







本文主要是对我们使用交叉验证可能出现的一个问题进行讨论,并提出修正方案。
本文地址:http://blog.csdn.net/shanglianlm/article/details/47207173
交叉验证(Cross validation)在统计学习中是用来估计你设计的算法精确度的一个极其重要的工具。本文主要展示我们在使用交叉验证时可能出现的一个问题,并提出修正的方法。
下面主要使用 Python scikit-learn 框架做演示。
先验理论(Theory first)
交叉验证将数据集随机地划分成 k 类,每类作为一个测试集,用剩余 k-1 个类作为训练集。交替作为测试集计算 k 次,求每次的均方误差 (MSE:mean squared error)。最后有
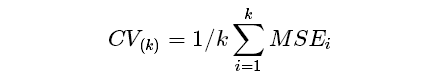
估计获得值,我们称之为 真是的 MSE,我们的目标是尽可能地使这个估计精确。
动手(Hands on)
全部代码见 IPython notebook on github
产生数据集(Dataset generation)
# Import pandas
import pandas as pd
from pandas import *
# Import scikit-learn
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import *
from sklearn.metrics import *
import random我们产生 100 个数据,每个数据 10,000 个特征(我们需要产生一些输入和输出间纯粹偶然的联系)。
features = np.random.randint(0,10,size=[100,10000])
target = np.random.randint(0,2,size=100)
df = DataFrame(features)
df['target'] = target
df.head()特征选择(Feature selection)
使用 corr() 函数,我们选出与目标最相关的两个特征。
corr = df.corr()['target'][df.corr()['target'] < 1].abs()
corr.sort(ascending=False)
corr.head()
# 3122 0.392430
# 830 0.367405
# 8374 0.351462
# 9801 0.341806
# 5585 0.336950
# Name: target, dtype: float64开始训练(Start the training)
根据上面从 10,000 选出的两个特征 3122(0.36) 和 830(0.39) 训练一个简单的 LogisticRegression 。接着我们使用 cross_val_score 来计算它的 MSE,有 MSE = 0.33 。
features = corr.index[[0,1]].values
training_input = df[features].values
training_output = df['target']
logreg = LogisticRegression()
# scikit learn return the negative value for MSE
# http://stackoverflow.com/questions/21443865/scikit-learn-cross-validation-negative-values-with-mean-squared-error
mse_estimate = -1 * cross_val_score(logreg, training_input, training_output, cv=10, scoring='mean_squared_error')
mse_estimate
# array([ 0.45454545, 0.27272727, 0.27272727, 0.5 , 0.4 ,
# 0.2 , 0.2 , 0.44444444, 0.33333333, 0.22222222])
DataFrame(mse_estimate).mean()
# 0 0.33
# dtype: float64知识泄露(Knowledge leaking)
如上,我们发现输出的结果和预测的不同,为什么?
当我们使用特征选择时,我们同时使用了来自训练集和测试集的信息。但在我们的 LogisticRegression 阶段,测试集的信息是不可见的。事实上,当我们在每次迭代计算 MSE^ 的时候,我们应该只使用来自训练集的信息。这里我们使用知识泄露(Knowledge leaking) 来描述这种情况。
下图是一个简单的描述:
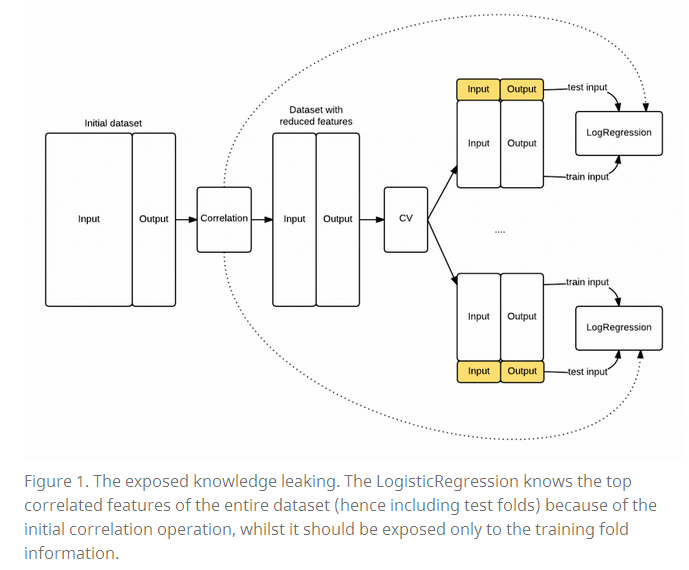
证明我们的做法有错(Proof that our model is biased)
接着我们来验证我们的做法是错误的,
* 从所有数据中取出一部分数据(take_out_set)。
* 用剩余的数据来训练 LogisticRegression 。
* 在 take_out_set 上计算 MSE 。
take_out_set = df.ix[random.sample(df.index, 30)]
training_set = df[~(df.isin(take_out_set)).all(axis=1)]
corr = training_set.corr()['target'][df.corr()['target'] < 1].abs()
corr.sort(ascending=False)
features = corr.index[[0,1]].values
