







前言
Pandas 是一个广受欢迎的 Python 数据分析库,它提供了高性能、易用的数据结构和数据分析工具。特别是对于处理和分析输入数据表格,Pandas 是非常有用的。这个库主要用于数据清洗和准备,它可以极大地简化数据预处理、分析和可视化的过程。以下是Pandas的一些主要特点:
主要特点:
-
DataFrame 对象:Pandas 的核心是 DataFrame 对象,这是一个用于数据操纵的二维表格结构,类似于 Excel 表格或 SQL 数据库中的表。DataFrame 支持对行和列进行操作,如选择、删除、新增和数据整合。
-
读写工具:Pandas 提供了从多种文件格式(如 CSV、Excel、JSON、SQL 数据库)读取数据的功能,并且可以将处理后的数据导出到这些格式,使得数据交换非常便利。
-
数据清洗功能:Pandas 提供了丰富的数据清洗功能,如处理缺失数据、数据过滤、去重、数据转换等,这对于确保数据质量和准备数据分析非常重要。
-
数据合并和连接:Pandas 有强大的数据合并和连接功能,允许用户方便地合并多个数据源,通过键来连接不同的数据表。
-
时间序列分析:Pandas 对时间序列数据的支持非常出色,包括日期范围生成、频率转换、移动窗口统计、日期位移等。
-
性能:Pandas 对于大数据集也有良好的性能表现,内部优化了很多操作,如内置的 C 语言操作库。
-
灵活的数据索引功能:允许用户使用标签而非仅仅是数字索引来定位数据,提高了数据操作的可读性和便利性。
常见用途:
- 数据清洗和准备
- 数据分析和统计
- 数据可视化配合 Matplotlib、Seaborn
- 机器学习数据准备
- 自动化报告数据处理
本文都将讲解最常用的 Pandas 函数以及如何实际使用它们。
