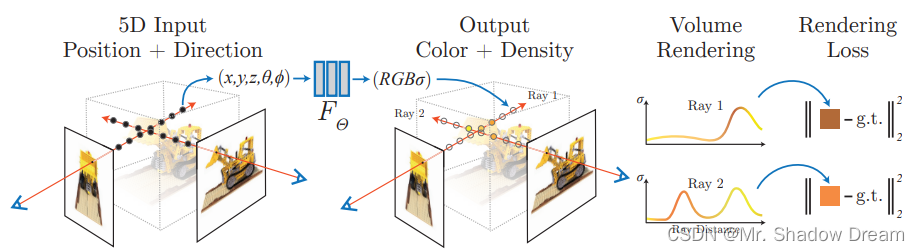
NeRF
(有NeRF基础可以跳过这部分)
NeRF使用神经网络来储存三维物体的隐函数表达。简单来说,训练一个神经网络 ,
是神经网络参数。将三维空间的坐标
和观察方向
输入神经网络,神经网络会输出
这一点的密度和颜色。
渲染方法也很简单。我们定义一个摄像机平面来渲染这个三维物体的二维图像,对于摄像机平面上的任意点,我们从摄像机的焦点
出发,构造射线
。将射线上的点采样,输入神经网络,输出颜色按其密度权重积分起来,就可以得到摄像机平面上这一点的颜色。
(具体表达式参照NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis)
SJC原论文中使用Voxel优化的NeRF,但实际使用的隐式场三维表达模型对理论复现不产生影响,使用NeRF,DMTet都可以。因此复现过程简单选取原始的NeRF来完成三维物体的表达。复现中的NeRF网络由两部分组成,Density Network和Color Network,都是简单的全连接网络。Density Network输入点坐标,输出点密度
和点特征
,将观察方向
和
输入Color Network,获得点颜色。
Diffusion
(有Classifier Free Guidance和Score Function基础可以跳过这部分)
Diffusion是一类生成模型。给定一个容易获得的分布(如高斯分布,可以由随机数发生器获得),神经网络
可以指明
这个分布朝向真实样本分布
的梯度
。这个梯度称为Score Function(这里只是一个形象化的简单解释)。随着这个梯度方向迭代,我们便可以一步步去接近真实样本分布,完成生成过程。
(具体可参照 一文解释 Diffusion Model (二) Score-based SDE 理论推导)
而要使得Diffusion迭代的梯度朝向我们指定的方向,我们就需要额外给出Guidance,比如Stable Diffusion中输入的文本prompt。假设prompt是y,那么我们的目标分布就应该是,梯度就应该是
。这个式子很难求,那么可以使用贝叶斯定理将梯度拆解为容易求解的几个部分:
可以使用另外一个神经网络
来估计(比如想要生成一条狗,将x输入c,可以得到最终迭代结果是狗的概率),而
实际上就是原来的Score,使用原先训练好的Diffusion可以求得。这样就可以完成具有附加条件的可控生成。
然而这种方法进行可控生成需要另外建立一个Classifier网络,并且会出现像GAN一样生成无关细节欺骗Classifier的问题。因此,后面的改进中采用了Classifer Free Guidance。Classifer Free Guidance将原神经网络改造为
。加入条件y输入,便可求得
,条件置空,则求得
。我们将
和
以一定比例混合,便可求得可控的Score,其中
表示Guidance的强度:
(具体可参照 通俗理解Classifier Guidance 和 Classifier-Free Guidance 的扩散模型,Classifer Guidance其实又使用了一次贝叶斯公式进行推导,感觉没有必要,其实就是加了个y输入)
SJC原论文中使用Stable Diffusion,Stable Diffusion使用VAE编码的latent而非原图进行Diffusion逆向过程完成图像生成。但理论复现使用任意能获得Score Function的Diffusion模型均可完成。这里使用最简单的DDPM模型。