training_input = training_set[features].values
training_output = training_set['target']
logreg = LogisticRegression()
logreg.fit(training_input, training_output)
# LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
# intercept_scaling=1, max_iter=100, multi_class='ovr',
# penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
# verbose=0)
y_take_out = logreg.predict(take_out_set[features])
mean_squared_error(take_out_set.target, y_take_out)
# 0.53333333333333333很明显,我们在 take_out_set 获得的 MSE(0.53) 与我们使用 CV 获得的 MSE^(0.33) 不一样。
正确的做法(Cross validation done right)
先前的部分,我们可以看到我们出错的主要原因是把测试集的信息也添加到特征选择阶段,因此我们修改我们的模型,使得特征选择阶段只使用来自训练集的信息而不是全部数据的信息。
下面的图展示了修改后的序列图:
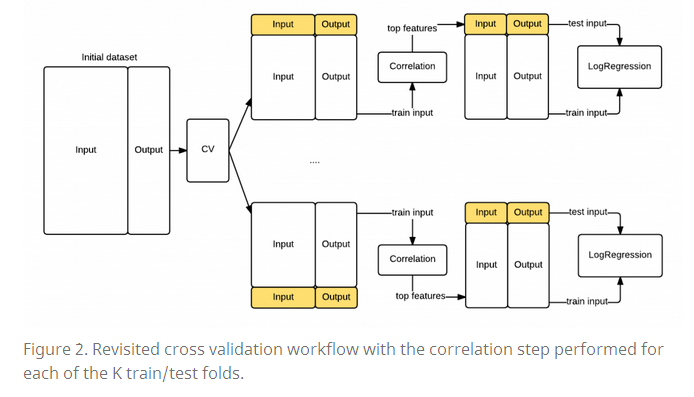
kf = KFold(df.shape[0], n_folds=10)
mse = []
fold_count = 0
for train, test in kf:
print("Processing fold %s" % fold_count)
train_fold = df.ix[train]
test_fold = df.ix[test]
# find best features
corr = train_fold.corr()['target'][train_fold.corr()['target'] < 1].abs()
corr.sort(ascending=False)
features = corr.index[[0,1]].values
# Get training examples
train_fold_input = train_fold[features].values
train_fold_output = train_fold['target']
# Fit logistic regression
logreg = LogisticRegression()
logreg.fit(train_fold_input, train_fold_output)
# Check MSE on test set
pred = logreg.predict(test_fold[features])
mse.append(mean_squared_error(test_fold.target, pred))
# Done with the fold
fold_count += 1
print(DataFrame(mse).mean())
# Processing fold 0
# Processing fold 1
# Processing fold 2
# Processing fold 3
# Processing fold 4
# Processing fold 5
# Processing fold 6
# Processing fold 7
# Processing fold 8
# Processing fold 9
DataFrame(mse).mean()
# 0 0.53
# dtype: float64结论(Conclusion)
If you want to make sure you don’t leak info across the train and test set scikit learn gives you additional extra tools like the feature selection pipeline4 and the classes inside the feature selection module5.
如果我们想确保我们没有泄露来自训练和测试集的信息到我们的模型中。我们可以使用 feature selection pipeline 和 feature selection module 。
参考及延伸材料:
[1] http://www.alfredo.motta.name/cross-validation-done-wrong/
[2] Scikit-learn framework
[3] [R. Kohavi. A study of cross-validation and bootstrap for accuracy estimation and model selection] (http://dl.acm.org/citation.cfm?id=1643047)
[4] [Y. Bengio and Y. Grandvalet. No unbiased estimator of the variance of k-fold cross-validation] (http://dl.acm.org/citation.cfm?id=1044695)


















 1882
1882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