1. pd.read_csv()
pd.read_csv 是 Python 中 panda 库中的一个函数,用于读取 CSV(逗号分隔值)文件并将其转换为 pandas DataFrame。
import pandas as pd
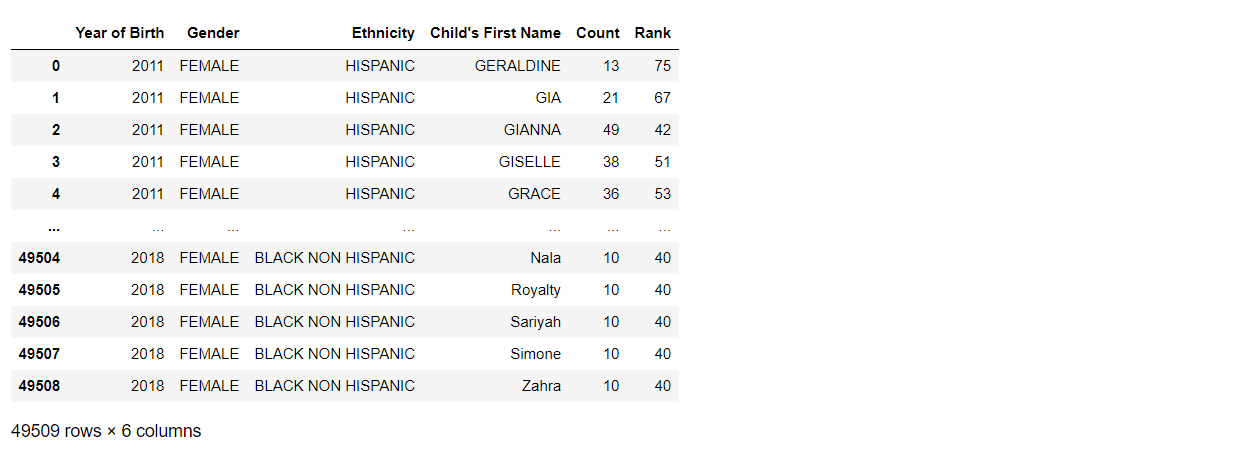
df = pd.read_csv('Popular_Baby_Names.csv')
在此示例中,76pd.read_csv 函数读取766文件“Popular_Baby_Names.csv”并将其转换为 DataFrame,然后将其分配给变量“df”。然后,可以使用打印函数打印 df 的内容。
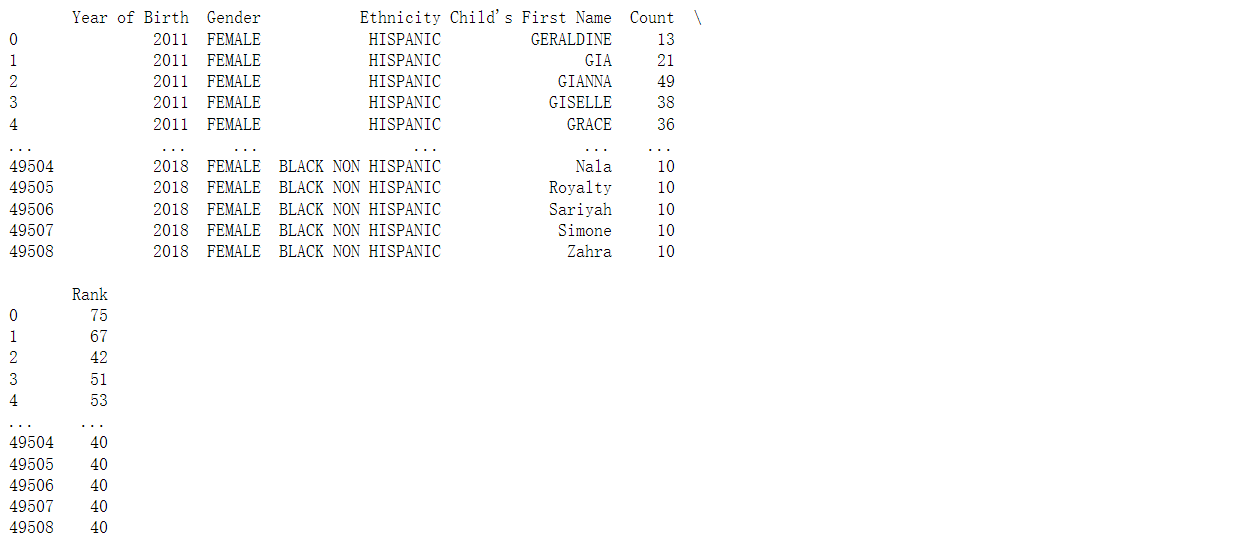
它有很多选项,如 sep 、 header 、 index_col 、 skiprows 、na_values等 。
df = pd.read_csv('Popular_Baby_Names.csv', sep=';', header=0, index_col=0, skiprows=5, na_values='N/A')
此示例读取 CSV 文件 data.csv ,以 ; 分隔符为分隔符,第一行为标题,第一列为索引,跳过前 5 行并替换 N/A 为 NaN。
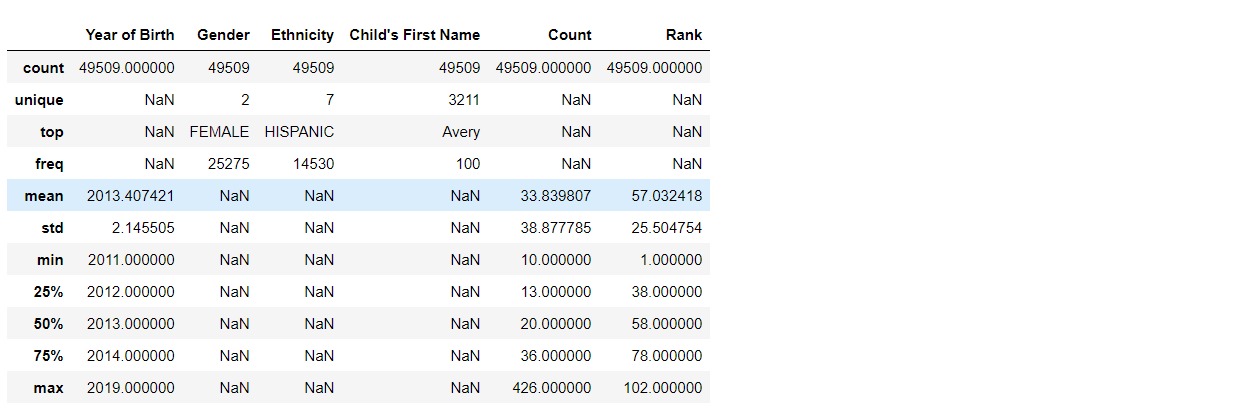
2. df.describe()
df.describe() 中的方法用于生成 DataFrame 各种特征的汇总统计信息。它返回一个新的 DataFrame,其中包含原始 DataFrame 中每个数值列的计数、平均值、标准差、最小值、第 25 个百分位数、中位数、第 75 个百分位数和最大值。