(具体可参照 扩散模型之DDPM)
方法
基础算法
首先,回顾背景部分,我们想要的其实是从三维物体的参数出发进行优化,使用二维渲染图作为“桥梁”,连接Diffusion这个老师和NeRF这个学生。换而言之,我们目前已知二维渲染图的Score,最终想要获得的是三维物体参数的Score。SJC的做法是,它假设隐式场参数的概率密度
,与所有视角
渲染出图像
的概率密度
的期望
成正比。这个假设建立了三维的
和二维的
之间的联系,使得其Score的转化变得可能:
为了得到Score的形式,在等式两边加上对数,其中Z是正比的比例:
要得到二维Score形式,等式右边log要在期望里,因此琴生不等式得到:
等号没了不要紧,只是将原问题变成min-max优化问题了,我们记右边这一串表达式为,为左边概率密度的下界:
顺着这个下界的Score走,那么左边也会更接近最优的分布。
将上式求导得到:
应用求导链式法则得到:
即:
上式中, 为下界的三维Score,
为渲染图像的二维Score,
为可微分渲染器的Jacobian矩阵。其实推导到这里,三维的Score已经出来了。剩下只需要完成三个任务,求出
,求出
,和求出它们乘积的期望。
对于,实际上就是二维Score。记Diffusion的神经网络为
,
为Diffusion的预训练参数。对于DDPM来说,这个神经网络估计的是
相对真实分布图像
的噪声,即
,其中
为高斯噪声的标准差。根据Diffusion的迭代式可以推导出二维Score
(具体推导详见 Score-based Generative Modeling Through Stochastic Differential Equations)
对于,实际上就是渲染图像对三维物体参数求导,直接将渲染图像backward求梯度即可。
对于E,我们只需要使用祖传的随机抽样法估计即可,即随便取几个视角,算样本均值来估计总体均值即可。
将上述的想法总结为最终的算法,其实我们只需要一个训练好的Diffusion就足够去获得一个三维物体了。下面是算法的简单描述:
- 随机取一个视角,使用NeRF渲染出图片
- 将
代入预训练的Diffusion,得
(这里省略了
,因为只需要Score的方向)
- 截断
的梯度(即将
- 计算
- 对
求梯度,进行梯度下降
- 重复1、2、3、4、5直至收敛
看起来好像很复杂,其实理解之后SJC的想法非常简单,算法也比较简短,其实就是一个偏理论性的工作。个人认为其核心就是一开始那个不加证明的假设了。论文中好像并没有证明这个式子,只能从直观上来说这个正比关系是有一定道理的。
PAAS优化
上述的算法看似正确,但实际上我们并无法找到一个足够强大的Diffusion模型,使得无论输入任何
,
都能求出准确的Score(
一般是使用真实分布的图像加噪后训练的,输入图像满足
,如果输入不满足上式的图片
,神经网络没有见过类似的分布,会估计出不准确的噪声)。并且,以DDPM为例子,估计噪声时,神经网络还需要时间步 t 输入。但单从NeRF渲染出的图片
,我们根本无法确定其对应的时间步(并且
很可能根本不满足
的分布)。

SJC提出了PAAS(Perturb-and-Average Scoring)的方法来解决这个问题。简单来说,就是在NeRF渲染的图像上,再额外增加噪声,强行将
拉回神经网络
熟悉的分布上。
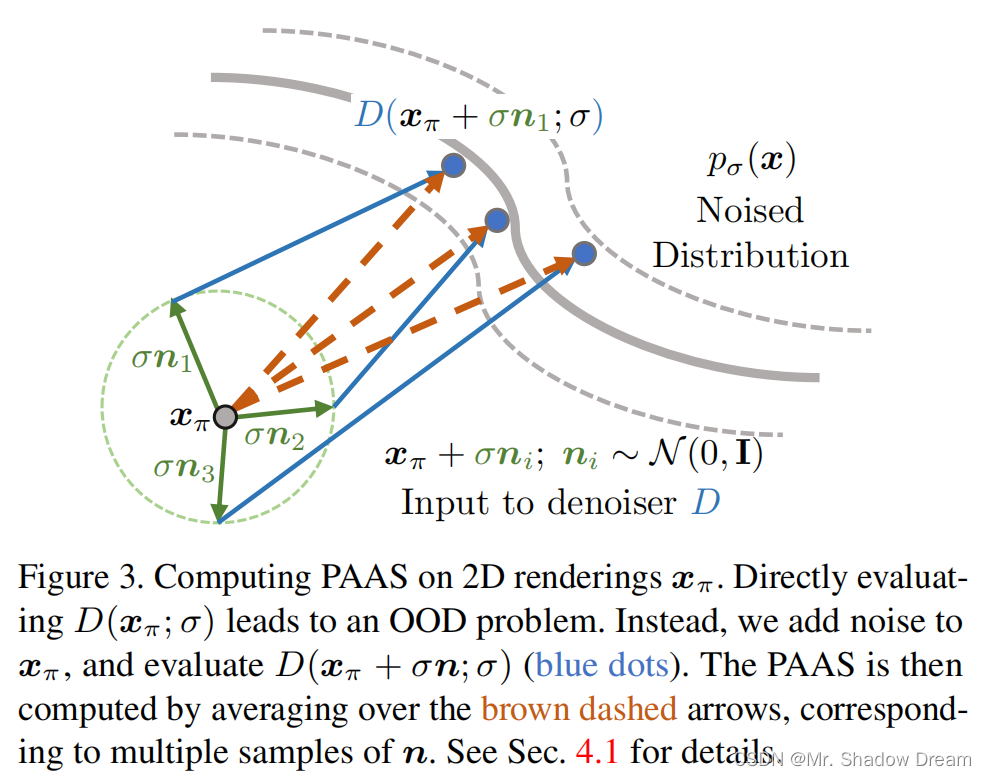
PAAS函数的定义如下:
额外增加的噪声为,加噪后的图像为
,其中
为时间步
对应的方差,由Diffusion的Schedule决定,
