







本文是本系列的第8篇文章,也是终结篇章。在本文中我们主要讲5层卷积神经网络参数更新和训练的代码实现,以及如何使用5层卷积神经网络来实现0~9的手写数字图像的识别。
首先还是列出本系列其它博文的超链接,方便读者跳转查阅:
4. 卷积神经网络原理及其C++/Opencv实现(4)—误反向传播法
5. 卷积神经网络原理及其C++/Opencv实现(5)—参数更新
6. 卷积神经网络原理及其C++/Opencv实现(6)—前向传播代码实现
7. 卷积神经网络原理及其C++/Opencv实现(7)—误反向传播代码实现
下面我们还是分别讲5层网络其余部分的代码实现吧~
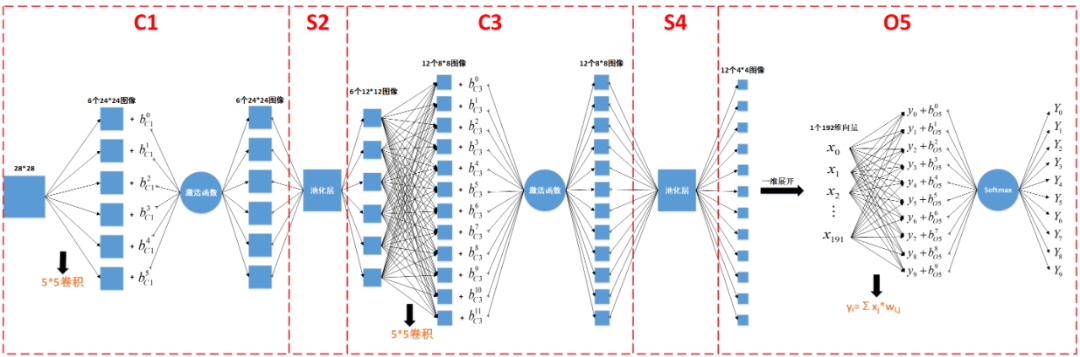
1. 训练过程中参数的更新
(1) O5层参数更新
本层需要更新的参数为192*10个权重值,以及10个偏置值。更新公式如下,其中α为学习率,Y为Softmax函数的输出,t为标签,x为Affine层的输入,0≤i<10,0≤j<192。


本层的参数更新代码实现如下:
void update_full_para(vector<Mat> inputData, CNNOpts opts, OutLayer &O)
{
int outSize_r = inputData[0].rows;
int outSize_c = inputData[0].cols;
Mat OinData(1, outSize_r*outSize_c*inputData.size(), CV_32FC1);
for (int i = 0; i < inputData.size(); i++) //12通道
{
for (int r = 0; r < outSize_r; r++) //4
{
for (int c = 0; c < outSize_c; c++) //4
{
//把本层输入的12个4*4图像展开成长度为192的一维向量
OinData.ptr<float>(0)[i*outSize_r*outSize_c + r*outSize_c + c] = inputData[i].ptr<float>(r)[c];
}
}
}
for (int j = 0; j < O.outputNum; j++) //10通道
{
for (int i = 0; i < O.inputNum; i++) //192通道
{
//w = w - α。dE/dw
O.wData.ptr<float>(j)[i] = O.wData.ptr<float>(j)[i] - opts.alpha*O.d.ptr<float>(0)[j] * OinData.ptr<float>(0)[i];
}
//b = b - α。dE/db
O.basicData.ptr<float>(0)[j] = O.basicData.ptr<float>(0)[j] - opts.alpha*O.d.ptr<float>(0)[j];
}
}
(2) C3层参数更新
本层需要更新的参数为6*12个5*5卷积核,以及12个偏置值。更新公式如下,其中α为学习率,k为本层的卷积核,b为本层的偏置,YS2为S2层的输出,dC3为C3层的局部梯度,sum为求矩阵中所有元素和的操作,0≤i<12,0≤j<6。dC3的计算可参考上篇博文:
卷积神经网络原理及其C++/Opencv实现(7)—误反向传播代码实现
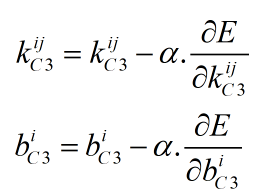
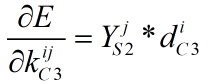

