







shadow:
从去年开始,我做了不少生成式AI的项目,包括MixCopilot、ComfyUI插件mixlab-nodes等,这一个领域的知识更新非常快,去年我们还在聊SDXL,现在生图的基础模型几乎已经切换为Flux了,在图像生成领域,开源已经对闭源的产品(MJ)产生了威胁(效果逼近)。
技术发展非常快,我们可以从系统性的角度,开始总结知识了。这个系列是Chip Huyen的一些技术文章的翻译总结,分享给大家。


长期以来,每个机器学习模型(AI模型)都以单一的数据模式运行——文本(翻译)、图像(对象检测、图像分类)或音频(语音识别)。
然而,生物智能并不局限于单一模态。人类可以阅读、说话和观察。我们听音乐来放松,留意奇怪的声音来发现危险。能够处理多模态数据对于我们或任何人工智能在现实世界中的运作都至关重要。
OpenAI 在其GPT-4V 系统中指出,“将其他模式(例如图像输入)纳入 LLM 是人工智能研究和开发的关键性前沿技术。”
将其他模态纳入 LLM(大型语言模型)可创建 LMM(大型多模态模型)。并非所有多模态系统都是 LMM。例如,文本到图像模型(如 Midjourney、Stable Diffusion 和 Dall-E)是多模态的,但没有语言模型组件。
多模态,意味着:
- 输入和输出具有不同的形式(例如文本到图像、图像到文本)
- 输入是多模式的(例如,可以同时处理文本和图像的系统)
- 输出是多模式的(例如,可以生成文本和图像的系统)
为何选择多模态?
如果没有多模态性,许多用例就不可能实现,特别是在处理混合数据模态的行业,例如医疗保健、机器人、电子商务、零售、游戏等。
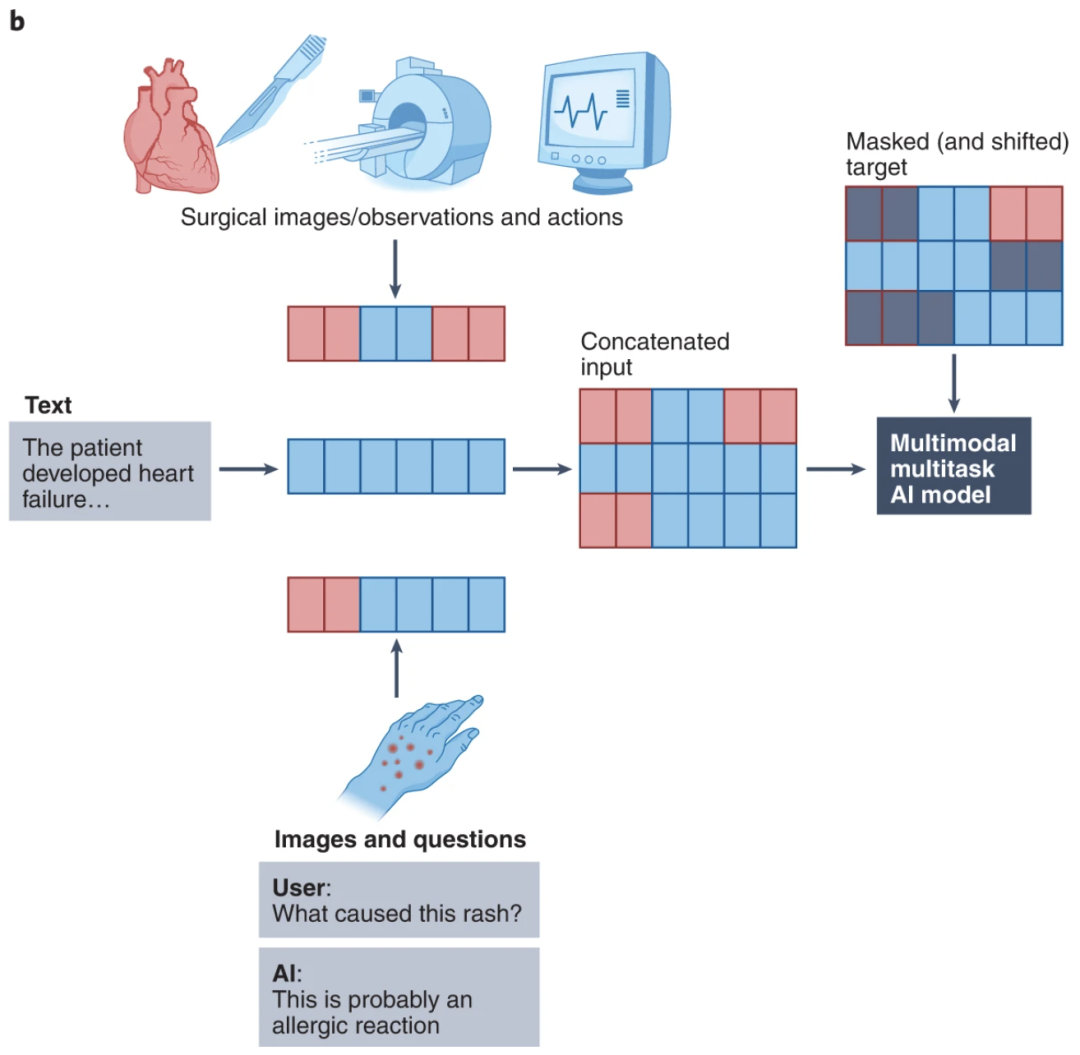
多模态技术在医疗保健中的应用示例。图片来自多模态生物医学 AI(Acosta 等人,《自然医学》2022 年)
不仅如此,结合其他模态的数据有助于提高模型性能。能够从文本和图像中学习的模型难道不应该比只能从文本或图像中学习的模型表现更好吗?
多模态系统可以提供更灵活的界面,让您以当前最适合的方式与它们交互。想象一下,您可以通过打字、说话或将相机对准某个物体来提问。
有一个特别兴奋的例子是,多模态还可以让视障人士浏览互联网并探索现实世界。

