






一. Zero-shot Text-Guided Object Generation with Dream Fields (Dream Fields, DreamFusion 前身,CVPR2022)
1.动机:
- 2022年3D数据集主要还是ShapeNet,总的来说caption和diverse都不行,所以想绕开3D直接监督。
- Nerf的兴起。好处:不同视角的渲染图可以插值,且平滑和稳定。由于是场,相对体素、点云等,是无限分辨率。
但直接用nerf的问题:
- 需要现实已有的图片进行监督,但文生3D任务中没有现实的图片 --> 将渲染好的图片用CLIP与文本embedding进行监督
- 实践证明只有1的话效果也不好,有很多artifact。–> general-purpose priors
对前工作锐评:
CLIP-Forge: 用CLIP+conditional normalizing flow model 和 geometry-only decoder。 在ShapeNet上训练,对ShapeNet以外类别表现很差;需要多视角图的ground-truth和体素数据。
TextShape:一个text-conditional wasserstein GAN合成体素化表示。生成物体像素有限,且只支持ShapeNet类别。
2. 方法
2.1 nerf+clip简单尝试及遭遇挑战
回想nerf的方法,输入粒子3D位置和3D位姿,得到密度
σ
=
f
0
(
x
)
\sigma= f_{0}(x)
σ=f0(x),颜色
c
o
l
o
r
=
f
1
(
x
,
d
)
color=f_{1}(x,d)
color=f1(x,d)
(本文用的是nerf的一种变种,但本质一样)
根据得到的密度和颜色,可以渲染出给定视角下的RGB图片。
渲染出的图片(一般渲染几十到上百张)在groundtruth的监督下计算loss。
本方法将这个监督换为渲染出图片与文本caption的CLIP损失函数(图片与文本一致性)
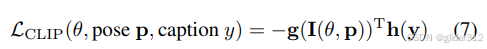
用了两个CLIP模型(预训练,冻结)
小的:CLIP
大的:LiT
可想而知,原先nerf在groundtruth的新视角的监督下训练,渲染出的新视图要与实际的新视图一致,视图间的一致性,以及模型的一些幻觉肯定会被很好的消除。
但现在把这个监督换位只要满足文本描述就可以,显然削弱了很大的监督,那渲染出的新视图缺少约束(under-constrained),必然会出现很大的问题,例如近场伪影。

2.2 改进
- 方位角采样:360°均匀采样,因为nerf网络在每个视图的监督时share了对3D shape的隐式理解,多个pose可以增强nerf对物体3D信息的学习。比如可以避免比较窄范围内方位角采样导致的扁平像布告牌类似的物体。本文发现相机仰角、焦距、距离物体距离的数据增强没什么用。
- 鼓励射线的平均transmittance达到某个设定值。transmittance是nerf的nlp网络得到空间中每个粒子的密度和颜色后,渲染图片时的概念,表示一条射线上,光线在这个点没被阻碍的概率。
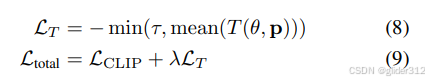
这么做的原因可能是上图b中,有很多杂质,其实背景应该是干净的,透明的,transmittance为1的。但是现在有很多地方不是1。
实际过程中, τ \tau τ从40%通过500 iteration退火到80%。可以改善上述问题同时避免生成整个都是透明的场景。放缩时, 1 − τ ∝ f 2 / d 2 1-\tau\propto f^2/d^2 1−τ∝f2/d2可以保留物体在不同焦距和离相机距离时的横截面积(有点难理解,可以简单理解为一种退火的策略)。 - 训练时,背景设置为高斯噪声、纹理、棋盘。通过扰动,让模型对前景背景区分能力更强,并且使前景一致性更强,测试时背景为纯白。
