







推荐:用 NSDT编辑器 快速搭建可编程3D场景
在为特定用例选择最佳图像注释工具时,很容易感到困惑。
更重要的是,每隔几个月就有一个新的数据训练平台进入市场,并承诺提供创新功能、更快的标记或更高精度。
但优化数据注释过程对于确保模型的高性能和可靠性至关重要。 因此,为你的计算机视觉项目选择正确的工具不应掉以轻心。
为此,我们列出了13个最流行的图像标注工具及其主要功能和定价信息,其中1至8为付费平台,9至13为免费图像标注工具。
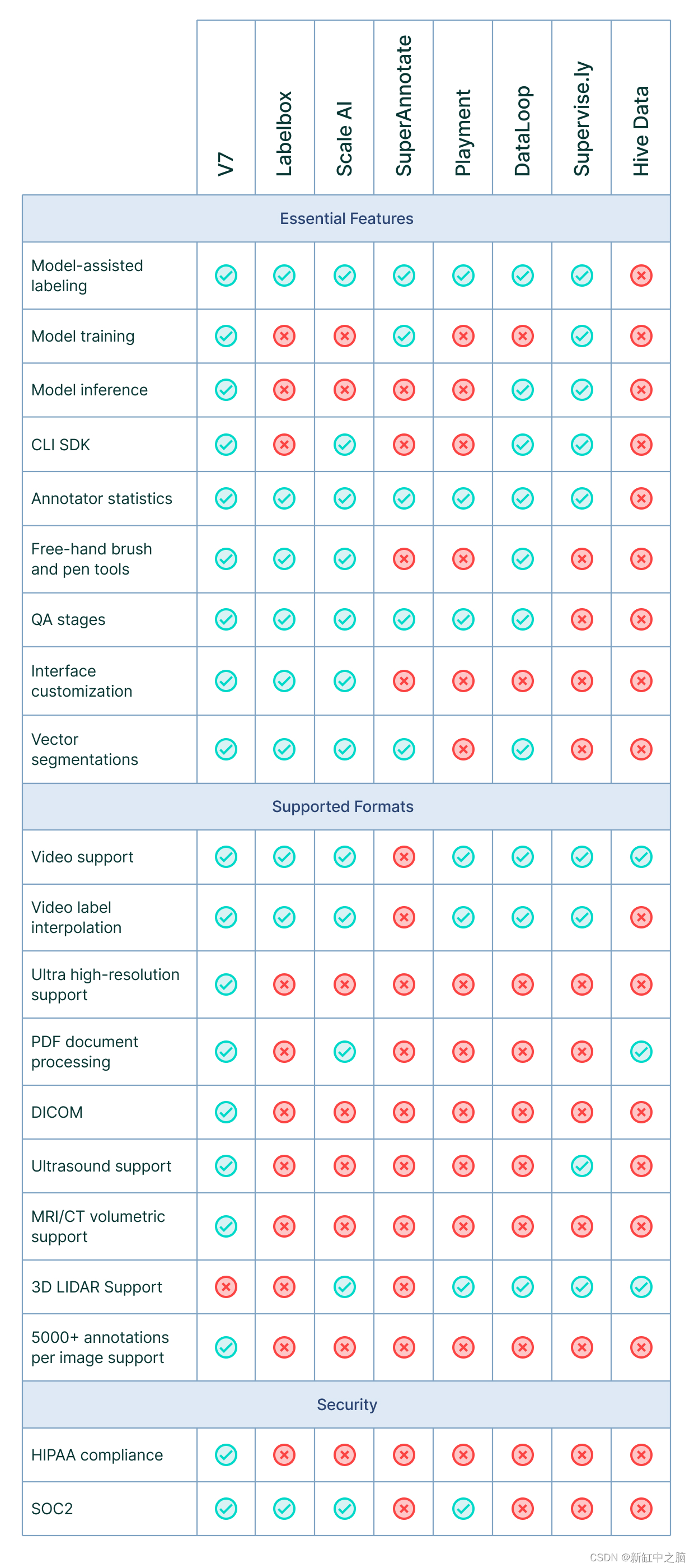
下表为8个付费平台的主要对比:
1、V7
V7是一个集数据集管理、图像标注、视频标注、autoML模型训练于一体的自动化标注平台,自动完成标注任务。
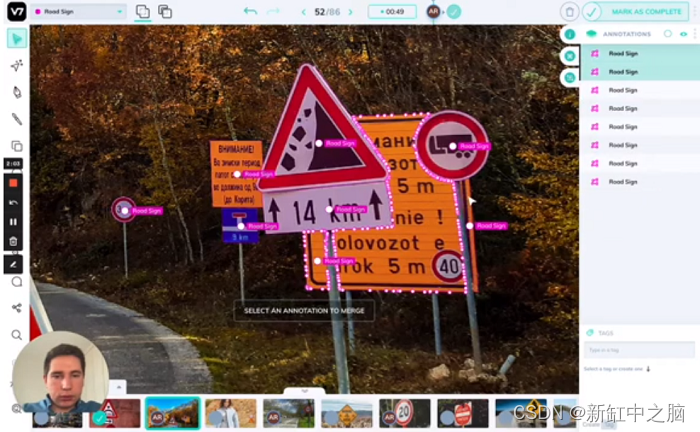
V7 使团队能够存储、管理、注释和自动化其数据标注工作流程:图片、视频、DICOM医疗数据、显微镜图像、PDF和文档处理、3D体积数据。
V7的主要特点包括:
- 自动标注功能,无需事先培训
- 可组合的工作流程允许多个模型和人员参与循环阶段
- 在大规模情况下保持稳健的数据集管理
- 综合数据标记服务
- 实时协作和流畅的用户体验
- 帧完美的视频标注工具
V7的价格:
- 0 美元起(教育计划),更多详情请参见 V7 定价页面
2、Labelbox
Labelbox 是一个由三个核心层构建的训练数据平台,可促进从标记、协作到迭代的整个过程。 它创建于 2018 年,并迅速成为最流行的数据标记工具之一。
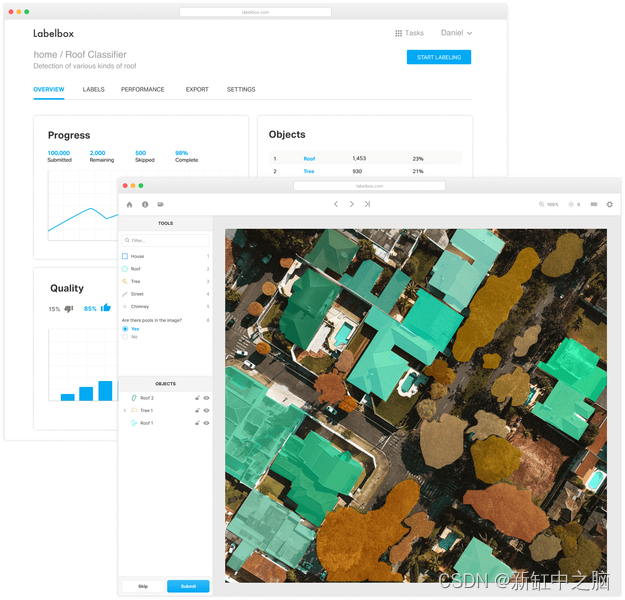
Labelbox 提供支持 AI 的标签工具、标签自动化、人力、数据管理、强大的集成 API 以及用于扩展的 Python SDK。它支持使用多边形、边界框、线条以及更高级的标签工具进行注释。
Labelbox的主要特性:
- AI 辅助标签(BYO 模型)
- 综合数据标记服务
- QA/QC 工具和标注审核工作流程
- 强大的标注者性能分析
- 可定制的界面以简化任务
Labelbox的价格:
- 免费 5000 张图像/定制专业版和企业版计划。
3、Scale AI
Scale 是一个数据平台,可对大量 3D 传感器、图像和视频数据进行注释。
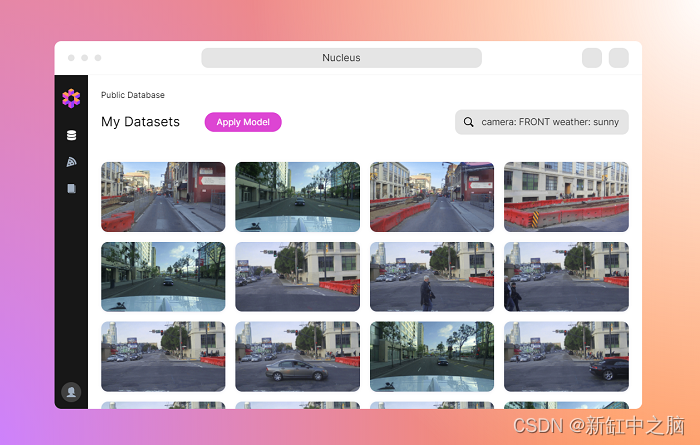
Scale 提供基于 ML 的预标记、自动化质量保证系统、数据集管理、文档处理和人工智能辅助数据注释(避开自动驾驶数据处理)。该数据注释工具可用于各种计算机视觉任务,包括对象检测、分类和文本识别,并且支持多种数据格式。
