







论文地址:(V1)https://arxiv.org/abs/1409.4842
本文所包含代码GitHub地址:https://github.com/shankezh/DL_HotNet_Tensorflow
如果对机器学习有兴趣,不仅仅满足将深度学习模型当黑盒模型使用的,想了解为何机器学习可以训练拟合最佳模型,可以看我过往的博客,使用数学知识推导了机器学习中比较经典的案例,并且使用了python撸了一套简单的神经网络的代码框架用来加深理解:https://blog.csdn.net/shankezh/article/category/7279585
项目帮忙或工作机会请邮件联系:cloud_happy@163.com
数据集下载地址:https://www.kaggle.com/c/cifar-10 or http://www.cs.toronto.edu/~kriz/cifar.html
本文将会提取论文Inception V1的关键点,并直接使用代码来复现InceptionV1的分类网络,但不对InceptionV1结构的网络进行训练展示,但我将会在近期的InceptionV3进行训练复现展示;
论文精华(V1)
关键信息提取
InceptionV1:
1.提出了新的神经网络卷积结构叫做Incetpion(注意是卷积,不是整体网路),并且在2014年ImageNet的分类和检测任务中获得了新高度;
2.在2014年的竞赛中,提交的网络名称叫做GoogLeNet;
3.感慨了下许多设计网络对小数据集mnist,cifar分类比较好,大数据集的解决方法则是这段时期(2014年之前)通过增加网络深度以及使用dropout来预防过拟合;
4.使用1x1卷积可以维度式的消除网络计算瓶颈,防止限制网络的大小;同时也是增加了网络深度,却不会影响正确率;
5.当前(2014)主要的对象检测方法是R-CNN,R-CNN分解了检测问题一拆为二,首先利用低层次提示(如颜色,像素一致性)在不知类别的对象中找潜在可能对象,然后在定位地方使用CNN分类器识别对象类别;二阶段利用边界框分割分数和底层次提示,及强大的CNN分类能力;我们使用了了相似的方法在我们的检测提交中,但是增强了各阶段的观察能力,例如更好地对象边界框复用的多盒预测,总体上实现了更好地边界框建议;
6.提高正确率最直接了当的方式为增加深度神经网络的尺寸,包括了增加深度(层级数量)和宽度(每一层的单元数量),但是这两种简单的解决方法会带来两种不利因素;a)带来过大的参数量和过拟合风险;b)大大增加计算资源的消耗;
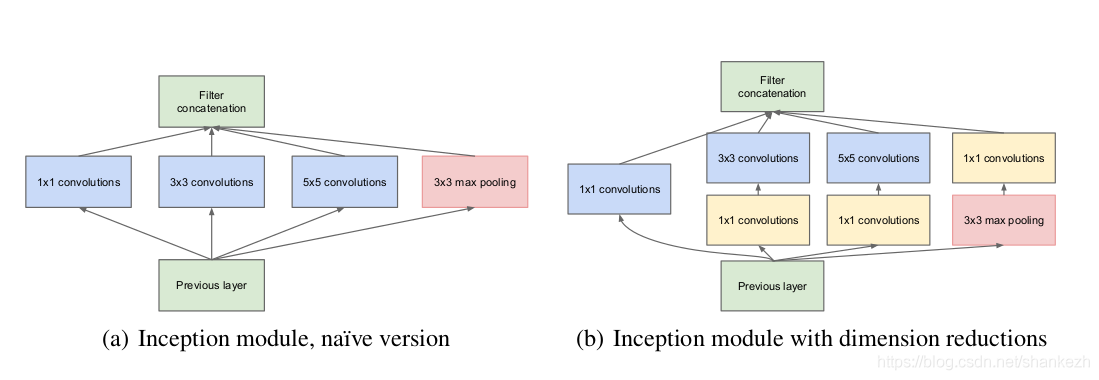
7.解决上面问题的根本办法为,将全连接替换为稀疏结构,甚至为内部卷积层;
8.基于自己的inception结构思想设计了最初的网络,训练,调参,并且认为在上下文定位和对象检测非常有用,并且多数质疑和测试都通过了,起码时获得了局部的最优效果;
9.需要注意,虽然提出的结构可以成功应用于计算机视觉,但依旧存在疑问--质量能否归功于构建原则,这件事的确定需要更多的研究和分析,
10.假设平移不变性,我们的网络将有卷积块构建而成;
11.建议层次化构建,分析最后一层的统计相关性,同时聚类它们形成高相关性的单元组;
12.假设来自早期层的每个单元对应于输入图像的某个区域,并且这些单元被分组到滤波器组中;
13.更低层的相关单元则会集中在局部区域;
14.觉的最终大量的簇单元聚集在一个区域,并且可以被下一层的1x1的卷积覆盖;
15.为了避免块对齐问题,限制Incepiton结构使用的滤波器尺寸在1x1,3x3,5x5,然而这个决定是基于便利比需求更好;
16.在当前计数水平下,卷积网络的池化操作是必要的;
17.网络设计的思想是计算效率和实用性,因此可以运行资源有限的个人设备上,特别是低内存占用;
结构细节
1.试过增加Inception结构的宽度和深度,但结果并没有很理想,最成功的结构,见Figure1.