- Nerf训练时物体一般在图中心,CLIP训练时则不一定,所以用EMA追踪了物体原点。(具体实现没讲)
- 改进了Nerf网络
评价:
后续的改进还是很难消除我心中的质疑,毕竟CLIP监督是在语义层面的,假设文本是一只猫,有无数个不同的猫可以与“一只猫”的CLIP score相同。
另外,改进部分论文是真有点晦涩难懂。
渲染时,用的漫反射,其实感觉有点从Nerf退化了,效果应该不如Nerf的PBR。
二. DreamFusion: TEXT-TO-3D USING 2D DIFFUSION(ICLR2023)
1. 前置知识:
stable diffusion的扩散过程可以被看做生成三种等价产物:paper video
预测
图片
x
^
<
=
=
>
噪声
ϵ
^
<
=
=
>
图片\hat{x}<==> 噪声\hat{\epsilon} <==>
图片x^<==>噪声ϵ^<==> socre function
s
θ
(
x
)
s_\theta(x)
sθ(x)
Dreamfusion延续了Dreamfield的思路,即找到一种监督,指导Nerf渲染图片符合文本prompt描述。
Dreamfield使用了CLIP作为监督,效果不是很好,Dreamfusion用stable diffusion来做新的尝试。
2. 核心
2.1 前向
查看stable diffusion的训练过程:
输入一张图片
x
x
x,通过加噪得到噪声
z
z
z,噪声与条件通过decoder得到预测的图片\噪声\score function。
在这个过程中,ground truth是输入图片
x
x
x,预测是模型的输出。
Dreamfusion的思路是: 利用训练好的stable diffusion做到Dreamfield中类似CLIP的监督
一个stable diffusion训练好后,把模型参数冻结,那么模型的输出(输入加噪为高斯白噪声后通过解码器)因为通过大量训练,肯定表现很好了,可以反过来作为一种指导,监督输入的Nerf渲染的图片。
这个过程比较work的原因是,原本Nerf自己渲染出来的图不是很好,但是通过stable diffusion的前向过程,还是可以加噪为符合预定义的白噪声,由于stable diffusion的特性,哪怕是随机抽样,只要满足预定义分布的白噪声,都可以在加入条件后去噪为合理质量高的图片。并且由于 z z z是输入渲染图加噪后生成的,去噪后的图片与渲染图还有很强的相关性。
Dreamfusion提出一种SDS损失函数:Score Distillation Sampling,分数蒸馏采样,与stable diffusion一样:
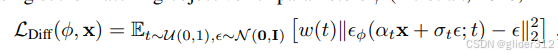
其中
x
x
x替换为
g
(
θ
)
g(\theta)
g(θ)(Nerf的渲染图)
a. 分数:虽然公式是网络预测噪声,但是预测噪声等价于预测分数
b. 蒸馏:本质上是用预训练好的stable diffusion网络预测的分数作为监督,相当于一种蒸馏
c. 采样:由于借用的是stable diffusion训练过程,中间解码器输入噪声
z
z
z是有编码器编码渲染图片得到的,而不是stable diffusion采样过程中预定义分布下随机得到的,所以叫做采样。
2.2 后向:
后向公式推导
该文介绍了后向公式的详细推导
Dreamfusion的一个重要的贡献在于:
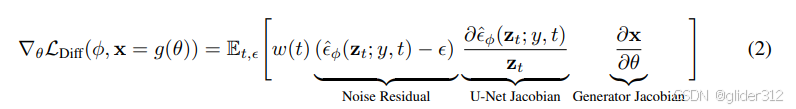
将以下式子反向传播过程中Unet反向传播的部分直接省略,为以下式子:
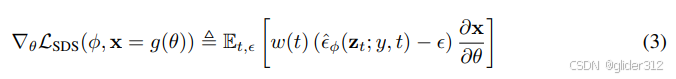
等价为
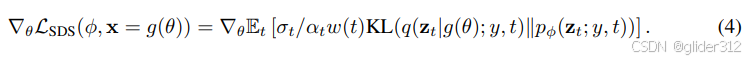
为什么省略?
有两个原因,大部分文章都讲第一个:
- UNet虽然冻结,但是反向传播仍然要参与运算,UNet本身是很大的,运算过程消耗很大。

这个有点难理解,在这个视频中看到了一些解释:

2.3 pipeline:
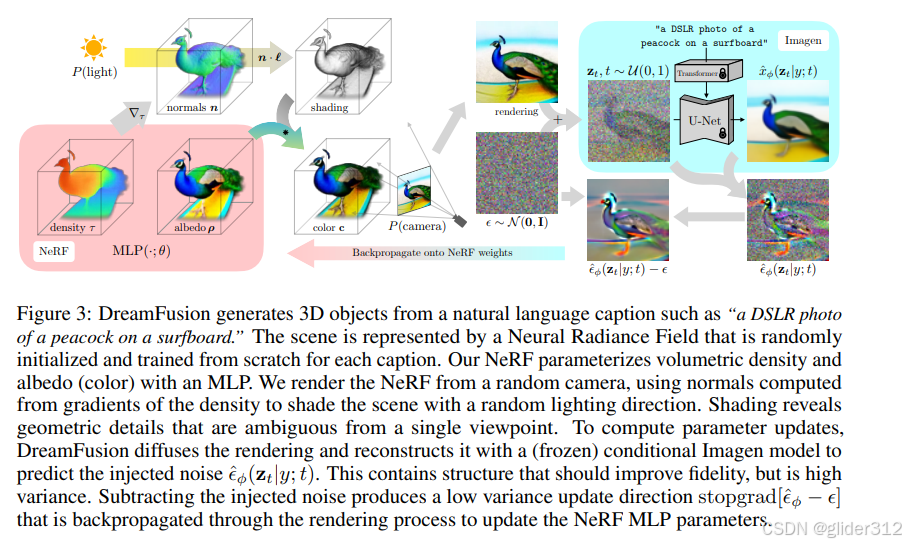
渲染:
使用了新的渲染技术,不过不是论文重点。
3. 评价
用diffusion做监督,也只是用了“大概跟输入图像长得像,而且跟prompt对得上”的图片做监督,还是缺乏了空间一致性。
SDS会导致著名的“Janus problem”:
三. Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation(SJC,CVPR2023)
SJC和SDS类似,都是Nerf的渲染串联预训练的stable diffusion。SJC在Dreamfusion的SDS arxiv版后发表,不过SDS在SJC的CVPR2023后的ICLR2023发表。
2. 核心
本质上,Dreamfusion的SDS和SJC都是将Nerf包含3D信息的场通过渲染
f
(
θ
)
f(\theta)
f(θ)与2D stable diffusion联系起来。
一个重要的假设:
3D分布与2D多视角分布的期望成正比,没有给出证明,可以这样理解:
3D 物体和2D渲染图尽可能的像
即:
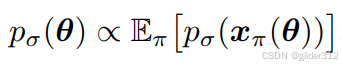
取对数,且将这个比例系数设定为
Z
Z
Z后,有(7)
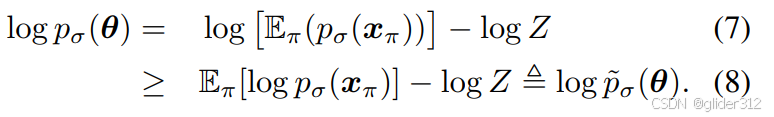
根据琴生不等式有(8)。
即,左边3D score的下界为右边log
p
~
σ
(
θ
)
\tilde{p}_{\sigma}(\theta)
p~σ(θ)
因此,3D score可以如下求:

其中,(11)等式右边,2D score可以通过pretrained的stable diffusion求到;renderer Jacobian即Nerf的梯度,求期望可以采样后取平均。
2D score的求法:
其实最终就是用的Dreamfusion的方法,即将渲染图作为encoder输入,noise后,再denoise。
论文花了一些篇幅说明,为什么不能直接渲染图denoise。因为diffuser的denoise过程中,decoder只认识预设分布的噪声输入,输入图像肯定不行。
最终步骤:
- Nerf渲染出多张图片 x π x_{\pi} xπ
- 输入到diffuser中(先加噪再去噪)
- diffuser会得到2D score(预测噪声转换一下,代码中这里不取梯度,detach一下)
- 渲染图loss = x π x_{\pi} xπ*2D score,求偏导,更新Nerf参数。
正则
SJC和dreamfusion不同的一个地方:
dreamfusion直接生成了合理的2D图像指导Nerf构建场;
但SJC是指导Nerf构建场,这个场和2D图像生成的score正相关,即尽可能像。
所以又会出现Dreamfield中出现的问题:
表示的3D物体会有很多模糊杂质,在大的空间中不稀疏
为了解决这个问题,SJC提出两个正则:
-
Emptiness Loss,其中 β \beta β先小(方便生成物体)后大(稀疏)
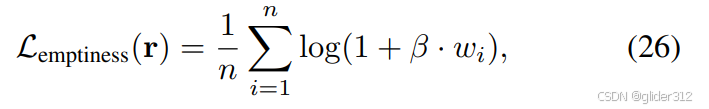
-
Center Depth Loss: 跟dreamfield一样,也需要一个额外的正则loss来追踪物体中心
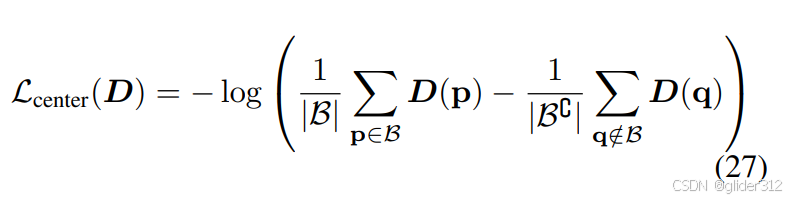
直观地说就是在图像上圈一个框,如果渲染的物体落在框内,则Loss变小 ,如果落在框外则Loss变大。
3.与dreamfusion不同
- dreamfusion有但是省略了unet的梯度,SJC直接就没有
- SJC进一步阐述了为什么不能直接denoise( x r e n d e r x_{render} xrender)(感觉都不是不同)