Scale 的主要特性:
- 机器学习驱动的预标注
- 核心数据集管理
- 带有黄金套装的自动化 QA 系统
- 文档处理功能
- 模型在环数据管理
Scale的价格:
- 50,000 美元起
4、SuperAnnotate
Superannotate 是一个端到端图像和视频注释平台,可简化和自动化计算机视觉工作流程。
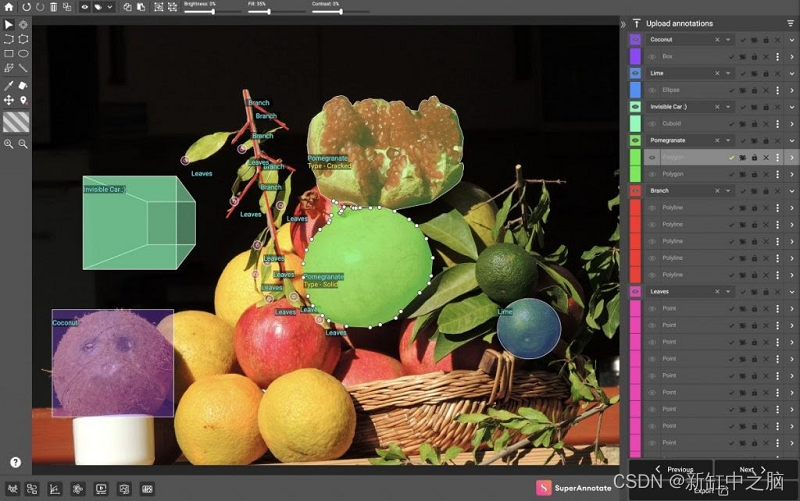
SuperAnnotate 允许你为各种计算机视觉任务创建高质量的训练数据集,包括对象检测、实例和语义分割、关键点注释、长方体注释和视频跟踪。可用的工具包括矢量注释(框、多边形、直线、椭圆、关键点和长方体)和使用画笔的像素级注释。
SuperAnnotate的主要特性:
- AI 辅助标签(BYO 模型)
- 用于语义分割的超像素
- 先进的质量控制系统
- 通过图像转换支持多种格式
SuperAnnotate的价格:
- 14 天免费试用
- 定制入门版、专业版、企业版计划
5、DataLoop
DataLoop是一体化的基于云的注释平台,具有嵌入式工具和自动化功能,可生成高质量的数据集。

DataLoop 通过利用循环中的人类反馈来适应整个人工智能生命周期,包括注释、模型评估和模型改进。它提供了用于基本计算机视觉任务的工具,例如检测、分类、关键点和分割。 Dataloop 支持图像和视频数据。