还可以包含或排除某些列,还可以通过向方法传递适当的参数来包含非数值列。
df.describe(include='all')
df.describe(exclude='number') # exclude numerical columns

3. df.info()
df.info() 是 pandas 中的一种方法,用于获取 DataFrame 的简明摘要,包括每列中非 null 值的数量、每列的数据类型以及 DataFrame 的内存使用情况。

4. df.plot()
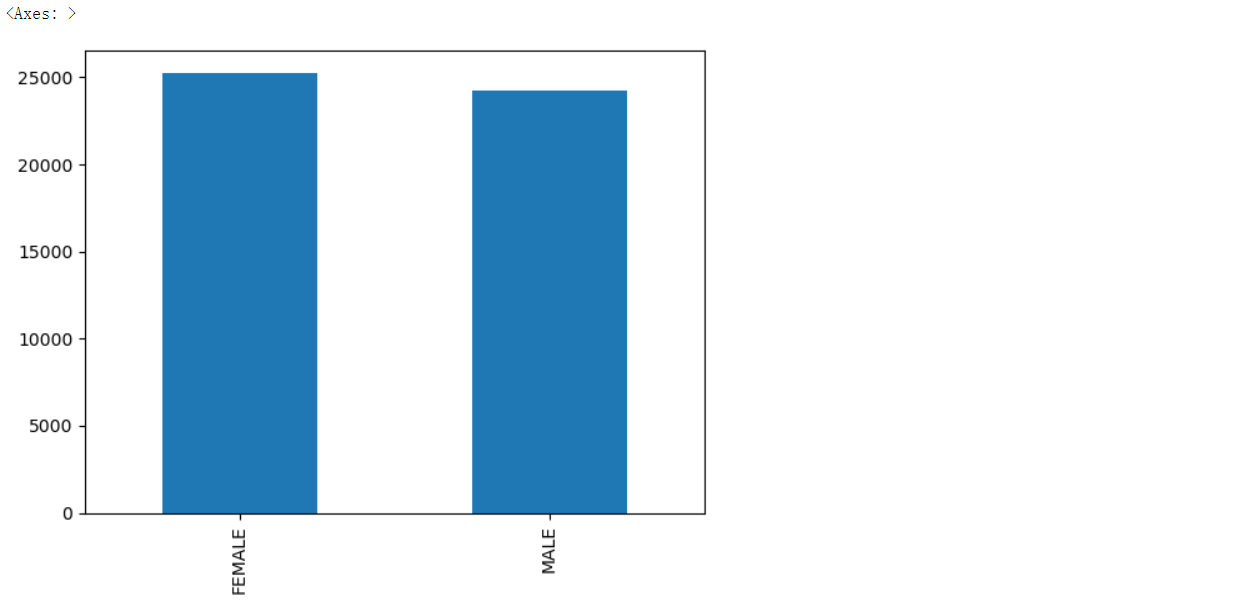
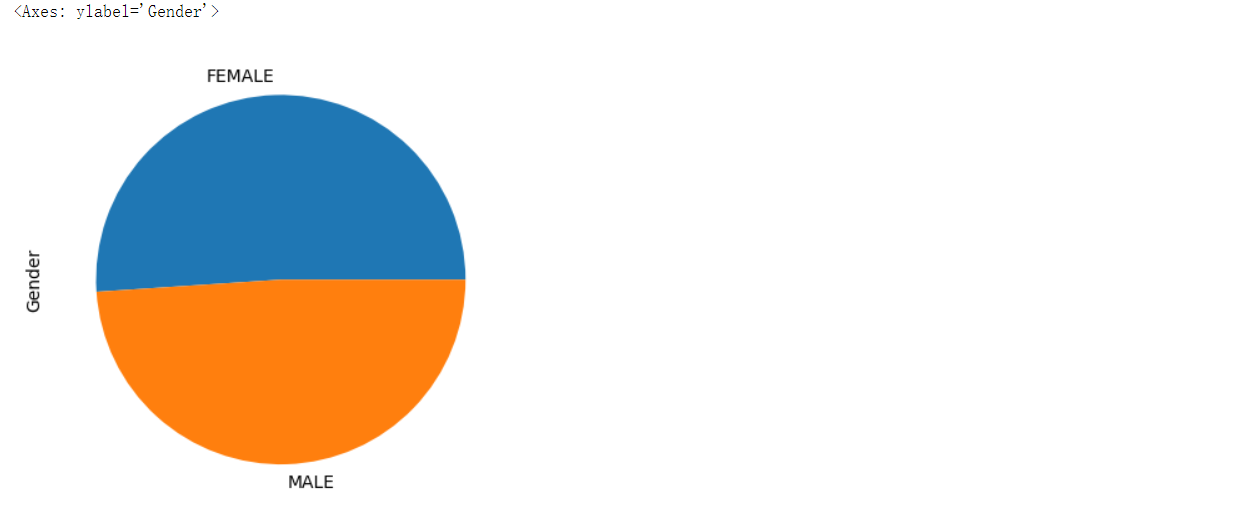
df.plot()是Pandas中的一个方法,用于从DataFrame中创建各种类型的图形。默认情况下,它会创建DataFrame中所有数值列的折线图。但是,你也可以传递kind参数来指定要创建的图形类型。可用选项包括line(折线图)、bar(条形图)、barh(水平条形图)、hist(直方图)、box(箱线图)、kde(核密度估计图)、density(密度图)、area(面积图)、pie(饼图)、scatter(散点图)和hexbin(六边形箱式图)。
在下面的示例中,我将使用.plot()方法绘制数值变量和分类变量。对于分类变量,我将绘制条形图和饼图,而对于数值变量,我将绘制箱线图。你可以自己尝试不同类型的图形。
数值变量绘图
df['Gender'].value_counts().plot(kind='bar')
df['Gender'].value_counts().plot(kind='pie')
df['Count'].plot(kind='box')
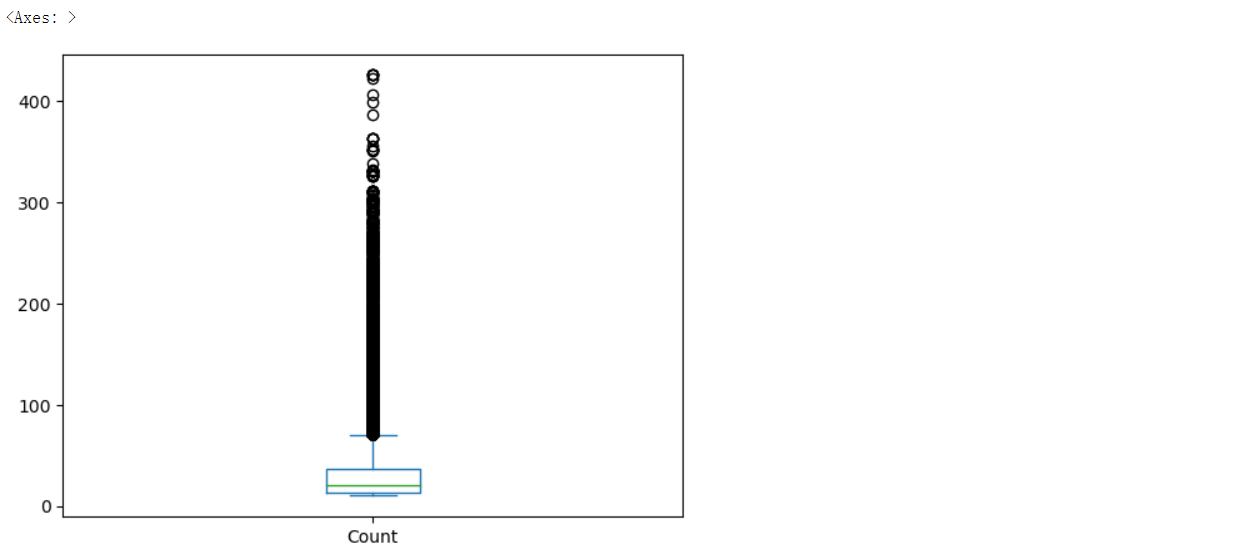
它还支持许多其他选项,如标题、x轴标签、y轴标签、图例、网格、x轴限制、y轴限制、x轴刻度、y轴刻度等,用于自定义绘图。你还可以在绘图后使用plt.xlabel()、plt.ylabel()、plt.title()等函数进行自定义。
请记住,df.plot()只是对matplotlib.pyplot库的一个方便封装,因此matplotlib中可用的所有自定义选项也同样适用于df.plot()。
5. df.iloc()
df.iloc() 函数用于在 DataFrame 中按基于整数的索引选择行和列。它用于按基于整数的位置选择行和列
print(df.iloc[0])

