









深度学习论文: Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
PDF: https://arxiv.org/abs/2401.10891.pdf
代码:https://github.com/LiheYoung/Depth-Anything
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
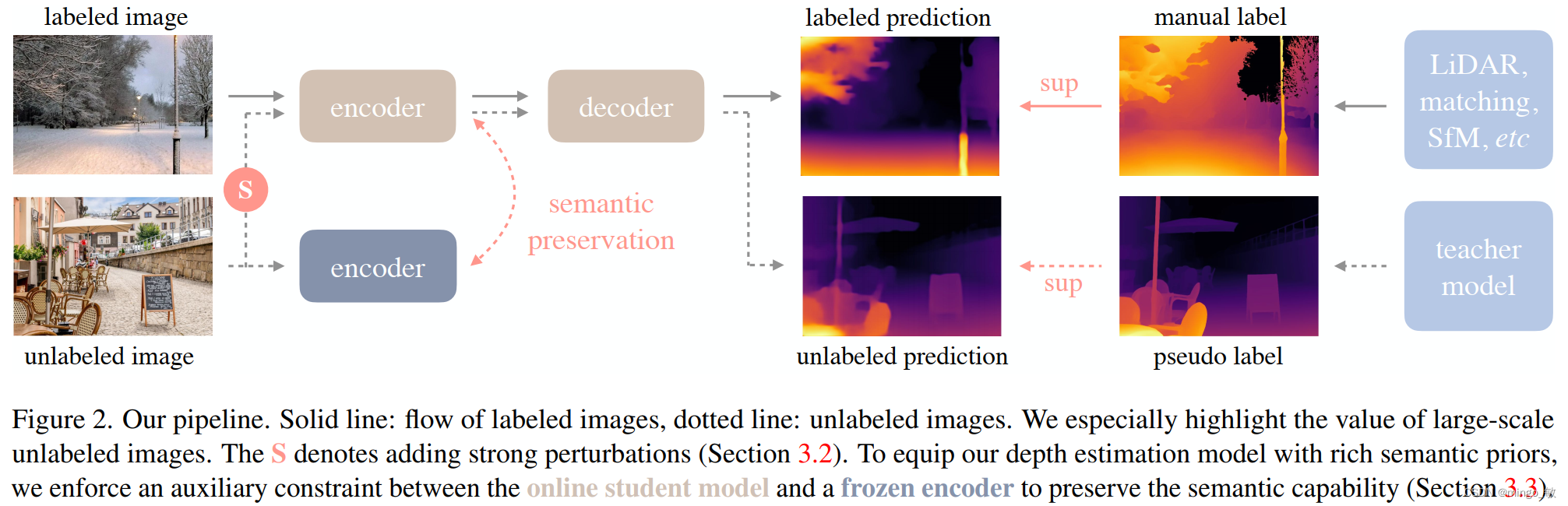
本文提出了名为Depth Anything的实用单目深度估计(MDE)方案,旨在构建能够处理各种任务环境图像的简单而强大的基础模型。方案从三个关键维度进行优化:首先,通过数据引擎实现大规模无标注数据的收集与自动标注,显著提升数据覆盖率和降低泛化误差;其次,利用数据增广工具创造更具挑战性的优化目标,增强模型对额外视觉知识的探索能力,提升特征鲁棒性;最后,设计辅助监督信息,使模型能够继承预训练Encoder中的丰富语义先验信息。

2 Depth Anything
本文提出了一种结合有标签和无标签图像训练的单目深度估计方法,以实现更优的性能。
首先,利用一个有标签的数据集来训练一个初始的“老师模型”T。这个模型通过监督学习的方式,从有标签的数据中学习深度估计的能力。