可以发现,2D的指导仍然没有考虑多视角一致性,Janus问题仍然没有得到很好的解决,甚至相比dreamfusion都不算是进步了。
4. 四. Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures(CVPR2023)
1. 核心:
- 使用的stable diffusion是一个LDM(先用vae的encoder编码到低维空间,在denoise后再decoder回rgb空间)。Nerf与SD串联时,不是 Nerf生成RGB–>LDM的vae encoder编码–> 加噪 --> 去噪 --> vae decoder解码;而是Nerf直接生成原来encoder编码的特征–>加噪–>去噪。额外单独train一个decoder,从特征空间还原到rgb空间。
2)使用sketch作为条件,可以实现更细致的控制
2.方法:
- Latent NeRF:
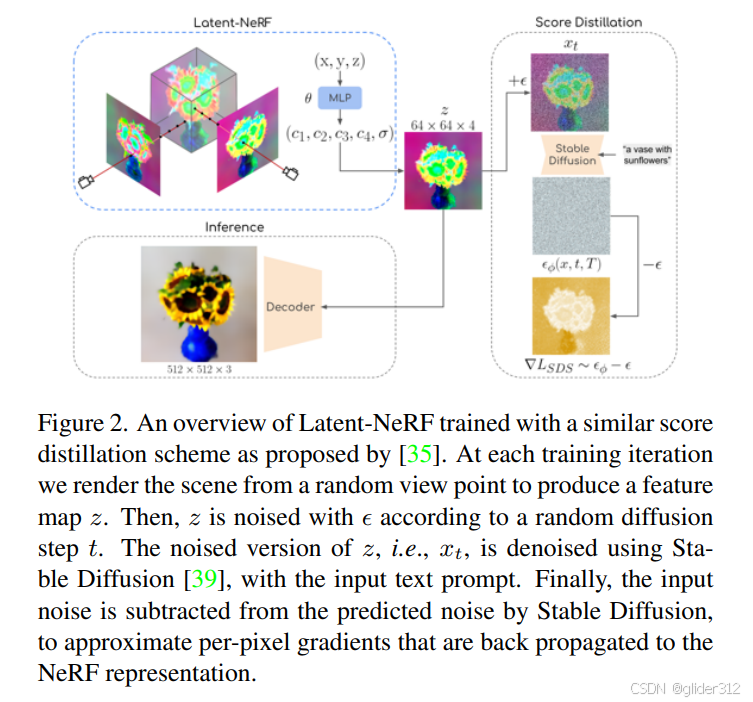
论文有一段话比较难读懂的:
Still, the fact that Z can be represented by a NeRF with spatial consistencies is non-trivial. Previous works [1,45] showed that super-pixels in Z depend mainly on individual patches in the output image. This can be attributed to the high resolution (64 x 64) and low channel-wise depth (4) of this latent space, which encourages local dependency over the autoencoder’s image and latent spaces. Assuming Z is a near patch level representation of its corresponding RGB image makes the latents nearly equivariant to spatial transformations of the scene, which justifies the use of NeRFs for representing the 3D scenes.
解读:Latent-NeRF相比于Dreamfusion主要区别:Dreamfusion用NeRF渲染图直接输入diffusion。Latent-NeRF则是用NeRF渲染出四通道(与LDM的vae encoder编码空间一致)特征图输入LDM的加噪去噪过程(Unet)。那么首先要说清楚,为什么可以用NeRF渲染这个四通道特征图?这个渲染还有意义吗?
a. “the fact that Z can be represented by a NeRF with spatial consistencies is non-trivial”,理解为, Z 可以用具有空间一致性的 NeRF 来表示这一事实并非微不足道。
b. 因为latent空间(vae编码后特征空间)分辨率高,通道数少,加噪后的噪声Z中,superpixel(具备类似纹理、颜色、亮度等特征的像素块)对应了原图的块。说人话就是,Z可以近似理解为对原图的块级表示,因此,对应RGB空间的空间变换,与这个latent特征的空间变换是一致的。
我不禁要问,问啥非得要这么搞?直接像Draemfusion那样输入RGB空间不也挺好吗?结果最后还要自己train一个decoder,说白了就少了一个encoder,还是frozen的??虽然latent空间和RGB空间是一致的,但是一致,也不是完全相等呀??