GPT-4V 中的一些很酷的多模态用例
数据模式
不同的数据模式包括文本、图像、音频、表格数据等。一种数据模式可以用另一种数据模式表示或近似。例如:
音频可以表示为图像(梅尔声谱图)。
语音可以转录成文本,但纯文本表示会丢失音量、语调、停顿等信息。
图像可以表示为矢量,而矢量又可以被展平并表示为文本标记序列。
视频是一系列图像和音频的组合。如今的机器学习模型大多将视频视为一系列图像。这是一个严重的限制,因为事实证明,声音对于视频来说与视觉效果同样重要。88 % 的 TikTok 用户表示,声音对于他们的 TikTok 体验至关重要。
只要你拍摄一张照片,文本就可以表示为图像。
数据表可以转换成图表,也就是图像。
其他数据模式怎么样?
所有数字数据格式都可以使用位串(0 和 1 的字符串)或字节串来表示。能够有效从位串或字节串中学习的模型将非常强大,它可以从任何数据模式中学习。
我们还未涉及其他数据形式,例如图形和 3D 资产。我们也没有涉及用于表示嗅觉和触觉(触觉)的格式。
在当今的机器学习中,音频仍然在很大程度上被视为基于语音的文本替代品。音频最常见的用例仍然是语音识别(语音转文本)和语音合成(文本转语音)。非语音音频用例(例如音乐生成)仍然相当小众。
图像可能是模型输入最通用的格式,因为它可用于表示文本、表格数据、音频以及某种程度上的视频。视觉数据也比文本数据多得多。如今,我们的手机/网络摄像头会不断拍摄照片和视频。
文本是模型输出的更强大的模式。可以生成图像的模型只能用于图像生成,而可以生成文本的模型可以用于许多任务:摘要、翻译、推理、问答等。
为简单起见,我们将重点关注两种模式:图像和文本。这些知识可以推广到其他模式。
多模态任务
要理解多模态系统,了解它们要解决的任务很有帮助。在文献中,我经常看到视觉语言任务分为两类:生成和视觉语言理解(VLU),后者是所有不需要生成的任务的总称。这两类任务之间
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