接着,利用这个已经训练好的老师模型T,对无标签的数据集进行预测,从而生成伪标签(pseudo-labels)。这些伪标签虽然不如真实的标签准确,但它们提供了关于无标签图像中深度信息的近似估计。
最后,结合有标签的数据集(包含真实标签)和经过伪标签标记的无标签数据集,共同训练一个“学生模型”S。通过这种方式,学生模型S能够同时从真实标签和伪标签中学习到深度估计的知识,从而进一步提升其性能。
这种方法充分利用了有标签和无标签数据集的各自优势,有效提升了单目深度估计的准确性和泛化能力。
本文所构建的有标签与无标签数据集,相比于MiDaS v3.1,该方案使用的有标签数据集更少(6 vs 12)。

2-1 Learning Labeled Images
采用类似于MiDaS的方法进行单目深度估计模型的训练。在训练中,深度值通过特定公式转换到视差空间,并进行归一化处理。同时为了适应多数据集训练,引入了仿射不变损失来忽略样本的比例和偏移差异。
为了增强模型的泛化能力和鲁棒性,
- 除了使用标记图像,还利用了大量易于获取且多样化的未标记图像。
- 此外,为了加强模型的编码器部分,使用了DINOv2的预训练权重进行初始化,
- 并利用预训练的语义分割模型来识别并处理图像中的天空区域,将其视差值设为最远点。
2-2 Unleashing the Power of Unlabeled Images