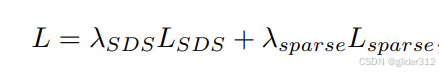
后面的sparse正则,跟dreamfield中的背景正则类似,让背景干净一点,整体稀疏。
-
再train一个decoder,之前研究[45]表明一个线性层就足够了(某种程度上又论证了可以用Nerf表示latent空间)

初始化为这个,然后再跟其他一起finetue。 -
Sketch-Shape Guidance
定义Sketch-Shape:球、长方体、盒子等基础形状构成的大致形状,例如:


sketch起到一个指导作用,但也希望能生成更多的细节,通过了winding-number indicator构建了一个损失函数:
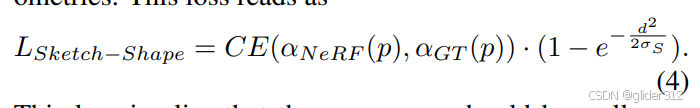
可以理解为,winding-number指示了是否在sketch内,离sketch越近的会通过这个loss更大概率预测存在物体表面。 -
Latebt-Paint of Explicit Shapes
这一部分是实现已有Mesh的渲染
训练好latent-nerf后(即nerf的mlp参数),冻结latent-nerf。假设已有Mesh,通过latent-nerf可以得到渲染后的lantent(没有颜色),初始化一个latent image(UV map的图片),将这个image贴图到渲染后无颜色的latent的表面,然后同样经过sd,利用sds反向传播,区别是不更新latent-nerf,而是更新这个latent image。
最后这个latent image经过vae decoder得到最终贴图。
3. 评价
多的不说,还是老的一致性问题
四.Magic3D:High-Resolution Text-to-3D Content Creation(CVPR2023)
1.背景
dreamfusion两个缺点:
- 监督是64x64的低分辨率图片,导致生成3D几何和纹理细节比较差
- NeRF的MLP效率低,时间长(1.5 hours TPUv4)。
2.方法
核心:升级版快速Nerf(Instant NGP)粗生成场–>转化为SDF–>利用DMDET原理精修为Mesh。
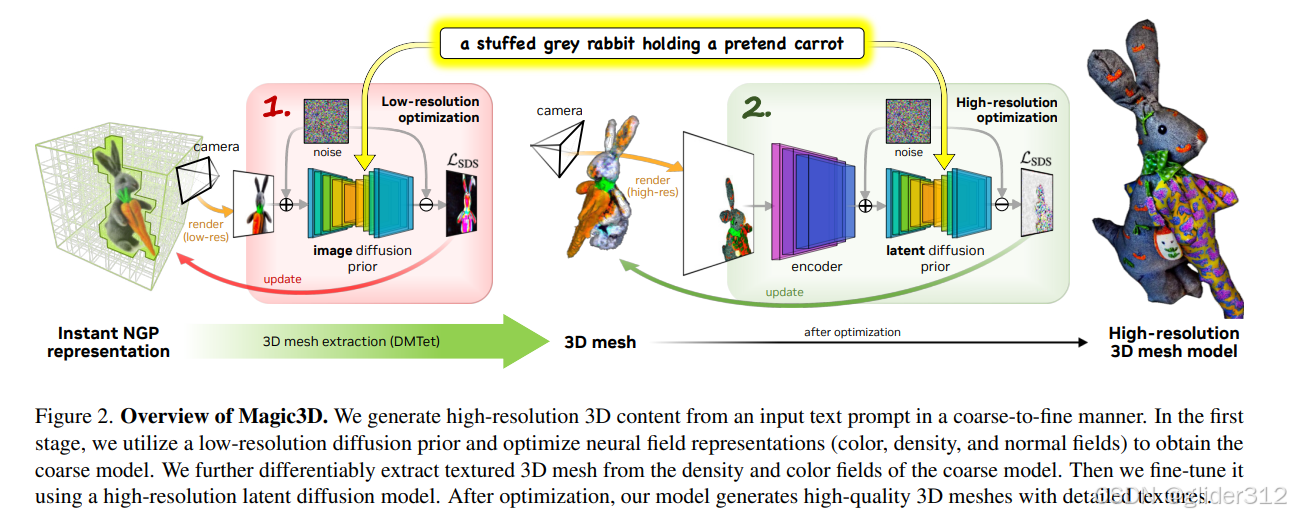
2.1 Coarse-to-fine Diffusion
一阶段采用eDiff-I,像素低64*64,二阶段SD,像素512*512
都预训练,使用Dreamfusion提出的SDS作为监督。
2.2 Coarse阶段场景建模
Dreamfusion中的Mip-NeRF360–>Instant NGP,更快
两个单层的MLP,一个预测颜色和预测密度,一个预测法向。
基于八叉树的射线采样和渲染算法
2.3 Fine阶段
采用DMTET表示方法,不过监督换成生成Mesh后渲染图的SDS损失函数
2.4 其他
还有其他很多小的技术手段。。
2.5 结果
性能提升8x,速度提升2x
3. 备注
论文中涉及到了很多mesh optimization和rasterization的背景,还有4篇核心论文,暂时挖个坑,等博主补上背景知识再回头来详细写。