DataLoop的主要特性:
- 模型辅助标记
- 多种数据类型支持
- 具有简化的数据索引和查询系统的高级团队工作流程
- 视频支持
DataLoop的价格:
- 免费试用、定制企业计划
6、Playment
Playment 是一个完全托管的数据标签平台,成立于 2015 年,为计算机视觉模型生成训练数据。
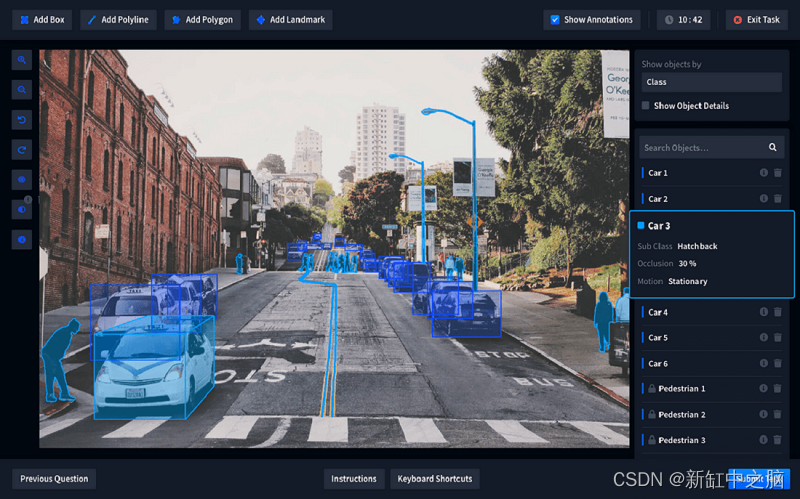
Playment 支持图像和视频数据,并提供各种基本注释工具,包括边界框、长方体、多边形或地标。它遵循微工作原则,将大问题分解为微任务,并将它们分配给训练有素的注释者的大型社区。
Playment的主要特性:
- 完全托管—只需要企业共享数据和标签指南
- 允许属性提取
- 文档管理(人工辅助 OCR)
7、Supervise.ly
Supervise.ly 是一个基于网络的图像和视频标注平台,个人研究人员和大型团队可以在其中对数据集和神经网络进行注释和实验。
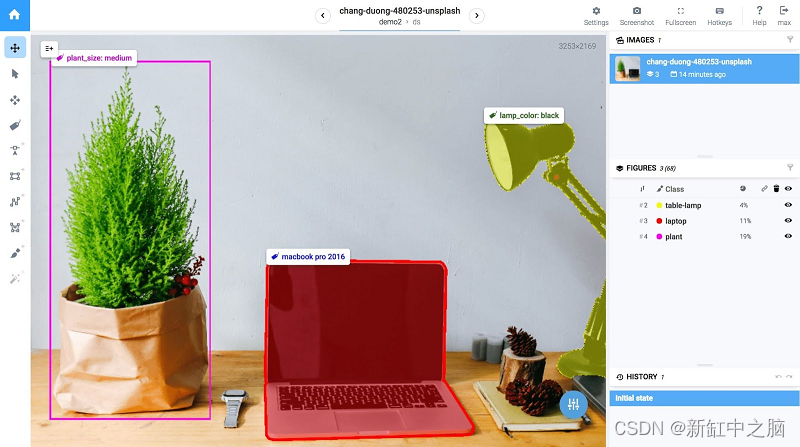
除了框、线、点、多边形或位图画笔等基本注释工具外,Supervise.ly 还提供数据转换语言工具并支持 3D 点云。