print(df.iloc[:2])
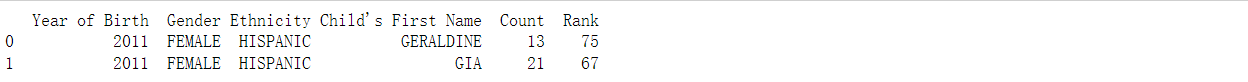
print(df.iloc[:, 0])

print(df.iloc[:, :2])

print(df.iloc[1, 1])

在上述示例中,df.iloc选择了数据框的第一行,df.iloc[:2]选择了前两行,df.iloc[:,0]选择了第一列,df.iloc[:,:2]选择了前两列,df.iloc选择了数据框中(1,1)位置的元素(第二行,第二列)。
请记住,iloc()只根据基于整数的索引来选择行和列,因此如果你想根据标签来选择行和列,你应该使用loc()方法,接下来将展示如何使用。
6. df.loc()
Pandas的.loc()函数用于通过标签索引(label-based index)在DataFrame中选择行和列。它可用于通过标签位置(label-based location)选择行和列。
print(df.loc[:,'Gender'])

print(df.loc[:, ['Year of Birth', 'Gender']])

在上面的示例中,我们使用df.loc[:,‘Gender’]来选择名为’Gender’的列,而df.loc[:,[‘Year of Birth’,‘Gender’]]则选择了名为’Year of Birth’和’Gender’的列。
7. df.assign()
Pandas的.assign()函数用于基于现有列的计算向DataFrame中添加新列。它允许你在不修改原始DataFrame的情况下向DataFrame中添加新列。该函数返回一个新的DataFrame,其中包含添加了新列的数据。
使用.assign()函数的基本语法如下:
new_df = df.assign(new_column_name=lambda df: computation)
其中,new_column_name是要添加的新列的名称,computation是一个lambda函数,用于计算新列的值。
df_new = df.assign(count_plus_5=df['Count'] + 5)
df_new.head()