五.Fantasia3D:Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation(ICCV 2023)
1. 背景
NeRF的Novel-View synthesis不错,但是表面重建不好。
“因为耦合了几何信息和每个空间点颜色信息,所以精细的几何和材质纹理两方面都不是很高效[43,46]”
[43]: Neus
[6]: Volume rendering of neural implicit surfaces
跟这两篇文献从隐式表达中重建表面的工作不同,本文采用了hybrid scene representation: DMTET。即隐式场+Mesh表达。见博客
因为NeRF耦合空间和颜色信息的问题,本文讲这两个问题进行了解耦。
a. 采用DMTET重建几何表面,用渲染法向图输入pretrained diffusers做SDS监督。
b. full BRDF(Bidirectional Reflectance Distribution Function) learning。
2. 方法
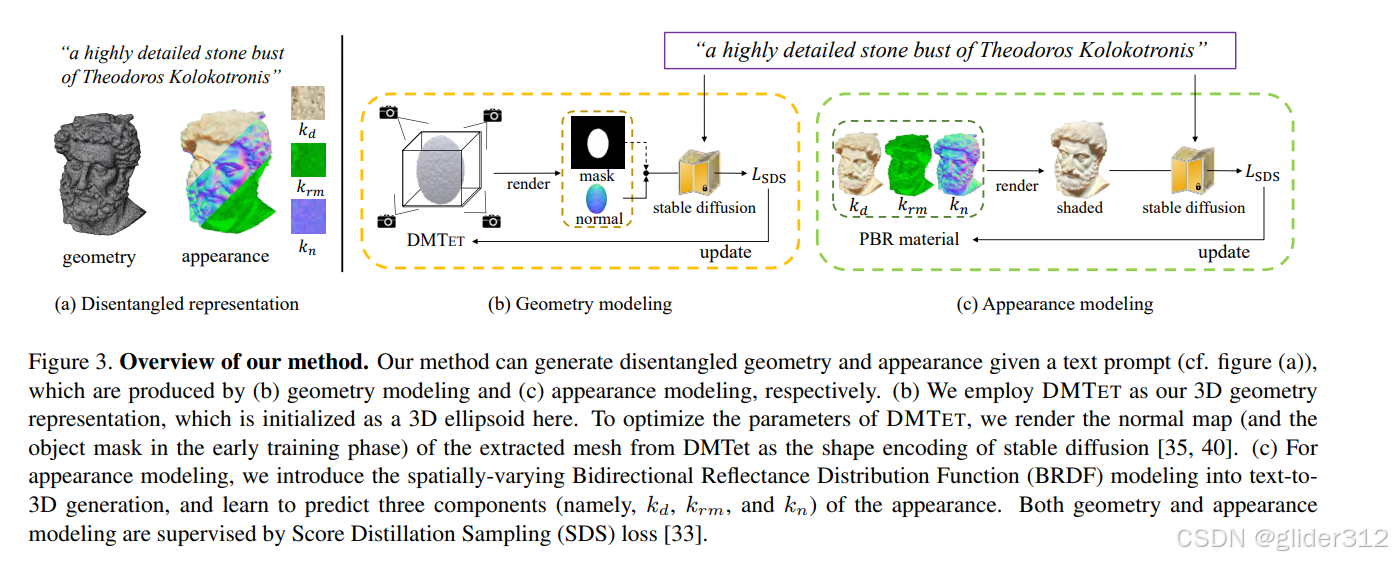
分别用两个模型对几何和颜色进行建模。
2.1 DMTET初始化
可以初始化为椭圆,或者依照用户喜欢自定义初始大概形状。这个椭圆对应的DMTET初始化(DMTET是一个SDF场+Mesh extractor,由于自定义/预设了形状,例如椭圆,这个形状对应的DMTET表达需要被初始化):采样这个椭圆表面附近的点做监督:
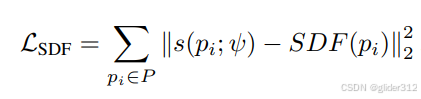
2.2 Geometry modeling
简单来说,得到了DMTET后进行渲染:
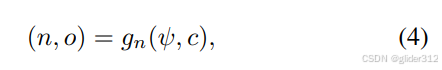
其中,
g
g
g为可微体渲染过程,
g
(
∗
,
∗
)
g(*,*)
g(∗,∗)中两项分别为DMTET表示和相机视角,生成
n
n
n为法相图,
o
o
o为物体mask图。
得到渲染图后,即可通过SDS监督
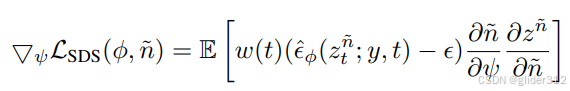
注:与magic3d区别:
magic3d先用nerf重建了粗粒度3D模型,再利用DMTET+SDS精修。
fantasia3d直接利用DMTET+SDS,把椭圆/人为设定作为粗粒度,相当于少了nerf的过程。
训练过程coarse to fine
- 类似于latent-nerf,先用降采样的法向图,作为sd的latent向量。但latent向量跟rbg空间肯定不天然对齐,这也是latent-nerf后续要重新train一个decoder映射回来的原因。这里coarse阶段为了更加对齐一点对法向图添加了随机噪声。
- 用没有mask o o o的法向图直接输入sd,vae编码后再加噪、去噪、SDS。
