







如今,大型语言模型的使用方式有以下几种:
- 作为 OpenAI、Anthropic 或主要云提供商托管的专有模型的 API 端点
- 作为从 HuggingFace 的模型中心下载的模型工件和/或使用 HuggingFace 库进行训练/微调并托管在本地存储中
- 作为针对本地推理优化的格式的模型工件,通常为 GGUF,可通过 llama.cpp 或 ollama 等应用程序访问
- 作为 ONNX,一种优化后端 ML 框架之间共享的格式
对于一个附带项目,我使用 llama.cpp,这是一个基于 C/C++ 的 LLM 推理引擎,针对 Apple Silicon 上的 M 系列 GPU。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
运行 llama.cpp 时,你会得到一个长日志,主要包含有关模型架构及其性能(没有杂音)的元数据的键值对:
make -j && ./main -m /Users/vicki/llama.cpp/models/mistral-7b-instruct-v0.2.Q8_0.gguf -p "What is Sanremo? no yapping"
Sanremo Music Festival (Festival di Sanremo) is an annual Italian music competition held in the city of Sanremo since 1951. It's considered one of the most prestigious and influential events in the Italian music scene. The festival features both newcomers and established artists competing for various awards, including the Big Award (Gran Premio), which grants the winner the right to represent Italy in the Eurovision Song Contest. The event consists of several live shows where artists perform their original songs, and a jury composed of musicians, critics, and the public determines the winners through a combination of points. [end of text]
llama_print_timings: load time = 11059.32 ms
llama_print_timings: sample time = 11.62 ms / 140 runs ( 0.08 ms per token, 12043.01 tokens per second)
llama_print_timings: prompt eval time = 87.81 ms / 10 tokens ( 8.78 ms per token, 113.88 tokens per second)
llama_print_timings: eval time = 3605.10 ms / 139 runs ( 25.94 ms per token, 38.56 tokens per second)
llama_print_timings: total time = 3730.78 ms / 149 tokens
ggml_metal_free: deallocating