本层的参数更新代码实现如下:
void update_cov_para(vector<Mat> inputData, CNNOpts opts, CovLayer &C)
{
for (int i = 0; i < C.outChannels; i++) //6通道
{
for (int j = 0; j < C.inChannels; j++) //1通道
{
Mat Cdk = correlation(C.d[i], inputData[j], valid); //计算YS2*dC3
Cdk = Cdk*(-opts.alpha); //矩阵乘以系数-α.dE/dk
C.mapData[j][i] = C.mapData[j][i] + Cdk; //计算k = k - α.dE/dk
}
float d_sum = (float)cv::sum(C.d[i])[0]; //计算sum(dC3),这里有6个24*24的d,6个偏置b,一个偏置b对应一个24*24矩阵d的所有元素和
C.basicData.ptr<float>(0)[i] = C.basicData.ptr<float>(0)[i] - opts.alpha*d_sum; //计算b = b - α.dE/db
}
}
(3) C1层参数更新
本层需要更新的参数为6个5*5卷积核,以及6个偏置值。更新公式如下,其中α为学习率,k为本层的卷积核,b为本层的偏置,IC1为C1层的28*28输入图像(也即5层网络的一张28*28输入图像),dC1为C1层的局部梯度,sum为求矩阵中所有元素和的操作,0≤i<6。dC1的计算也可参考上篇博文。
卷积神经网络原理及其C++/Opencv实现(7)—误反向传播代码实现
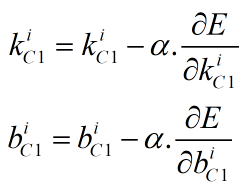

由于本层的参数更新代码操作与C3层一样,只是输入、输出参数不一样而已,因此本层的参数更新也可以调用上述update_cov_para函数来实现。
(4) 所有参数的更新
综上,C1、C3、O5层的参数更新代码如下,其中inputdata为5层网络的单张28*28手写数字图像。
void cnnapplygrads(CNN &cnn, CNNOpts opts, Mat inputData) // 更新权重
{
vector<Mat> input_tmp;
input_tmp.push_back(inputData);
update_cov_para(input_tmp, opts, cnn.C1);
update_cov_para(cnn.S2.y, opts, cnn.C3);
update_full_para(cnn.S4.y, opts, cnn.O5);
}
2. 训练过程中参数的清零
由于训练是一个多轮迭代的过程,且训练时会有参数累加的操作,下一轮训练开始之前需要将参数清零,否则累加操作会出问题。
//清零卷积层的参数
void clear_cov_mid_para(CovLayer &C)
{
int row = C.d[0].rows;
int col = C.d[0].cols;
for (int j = 0; j < C.outChannels; j++)
{
for (int r = 0; r < row; r++)
{
for (int c = 0; c < col; c++)
{
C.d[j].ptr<float>(r)[c] = 0.0;
C.v[j].ptr<float>(r)[c] = 0.0;
C.y[j].ptr<float>(r)[c] = 0.0;
}
}
}
}
//清零池化层的参数
void clear_pool_mid_para(PoolLayer &S)
{
int row = S.d[0].rows;
int col = S.d[0].cols;
for (int j = 0; j < S.outChannels; j++)
{
for (int r = 0; r < row; r++)
{
for (int c = 0; c < col; c++)
{
S.d[j].ptr<float>(r)[c] = 0.0;
S.y[j].ptr<float>(r)[c] = 0.0;
}
}
}
}
//清零输出层的参数
void clear_out_mid_para(OutLayer &O)
{
for (int j = 0; j < O.outputNum; j++)
{
O.d.ptr<float>(0)[j] = 0.0;
O.v.ptr<float>(0)[j] = 0.0;
O.y.ptr<float>(0)[j] = 0.0;
}
}
//调用上述函数实现5层网络的参数清零
void cnnclear(CNN &cnn)
{
clear_cov_mid_para(cnn.C1);
clear_pool_mid_para(cnn.S2);
clear_cov_mid_para(cnn.C3);
clear_pool_mid_para(cnn.S4);
clear_out_mid_para(cnn.O5);
}
2. 手写数字图像的读取
从网上下载的手写数字图像,是gz压缩文件,需要将其解压:

解压gz文件之后得到以下4个对应文件,其中train-images.idx3-ubyte为训练数据文件,train-labels.idx1-ubyte为训练数据的标签文件,t10k-images.idx3-ubyte为测试数据文件,t10k-labels.idx1-ubyte为测试数据的标签文件。

(1) 训练数据文件与测试数据文件的格式如下图所示:

文件格式:该区域的4个字节数据组成一个int数据,如果该int数据为2051,表示该文件是图像文件,如果是2049表示该文件是文本文件。因此对于训练数据和测试数据文件,本区域的值为2051。
图像总数:该区域的4个字节数据组成一个int数据,该int数据为文件中包含的图像总数。
图像行数:该区域的4个字节数据组成一个int数据,该int数据为每张图像的行数。
图像列数:该区域的4个字节数据组成一个int数据,该int数据为每张图像的列数。
需要注意的是,如果运行程序的处理器为英特尔处理器,需要把读到的4个字节数据按相反顺序排序,再组成int数据,比如首先我们读取到的int数据由byte0、byte1、byte2、byte3这4个字节数据组成(<<为左移运算):
d=(byte3<< 24)) + (byte2<< 16) + (byte1<< 8) + byte0
那么需要把4个数据按照相反顺序排序,重新组成int数据,这个重组的int数据才是我们想要的数据:
d'=(byte0<< 24)) + (byte1<< 16) + (byte2<< 8) + byte3
根据上述格式,训练数据文件与测试数据文件的读取代码如下,我们将同一个文件中的多张图像都读成Opencv的Mat格式,然后将多个Mat格式图像保存进vector数组中:
//将int数据中的4个字节数据按相反顺序重新排列,重组成一个int数据
int ReverseInt(int i)
{
unsigned char ch1, ch2, ch3, ch4;
ch1 = i & 0xff;
ch2 = (i >> 8) & 0xff;
ch3 = (i >> 16) & 0xff;
ch4 = (i >> 24) & 0xff;
return ((int)(ch1 << 24)) + ((int)(ch2 << 16)) + ((int)(ch3 << 8)) + (int)ch4;
}
vector<Mat> read_Img_to_Mat(const char* filename)
{
FILE *fp = NULL;
fp = fopen(filename, "rb");
if (fp == NULL)
printf("open file failed\n");
assert(fp);
int magic_number = 0;
int number_of_images = 0;
int n_rows = 0;
int n_cols = 0;
fread(&magic_number, sizeof(int), 1, fp); //从文件中读取sizeof(int) 个字符到 &magic_number
magic_number = ReverseInt(magic_number);
fread(&number_of_images, sizeof(int), 1, fp); //获取训练或测试image的个数number_of_images
number_of_images = ReverseInt(number_of_images);
fread(&n_rows, sizeof(int), 1, fp); //获取训练或测试图像的高度Heigh
n_rows = ReverseInt(n_rows);
fread(&n_cols, sizeof(int), 1, fp); //获取训练或测试图像的宽度Width
n_cols = ReverseInt(n_cols);
//获取第i幅图像,保存到vec中
int i, r, c;
int img_size = n_rows*n_cols;
vector<Mat> img_list;
for (i = 0; i < number_of_images; ++i)
{
Mat tmp(n_rows, n_cols, CV_8UC1);
fread(tmp.data, sizeof(uchar), img_size, fp); //读取一张图像
tmp.convertTo(tmp, CV_32F); //将图像转换为float数据
tmp = tmp / 255.0; //将数据转换成0~1的数据
img_list.push_back(tmp.clone());
}
fclose(fp);
return img_list;
}
(2) 标签文件的格式如下图所示:

文件格式:该区域的4个字节数据组成一个int数据,如果该int数据为2051,表示该文件是图像文件,如果是2049表示该文件是文本文件。标签文件属于文本文件,因此本区域的值为2049。
图像总数:该区域的4个字节数据组成一个int数据,该int数据为文件中包含的图像总数。
如果运行程序的处理器为英特尔处理器,同样需要把读到的4个字节数据按相反顺序排序,再重组成int数据。
每张图像表示的数字为0~9中的一个数字,因此图像标签就是0~9之中的一个数字,且该数字与图像表示的数字相对应。
由于卷积神经网络使用的是"one-hot"码,因此我们需要把0~9的标签数字转换为"one-hot"码:
0-->1 0 0 0 0 0 0 0 0 0
1-->0 1 0 0 0 0 0 0 0 0
2-->0 0 1 0 0 0 0 0 0 0
3-->0 0 0 1 0 0 0 0 0 0
4-->0 0 0 0 1 0 0 0 0 0
5-->0 0 0 0 0 1 0 0 0 0
6-->0 0 0 0 0 0 1 0 0 0
7-->0 0 0 0 0 0 0 1 0 0
8-->0 0 0 0 0 0 0 0 1 0
9-->0 0 0 0 0 0 0 0 0 1
根据上述格式,标签文件的读取代码如下,我们将同一个标签文件中的每个标签数字转换成"one-hot"码,然后再将"one-hot"码保存到一个1行10列的Mat结构当中,再将Mat保存到vector中:
vector<Mat> read_Lable_to_Mat(const char* filename)
{
FILE *fp = NULL;
fp = fopen(filename, "rb");
if (fp == NULL)
printf("open file failed\n");
assert(fp);
int magic_number = 0;
int number_of_labels = 0;
int label_long = 10;
fread(&magic_number, sizeof(int), 1, fp); //从文件中读取sizeof(magic_number) 个字符到 &magic_number
magic_number = ReverseInt(magic_number);
fread(&number_of_labels, sizeof(int), 1, fp); //获取训练或测试image的个数number_of_images
number_of_labels = ReverseInt(number_of_labels);
int i, l;
vector<Mat> label_list;
for (i = 0; i < number_of_labels; ++i)
{
Mat tmp = Mat::zeros(1, label_long, CV_32FC1);
unsigned char temp = 0;
fread(&temp, sizeof(unsigned char), 1, fp);
tmp.ptr<float>(0)[(int)temp] = 1.0; //将0~9的数字转换成one-hot码
label_list.push_back(tmp.clone());
}
fclose(fp);
return label_list;
}
3. 训练过程的实现代码
void cnntrain(CNN &cnn, vector<Mat> inputData, vector<Mat> outputData, CNNOpts opts, int trainNum)
{
// 学习训练误差曲线,记录交叉熵误差函数的值
cnn.L = Mat(1, trainNum, CV_32FC1).clone();
for (int e = 0; e < opts.numepochs; e++) //opts.numepochs表示需要训练次数
{
for (int n = 0; n < trainNum; n++) //trainNum表示由多少张图片,训练完这些图片相当于完成一次训练
{
//学习率递减0.03~0.001
opts.alpha = 0.03 - 0.029*n / (trainNum - 1);
cnnff(cnn, inputData[n]); // 前向传播
cnnbp(cnn, outputData[n]); // 后向传播
cnnapplygrads(cnn, opts, inputData[n]); // 更新参数
// 计算交叉熵误差函数的值
float l = 0.0;
for (int i = 0; i < cnn.O5.outputNum; i++)
{
l = l - outputData[n].ptr<float>(0)[i] * log(cnn.O5.y.ptr<float>(0)[i]);
}
cnn.L.ptr<float>(0)[n] = l;
cnnclear(cnn); //清零参数
printf("n=%d, f=%f, α=%f\n", n, cnn.L.ptr<float>(0)[n], opts.alpha);
}
}
}
4. 对手写数字图像分类的实现代码
//1行n列的向量
int vecmaxIndex(Mat vec) //返回向量最大数的序号