2.所有的卷积层,包括Inception模块,都使用线性激活;
3.接收模板224x224,RGB3通道与均值消除;
4.Figure1.中 #3x3 reduce 和 #5x5 reduce 表示的是3x3和5x5之前的1x1卷积层及数量;pool proj列中是最大池化层后跟的1x1卷积滤波器的数量;他们都是用了线性激活;
5.网络是22层,如果算池化层则是27层;
6.使用的均值池化层在分类器之前;
7.发现了从全连接层到均值池化层,top-1正确率提升了0.6%,然后使用dropout仍然必不可少,即使后来移除了全连接层;
8.通过添加辅助分类器到中间层,预计将会在分类器中的较低阶段激发辨别能力,增加梯度信号到反向传播,提供增加正则项;
9.这些辅助分类器以更小的卷积网络形式输出到Inception 4a和4d模块后;训练期间,它们的损失通过引入一个系数权重后加入总网络损失中(辅助分类器的权重是 0.3),但在正式的推理阶段,权重不进行计算;
10.辅助分类器信息:a)均值池化层使用5x5滤波,步长为3,结果为4x4x512输出(从4a输出),和结果为4x4x528输出(从4d输出);b)1x1的卷积有128个用来降维,使用ReLU激活;c)全连接使用1024个单元,使用ReLU激活;d)dropout系数0.7;e)softmax线性激活分类器(预测同样的种类计算损失,但推理阶段不使用)
训练细节
1.使用momentum,冲量0.9,固定学习速率,每8个epoch就减少4%(注意,这是针对imageNet数据集);
2.训练了很久,有时会同时改变超参数,如dropout和lr,很难找到一个具有决定性效果指引的方法去训练网络QAQ;
3.发现Andrew Howard的方法对防止过拟合很有效(论文名:Some Improvements on Deep Convolutional Neural network Based Image Classification)
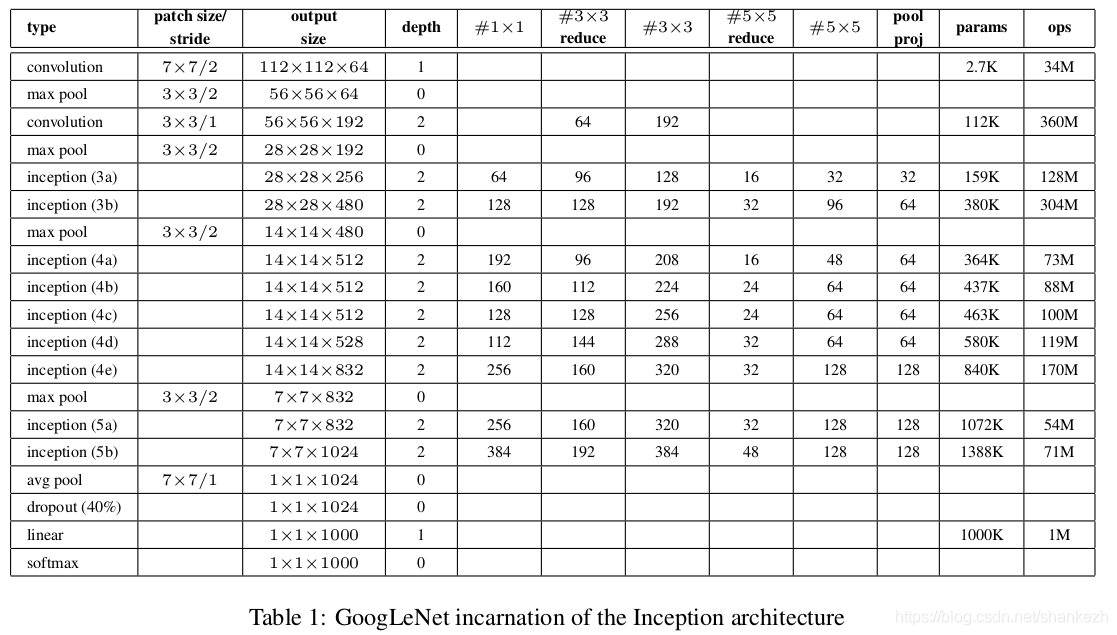
Figure1 InceptionV1搭建的GoogLeNet;
Tensorflow代码实现
说明
使用Tensorflow搭建论文网络,搭建过程遵循论文原意,并且确认google官方给出的IncetpionV1的代码与我的区别,在于Google官方放出的代码没有把论文中两个协助分类器加进去,其他的基本一致,由于论文中结果网络图太长,请大家自行观察论文去看;
代码
模型
InceptionV1.py
def inception_moudle_v1(net,scope,filters_num):
with tf.variable_scope(scope):
with tf.variable_scope('bh1'):
bh1 = slim.conv2d(net,filters_num[0],1,scope='bh1_conv1_1x1')
with tf.variable_scope('bh2'):
bh2 = slim.conv2d(net,filters_num[1],1,scope='bh2_conv1_1x1')
bh2 = slim.conv2d(bh2,filters_num[2],3,scope='bh2_conv2_3x3')
with tf.variable_scope('bh3'):
bh3 = slim.conv2d(net,filters_num[3],1,scope='bh3_conv1_1x1')
bh3 = slim.conv2d(bh3,filters_num[4],5,scope='bh3_conv2_5x5')
with tf.variable_scope('bh4'):
bh4 = slim.max_pool2d(net,3,scope='bh4_max_3x3')
bh4 = slim.conv2d(bh4,filters_num[5],1,scope='bh4_conv_1x1')
net = tf.concat([bh1,bh2,bh3,bh4],axis=3)
return net
def V1_slim(inputs,num_cls,is_train = False,keep_prob=0.4,spatital_squeeze=True):
with tf.name_scope('reshape'):
net = tf.reshape(inputs, [-1, 224, 224, 3])
with tf.variable_scope('GoogLeNet_V1'):
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(5e-4),
weights_initializer=slim.xavier_initializer(),
):
with slim.arg_scope(
[slim.conv2d,slim.max_pool2d,slim.avg_pool2d],
padding='SAME',
stride=1,
):
net = slim.conv2d(net,64,7,stride=2,scope='layer1')
net = slim.max_pool2d(net,3,stride=2,scope='layer2')
net = tf.nn.lrn(net)
net = slim.conv2d(net,64,1,scope='layer3')
net = slim.conv2d(net,192,3,scope='layer4')