Supervise.ly的主要特性:
- AI辅助标记
- 多格式数据注释和管理
- 选项开发和导入自定义数据格式的插件
- 3D 点云
- 团队、工作区和数据集不同级别的项目管理选项。
Supervise.ly的价格:
- 社区版免费 100 张图片
8、Hive Data
Hive Data 是一个完全托管的数据注释解决方案,用于为 AI / ML 模型获取和标记训练数据。
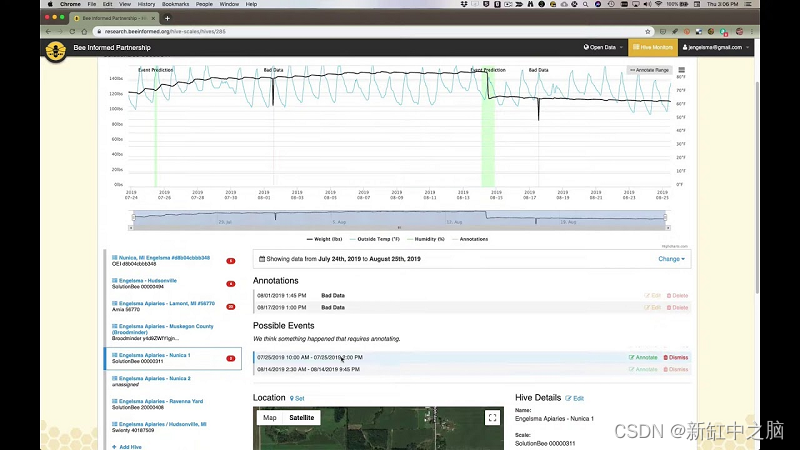
Hive Data 支持图像、视频、文本、3D 点云注释和数据源。 除了基本注释类型之外,Hive Data 还提供多帧对象跟踪、轮廓和 3D 全景分割。
Hive Data的主要特性:
- 多种数据类型支持
- 可用数据来源
- 完全托管的端到端数据标签服务
9、CVAT
CVAT(计算机视觉标注工具)是一个开源的、基于网络的图像和视频标注工具,用于标记计算机视觉数据,由英特尔支持和维护。
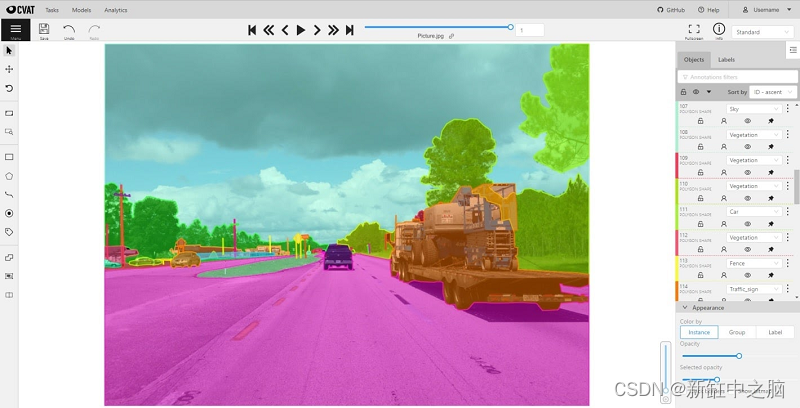
CVAT 支持监督机器学习的主要任务:对象检测、图像分类和图像分割。 它提供四种基本类型的注释:框、多边形、折线和点。
CVAT的主要特性:
- 半自动标注
- 关键帧之间形状的插值
- 带有注释项目和任务列表的仪表板
- LDAP