{
int veclength = vec.cols;
float maxnum = -1.0;
int maxIndex = 0;
float *p = vec.ptr<float>(0);
for(int i=0; i < veclength; i++)
{
if(maxnum < p[i])
{
maxnum = p[i];
maxIndex = i;
}
}
return maxIndex;
}
//测试函数
float cnntest(CNN cnn, vector<Mat> inputData, vector<Mat> outputData)
{
int incorrectnum = 0; //错误预测的数目
for (int i = 0; i < inputData.size(); i++) //inputData.size()为测试图像的总数
{
cnnff(cnn, inputData[i]); //前向传播
//检查神经网络输出的最大概率的序号是否等于标签中1值的序号,如果等于则表示分类成功
if (vecmaxIndex(cnn.O5.y) != vecmaxIndex(outputData[i]))
{
incorrectnum++;
printf("i = %d, 识别失败\n", i);
}
else
{
printf("i = %d, 识别成功\n", i);
}
cnnclear(cnn);
}
printf("incorrectnum=%d\n", incorrectnum);
printf("inputData.size()=%d\n", inputData.size());
return (float)incorrectnum / (float)inputData.size();
}
5. 总体测试的实现代码
以下函数就是5层网络的测试代码,在mian函数中调用。
void minst_cnn_test(void)
{
vector<Mat> traindata_list;
vector<Mat> traindata_label;
vector<Mat> testdata_list;
vector<Mat> testdata_label;
//读取训练数据标签
traindata_label = read_Lable_to_Mat("Minst/train-labels.idx1-ubyte");
//读取训练数据
traindata_list = read_Img_to_Mat("Minst/train-images.idx3-ubyte");
//读取测试数据标签
testdata_label = read_Lable_to_Mat("Minst/t10k-labels.idx1-ubyte");
//读取测试数据
testdata_list = read_Img_to_Mat("Minst/t10k-images.idx3-ubyte");
int train_num = traindata_list.size();
int test_num = testdata_list.size();
int outSize = testdata_label[0].cols;
int row = traindata_list[0].rows;
int col = traindata_list[0].cols;
CNNOpts opts;
opts.numepochs = 1;
opts.alpha = 0.03; //学习率初始值
int trainNum = 60000;
CNN cnn;
cnnsetup(cnn, row, col, outSize); //cnn初始化
cnntrain(cnn, traindata_list, traindata_label, opts, train_num); //训练
float success = cnntest(cnn, testdata_list, testdata_label); //分类
printf("success=%f\n", 1 - success); //打印分类的成功率
}
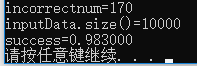
运行以上函数对5层网络进行手写数字图像的训练和分类测试,得到的结果如下,对10000张图像进行分类,分类失败170张,准确率达到98.3%,还是相当高的。
本系列的基于VS2015与Opencv3.4.1的完整代码工程,读者可在以下网址下载:
https://download.csdn.net/download/shandianfengfan/16392246
好了,本系列的文章就更新到这里啦,有人可能会说我重复造轮子没有意义,我倒不这么认为,因为这是一个学习的过程,自己去实现一遍会加深自己的理解。在深度理解之后,再去使用别人现成的深度学习框架,也会顺手得多。接下来的文章我们就不自己实现网络了,而是使用别人现成的深度学习框架,我们把主要精力放在网络的构建与训练模型的构建上面。
欢迎扫码关注以下微信公众号,接下来会不定时更新更加精彩的内容噢~

















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