其实训练过程分两个阶段,也可以看出,fantasia3d少了nerf,但重新塞了一个coarse阶段。在摘要部分fantasia3d强调了很多nerf重建做的不行,关键magic3d也只把nerf作为coarse阶段呀!!fantasia阶段中coarse阶段对标magic3d中的nerf,那效果感觉还更差了不是。。。
2.3 外表建模
#挖个坑学习games101后来更新
六. ProlificDreamer:High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
1. intro
Q:
SDS问题:over-saturation, over-smoothing, low-diversity
文生3D方面,渲染分辨率和蒸馏time scheduler未被探索
A:
VSD取代SDS: SDS中一个固定的场景渲染出的图片与diffuser生成图片做对比。将场景/生成图片视为一个single point。 但是,其实在diffuser角度来说,有一个文本prompt后,其实可以得到一个图片分布,这个分布下的采样都能满足这个文本prompt。VSD将前面的nerf场景也视为一个random varaiable,也视为一个分布,因此切换为让场的分布得到的渲染多视角图的分布与diffuser生成图片分布一致。这也是叫变分的原因。
实现过程中将多个场的参数视为分布下的一个粒子,通过Wasserstein gradient flow和gradient-based update rule优化。优化时需要估计场渲染出图像的score function,这里用了LoRA来估计。
代表场的参数和代表score function的LoRA参数可以交替更新。
证明了SDS是VSD的单点Dirac分布特例,有了score function估计,即便只有单点一个场也可以有更好的效果。VSD可以有正常的CFG(7.5),但SDS因为只需要一张图,常需要很大(100)。
提出了512*512的渲染图分辨率;退火蒸馏time shedule;scene initialization。
2. VSD
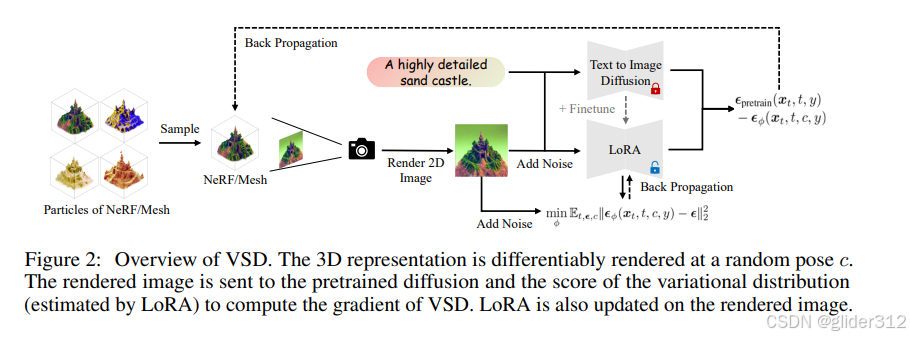
2.1 建模
将场景视为一个随机变量后,场景在给定视角下渲染图也成为了一个分布
q
0
μ
(
x
0
∣
c
,
y
)
q_{0}^{\mu} ( x_{0} | c, y )
q0μ(x0∣c,y),同时,输入文本后,diffuser生成的图片也有一个分布
p
0
(
x
0
∣
y
c
)
p_{0} ( x_{0} | y^{c} )
p0(x0∣yc),那么直观的想法是让他们的KL距离接近
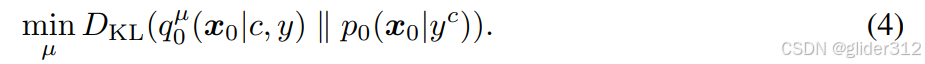
解这个很难,因为diffuser生成的图片分布很复杂,且在高纬稀疏([47]),参考diffusion,把优化设置成多步:
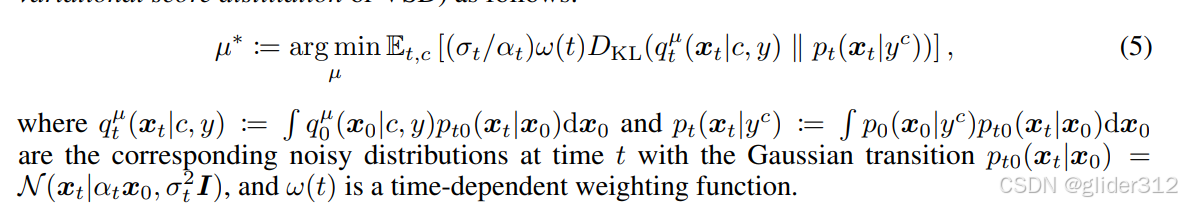
它的最优等价于(4)的最优。 (证明见论文)
2.2 求解
求解
μ
{\mu}