- 支持大量自动化仪器,包括使用 TensorFlow* 对象检测 API 或视频插值的自动标注。
CVAT是免费的。
10、LabelMe
LabelMe是由麻省理工学院计算机科学与人工智能实验室创建的在线注释工具。 它提供带有标注的数字图像数据集。
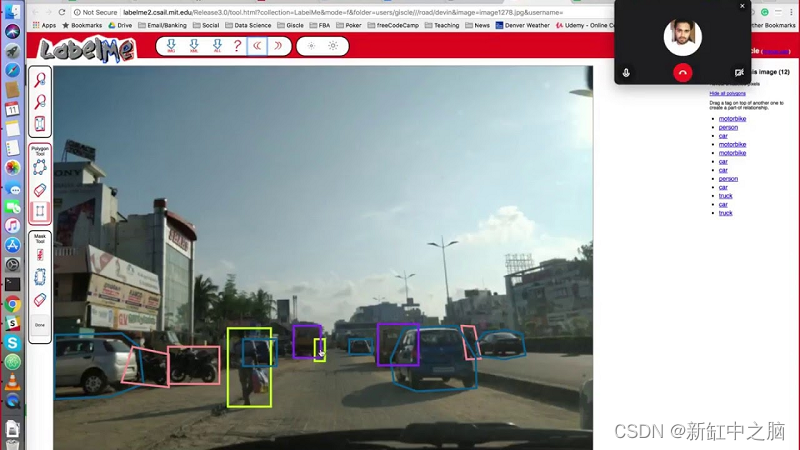
该数据集是免费的,并向外部贡献开放。Labelme支持多边形、矩形、圆形、直线、点、线带等六种不同的标注类型。 限制之一是文件只能以 JSON 格式保存和导出。
LabelMe的主要特征:
- 控制点修改
- 线段和多边形移除
- 六种注释类型
- 文件列表
LabelMe是免费的。
11、Labelimg
Labelimg是一种图形图像标注工具,用于使用图像中的边界框来标记对象。 它是用 Python 编写的。 你可以将标注导出为 PASCAL VOC 格式的 XML 文件。
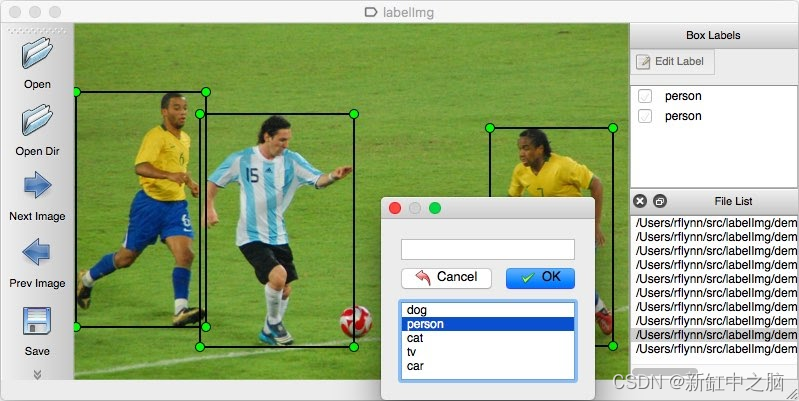
在默认版本中,Labelimg 仅提供一种注释类型 - 边界框或矩形形状。 不过,你还可以使用 GitHub 页面通过代码添加另一种形状。
Labelimg的主要特性:
- 标注在 PASCAL VOC 中保存为 XML 文件
- 需要本地安装
