






今天看到一个新的webui方案,是Stability-AI开源的:
StableSwarmUI
是一个模块化的稳定扩散web用户界面,着重于使强大的工具易于访问、高性能和可扩展性。
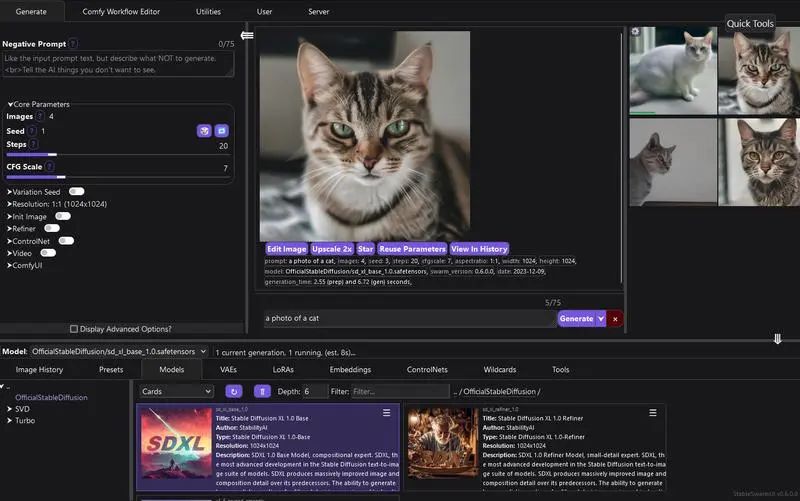
由于项目还在开发中,我们可以先了解下,翻看了它的特点,有一点非常吸引我,就是它对提示工程的处理。
More Than Text: Playing with Prompts 超越文本:提示工程
不就是text?没这么简单,下面的一些要点都非常值得我们学习,如果你在设计一个智能产品或者正在使用sd来创作,值得你查看以下关于prompt的设计:
提示主要是文本输入。不过,还有一些特殊选项可供使用:
1 提示加权,例如 an (orange) cat or an (orange:1.5) cat。括号中的任何内容都会被加权修改,这意味着模型会更加关注提示的这一部分。权重大于1表示更重要,小于1(如0.5)表示不太重要。你还可以按住Ctrl键并按上/下箭头键来更改所选文本的权重。
注意:提示权重的理解方式因后端而异。
2 如果使用SDXL或UnClip,你可以通过将图像拖放到提示框中来使用 ReVision。这将使模型解释图像(使用ClipVision)并将其包含在提示中。
3 你可以使用语法<random:red, blue, purple>来随机从列表中选择每一代的选项。此随机是由主种子确定的 - 因此,如果你有一个固定的种子,这不会改变。
你可以使用逗号“,”来分隔条目,或者使用竖线“|”或两个竖线“||”。使用最独特的分隔符 - 因此,如果你希望在随机选项中包含逗号“,”,只需使用竖线“|”作为分隔符,逗号“,”将被忽略(例如random:red|blue|purple)。
条目可以包含例如1-5的语法,自动从1到5选择一个数字。例如,<random:1-3, blue>将返回1、2、3或blue中的任何一个。
你可以通过<random[1-3]:red, blue, purple>重复随机选择,例如可能返回red blue或red blue purple或blue。你可以在末尾使用逗号,如random[1-3,],以指定输出应该带有逗号,例如red, blue。这将避免重复,除非你的计数大于选项数。
4 你可以使用语法wildcard:my/wildcard/name从通配符文件中随机选择,通配符文件基本上是一个预先保存的文本文件,每行一个随机选项。在UI中,在“Wildcards”选项卡的底部进行编辑。你还可以从其他UI(即文本文件集合)导入通配符文件,只需将它们添加到Data/Wildcards文件夹中。这支持与随机相同的语法来获取多个选项,例如<wildcard[1-3]:animals>可能返回cat dog或elephant leopard dog。
5 你可以使用语法<repeat:3, cat>连续获得“cat”这个词3次(cat cat cat)。例如,你可以使用<repeat:1-3, <random:cat, dog>>来获得1到3个猫或狗的副本,例如可能返回cat dog cat。
6 你可以使用embed:filename在任何地方使用文本反转嵌入。
7 你可以使用lora:filename:weight来启用LoRA。请注意,通常最好使用页面底部的GUI来选择LoRA。请注意,提示中的位置无关紧要,LoRA实际上不是提示的功能,这只是一个方便的选项,供习惯于Auto WebUI的用户使用。
8 你可以使用preset:presetname来注入预设。通常更喜欢使用GUI来进行LoRA,这个选项可用于动态地调整预设(例如<preset:<random:a, b>>)。
9 你可以使用segment:texthere使用CLIP分割自动细化图像的一部分。或者segment:texthere,creativity,threshold - 其中creativity是修复强度,threshold是分割的最小阈值 - 例如,segment:face,0.8,0.5 - 默认为0.6的创造力,0.5的阈值。详情请参阅功能公告。
10 你可以使用clear:texthere自动将图像的部分清除为透明。这与分割(上面)使用相同的输入格式(出于明显的原因,这需要PNG而不是JPG)。例如,clear:background以清除背景为例。
把图像分割和抠图也纳入到了prompt里来操作,给了我很多启发,确实很多操作可以转化为prompt的语法,从而实现“自然语言操作界面“。
更多AIGC的知识沉淀,可以在知识库获取,目前已积累了4,012条标签化的知识。


















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