在单目深度估计(MDE)领域,利用未标记图像可以显著扩展数据覆盖范围并提升模型的泛化能力。本文提出一种方法,从互联网和公共数据集中收集大规模的未标记图像,并利用一个预训练的MDE模型为这些图像生成深度图的近似值。
在技术实现上,采用了一种基于教师-学生架构的策略。首先,利用已有的MDE教师模型T对未标记图像集进行预测,生成一个伪标记数据集。随后,将这个伪标记数据集与已有的标记图像集相结合,共同用于训练学生模型S。
然而,当标记图像的数量已经足够时,从额外的未标记图像中获取的额外信息可能会变得相对有限。特别是,由于教师和学生模型通常共享相同的预训练参数和架构,它们在未标记数据集Du上往往会做出类似的预测,无论是正确的还是错误的。
为了克服这一挑战,引入了数据增强技术。通过应用如颜色失真和CutMix空间失真等数据增强方法,增加了图像的多样性,从而迫使学生模型S从未标记图像中学习到更多样化的视觉特征和知识。这种策略有助于提升学生模型在未标记数据上的性能,进而增强整个单目深度估计系统的泛化能力。
2-3 Semantic-Assisted Perception
通过整合DINOv2模型的强大语义能力,提出了一个辅助特征对齐损失,用于改善深度估计模型的性能。该损失在深度模型的特征与DINOv2编码器的特征之间引入了对齐,同时保持了对深度信息的敏感性。
但是使用RAM、GroundingDINO和HQ-SAM模型进行语义分割,但未能提高深度估计性能,因为将图像解码到离散类空间损失了过多语义信息。因此引入DINOv2模型,利用其强大的语义能力通过辅助特征对齐损失来改善深度估计。特征对齐损失通过测量深度模型提取的特征与DINOv2编码器特征之间的余弦相似度来计算。