μ,最直观的方式就是训练另一个生成式模型。个人理解,
μ
{\mu}
μ是一个分布,用NN来模拟的话,就是一个网络,这个网络可以通过采样噪声输入,得到一个输出,这个输出是Nerf。
但这样显然会带来很多计算成本。
本文用了一种基于粒子的方法(particle-based variational inference methods[23,3,9])。
将采样样本(nerf场)视为粒子
{
θ
}
i
=
1
n
\{\theta\}_{i=1}^n
{θ}i=1n,通过解下面的ODE (Wasserstein gradient flow)来迭代更新
θ
\theta
θ。
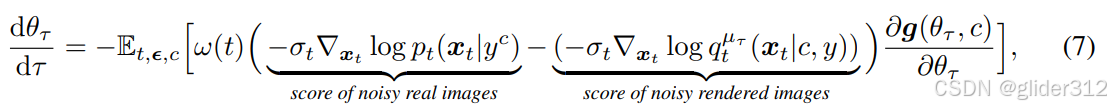
τ
→
∞
\tau\to\infty
τ→∞时
μ
∞
=
μ
∗
\mu_\infty=\mu^*
μ∞=μ∗
其中,
x
t
=
α
t
g
(
θ
,
c
)
+
σ
t
ϵ
\boldsymbol{x}_t=\alpha_t\boldsymbol{g}(\theta,c)+\sigma_t\boldsymbol{\epsilon}
xt=αtg(θ,c)+σtϵ
这当中,score of noisy real images,就是pretrained diffusion的预测;
score of noisy rendered images则需要估计,那其实同样可以用一个新的diffusion估计(训练一个专门针对rendered images的diffusion,然后预测输出就是这一项)。
这里在原来Unet基础上加入了LoRA。
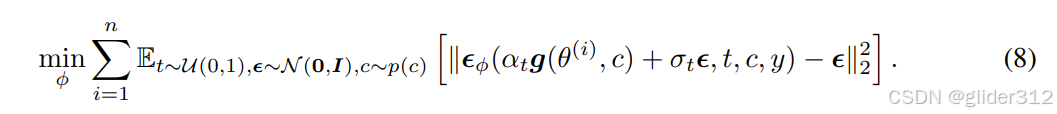
由于在diffusion中,预测score function,预测原图,预测噪声是等价的,那么可以将
ϵ
pretrain
(
x
t
,
t
,
y
)
\epsilon_\text{pretrain}(\mathbf{x}_t,t,y)
ϵpretrain(xt,t,y),
ϵ
ϕ
(
x
t
,
t
,
c
,
y
)
\epsilon_\phi(\mathbf{x}_t,t,c,y)
ϵϕ(xt,t,c,y)替换(7)中两个score function,就有了
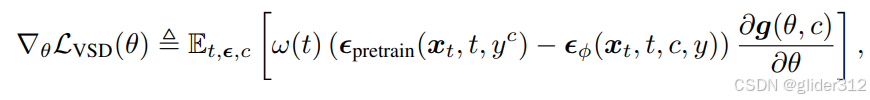
训练时,交替训练LoRA和Nerf场。即:多个Nerf场随机挑选一个通过SDS更新参数,然后Nerf场新生成的图像训练lora。

3. VSD与SDS比较
- SDS是VSD的Dirac分布下特殊情况
- VSD训练LORA过程时,额外利用到了文本prompt信息,能与文本更加对齐。
- 因为是分布对齐,不再需要一个很大的CFG
4. implementation
一阶段如上
二阶段DMTET(optional)

















 9425
9425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