在上面的示例中, df.assign() 用于创建名为“count_plus_5”的新列,其值为 count + 5。
例如,如果你想在DataFrame中添加一个新列,其值是现有列A和B的和,可以使用以下代码:
new_df = df.assign(new_column_name=lambda df: df['A'] + df['B'])
这将创建一个新的DataFrame,其中包含原始DataFrame的所有列,以及新添加的列new_column_name。
需要注意的是,.assign()函数返回一个新的DataFrame,不会修改原始DataFrame。如果你希望修改原始DataFrame,可以使用以下代码:
df['new_column_name'] = df['A'] + df['B']
这将在原始DataFrame中添加新的列new_column_name,其值是现有列A和B的和。
8. df.query()
Pandas的.query()函数允许你基于布尔表达式来过滤DataFrame。它使你能够使用与SQL相似的查询字符串从DataFrame中选择行。此函数返回一个新的DataFrame,其中仅包含满足布尔表达式的行。
df_query = df.query('Count > 30 and Rank < 20')
df_query.head()

df_query = df.query("Gender == 'MALE'")
df_query.head()

在上述示例中,第一次使用df.query()是为了选择计数大于30且排名小于30的行,第二次使用df.query()则是为了选择性别为‘MALE’的行。
需要注意的是,原始的DataFrame df保持不变,新的DataFrame df_query将返回包含过滤后的行。
.query()方法可以与任何有效的布尔表达式一起使用,当你需要基于多个条件过滤DataFrame,或者当条件复杂且难以使用标准索引操作符表达时,这个方法非常有用。
同时,请记住.query()方法比布尔索引慢,因此如果性能至关重要,你应该使用布尔索引。
9. df.sort_values()
Pandas 的 .sort_values() 函数允许你根据一个或多个列对 DataFrame 进行排序。它根据一个或多个列的值以升序或降序对 DataFrame 进行排序。该函数返回一个按指定列排序的新 DataFrame。
df_sorted = df.sort_values(by='Count')
df_sorted.head()

df_sorted = df.sort_values(by='Rank', ascending=False)
df_sorted.head()

df_sorted = df.sort_values(by=['Count', 'Rank'])
df_sorted.head()

在上述示例中,第一次使用 df.sort_values() 是按 ‘Count’ 列的升序对 DataFrame 进行排序,第二次使用是按 ‘Rank’ 列的降序进行排序,最后一次使用是按多个列 ‘Count’ 和 ‘Rank’ 进行排序。
需要注意的是,原始的 DataFrame df 保持不变,而返回的新 DataFrame df_sorted 包含了排序后的值。
.sort_values() 方法可以用于 DataFrame 的任何列,并且在你想要基于多个列对 DataFrame 进行排序,或者想要按某一列的降序对 DataFrame 进行排序时非常有用。
10. df.sample()
Pandas 的 .sample() 函数允许你从 DataFrame 中随机选择行。它返回一个包含随机选定行的新 DataFrame。该函数接受多个参数,使你可以控制抽样过程,例如返回的行数、是否替换抽样以及是否设定种子以保证结果的可重现性。
df_sample = df.sample(n=2, replace=False, random_state=1)
df_sample