对于DDPM而言就是随机采样的高斯噪声。时间步是从Schedule的最大和最小时间步之间随机采样的,
论文中证明了,。对于PAAS方法我其实也不是太懂,单从上式好像也不能看出收敛性,求大佬们浇浇😵。暂时是这样理解的:使用PAAS在保证神经网络输出一个较为准确的Score的同时,也能保证梯度方向与真正的
相差无几。在
比较偏离真实分布
时,这个方法能够估算出大致正确的方向,使得两个分布慢慢接近,不至于乱走;在训练后期,
比较接近真实分布
时,
就会在
分布附近震荡。因此最终能够接近
的分布。个人认为PAAS方法还有一个小问题,只有当
足够大,才能盖住原分布的影响。虽然这个问题可能随着迭代次数增多自然就解决了。
至于PAAS中的求期望操作,也使用随机抽样法估计即可。将原算法中计算的部分,替换为计算
,即可完成算法的改进。
最终的算法:
- 随机取一个视角,使用NeRF渲染出图片
- 将
- 截断
- 计算
- 对
- 重复1、2、3、4、5直至收敛
其实已经可以凭借上面的代码描述在tf或者torch中编写训练脚本了,PAAS改进后算法仍然比较elegant。
正则化方法
到这个部分其实与文章的主题相关性不大了,主要是一些经验性的正则化手段,因此复现中并没有包括这一个部分。使用正则化方法能使得生成的模型密度集中在一篇区域内,减少模糊与伪影。正则化包括空旷损失(Emptiness Loss)与中心损失(Center Depth Loss)两部分。
空旷损失的表达式为:,其中
为NeRF中射线上采样点的密度权重,满足
。对这个损失项的直观理解是,对数函数在
较大时梯度较小,在
接近0时梯度较大。要使得整个
最小,最好的情况是只有一个点的权重是1,其余都是0。举个栗子,假如某一点正好位于物体表面,则挡在其后面的点的
肯定是接近0的(参见NeRF中
的表达式);加入
后,在其前面的点
也要接近0。这就要求除了物体以外的“空气”区域,采样点的密度都应该是0。
中心损失的表达式为。这个损失是针对渲染后的二维深度图像计算的(参照NeRF,简单来说,就是射线碰到了物体,D(p)就比较大,如果没有东西,D(p)就是0)。直观地说就是在图像上圈一个框,如果渲染的物体落在框内,则Loss变小 ,如果落在框外则Loss变大。
复现中并没有写这两个损失,与文章的主要思想其实并不算非常相关(主要是懒😝),只是一些经验性的训练手段。并且考虑到训练使用的数据集较为简单(自己造的),不存在太多的干扰,因此不需要额外的正则化也不会有严重的伪影和模糊。
复现
( 数据集下载地址:链接:百度网盘 提取码:b7p1 )
(代码下载地址: Shadow-Dream/ScoreJacobianChaining (github.com))
对SJC论文中的算法进行玩具级的复现。所使用的数据集为Unity中随意拍摄的一个物体的多个角度的图片,由白色圆锥顶端和红色圆台底座组成。数据集还包含拍摄相机的forward,up和position。数据集一些图片如下:

由于篇幅较大这里就不放DDPM和NeRF的代码了。为了加快训练速度,NeRF使用一个半径为0.5的球来初始化。SJC训练代码如下:
def train(self,dataset):
# 从数据集中随便抽取一个batch,包括拍摄的图像,相机位置和朝向
# 朝向可分为上下左右前后,只需要确定前和上的向量即可确定相机姿态
images,positions,forwards,ups = dataset.batch()
batch_size = dataset.batch_size
self.nerf.density_optimizer.zero_grad()