- 仅图像标注
Labelimg是免费的。
12、VoTT
VoTT(Visual Object Tagging Tool)是微软开发的一款免费开源的图像标注工具。

VoTT 提供端到端支持,用于生成数据集并验证视频和图像资产的对象检测模型。
VoTT的主要特性:
- 可以选择标记和注释图像目录或独立视频
- 标签和资产导出为 CNTK、Tensorflow (PascalVOC) 或 YOLO 格式
- 提供可扩展模型,用于从本地和云存储提供商导入/导出数据
- 允许在新视频上运行和验证经过训练的 CNTK 对象检测模型,以生成更强大的模型
VoTT是免费的。
13、ImgLab
ImgLab 是一个开源的、基于网络的图像标注工具。
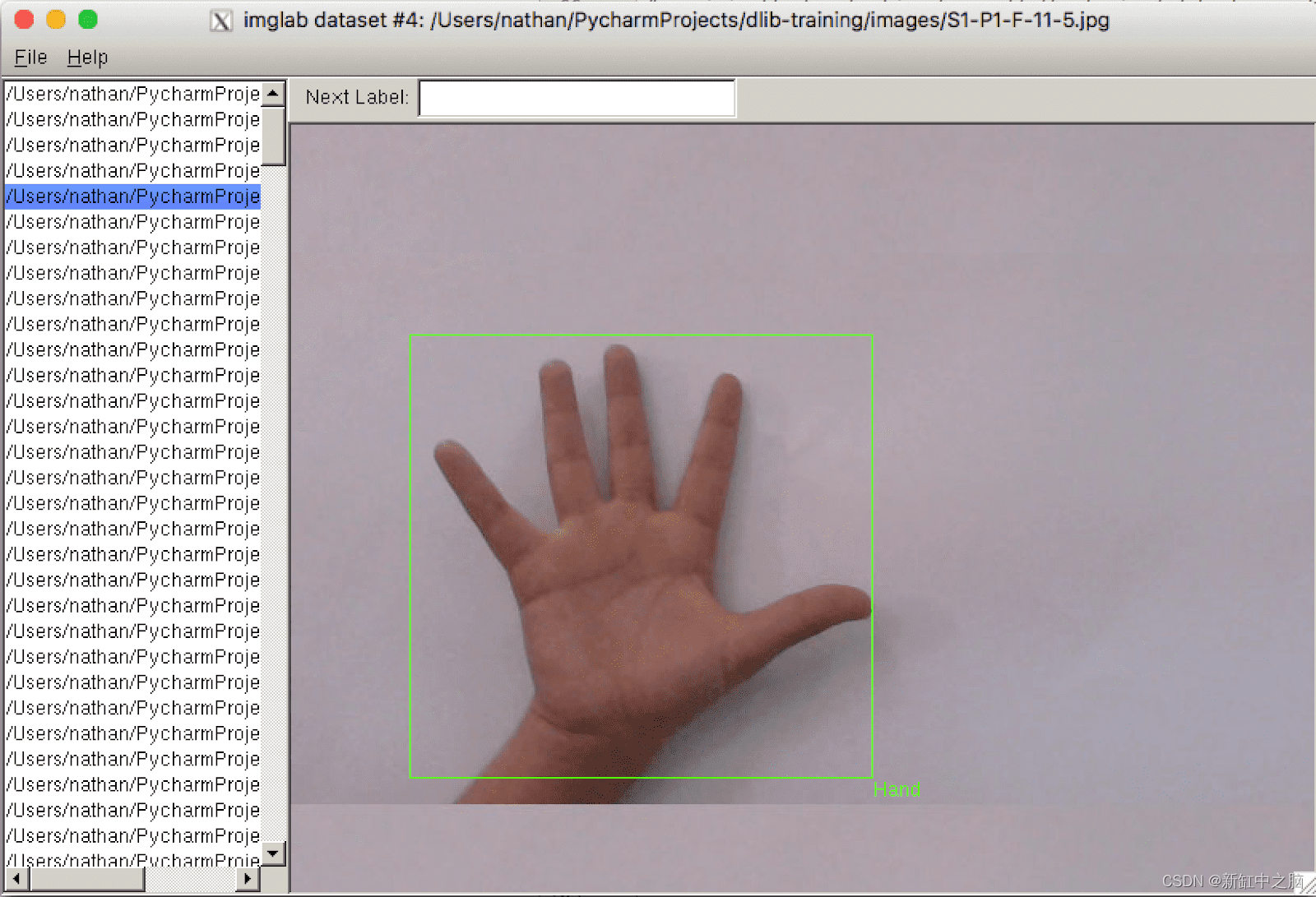
ImgLab提供点、圆、边界框、多边形等多种标签类型。 它还支持各种格式,包括 dlib、XML、Pascal VOC 和 COCO。
ImgLab的主要特性:
- 基于网络和本地版本
- 基本 IDE 功能
- 支持多种标签类型和文件格式
ImgLab是免费的。

















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