df_sample = df.sample(n=3, replace=True, random_state=1)
df_sample

df_sample = df.sample(n=2, replace=False, random_state=1, axis=1)
df_sample

在上面的示例中,第一次使用 df.sample() 是为了随机选择 2 行,不进行替换;第二次使用是为了随机选择 3 行,并进行替换;最后一次使用是为了随机选择 2 列,不进行替换。
需要注意的是,原始的 DataFrame df 保持不变,而包含随机选定行的新 DataFrame df_sample 被返回。
.sample() 方法在你想要随机选择数据的一个子集进行测试或验证,或者当你想要随机选择一些行进行进一步分析时非常有用。random_state 参数对于保证结果的可重复性非常有帮助,而 axis=1 参数则允许你选择列。
11. df.isnull()
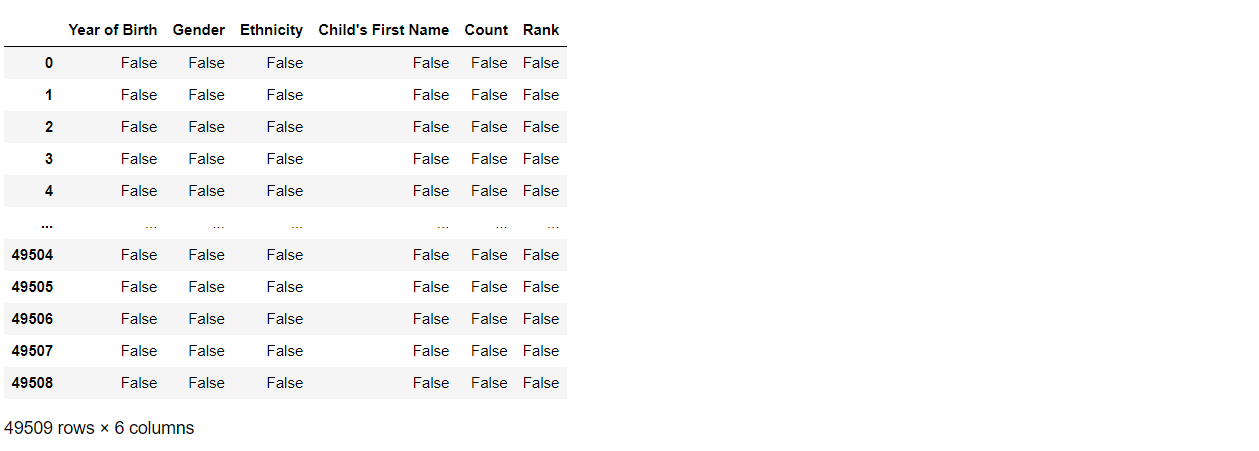
在 Pandas 中,isnull() 方法返回一个与原始 DataFrame 形状相同的 DataFrame,但包含 True 或 False 值来指示原始 DataFrame 中的每个值是否缺失。例如 NaN 或 None 这样的缺失值,在结果 DataFrame 中将标记为 True,而非缺失值将标记为 False。
df.isnull()
12. DF.Fillna()
在 Pandas 中,fillna() 方法用于用指定的值或方法填充 DataFrame 中的缺失值。默认情况下,它会将缺失值替换为 NaN,但你可以指定使用其他值,如下所示:
value: 指定用来填充缺失值的值。可以是一个标量值或不同列的值构成的字典。method: 指定填充缺失值的方法。可以是 ‘ffill’(向前填充)、‘bfill’(向后填充)、‘interpolate’(插值)、‘pad’(填充)、‘backfill’(向后填充)。axis: 指定沿哪个轴填充缺失值。可以是 0(行)或 1(列)。inplace: 是否在原地填充缺失值(修改原始 DataFrame),或返回一个填充了缺失值的新 DataFrame。limit: 指定连续缺失值填充的最大数量。downcast: 指定用于降低列数据类型的字典。
# fill missing values with 0
df.fillna(0)
# forward-fill missing values (propagates last valid observation forward to next)
df.fillna(method='ffill')
# backward-fill missing values (propagates next valid observation backward to last)
df.fillna(method='bfill')
# fill missing values using interpolation
df.interpolate()
重要提示:fillna() 方法返回一个填充了缺失值的新 DataFrame,并不会修改原始 DataFrame。如果你想修改原始 DataFrame,请使用 inplace 参数并将其设置为 True。
# fill missing values in place
df.fillna(0, inplace=True)
13. DF. Dropana()
df.dropna() 是 Pandas 库中用于从 DataFrame 中移除缺失或空值的方法。它会删除 DataFrame 中至少有一个元素缺失的行或列。
df = df.dropna()
如果你只想移除至少包含一个缺失值的列,可以使用 df.dropna(axis=1)。
df = df.dropna(axis=1)
你还可以将参数设置为 thresh 仅保留至少 thresh 具有非 NA/null 值的行/列。
df = df.dropna(thresh=2)
14. df.drop()
df.drop() 是 Pandas 库中用来通过指定对应的标签来移除 DataFrame 中行或列的方法。它可以根据标签来删除一个或多个行或列。
你可以通过调用 df.drop() 并传入你想要删除的行的索引标签,同时将 axis 参数设置为 0(默认值为 0)来移除特定的行。
df_drop = df.drop(0)
这将删除 DataFrame 的第一行。
你还可以通过传递索引标签列表来删除多行:
df_drop = df.drop([0,1])
这将删除 DataFrame 的第一行和第二行。
同样,你可以通过传入你想要删除的列的标签,并将 axis 参数设置为 1 来删除列:你可以通过传递你希望删除的列的标签,并将 axis 参数设置为 1 来删除列:
df_drop = df.drop(['Count', 'Rank'], axis=1)
15. pd.pivot_table()
pd.pivot_table() 是 Pandas 库中的一个方法,用于从 DataFrame 创建数据透视表。数据透视表是一种通过创建一个新表,将一个或多个列作为索引,一个或多个列作为值,以及一个或多个列作为属性,从而以更有意义和有组织的方式总结和聚合数据的表。
在下面的示例中,我们将创建一个以民族为索引的数据透视表,并聚合计数的总和。这用于了解数据集中每个民族的计数。
pivot_table = pd.pivot_table(df, index='Ethnicity', values='Count', aggfunc='sum')
pivot_table.head()