但是处于对特征对齐的考虑,不直接要求深度模型产生与DINOv2完全相同的特征,因为深度估计需要更精细的区分。同时引入容忍度α,仅当两个特征之间的余弦相似度低于α时才计算损失,允许深度模型保持其特有的深度感知能力。
因此提出的特征对齐损失不仅提高了深度估计性能,还使编码器在语义分割任务上表现出色,显示出作为多任务编码器的潜力。
3 Experiment
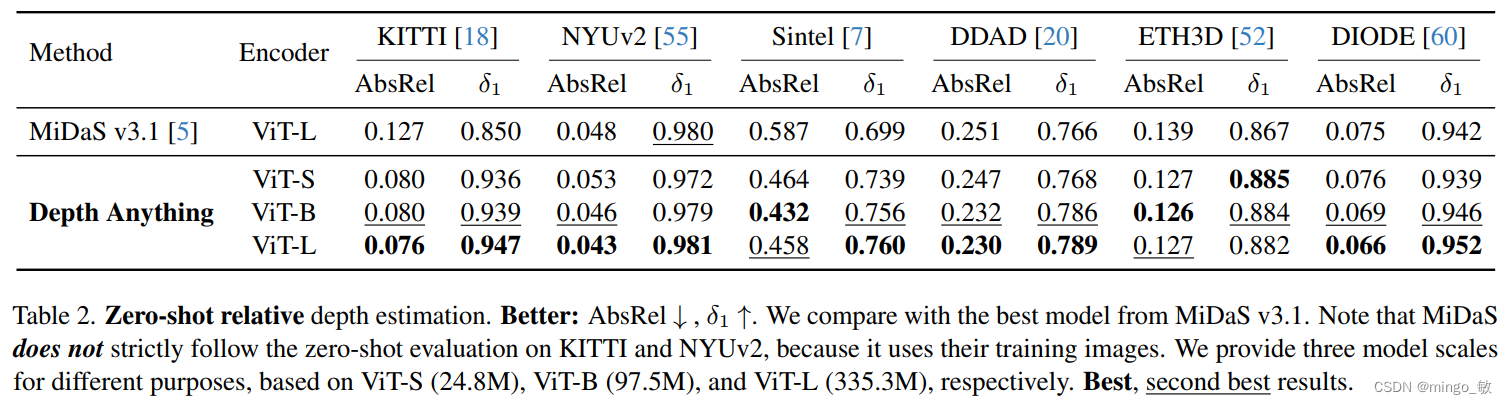
3-1 Zero-Shot Relative Depth Estimation
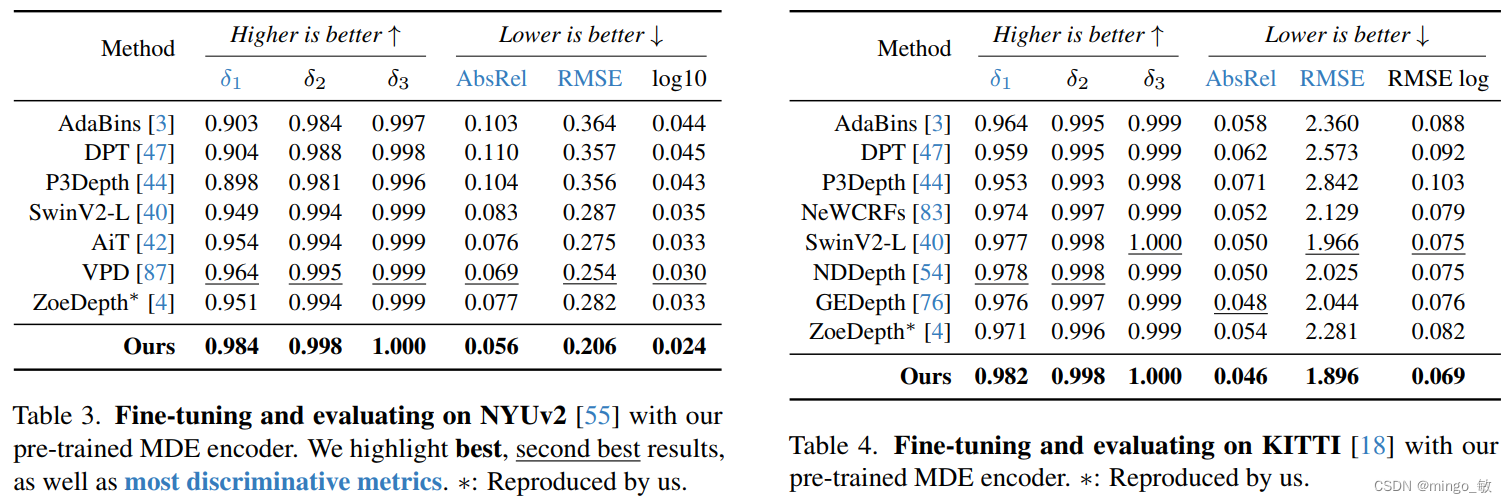
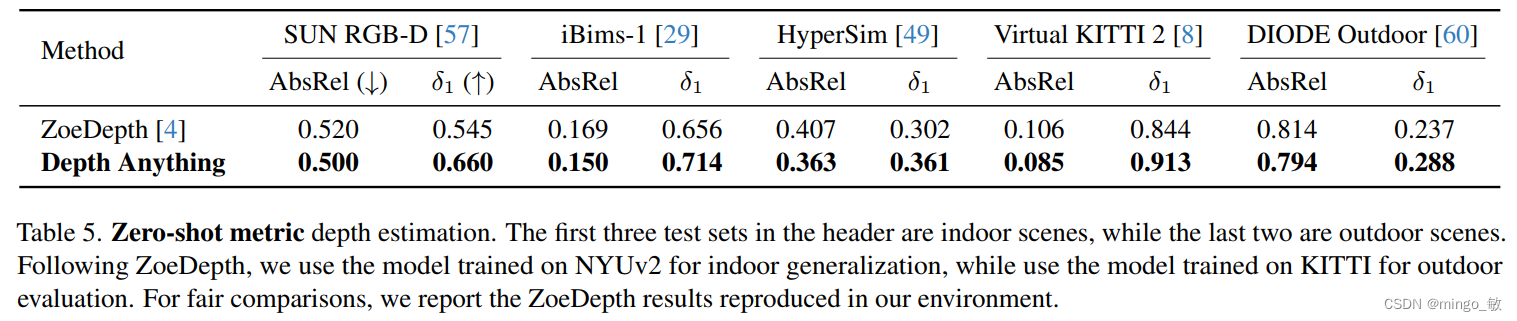
3-2 Fine-tuned to Metric Depth Estimation
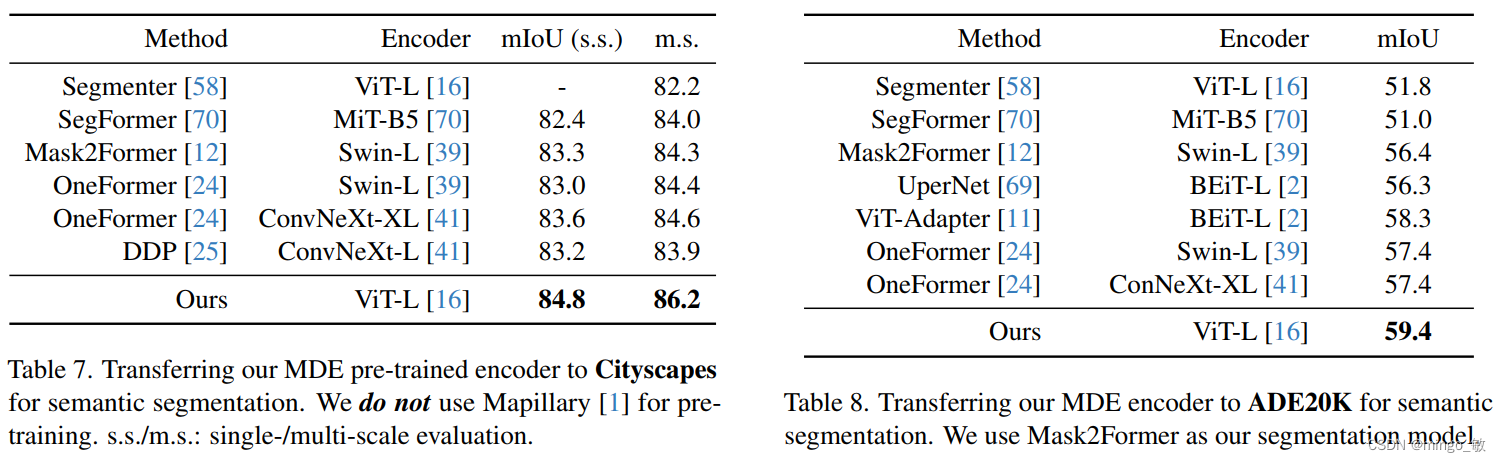
3-3 Fine-tuned to Semantic Segmentation















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