Log end这些日志可以在 Llama.cpp 代码库中找到。在那里,你还会找到 GGUF。GGUF是用于在 Llama.cpp 和其他本地运行器(如 Llamafile、Ollama 和 GPT4All)上提供模型的文件格式。
要了解 GGUF 的工作原理,我们首先需要深入研究机器学习模型及其生成的工件类型。
1、什么是机器学习模型
让我们从描述机器学习模型开始。最简单的说,模型是一个文件或一组文件,其中包含模型架构以及从训练循环生成的模型的权重和偏差。
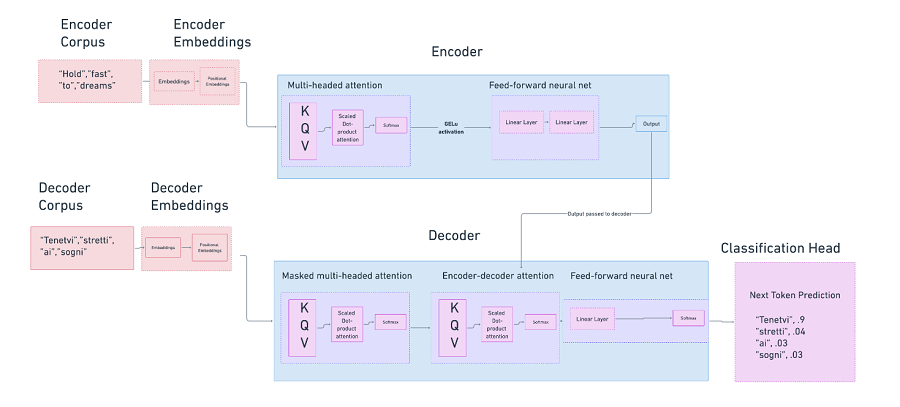
在 LLM 领域,我们通常对 Transformer 风格的模型和架构感兴趣。
在 Transformer 中,我们有许多活动部件。
对于输入,我们使用从人类生成的自然语言内容中聚合的训练数据语料库
对于算法,我们:
- 将这些数据转换为嵌入
- 对嵌入进行位置编码,以提供有关单词在序列中彼此相对位置的信息
- 基于初始化的权重组合,为序列中每个单词相对于其他单词创建多头自注意力
- 通过 softmax 对层进行规范化
- 通过前馈神经网络运行生成的矩阵
- 将输出投影到所需任务的正确向量空间中
- 计算损失,然后更新模型参数
输出:通常对于聊天完成任务,模型返回任何给定单词完成短语的统计可能性。由于其自回归性质,它会对短语中的每个单词一次又一次地执行此操作。
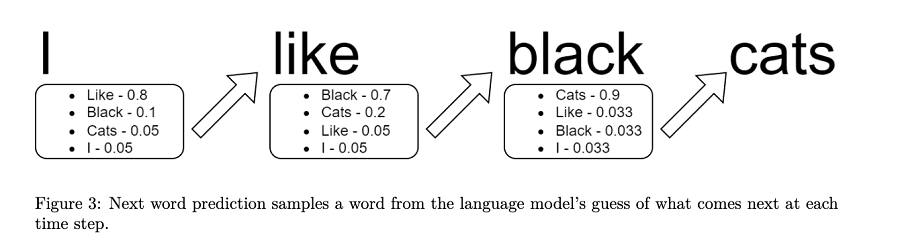
如果该模型作为消费者最终产品,它仅根据最高概率返回实际文本输出,并带有多种选择该文本的策略:
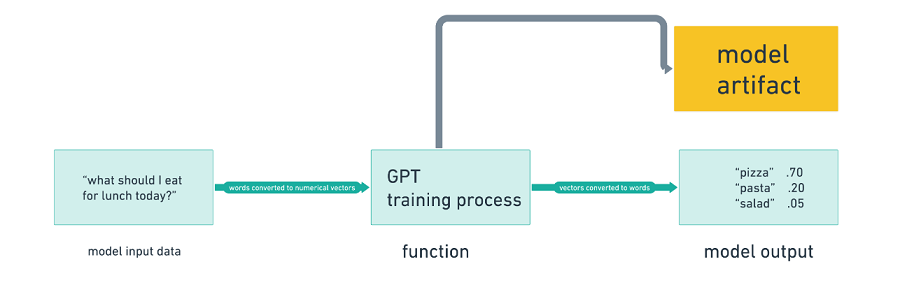
简而言之,我们使用方程将输入转换为输出。除了模型的输出,我们还有模型本身,它是建模过程的产物:
2、从一个简单的模型开始
让我们从转换器的复杂性中退一步,在 PyTorch 中构建一个小型线性回归模型。幸运的是,线性回归也是一个(浅层)神经网络,因此我们可以在 PyTorch 中使用它,并使用相同的框架将我们的简单模型映射到更复杂的模型。
线性回归接受一组数值输入并生成一组数值输出。(与转换器相反,转换器接受一组文本输入并生成一组文本输入及其相关的数值概率。)
例如,假设我们为统计学家生产手工榛子酱,并希望预测我们在任何一天将生产多少罐 Nulltella。假设我们有一些可用的数据,即我们每天有多少小时的日照,以及我们每天能够生产多少罐 Nulltella。

事实证明,天气晴朗时,我们更有灵感生产榛子酱,我们可以清楚地看到数据中输入和输出之间的这种关系(我们不会在周五至周日生产 Nulltella,因为我们更喜欢花那些时间编写有关数据序列化格式的内容):
| day_id | hours | jars |
|--------|---------|------|
| mon | 1 | 2 |
| tues | 2 | 4 |
| wed | 3 | 6 |
| thu | 4 | 8 |这是我们用来训练模型的数据。我们需要将这些数据分成三部分:
- 用于训练模型(训练数据)
- 用于测试模型的准确性(测试数据)
- 用于在模型训练阶段调整超参数、模型的元方面,如学习率(验证集)。
在线性回归的特定情况下,技术上没有超参数,尽管我们可以合理地认为我们在 PyTorch 中设置的学习率为 1。假设我们有 100 个这样的数据点值。
我们将数据分为训练、测试和验证。通常接受的分割是使用 80% 的数据进行训练/验证,20% 用于测试。我们希望我们的模型能够访问尽可能多的数据,以便它学习更准确的表示,所以我们将大部分数据留给训练。
现在我们有了数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