你还可以通过指定多个索引和值参数,并包括多个聚合函数(aggfunc),在数据透视表中包含更多列。
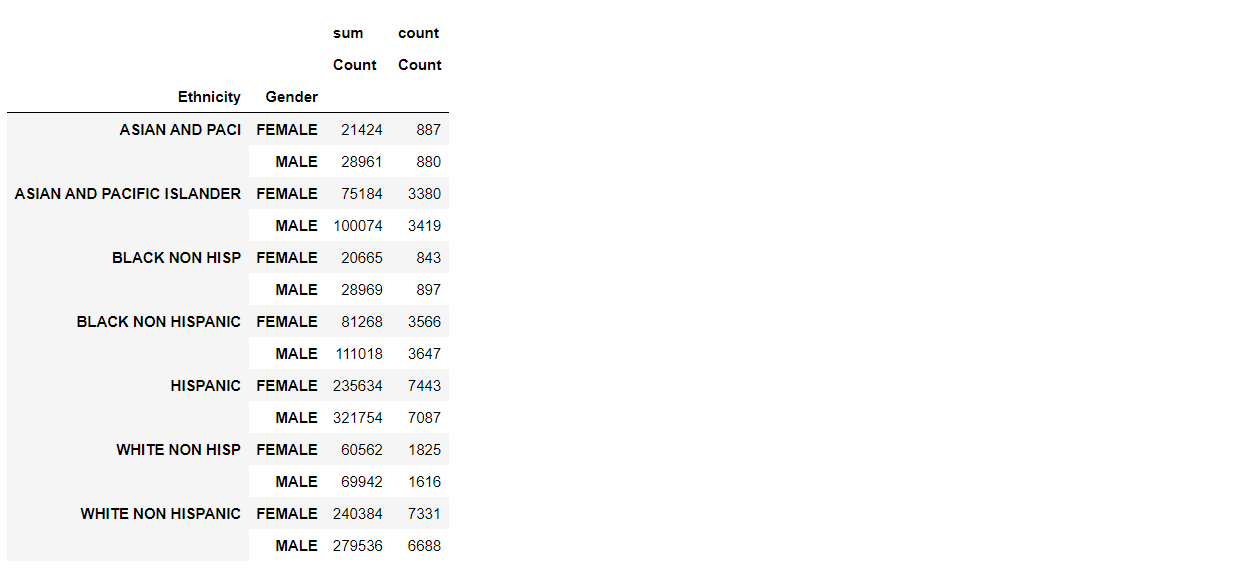
pivot_table = pd.pivot_table(df, index=['Ethnicity','Gender'], values= 'Count' , aggfunc=['sum','count'])
pivot_table.head(20)
16. df.groupby()
df.groupby() 是 Pandas 库中的一个方法,用于根据一个或多个列对 DataFrame 的行进行分组。这允许你对分组执行聚合操作,例如计算每个组中值的平均值、总和或计数。
df.groupby() 返回一个 GroupBy 对象,你可以使用它对分组执行各种操作,例如计算每个组中值的总和、平均值或计数。
让我们看一个使用出生姓名数据集的示例:
grouped = df.groupby('Gender')
# Print the mean of each group
print(grouped.mean())

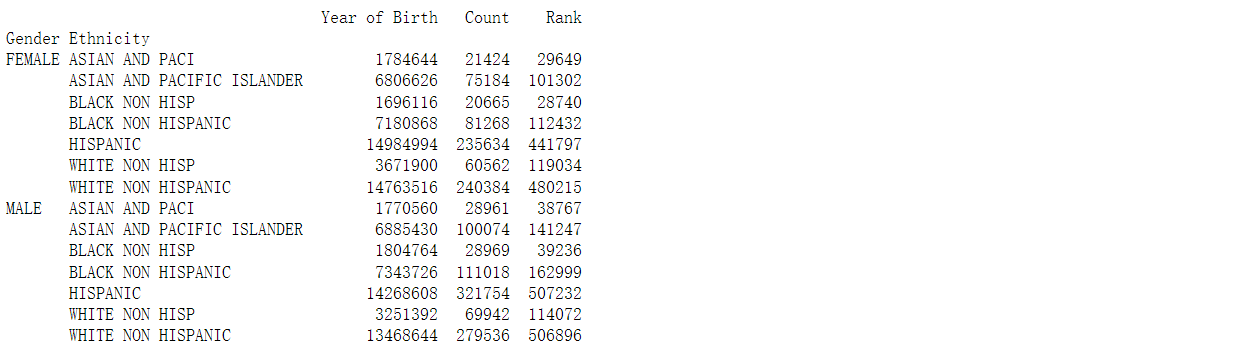
grouped = df.groupby(['Gender', 'Ethnicity'])
# Print the sum of each group
print(grouped.sum())
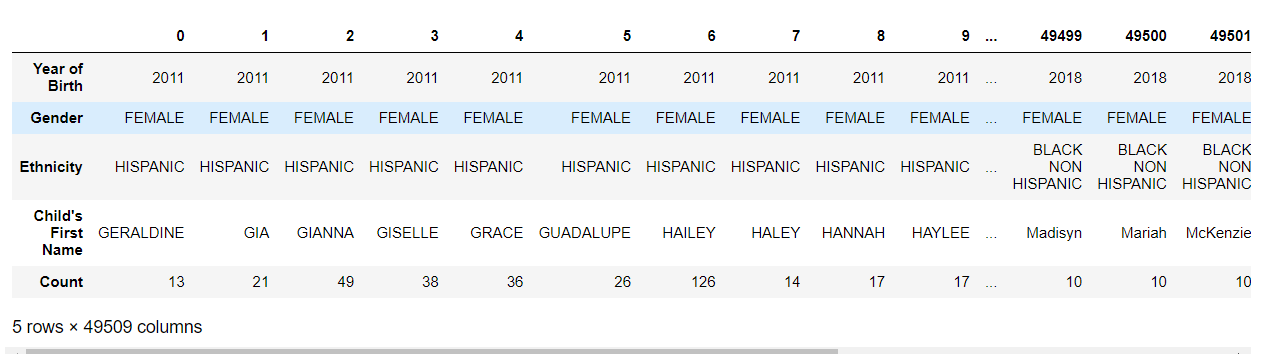
17. df.transpose()
df.transpose() 是 Pandas 库中用于转置 DataFrame 的行和列的方法。这意味着行变成列,列变成行。
# Transpose the DataFrame
df_transposed = df.transpose()
# Print the transposed DataFrame
df_transposed.head()
也可以使用 DataFrame 的 T 属性来实现。df.T 的效果与 df.transpose() 相同。
18. df.merge()
df.merge() 是一个 Pandas 函数,允许你根据一个或多个共同列合并两个 DataFrame。它类似于 SQL 中的 JOIN 操作。该函数返回一个新的 DataFrame,仅包含两个 DataFrame 中指定列的值匹配的行。
这里是一个示例,展示如何使用 df.merge() 基于一个共同列来合并两个 DataFrame:
# Create the first DataFrame
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
# Create the second DataFrame
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Merge the two DataFrames on the 'key' column
merged_df = df1.merge(df2, on='key')
# Print the merged DataFrame
print(merged_df)