self.nerf.color_optimizer.zero_grad()
# 使用NeRF在给定的位置和角度渲染一张图像
color_map,_ = self.nerf.render(positions, forwards, ups)
# 交换维度使其适应Diffusion的输入
# (BATCH,WIDTH,HEIGHT,CHANNEL) -> (BATCH,CHANNEL,WIDTH,HEIGHT)
color_map = color_map.permute(0,3,1,2)
with torch.no_grad():
# 随机抽样t
t = torch.randint(0,self.diffusion.schedule.num_timesteps,(batch_size,)).cuda()
# 加噪 x + σ(t)ε
noise_map,noise = self.diffusion.get_images_at_timestamp(color_map,t)
# 预测ε
predict_noise = self.diffusion.view_network(noise_map, t)
# 按照SJC公式计算梯度
color_map.backward(predict_noise)
self.nerf.density_optimizer.step()
self.nerf.color_optimizer.step()
return torch.mean(predict_noise)训练DDPM 100000 iters(前10000 iters 使用学习率0.0001,后使用学习率0.00001)
训练SJC 50000 iters (前10000 iters 使用学习率0.0003,后使用学习率0.0001)
训练使用GTX 1060 6GB(老掉牙机子了😂,Batch Size调大都怕他冒烟),训练时长8小时
总结
贡献
SJC提供了一种使用预训练的二维Diffusion进行三维生成的方法。其通过求导链式法则求出三维物体参数的Score进行迭代优化,并使用PAAS方法解决OOD问题。SJC与Dreamfusion的SDS同时期提出,有极为相似的优化算法,但是其推导方式是不一样的。
区别
SDS的推导是从多视角渲染图像分布与真实分布的KL Divergence的期望出发。真实分布是未知的,但根据Diffusion可以求出真实分布加噪后
分布的梯度。求导后可推导出初步的SDS梯度表达式。由于实际应用中发现,梯度中的U-Net Jacobian项不稳定,去掉之后效果更好,于是得到了最终的SDS梯度。
而Score Jacobian Chain基于三维参数的概率密度正比于渲染图像概率密度期望这一假设,使用链式法则推导出Score Function,并使用PAAS解决OOD问题。
题外话
Dreamfusion和SJC之后,使用SDS和SJC方法进行三维生成的理论和工程性的改进也越来越多了。比如Fantasia3D将隐式神经场换成更好的DMTet,参考了NeRF中BRDF光照模型的改进方法,能生成更精细的模型;ProlificDreamer更是从变分梯度下降中获得灵感,指出了SDS方法多样性差,过饱和等问题的症结所在,并给出了VSD方法改进。3D生成的质量越来越高,相信不久的将来,生成速度这个通病也能得到改进。希望有生之年能玩到3D生成的开放世界(不至于一个GTA6让我从初二等到大二🤣)

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