net = tf.nn.lrn(net)
net = slim.max_pool2d(net,3,stride=2,scope='layer5')
net = inception_moudle_v1(net,'layer6',[64,96,128,16,32,32])
net = inception_moudle_v1(net,'layer8',[128,128,192,32,96,64])
net = slim.max_pool2d(net,3,stride=2,scope='layer10')
net = inception_moudle_v1(net,'layer11',[192,96,208,16,48,64])
net = inception_moudle_v1(net,'layer13',[160,112,224,24,64,64])
net_1 = net
net = inception_moudle_v1(net,'layer15',[128,128,256,24,64,64])
net = inception_moudle_v1(net,'layer17',[112,144,288,32,64,64])
net_2 = net
net = inception_moudle_v1(net,'lauer19',[256,160,320,32,128,128])
net = slim.max_pool2d(net,3,stride=2,scope='layer21')
net = inception_moudle_v1(net,'layer22',[256,160,320,32,128,128])
net = inception_moudle_v1(net,'layer24',[384,192,384,48,128,128])
net = slim.avg_pool2d(net,7,stride=1,padding='VALID',scope='layer26')
net = slim.dropout(net,keep_prob=keep_prob,scope='dropout')
net = slim.conv2d(net,num_cls,1,activation_fn=None, normalizer_fn=None,scope='layer27')
if spatital_squeeze:
net = tf.squeeze(net,[1,2],name='squeeze')
net = slim.softmax(net,scope='softmax2')
if is_train:
net_1 = slim.avg_pool2d(net_1, 5, padding='VALID', stride=3, scope='auxiliary0_avg')
net_1 = slim.conv2d(net_1, 128, 1, scope='auxiliary0_conv_1X1')
net_1 = slim.flatten(net_1)
net_1 = slim.fully_connected(net_1,1024,scope='auxiliary0_fc1')
net_1 = slim.dropout(net_1, 0.7)
net_1 = slim.fully_connected(net_1,num_cls,activation_fn=None,scope='auxiliary0_fc2')
net_1 = slim.softmax(net_1, scope='softmax0')
net_2 = slim.avg_pool2d(net_2, 5, padding='VALID', stride=3, scope='auxiliary1_avg')
net_2 = slim.conv2d(net_2, 128, 1, scope='auxiliary1_conv_1X1')
net_2 = slim.flatten(net_2)
net_2 = slim.fully_connected(net_2,1024,scope='auxiliary1_fc1')
net_2 = slim.dropout(net_2, 0.7)
net_2 = slim.fully_connected(net_2,num_cls,activation_fn=None,scope='auxiliary1_fc2')
net_2 = slim.softmax(net_2, scope='softmax1')
net = net_1 * 0.3 + net_2 * 0.3 + net * 0.4
print(net.shape)
return net结论
这篇文章最大的贡献个人认为不仅仅是提供了Inception的卷积组合结构,更大的贡献在于,去掉了全连接,使得全局参数最多的地方被去除,这样网络参数量减少,极大地利于网络的运算,使得在算力差的设备也有了更好地运行效果;之前我曾使用过InceptionV1进行对cifar10数据的训练,结果是成功的,只是由于是很久之前的事情,并未对当时的结果和过程予以保存,同时由于时间的关系,我也不再复现InceptionV1训练过程,我将在InceptionV3进行复现训练过程;
本篇博客的代码依旧放在Github中,地址见文章开头。















 2934
2934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