如你所见,两个 DataFrame 是基于关键列进行合并的,合并后左右 DataFrame 的列名分别附加了 _x 和 _y。
你还可以通过分别传递 how=‘left’、how=‘right’ 或 how=‘outer’ 来使用左连接、右连接和外连接。
你也可以通过向 on 参数传递列的列表,来合并多个列。
merged_df = df1.merge(df2, on=['key1','key2'])
你还可以使用 left_on 和 right_on 参数来指定用于合并的不同列名。
merged_df = df1.merge(df2, left_on='key1', right_on='key3')
值得注意的是,merge() 函数拥有许多选项和参数,允许你控制合并的行为,比如如何处理缺失值、是保留所有行还是仅保留匹配的行,以及基于哪些列进行合并。
19. df.rename()
df.rename() 是一个 pandas 函数,允许你更改 DataFrame 中一个或多个列或行的名称。你可以使用 columns 参数来更改列名,使用 index 参数来更改行名。
# Rename column 'Count' to 'count'
df_rename = df.rename(columns={'Count': 'count'})
df_rename.head()

你还可以使用字典一次重命名多个列:
df_rename = df.rename(columns={'Count': 'count', 'Rank':'rank'})
df_rename.head()
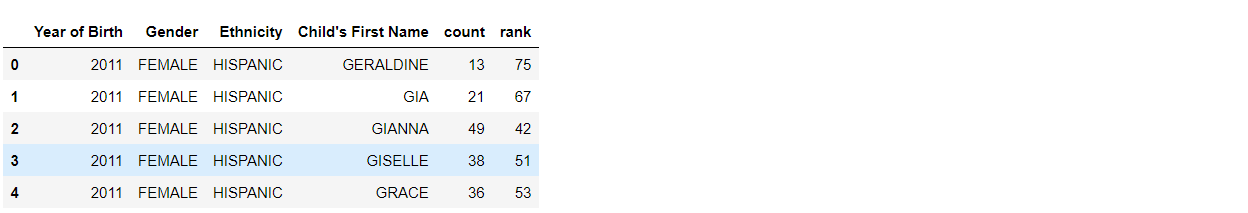
你也可以类似地重命名索引
df_rename = df.rename(index={0:'first',1:'second',2:'third'})
df_rename.head()

20. df.to_csv()
df.to_csv() 是 Pandas 库中用于将 DataFrame 导出到 CSV 文件的方法。CSV 代表“逗号分隔值”,它是一种用于以表格形式存储数据的流行文件格式。
例如,假设我们想要将 DataFrame df 导出到一个 CSV 文件。你可以通过调用 df.to_csv() 并传递文件名作为字符串来将 DataFrame 导出到 CSV 文件:
df.to_csv('data.csv')
这将把 DataFrame 保存为当前工作目录中名为 data.csv 的文件。你也可以通过传递文件路径给该方法来指定文件的存储位置:
df.to_csv('path/to/data.csv')
你还可以通过传递 sep 参数来指定 CSV 文件中使用的分隔符。默认情况下,它被设置为逗号(“,”)。
df.to_csv('path/to/data.csv', sep='\t')
还可以通过将列名列表传递给 columns 参数来仅保存 DataFrame 的特定列,同时通过将布尔掩码传递给 index 参数来仅保存特定的行。
df.to_csv('path/to/data.csv', columns=['Rank','Count'])
你也可以使用 index 参数来指定是否在导出的 CSV 文件中包含或排除数据框的索引。
df.to_csv('path/to/data.csv', index=False)
你还可以使用 na_rep 参数在导出的 CSV 文件中用特定值替换缺失值。
df.to_csv('path/to/data.csv', na_rep='NULL')















 6334
6334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











